 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRA-DCA: A Randomized Active-Set DCA for Directional Stationarity in Max-Structured DC Programs
May 22, 2026We study nonsmooth difference-of-convex programs whose subtracted convex term is a finite maximum of smooth convex functions. In this setting, standard DCA iterations may converge to critical points that are not directionally stationary, whereas exact active-vertex screening can be expensive when active sets are large or combinatorial. We propose RA-DCA, a vertex-first randomized active-set DCA that projects active gradients onto sampled directions, checks a sampled vertex residual, and uses a small linear program only as a low-residual convex-combination fallback. The method preserves the descent structure of DCA and reduces the randomized screening layer to matrix multiplications. Under the stated regularity, numerical active-set consistency, and random-embedding assumptions, every accumulation point generated by the safeguarded method is directionally stationary with probability one. MATLAB experiments first test the theorem on degenerate max-affine, max-quadratic, and sparse support-function models, where the safeguard avoids nonstationary critical points and closely tracks a full active-vertex scan. Block top-k tests then show that the same screening idea remains useful when exact aggregate enumeration is combinatorial. Trimmed-regression, complementarity, and QUBO diagnostics separate cases where active-set selection helps from cases dominated by multistart search, the DC split, or other problem-specific features.
Continuous-Time Dynamics of the Difference-of-Convex Algorithm
Apr 08, 2026We study the continuous-time structure of the difference-of-convex algorithm (DCA) for smooth DC decompositions with a strongly convex component. In dual coordinates, classical DCA is exactly the full-step explicit Euler discretization of a nonlinear autonomous system. This viewpoint motivates a damped DCA scheme, which is also a Bregman-regularized DCA variant, and whose vanishing-step limit yields a Hessian-Riemannian gradient flow generated by the convex part of the decomposition. For the damped scheme we prove monotone descent, asymptotic criticality, Kurdyka-Lojasiewicz convergence under boundedness, and a global linear rate under a metric DC-PL inequality. For the limiting flow we establish an exact energy identity, asymptotic criticality of bounded trajectories, explicit global rates under metric relative error bounds, finite-length and single-point convergence under a Kurdyka-Lojasiewicz hypothesis, and local exponential convergence near nondegenerate local minima. The analysis also reveals a global-local tradeoff: the half-relaxed scheme gives the best provable global guarantee in our framework, while the full-step scheme is locally fastest near a nondegenerate minimum. Finally, we show that different DC decompositions of the same objective induce different continuous dynamics through the metric generated by the convex component, providing a geometric criterion for decomposition quality and linking DCA with Bregman geometry.
Scalable Mean-Variance Portfolio Optimization via Subspace Embeddings and GPU-Friendly Nesterov-Accelerated Projected Gradient
Apr 03, 2026We develop a sketch-based factor reduction and a Nesterov-accelerated projected gradient algorithm (NPGA) with GPU acceleration, yielding a doubly accelerated solver for large-scale constrained mean-variance portfolio optimization. Starting from the sample covariance factor $L$, the method combines randomized subspace embedding, spectral truncation, and ridge stabilization to construct an effective factor $L_{eff}$. It then solves the resulting constrained problem with a structured projection computed by scalar dual search and GPU-friendly matrix-vector kernels, yielding one computational pipeline for the baseline, sketched, and Sketch-Truncate-Ridge (STR)-regularized models. We also establish approximation, conditioning, and stability guarantees for the sketching and STR models, including explicit $O(\varepsilon)$ bounds for the covariance approximation, the optimal value error, and the solution perturbation under $(\varepsilon,δ)$-subspace embeddings. Experiments on synthetic and real equity-return data show that the method preserves objective accuracy while reducing runtime substantially. On a 5440-asset real-data benchmark with 48374 training periods, NPGA-GPU solves the unreduced full model in 2.80 seconds versus 64.84 seconds for Gurobi, while the optimized compressed GPU variants remain in the low-single-digit-second regime. These results show that the full dense model is already practical on modern GPUs and that, after compression, the remaining bottleneck is projection rather than matrix-vector multiplication.
Yau's Affine Normal Descent: Algorithmic Framework and Convergence Analysis
Mar 30, 2026We propose Yau's Affine Normal Descent (YAND), a geometric framework for smooth unconstrained optimization in which search directions are defined by the equi-affine normal of level-set hypersurfaces. The resulting directions are invariant under volume-preserving affine transformations and intrinsically adapt to anisotropic curvature. Using the analytic representation of the affine normal from affine differential geometry, we establish its equivalence with the classical slice-centroid construction under convexity. For strictly convex quadratic objectives, affine-normal directions are collinear with Newton directions, implying one-step convergence under exact line search. For general smooth (possibly nonconvex) objectives, we characterize precisely when affine-normal directions yield strict descent and develop a line-search-based YAND. We establish global convergence under standard smoothness assumptions, linear convergence under strong convexity and Polyak-Lojasiewicz conditions, and quadratic local convergence near nondegenerate minimizers. We further show that affine-normal directions are robust under affine scalings, remaining insensitive to arbitrarily ill-conditioned transformations. Numerical experiments illustrate the geometric behavior of the method and its robustness under strong anisotropic scaling.
Understand the Effectiveness of Shortcuts through the Lens of DCA
Dec 13, 2024

Difference-of-Convex Algorithm (DCA) is a well-known nonconvex optimization algorithm for minimizing a nonconvex function that can be expressed as the difference of two convex ones. Many famous existing optimization algorithms, such as SGD and proximal point methods, can be viewed as special DCAs with specific DC decompositions, making it a powerful framework for optimization. On the other hand, shortcuts are a key architectural feature in modern deep neural networks, facilitating both training and optimization. We showed that the shortcut neural network gradient can be obtained by applying DCA to vanilla neural networks, networks without shortcut connections. Therefore, from the perspective of DCA, we can better understand the effectiveness of networks with shortcuts. Moreover, we proposed a new architecture called NegNet that does not fit the previous interpretation but performs on par with ResNet and can be included in the DCA framework.
A Refined Inertial DCA for DC Programming
Apr 30, 2021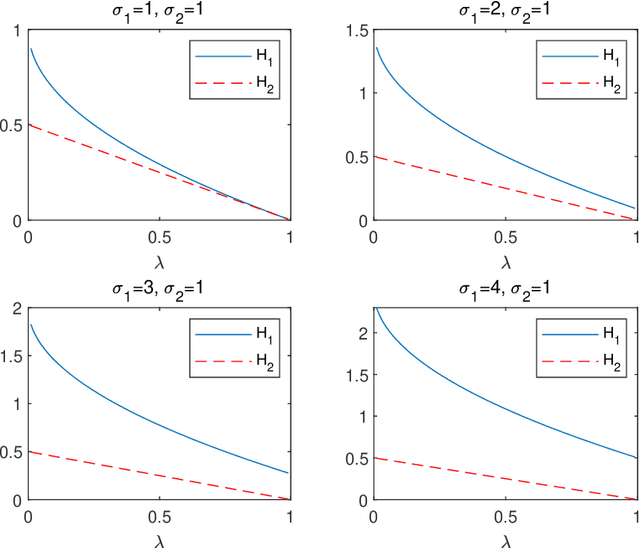

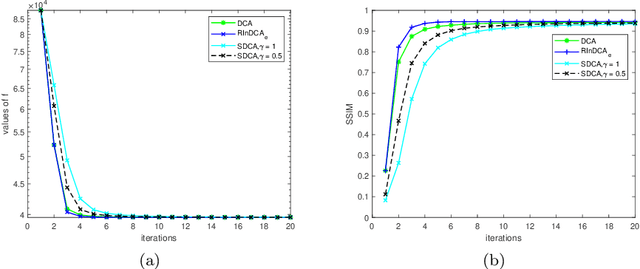
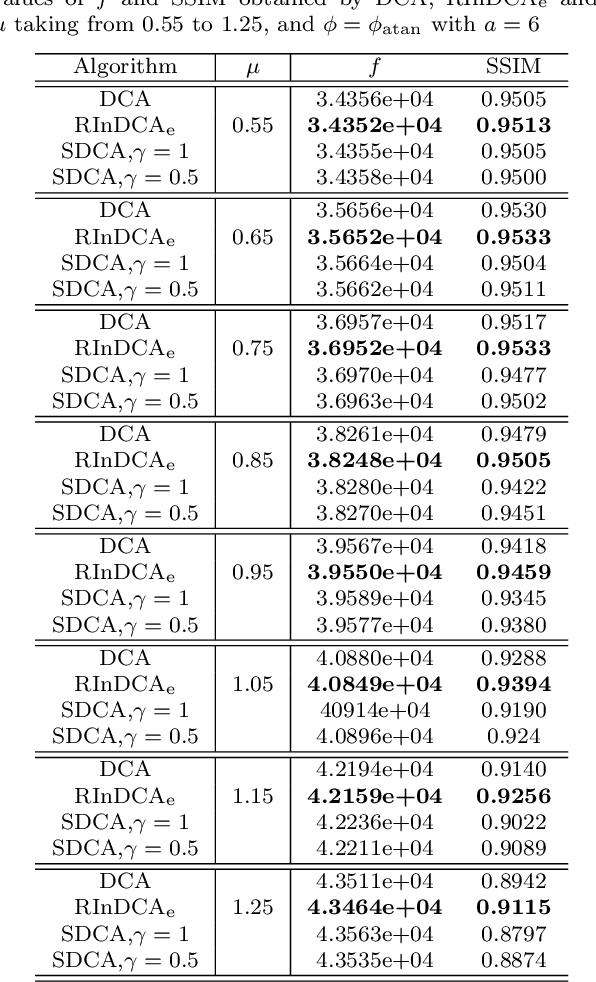
We consider the difference-of-convex (DC) programming problems whose objective function is level-bounded. The classical DC algorithm (DCA) is well-known for solving this kind of problems, which returns a critical point. Recently, de Oliveira and Tcheo incorporated the inertial-force procedure into DCA (InDCA) for potential acceleration and preventing the algorithm from converging to a critical point which is not d(directional)-stationary. In this paper, based on InDCA, we propose two refined inertial DCA (RInDCA) with enlarged inertial step-sizes for better acceleration. We demonstrate the subsequential convergence of our refined versions to a critical point. In addition, by assuming the Kurdyka-Lojasiewicz (KL) property of the objective function, we establish the sequential convergence of RInDCA. Numerical simulations on image restoration problem show the benefit of enlarged step-size.
Spatio-Temporal Neural Network for Fitting and Forecasting COVID-19
Mar 22, 2021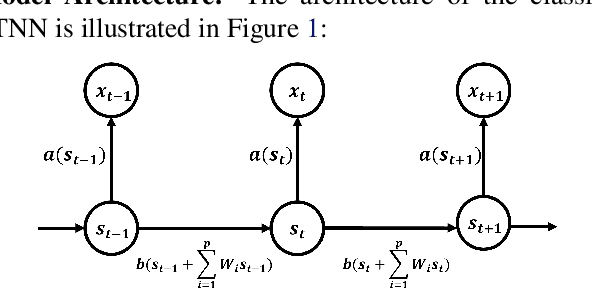
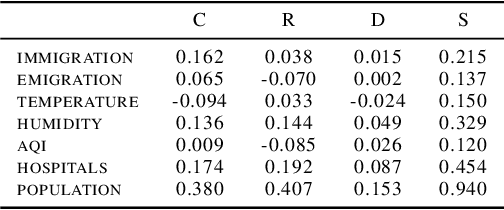
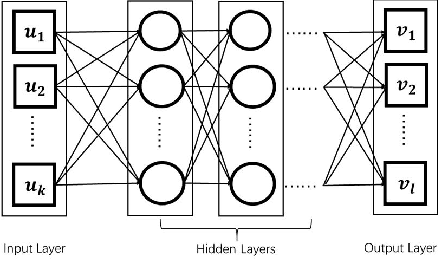
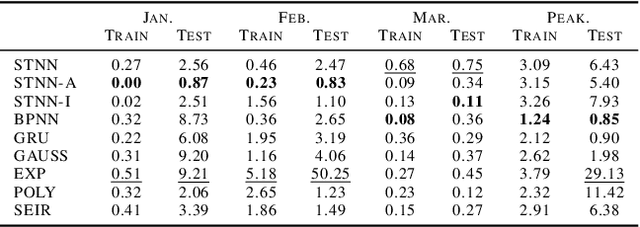
We established a Spatio-Temporal Neural Network, namely STNN, to forecast the spread of the coronavirus COVID-19 outbreak worldwide in 2020. The basic structure of STNN is similar to the Recurrent Neural Network (RNN) incorporating with not only temporal data but also spatial features. Two improved STNN architectures, namely the STNN with Augmented Spatial States (STNN-A) and the STNN with Input Gate (STNN-I), are proposed, which ensure more predictability and flexibility. STNN and its variants can be trained using Stochastic Gradient Descent (SGD) algorithm and its improved variants (e.g., Adam, AdaGrad and RMSProp). Our STNN models are compared with several classical epidemic prediction models, including the fully-connected neural network (BPNN), and the recurrent neural network (RNN), the classical curve fitting models, as well as the SEIR dynamical system model. Numerical simulations demonstrate that STNN models outperform many others by providing more accurate fitting and prediction, and by handling both spatial and temporal data.
A Difference-of-Convex Programming Approach With Parallel Branch-and-Bound For Sentence Compression Via A Hybrid Extractive Model
Feb 02, 2020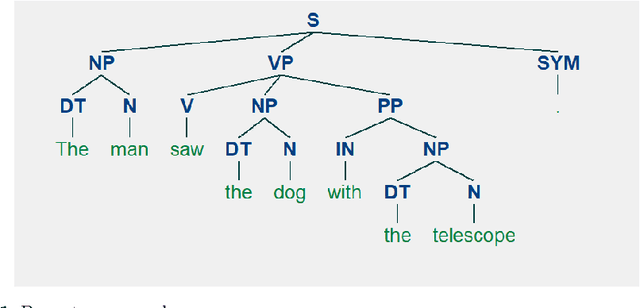
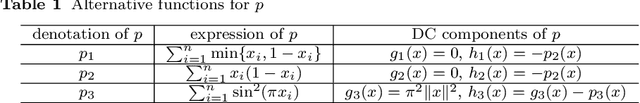
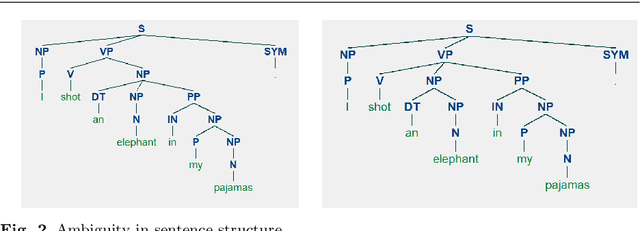

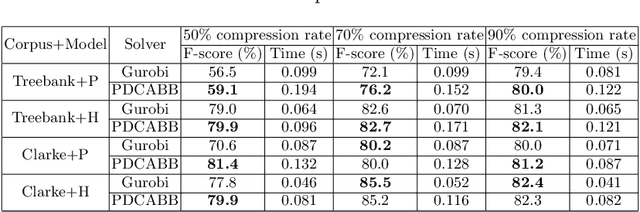
Sentence compression is an important problem in natural language processing with wide applications in text summarization, search engine and human-AI interaction system etc. In this paper, we design a hybrid extractive sentence compression model combining a probability language model and a parse tree language model for compressing sentences by guaranteeing the syntax correctness of the compression results. Our compression model is formulated as an integer linear programming problem, which can be rewritten as a Difference-of-Convex (DC) programming problem based on the exact penalty technique. We use a well known efficient DC algorithm -- DCA to handle the penalized problem for local optimal solutions. Then a hybrid global optimization algorithm combining DCA with a parallel branch-and-bound framework, namely PDCABB, is used for finding global optimal solutions. Numerical results demonstrate that our sentence compression model can provide excellent compression results evaluated by F-score, and indicate that PDCABB is a promising algorithm for solving our sentence compression model.
Sentence Compression via DC Programming Approach
Feb 13, 2019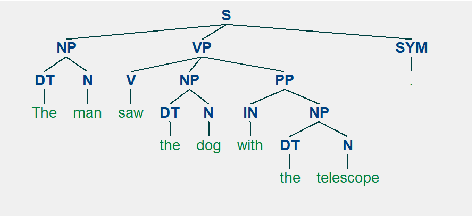
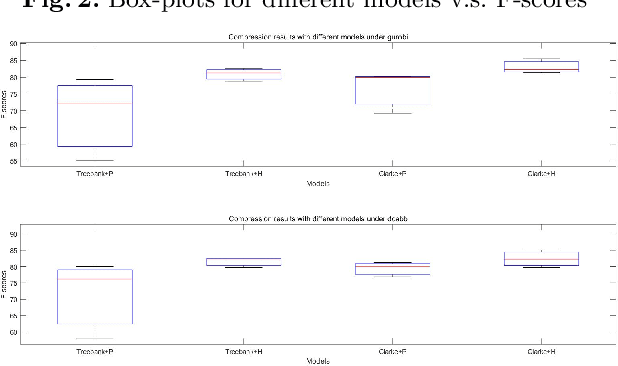
Sentence compression is an important problem in natural language processing. In this paper, we firstly establish a new sentence compression model based on the probability model and the parse tree model. Our sentence compression model is equivalent to an integer linear program (ILP) which can both guarantee the syntax correctness of the compression and save the main meaning. We propose using a DC (Difference of convex) programming approach (DCA) for finding local optimal solution of our model. Combing DCA with a parallel-branch-and-bound framework, we can find global optimal solution. Numerical results demonstrate the good quality of our sentence compression model and the excellent performance of our proposed solution algorithm.