 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemiparametric spectral modeling of the Drosophila connectome
May 09, 2017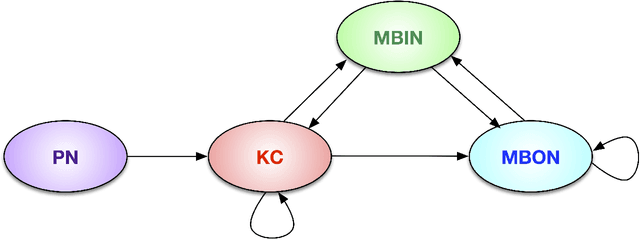
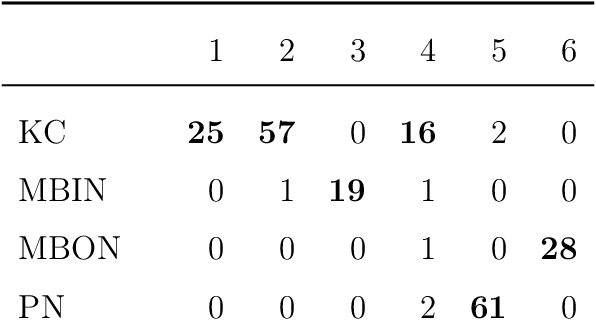
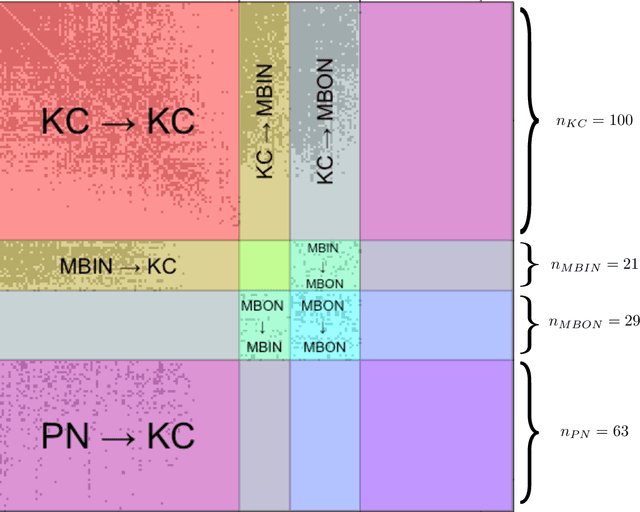

We present semiparametric spectral modeling of the complete larval Drosophila mushroom body connectome. Motivated by a thorough exploratory data analysis of the network via Gaussian mixture modeling (GMM) in the adjacency spectral embedding (ASE) representation space, we introduce the latent structure model (LSM) for network modeling and inference. LSM is a generalization of the stochastic block model (SBM) and a special case of the random dot product graph (RDPG) latent position model, and is amenable to semiparametric GMM in the ASE representation space. The resulting connectome code derived via semiparametric GMM composed with ASE captures latent connectome structure and elucidates biologically relevant neuronal properties.
Fast Embedding for JOFC Using the Raw Stress Criterion
Oct 31, 2016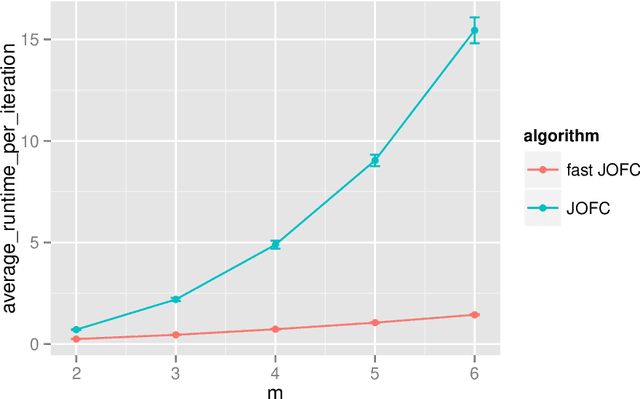
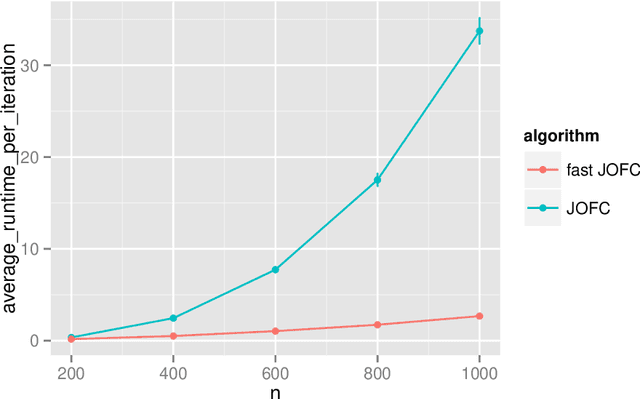
The Joint Optimization of Fidelity and Commensurability (JOFC) manifold matching methodology embeds an omnibus dissimilarity matrix consisting of multiple dissimilarities on the same set of objects. One approach to this embedding optimizes the preservation of fidelity to each individual dissimilarity matrix together with commensurability of each given observation across modalities via iterative majorization of a raw stress error criterion by successive Guttman transforms. In this paper, we exploit the special structure inherent to JOFC to exactly and efficiently compute the successive Guttman transforms, and as a result we are able to greatly speed up the JOFC procedure for both in-sample and out-of-sample embedding. We demonstrate the scalability of our implementation on both real and simulated data examples.
Community Detection and Classification in Hierarchical Stochastic Blockmodels
Aug 26, 2016
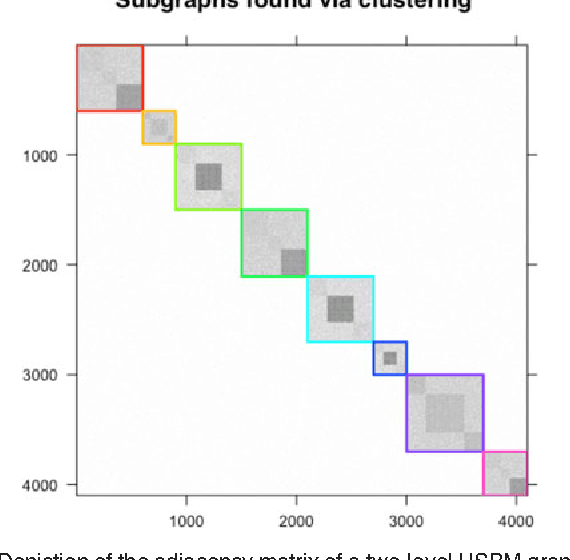
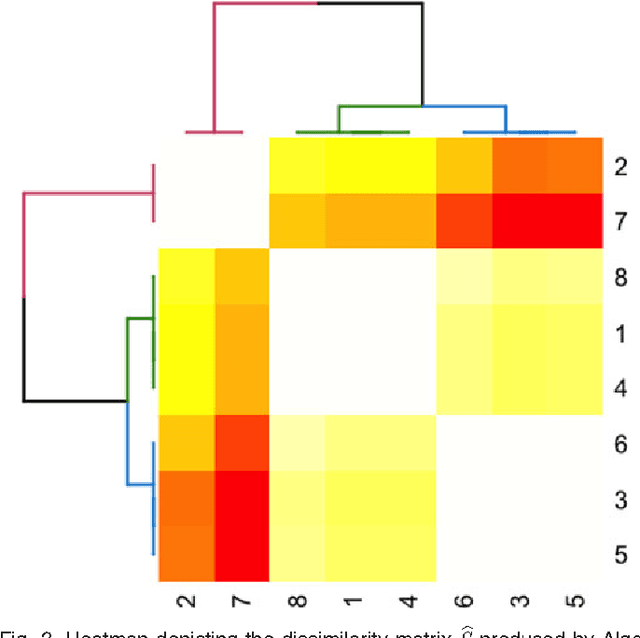
We propose a robust, scalable, integrated methodology for community detection and community comparison in graphs. In our procedure, we first embed a graph into an appropriate Euclidean space to obtain a low-dimensional representation, and then cluster the vertices into communities. We next employ nonparametric graph inference techniques to identify structural similarity among these communities. These two steps are then applied recursively on the communities, allowing us to detect more fine-grained structure. We describe a hierarchical stochastic blockmodel---namely, a stochastic blockmodel with a natural hierarchical structure---and establish conditions under which our algorithm yields consistent estimates of model parameters and motifs, which we define to be stochastically similar groups of subgraphs. Finally, we demonstrate the effectiveness of our algorithm in both simulated and real data. Specifically, we address the problem of locating similar subcommunities in a partially reconstructed Drosophila connectome and in the social network Friendster.
Spectral Clustering for Divide-and-Conquer Graph Matching
Mar 12, 2015We present a parallelized bijective graph matching algorithm that leverages seeds and is designed to match very large graphs. Our algorithm combines spectral graph embedding with existing state-of-the-art seeded graph matching procedures. We justify our approach by proving that modestly correlated, large stochastic block model random graphs are correctly matched utilizing very few seeds through our divide-and-conquer procedure. We also demonstrate the effectiveness of our approach in matching very large graphs in simulated and real data examples, showing up to a factor of 8 improvement in runtime with minimal sacrifice in accuracy.
On the Incommensurability Phenomenon
Feb 06, 2015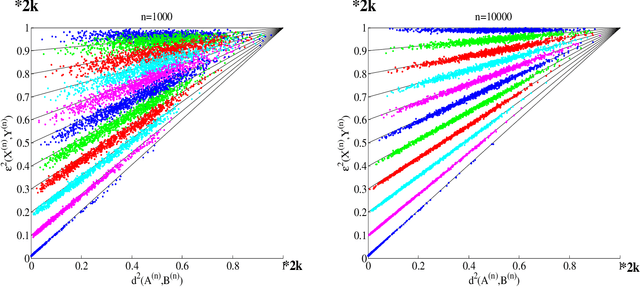
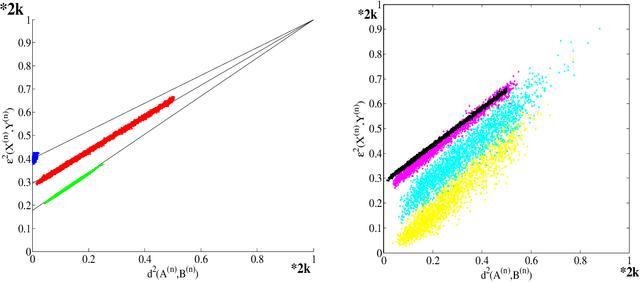
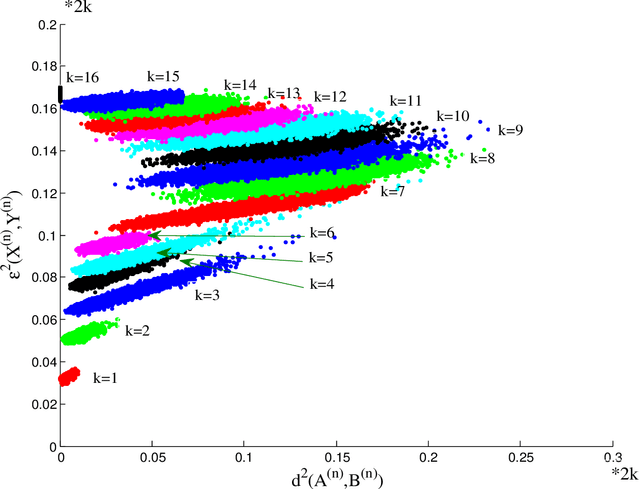
Suppose that two large, multi-dimensional data sets are each noisy measurements of the same underlying random process, and principle components analysis is performed separately on the data sets to reduce their dimensionality. In some circumstances it may happen that the two lower-dimensional data sets have an inordinately large Procrustean fitting-error between them. The purpose of this manuscript is to quantify this "incommensurability phenomenon." In particular, under specified conditions, the square Procrustean fitting-error of the two normalized lower-dimensional data sets is (asymptotically) a convex combination (via a correlation parameter) of the Hausdorff distance between the projection subspaces and the maximum possible value of the square Procrustean fitting-error for normalized data. We show how this gives rise to the incommensurability phenomenon, and we employ illustrative simulations as well as a real data experiment to explore how the incommensurability phenomenon may have an appreciable impact.
Techniques for clustering interaction data as a collection of graphs
Jan 10, 2015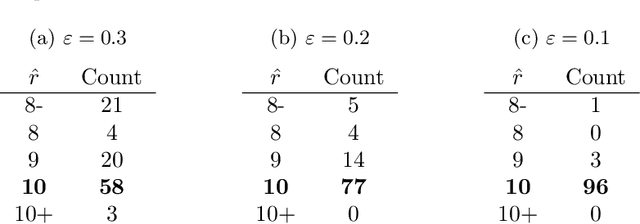

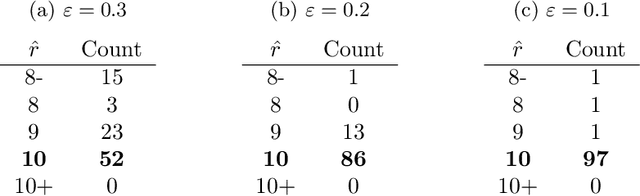

A natural approach to analyze interaction data of form "what-connects-to-what-when" is to create a time-series (or rather a sequence) of graphs through temporal discretization (bandwidth selection) and spatial discretization (vertex contraction). Such discretization together with non-negative factorization techniques can be useful for obtaining clustering of graphs. Motivating application of performing clustering of graphs (as opposed to vertex clustering) can be found in neuroscience and in social network analysis, and it can also be used to enhance community detection (i.e., vertex clustering) by way of conditioning on the cluster labels. In this paper, we formulate a problem of clustering of graphs as a model selection problem. Our approach involves information criteria, non-negative matrix factorization and singular value thresholding, and we illustrate our techniques using real and simulated data.
Automatic Dimension Selection for a Non-negative Factorization Approach to Clustering Multiple Random Graphs
Sep 09, 2014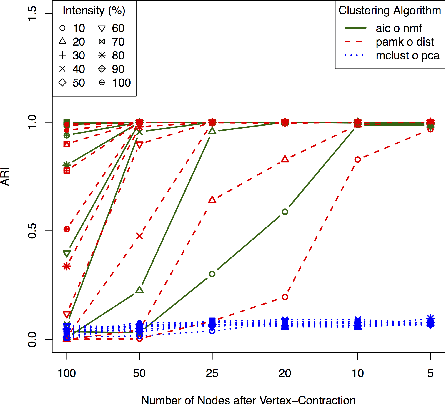
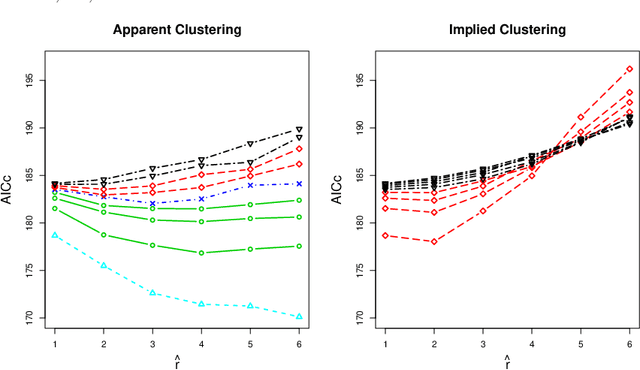
We consider a problem of grouping multiple graphs into several clusters using singular value thesholding and non-negative factorization. We derive a model selection information criterion to estimate the number of clusters. We demonstrate our approach using "Swimmer data set" as well as simulated data set, and compare its performance with two standard clustering algorithms.
Seeded Graph Matching Via Joint Optimization of Fidelity and Commensurability
Jan 16, 2014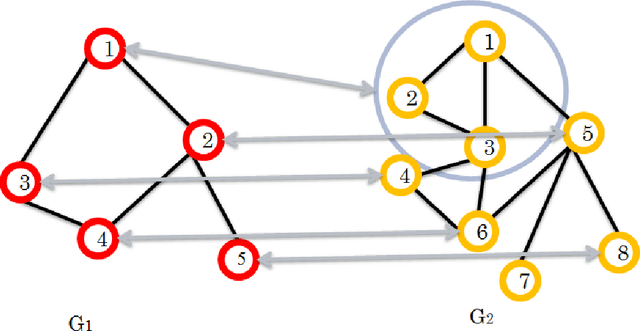
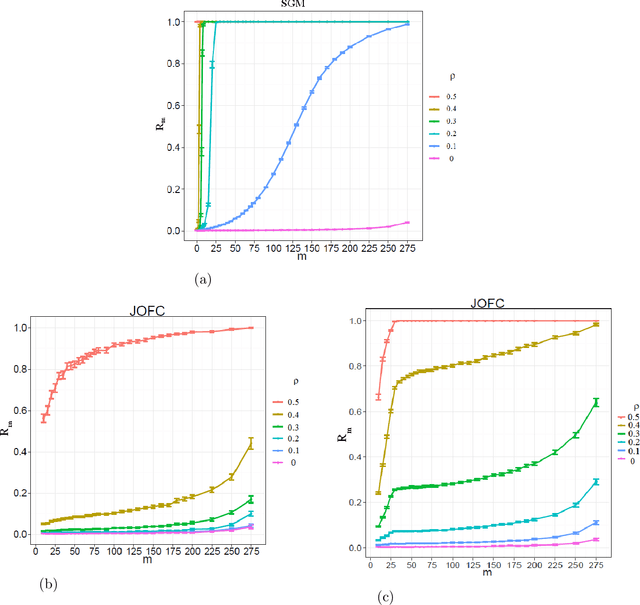
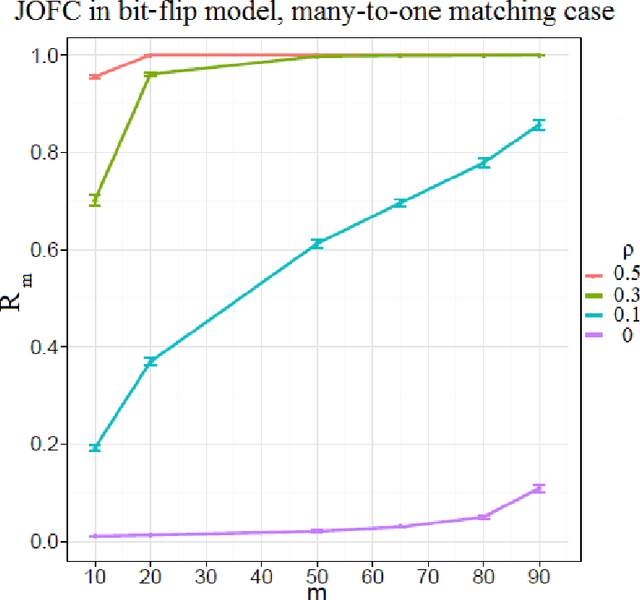
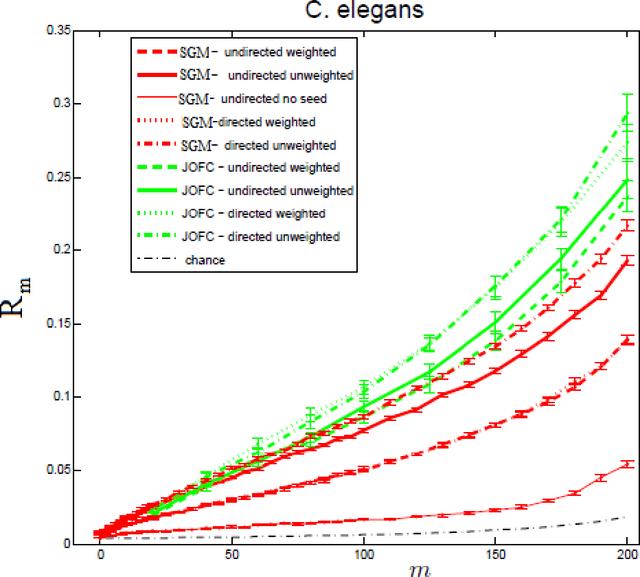
We present a novel approximate graph matching algorithm that incorporates seeded data into the graph matching paradigm. Our Joint Optimization of Fidelity and Commensurability (JOFC) algorithm embeds two graphs into a common Euclidean space where the matching inference task can be performed. Through real and simulated data examples, we demonstrate the versatility of our algorithm in matching graphs with various characteristics--weightedness, directedness, loopiness, many-to-one and many-to-many matchings, and soft seedings.
Out-of-sample Extension for Latent Position Graphs
May 21, 2013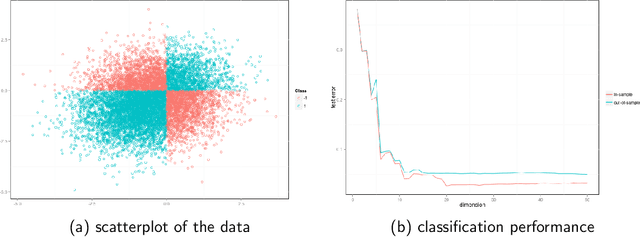
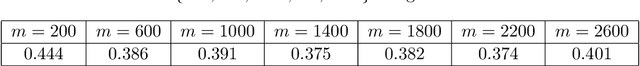
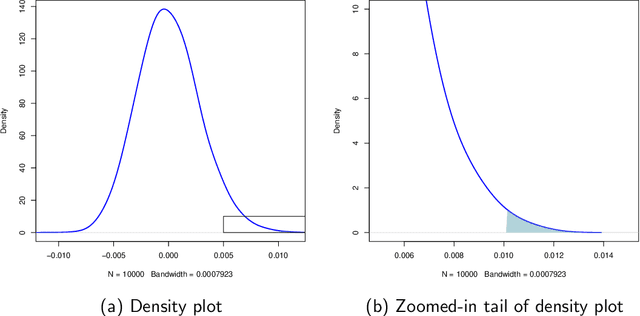
We consider the problem of vertex classification for graphs constructed from the latent position model. It was shown previously that the approach of embedding the graphs into some Euclidean space followed by classification in that space can yields a universally consistent vertex classifier. However, a major technical difficulty of the approach arises when classifying unlabeled out-of-sample vertices without including them in the embedding stage. In this paper, we studied the out-of-sample extension for the graph embedding step and its impact on the subsequent inference tasks. We show that, under the latent position graph model and for sufficiently large $n$, the mapping of the out-of-sample vertices is close to its true latent position. We then demonstrate that successful inference for the out-of-sample vertices is possible.
Anomaly Detection in Time Series of Graphs using Fusion of Graph Invariants
Oct 31, 2012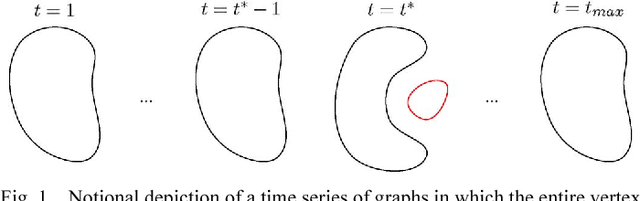
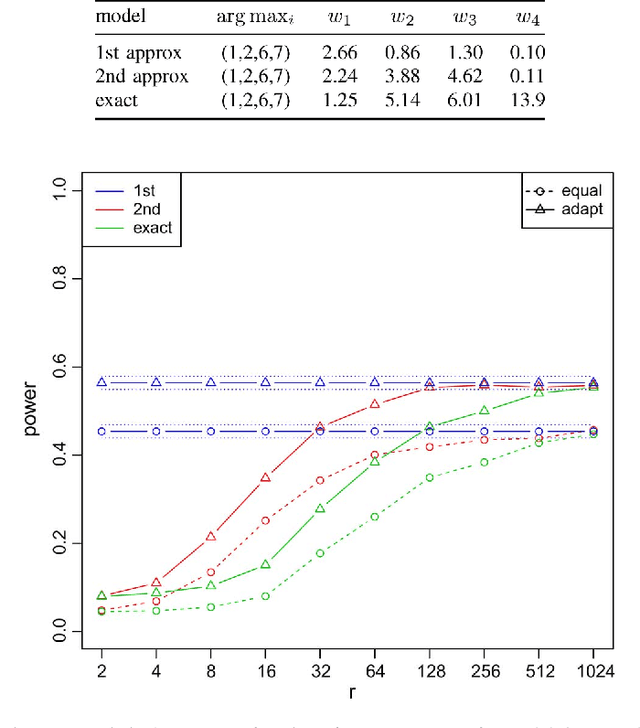
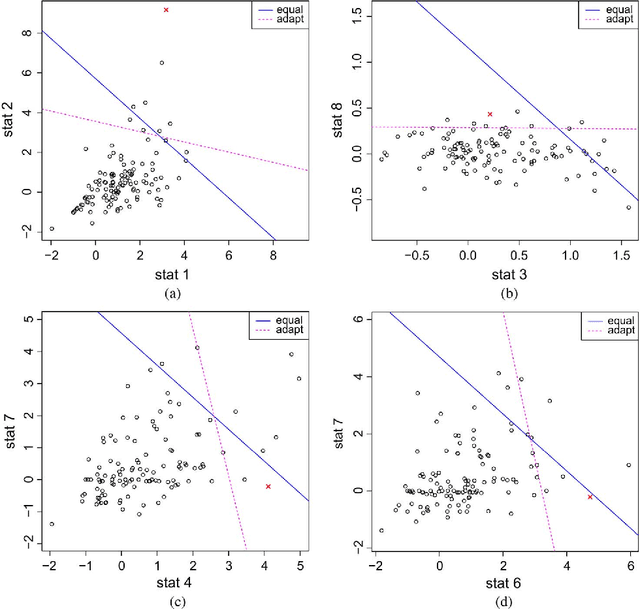
Given a time series of graphs G(t) = (V, E(t)), t = 1, 2, ..., where the fixed vertex set V represents "actors" and an edge between vertex u and vertex v at time t (uv \in E(t)) represents the existence of a communications event between actors u and v during the tth time period, we wish to detect anomalies and/or change points. We consider a collection of graph features, or invariants, and demonstrate that adaptive fusion provides superior inferential efficacy compared to naive equal weighting for a certain class of anomaly detection problems. Simulation results using a latent process model for time series of graphs, as well as illustrative experimental results for a time series of graphs derived from the Enron email data, show that a fusion statistic can provide superior inference compared to individual invariants alone. These results also demonstrate that an adaptive weighting scheme for fusion of invariants performs better than naive equal weighting.