 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Decision-driven Methodology for Designing Uncertainty-aware AI Self-Assessment
Aug 02, 2024Artificial intelligence (AI) has revolutionized decision-making processes and systems throughout society and, in particular, has emerged as a significant technology in high-impact scenarios of national interest. Yet, despite AI's impressive predictive capabilities in controlled settings, it still suffers from a range of practical setbacks preventing its widespread use in various critical scenarios. In particular, it is generally unclear if a given AI system's predictions can be trusted by decision-makers in downstream applications. To address the need for more transparent, robust, and trustworthy AI systems, a suite of tools has been developed to quantify the uncertainty of AI predictions and, more generally, enable AI to "self-assess" the reliability of its predictions. In this manuscript, we categorize methods for AI self-assessment along several key dimensions and provide guidelines for selecting and designing the appropriate method for a practitioner's needs. In particular, we focus on uncertainty estimation techniques that consider the impact of self-assessment on the choices made by downstream decision-makers and on the resulting costs and benefits of decision outcomes. To demonstrate the utility of our methodology for self-assessment design, we illustrate its use for two realistic national-interest scenarios. This manuscript is a practical guide for machine learning engineers and AI system users to select the ideal self-assessment techniques for each problem.
Exploiting Large Neuroimaging Datasets to Create Connectome-Constrained Approaches for more Robust, Efficient, and Adaptable Artificial Intelligence
May 26, 2023Despite the progress in deep learning networks, efficient learning at the edge (enabling adaptable, low-complexity machine learning solutions) remains a critical need for defense and commercial applications. We envision a pipeline to utilize large neuroimaging datasets, including maps of the brain which capture neuron and synapse connectivity, to improve machine learning approaches. We have pursued different approaches within this pipeline structure. First, as a demonstration of data-driven discovery, the team has developed a technique for discovery of repeated subcircuits, or motifs. These were incorporated into a neural architecture search approach to evolve network architectures. Second, we have conducted analysis of the heading direction circuit in the fruit fly, which performs fusion of visual and angular velocity features, to explore augmenting existing computational models with new insight. Our team discovered a novel pattern of connectivity, implemented a new model, and demonstrated sensor fusion on a robotic platform. Third, the team analyzed circuitry for memory formation in the fruit fly connectome, enabling the design of a novel generative replay approach. Finally, the team has begun analysis of connectivity in mammalian cortex to explore potential improvements to transformer networks. These constraints increased network robustness on the most challenging examples in the CIFAR-10-C computer vision robustness benchmark task, while reducing learnable attention parameters by over an order of magnitude. Taken together, these results demonstrate multiple potential approaches to utilize insight from neural systems for developing robust and efficient machine learning techniques.
A Risk-Sensitive Approach to Policy Optimization
Aug 19, 2022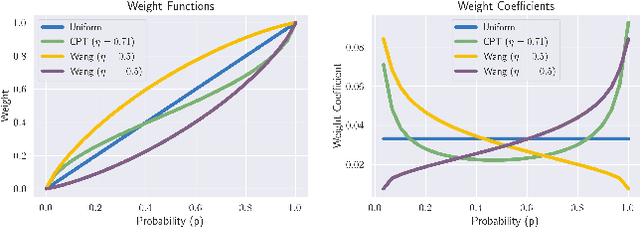
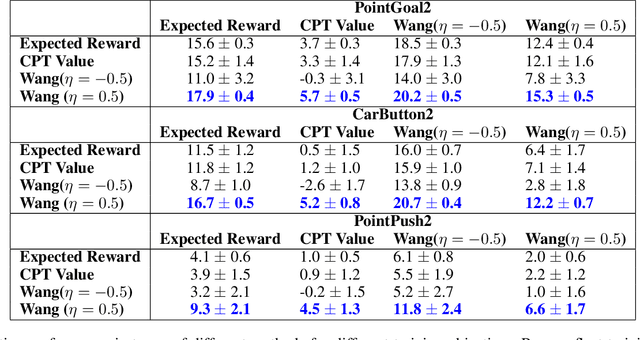
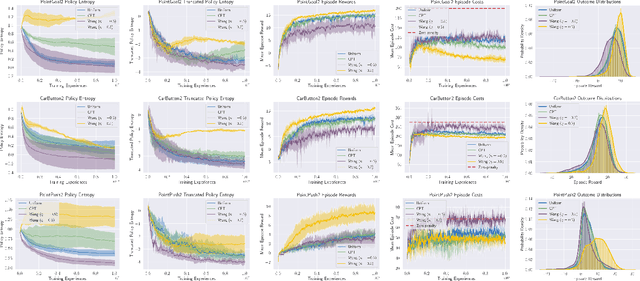
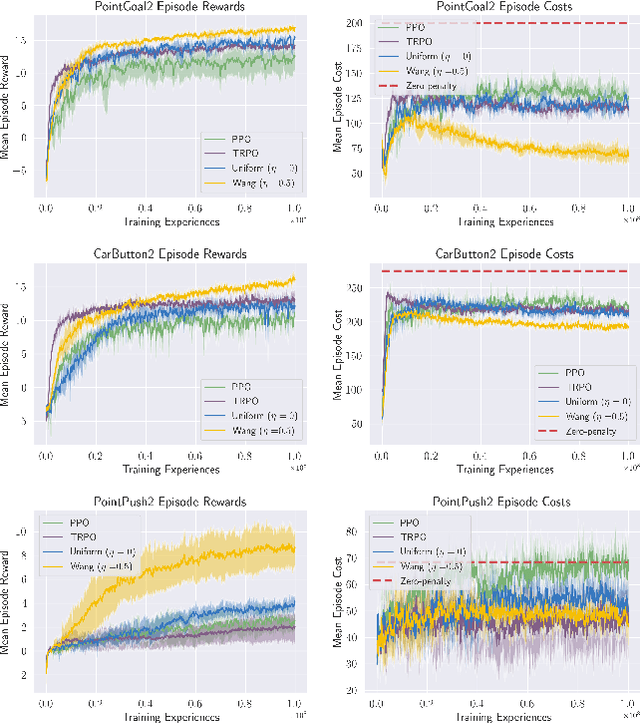
Standard deep reinforcement learning (DRL) aims to maximize expected reward, considering collected experiences equally in formulating a policy. This differs from human decision-making, where gains and losses are valued differently and outlying outcomes are given increased consideration. It also fails to capitalize on opportunities to improve safety and/or performance through the incorporation of distributional context. Several approaches to distributional DRL have been investigated, with one popular strategy being to evaluate the projected distribution of returns for possible actions. We propose a more direct approach whereby risk-sensitive objectives, specified in terms of the cumulative distribution function (CDF) of the distribution of full-episode rewards, are optimized. This approach allows for outcomes to be weighed based on relative quality, can be used for both continuous and discrete action spaces, and may naturally be applied in both constrained and unconstrained settings. We show how to compute an asymptotically consistent estimate of the policy gradient for a broad class of risk-sensitive objectives via sampling, subsequently incorporating variance reduction and regularization measures to facilitate effective on-policy learning. We then demonstrate that the use of moderately "pessimistic" risk profiles, which emphasize scenarios where the agent performs poorly, leads to enhanced exploration and a continual focus on addressing deficiencies. We test the approach using different risk profiles in six OpenAI Safety Gym environments, comparing to state of the art on-policy methods. Without cost constraints, we find that pessimistic risk profiles can be used to reduce cost while improving total reward accumulation. With cost constraints, they are seen to provide higher positive rewards than risk-neutral approaches at the prescribed allowable cost.
Out-of-Distribution Robustness with Deep Recursive Filters
Apr 06, 2021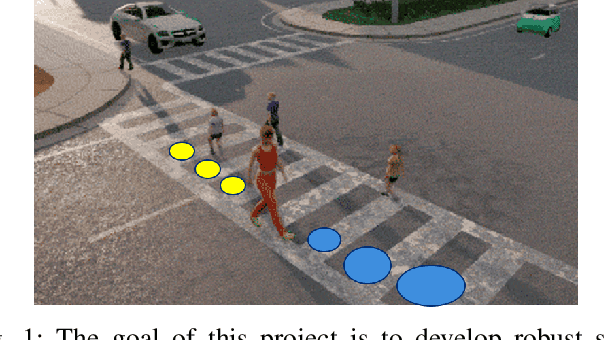
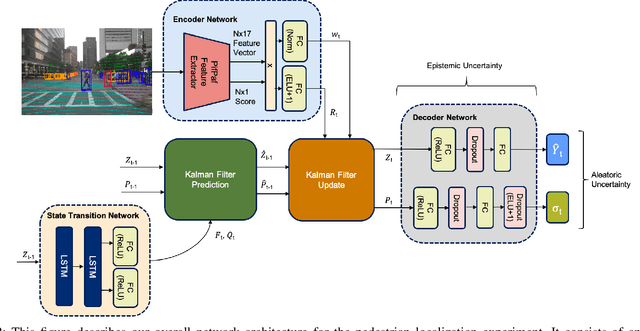
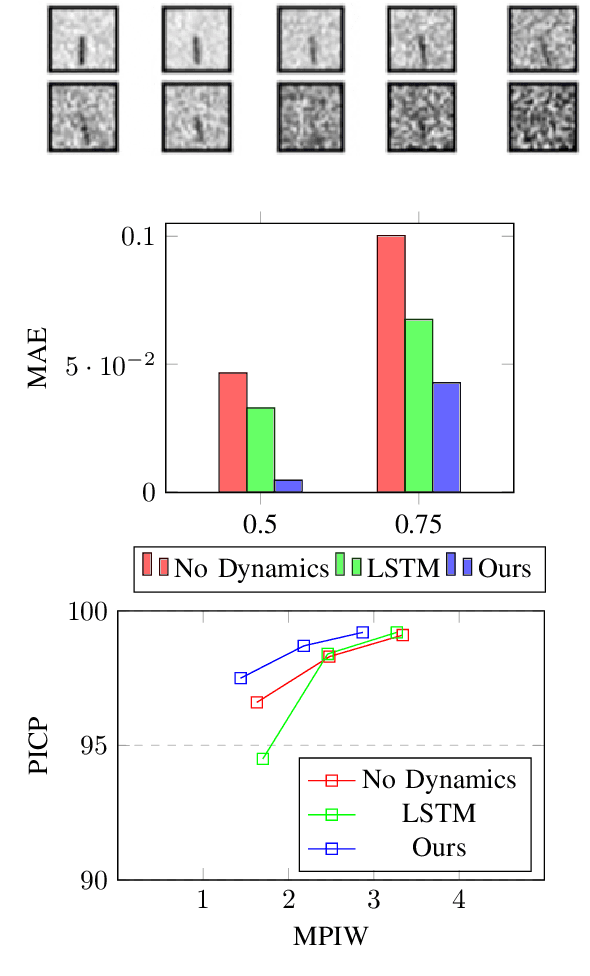
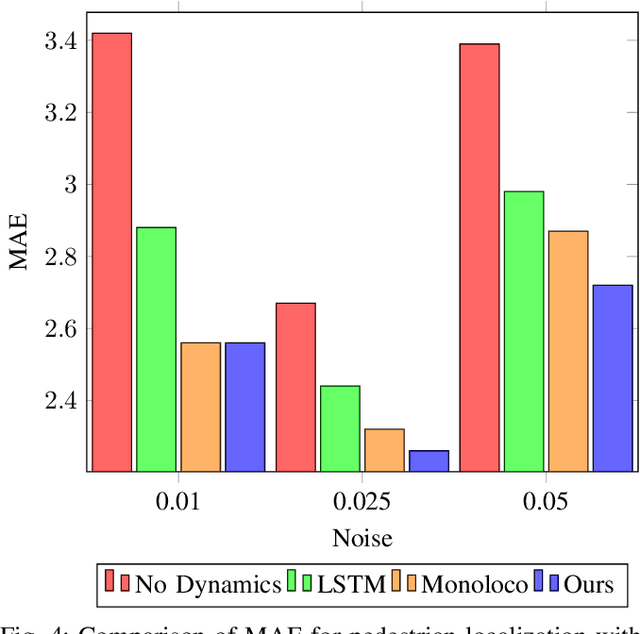
Accurate state and uncertainty estimation is imperative for mobile robots and self driving vehicles to achieve safe navigation in pedestrian rich environments. A critical component of state and uncertainty estimation for robot navigation is to perform robustly under out-of-distribution noise. Traditional methods of state estimation decouple perception and state estimation making it difficult to operate on noisy, high dimensional data. Here, we describe an approach that combines the expressiveness of deep neural networks with principled approaches to uncertainty estimation found in recursive filters. We particularly focus on techniques that provide better robustness to out-of-distribution noise and demonstrate applicability of our approach on two scenarios: a simple noisy pendulum state estimation problem and real world pedestrian localization using the nuScenes dataset. We show that our approach improves state and uncertainty estimation compared to baselines while achieving approximately 3x improvement in computational efficiency.
Group-Aware Robot Navigation in Crowded Environments
Dec 22, 2020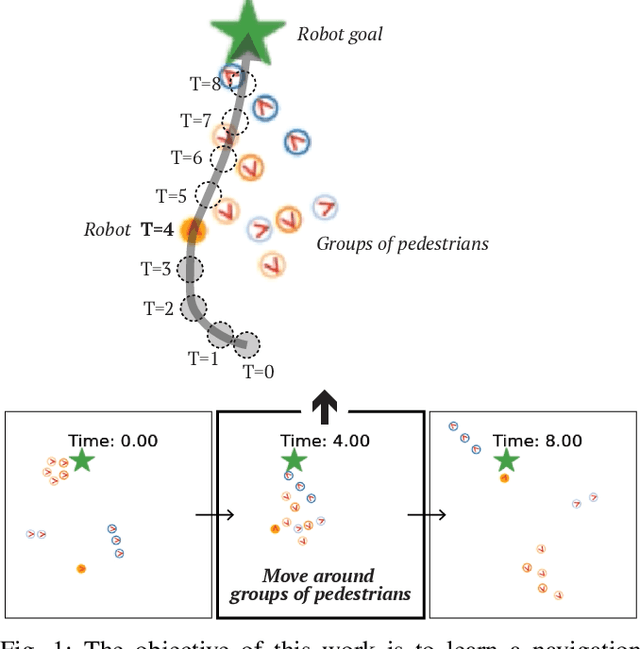

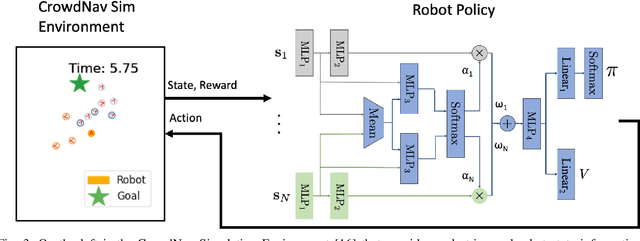
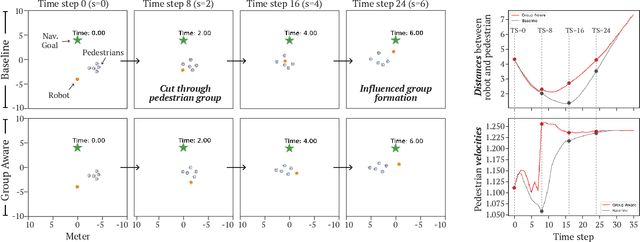
Human-aware robot navigation promises a range of applications in which mobile robots bring versatile assistance to people in common human environments. While prior research has mostly focused on modeling pedestrians as independent, intentional individuals, people move in groups; consequently, it is imperative for mobile robots to respect human groups when navigating around people. This paper explores learning group-aware navigation policies based on dynamic group formation using deep reinforcement learning. Through simulation experiments, we show that group-aware policies, compared to baseline policies that neglect human groups, achieve greater robot navigation performance (e.g., fewer collisions), minimize violation of social norms and discomfort, and reduce the robot's movement impact on pedestrians. Our results contribute to the development of social navigation and the integration of mobile robots into human environments.
Jacks of All Trades, Masters Of None: Addressing Distributional Shift and Obtrusiveness via Transparent Patch Attacks
May 01, 2020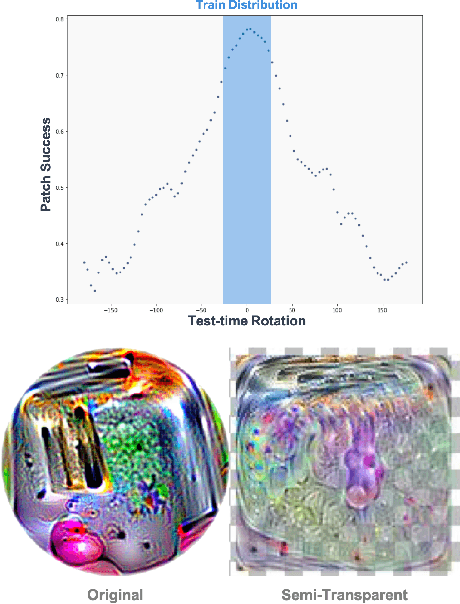
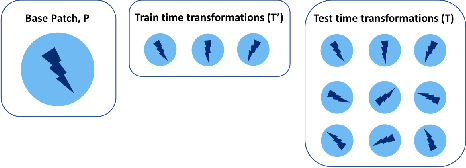
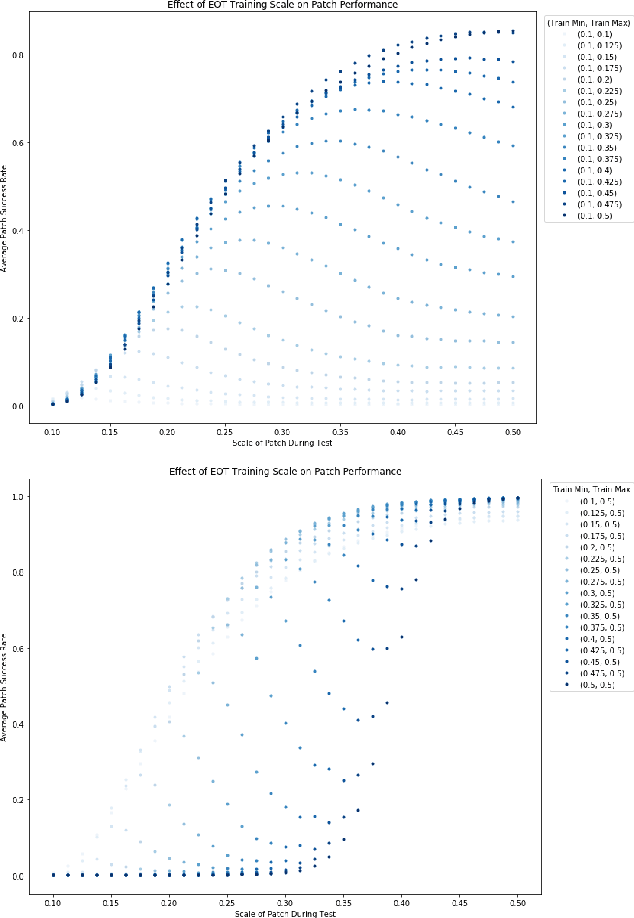
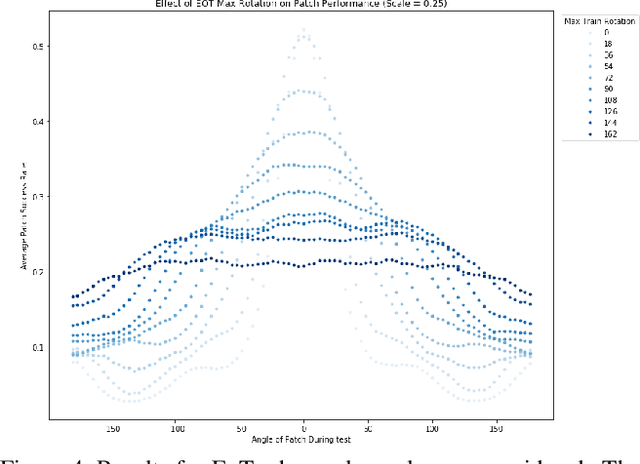
We focus on the development of effective adversarial patch attacks and -- for the first time -- jointly address the antagonistic objectives of attack success and obtrusiveness via the design of novel semi-transparent patches. This work is motivated by our pursuit of a systematic performance analysis of patch attack robustness with regard to geometric transformations. Specifically, we first elucidate a) key factors underpinning patch attack success and b) the impact of distributional shift between training and testing/deployment when cast under the Expectation over Transformation (EoT) formalism. By focusing our analysis on three principal classes of transformations (rotation, scale, and location), our findings provide quantifiable insights into the design of effective patch attacks and demonstrate that scale, among all factors, significantly impacts patch attack success. Working from these findings, we then focus on addressing how to overcome the principal limitations of scale for the deployment of attacks in real physical settings: namely the obtrusiveness of large patches. Our strategy is to turn to the novel design of irregularly-shaped, semi-transparent partial patches which we construct via a new optimization process that jointly addresses the antagonistic goals of mitigating obtrusiveness and maximizing effectiveness. Our study -- we hope -- will help encourage more focus in the community on the issues of obtrusiveness, scale, and success in patch attacks.
TanksWorld: A Multi-Agent Environment for AI Safety Research
Feb 25, 2020

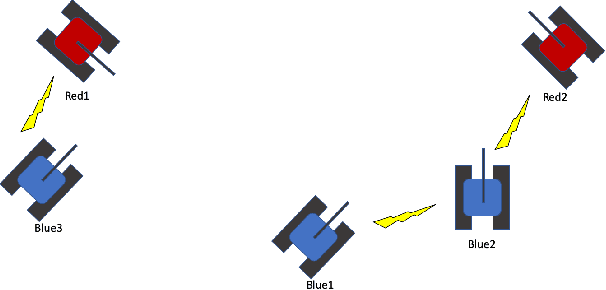
The ability to create artificial intelligence (AI) capable of performing complex tasks is rapidly outpacing our ability to ensure the safe and assured operation of AI-enabled systems. Fortunately, a landscape of AI safety research is emerging in response to this asymmetry and yet there is a long way to go. In particular, recent simulation environments created to illustrate AI safety risks are relatively simple or narrowly-focused on a particular issue. Hence, we see a critical need for AI safety research environments that abstract essential aspects of complex real-world applications. In this work, we introduce the AI safety TanksWorld as an environment for AI safety research with three essential aspects: competing performance objectives, human-machine teaming, and multi-agent competition. The AI safety TanksWorld aims to accelerate the advancement of safe multi-agent decision-making algorithms by providing a software framework to support competitions with both system performance and safety objectives. As a work in progress, this paper introduces our research objectives and learning environment with reference code and baseline performance metrics to follow in a future work.
Unsupervised Semantic Attribute Discovery and Control in Generative Models
Feb 25, 2020
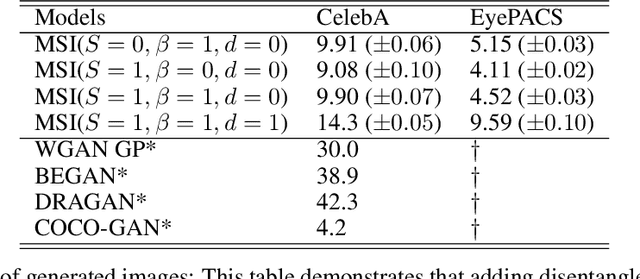
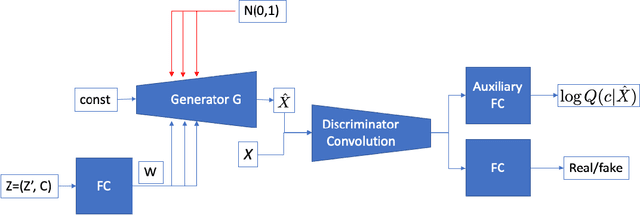

This work focuses on the ability to control via latent space factors semantic image attributes in generative models, and the faculty to discover mappings from factors to attributes in an unsupervised fashion. The discovery of controllable semantic attributes is of special importance, as it would facilitate higher level tasks such as unsupervised representation learning to improve anomaly detection, or the controlled generation of novel data for domain shift and imbalanced datasets. The ability to control semantic attributes is related to the disentanglement of latent factors, which dictates that latent factors be "uncorrelated" in their effects. Unfortunately, despite past progress, the connection between control and disentanglement remains, at best, confused and entangled, requiring clarifications we hope to provide in this work. To this end, we study the design of algorithms for image generation that allow unsupervised discovery and control of semantic attributes.We make several contributions: a) We bring order to the concepts of control and disentanglement, by providing an analytical derivation that connects mutual information maximization, which promotes attribute control, to total correlation minimization, which relates to disentanglement. b) We propose hybrid generative model architectures that use mutual information maximization with multi-scale style transfer. c) We introduce a novel metric to characterize the performance of semantic attributes control. We report experiments that appear to demonstrate, quantitatively and qualitatively, the ability of the proposed model to perform satisfactory control while still preserving competitive visual quality. We compare to other state of the art methods (e.g., Frechet inception distance (FID)= 9.90 on CelebA and 4.52 on EyePACS).
Adversarial Examples in Remote Sensing
May 28, 2018
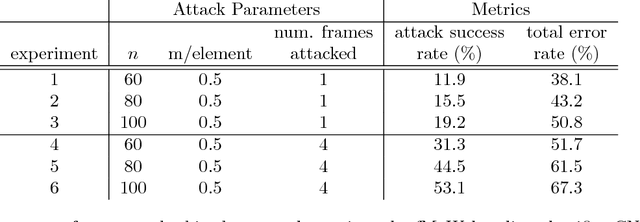
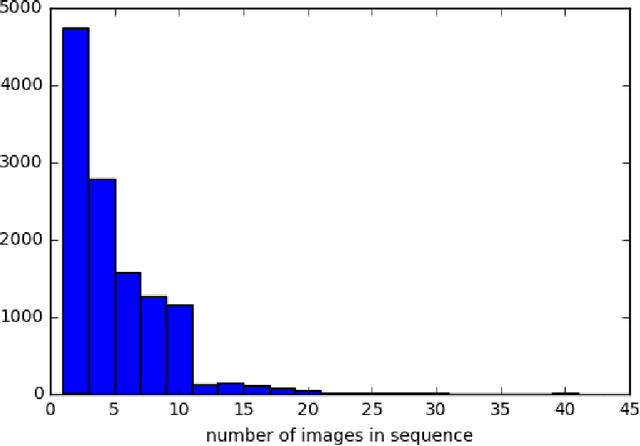
This paper considers attacks against machine learning algorithms used in remote sensing applications, a domain that presents a suite of challenges that are not fully addressed by current research focused on natural image data such as ImageNet. In particular, we present a new study of adversarial examples in the context of satellite image classification problems. Using a recently curated data set and associated classifier, we provide a preliminary analysis of adversarial examples in settings where the targeted classifier is permitted multiple observations of the same location over time. While our experiments to date are purely digital, our problem setup explicitly incorporates a number of practical considerations that a real-world attacker would need to take into account when mounting a physical attack. We hope this work provides a useful starting point for future studies of potential vulnerabilities in this setting.
Combining Deep Universal Features, Semantic Attributes, and Hierarchical Classification for Zero-Shot Learning
Dec 08, 2017
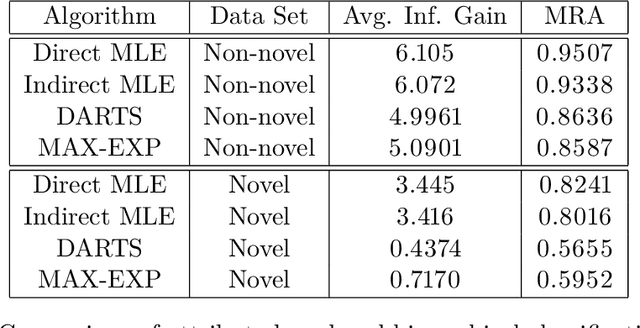
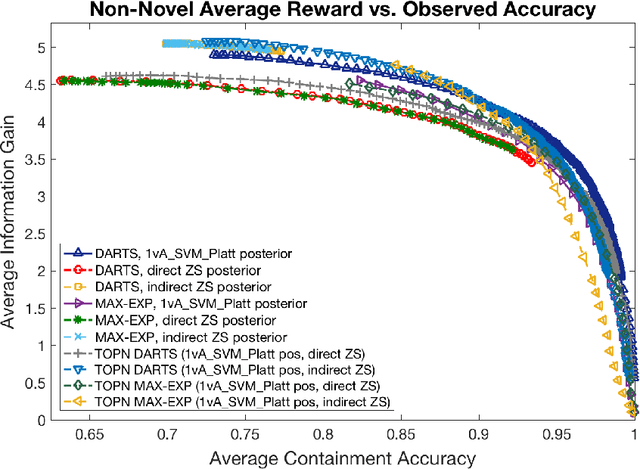
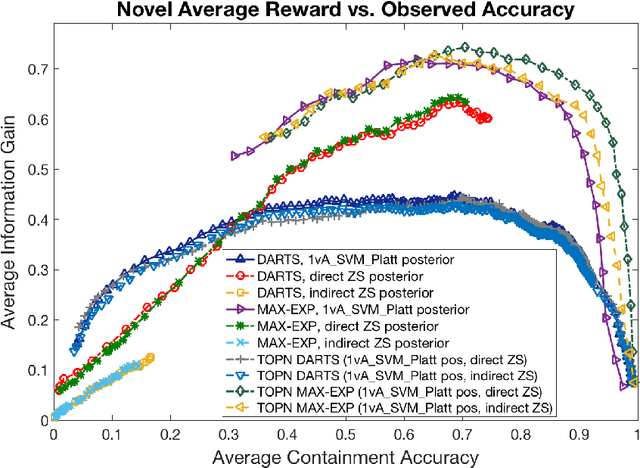
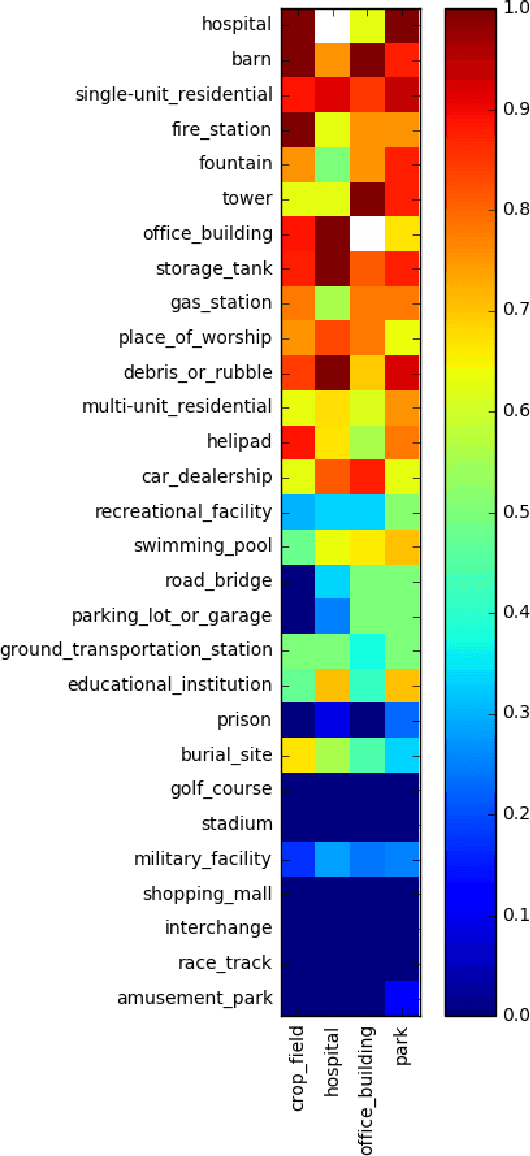
We address zero-shot (ZS) learning, building upon prior work in hierarchical classification by combining it with approaches based on semantic attribute estimation. For both non-novel and novel image classes we compare multiple formulations of the problem, starting with deep universal features in each case. We investigate the effect of using different posterior probabilities as inputs to the hierarchical classifier, comparing the performances of posteriors derived from distances to SVM classifier boundaries with those of posteriors based on semantic attribute estimation. Using a dataset consisting of 150 object classes from the ImageNet ILSVRC2012 data set, we find that the hierarchical classification method that maximizes expected reward for non-novel classes differs from the method that maximizes expected reward for novel classes. We also show that using input posteriors based on semantic attributes improves the expected reward for novel classes.