 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfoBot: Transfer and Exploration via the Information Bottleneck
Apr 04, 2019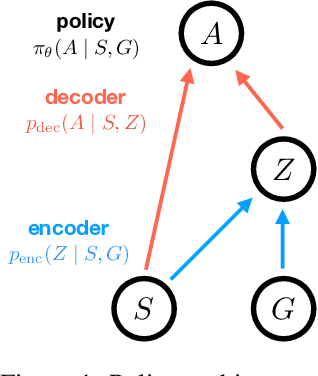



A central challenge in reinforcement learning is discovering effective policies for tasks where rewards are sparsely distributed. We postulate that in the absence of useful reward signals, an effective exploration strategy should seek out {\it decision states}. These states lie at critical junctions in the state space from where the agent can transition to new, potentially unexplored regions. We propose to learn about decision states from prior experience. By training a goal-conditioned policy with an information bottleneck, we can identify decision states by examining where the model actually leverages the goal state. We find that this simple mechanism effectively identifies decision states, even in partially observed settings. In effect, the model learns the sensory cues that correlate with potential subgoals. In new environments, this model can then identify novel subgoals for further exploration, guiding the agent through a sequence of potential decision states and through new regions of the state space.
Wasserstein Dependency Measure for Representation Learning
Mar 28, 2019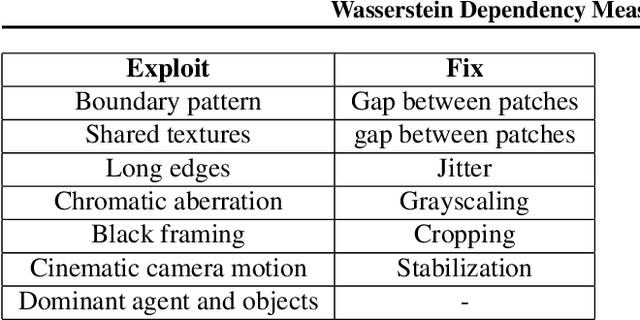
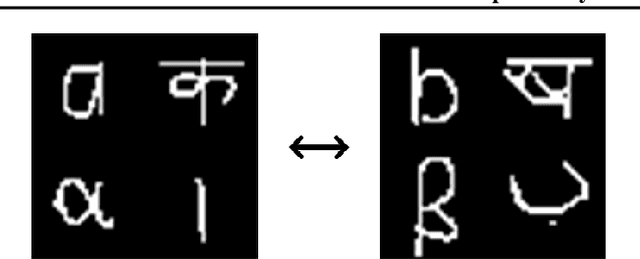

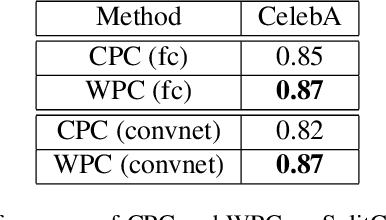
Mutual information maximization has emerged as a powerful learning objective for unsupervised representation learning obtaining state-of-the-art performance in applications such as object recognition, speech recognition, and reinforcement learning. However, such approaches are fundamentally limited since a tight lower bound of mutual information requires sample size exponential in the mutual information. This limits the applicability of these approaches for prediction tasks with high mutual information, such as in video understanding or reinforcement learning. In these settings, such techniques are prone to overfit, both in theory and in practice, and capture only a few of the relevant factors of variation. This leads to incomplete representations that are not optimal for downstream tasks. In this work, we empirically demonstrate that mutual information-based representation learning approaches do fail to learn complete representations on a number of designed and real-world tasks. To mitigate these problems we introduce the Wasserstein dependency measure, which learns more complete representations by using the Wasserstein distance instead of the KL divergence in the mutual information estimator. We show that a practical approximation to this theoretically motivated solution, constructed using Lipschitz constraint techniques from the GAN literature, achieves substantially improved results on tasks where incomplete representations are a major challenge.
InfoMask: Masked Variational Latent Representation to Localize Chest Disease
Mar 28, 2019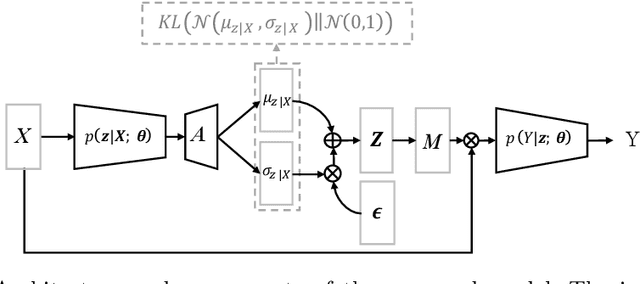
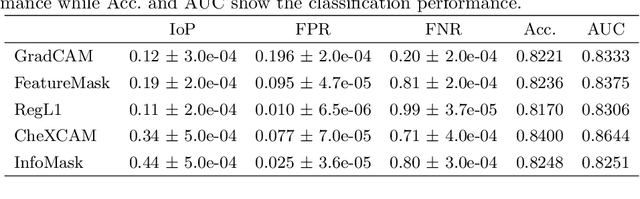
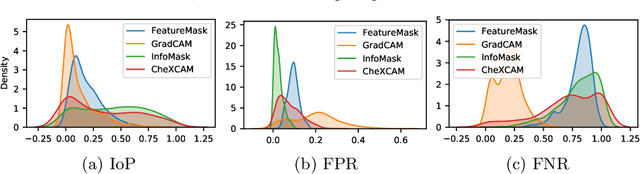
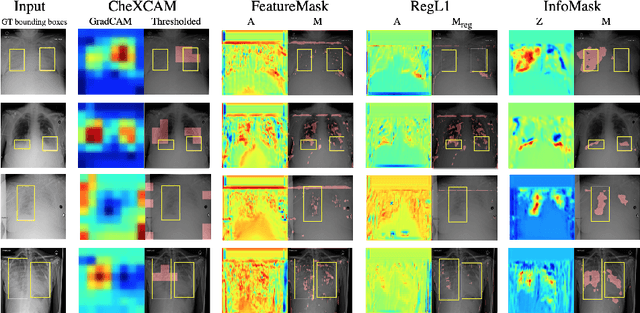
The scarcity of richly annotated medical images is limiting supervised deep learning based solutions to medical image analysis tasks, such as localizing discriminatory radiomic disease signatures. Therefore, it is desirable to leverage unsupervised and weakly supervised models. Most recent weakly supervised localization methods apply attention maps or region proposals in a multiple instance learning formulation. While attention maps can be noisy, leading to erroneously highlighted regions, it is not simple to decide on an optimal window/bag size for multiple instance learning approaches. In this paper, we propose a learned spatial masking mechanism to filter out irrelevant background signals from attention maps. The proposed method minimizes mutual information between a masked variational representation and the input while maximizing the information between the masked representation and class labels. This results in more accurate localization of discriminatory regions. We tested the proposed model on the ChestX-ray8 dataset to localize pneumonia from chest X-ray images without using any pixel-level or bounding-box annotations.
Online continual learning with no task boundaries
Mar 22, 2019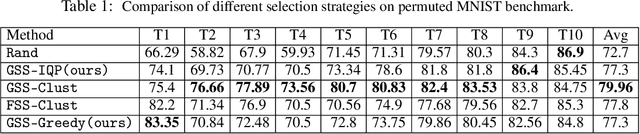

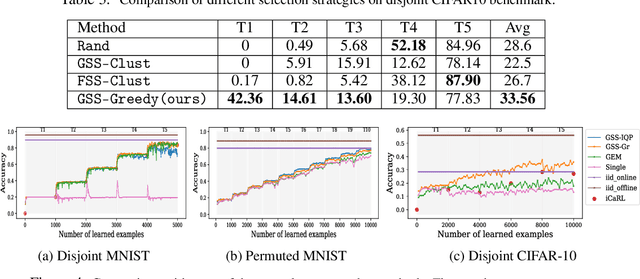
Continual learning is the ability of an agent to learn online with a non-stationary and never-ending stream of data. A key component for such never-ending learning process is to overcome the catastrophic forgetting of previously seen data, a problem that neural networks are well known to suffer from. The solutions developed so far often relax the problem of continual learning to the easier task-incremental setting, where the stream of data is divided into tasks with clear boundaries. In this paper, we break the limits and move to the more challenging online setting where we assume no information of tasks in the data stream. We start from the idea that each learning step should not increase the losses of the previously learned examples through constraining the optimization process. This means that the number of constraints grows linearly with the number of examples, which is a serious limitation. We develop a solution to select a fixed number of constraints that we use to approximate the feasible region defined by the original constraints. We compare our approach against the methods that rely on task boundaries to select a fixed set of examples, and show comparable or even better results, especially when the boundaries are blurry or when the data distributions are imbalanced.
Towards Standardization of Data Licenses: The Montreal Data License
Mar 21, 2019This paper provides a taxonomy for the licensing of data in the fields of artificial intelligence and machine learning. The paper's goal is to build towards a common framework for data licensing akin to the licensing of open source software. Increased transparency and resolving conceptual ambiguities in existing licensing language are two noted benefits of the approach proposed in the paper. In parallel, such benefits may help foster fairer and more efficient markets for data through bringing about clearer tools and concepts that better define how data can be used in the fields of AI and ML. The paper's approach is summarized in a new family of data license language - \textit{the Montreal Data License (MDL)}. Alongside this new license, the authors and their collaborators have developed a web-based tool to generate license language espousing the taxonomies articulated in this paper.
Learning Dynamics Model in Reinforcement Learning by Incorporating the Long Term Future
Mar 16, 2019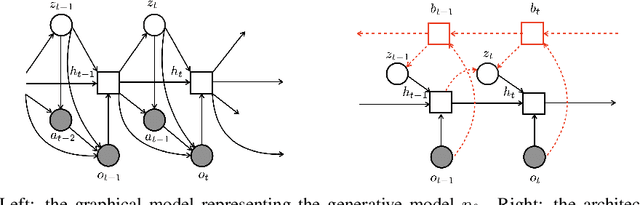
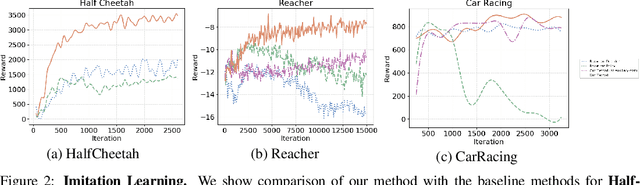
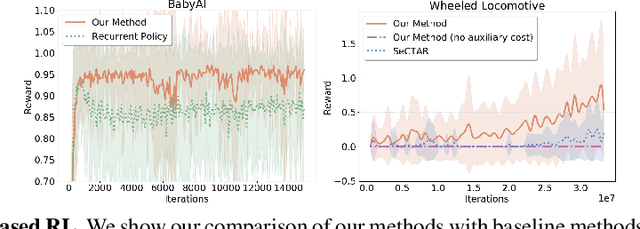
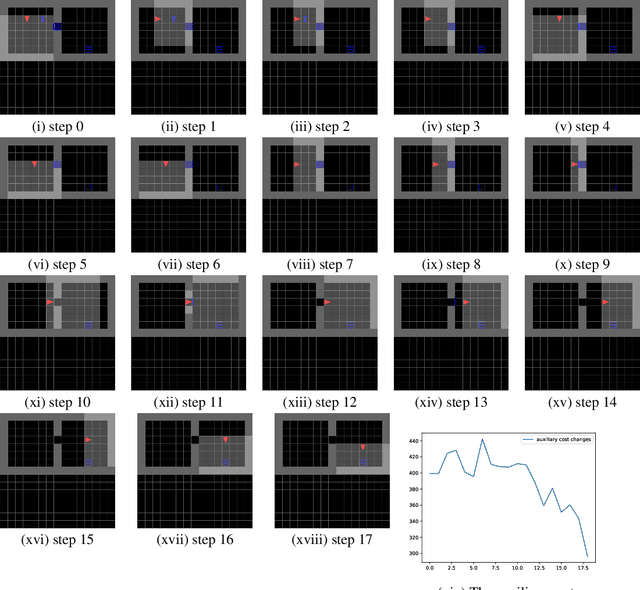
In model-based reinforcement learning, the agent interleaves between model learning and planning. These two components are inextricably intertwined. If the model is not able to provide sensible long-term prediction, the executed planner would exploit model flaws, which can yield catastrophic failures. This paper focuses on building a model that reasons about the long-term future and demonstrates how to use this for efficient planning and exploration. To this end, we build a latent-variable autoregressive model by leveraging recent ideas in variational inference. We argue that forcing latent variables to carry future information through an auxiliary task substantially improves long-term predictions. Moreover, by planning in the latent space, the planner's solution is ensured to be within regions where the model is valid. An exploration strategy can be devised by searching for unlikely trajectories under the model. Our method achieves higher reward faster compared to baselines on a variety of tasks and environments in both the imitation learning and model-based reinforcement learning settings.
Interpolation Consistency Training for Semi-Supervised Learning
Mar 09, 2019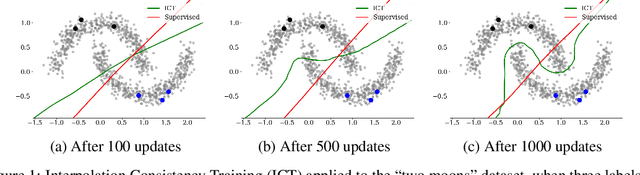
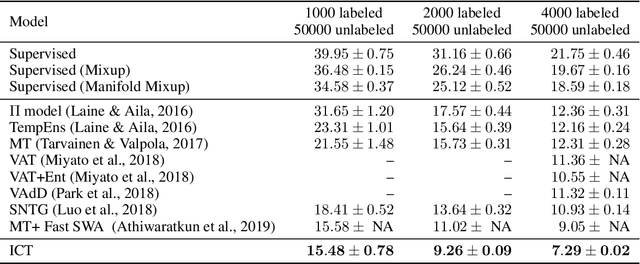
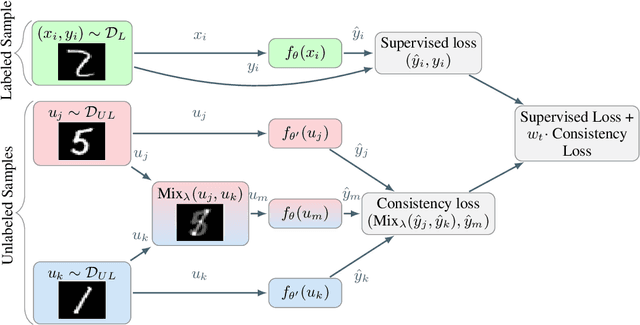
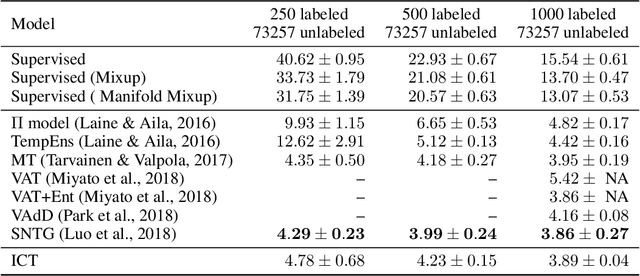
We introduce Interpolation Consistency Training (ICT), a simple and computation efficient algorithm for training Deep Neural Networks in the semi-supervised learning paradigm. ICT encourages the prediction at an interpolation of unlabeled points to be consistent with the interpolation of the predictions at those points. In classification problems, ICT moves the decision boundary to low-density regions of the data distribution. Our experiments show that ICT achieves state-of-the-art performance when applied to standard neural network architectures on the CIFAR-10 and SVHN benchmark datasets.
Hyperbolic Discounting and Learning over Multiple Horizons
Feb 28, 2019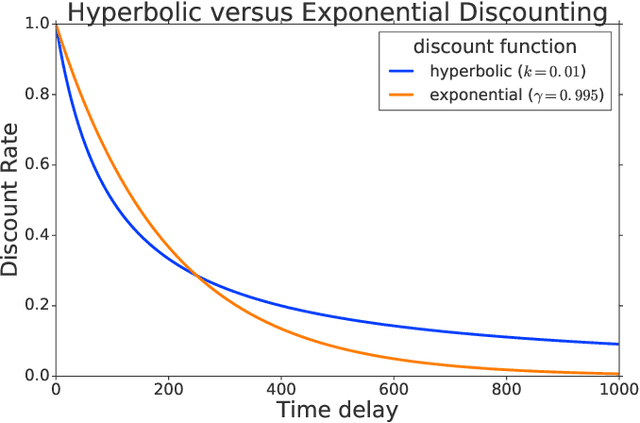

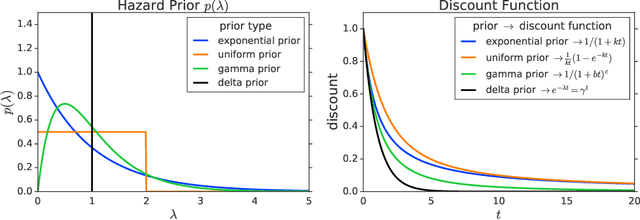
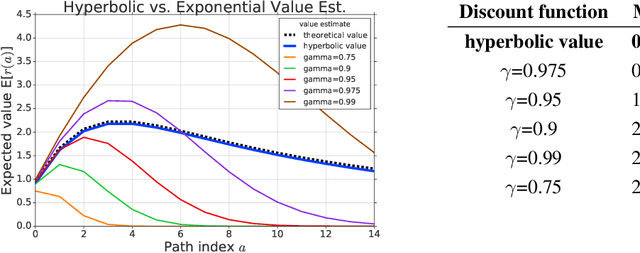
Reinforcement learning (RL) typically defines a discount factor as part of the Markov Decision Process. The discount factor values future rewards by an exponential scheme that leads to theoretical convergence guarantees of the Bellman equation. However, evidence from psychology, economics and neuroscience suggests that humans and animals instead have hyperbolic time-preferences. In this work we revisit the fundamentals of discounting in RL and bridge this disconnect by implementing an RL agent that acts via hyperbolic discounting. We demonstrate that a simple approach approximates hyperbolic discount functions while still using familiar temporal-difference learning techniques in RL. Additionally, and independent of hyperbolic discounting, we make a surprising discovery that simultaneously learning value functions over multiple time-horizons is an effective auxiliary task which often improves over a strong value-based RL agent, Rainbow.
A Meta-Transfer Objective for Learning to Disentangle Causal Mechanisms
Feb 04, 2019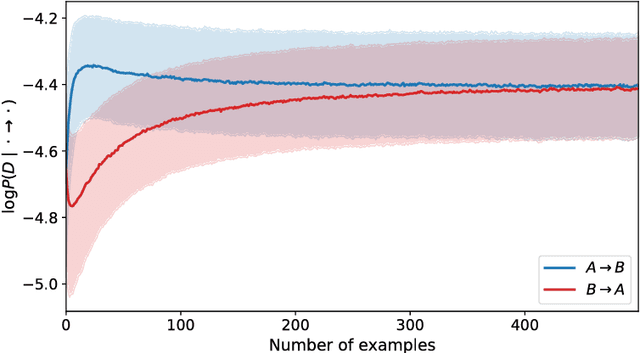

We propose to meta-learn causal structures based on how fast a learner adapts to new distributions arising from sparse distributional changes, e.g. due to interventions, actions of agents and other sources of non-stationarities. We show that under this assumption, the correct causal structural choices lead to faster adaptation to modified distributions because the changes are concentrated in one or just a few mechanisms when the learned knowledge is modularized appropriately. This leads to sparse expected gradients and a lower effective number of degrees of freedom needing to be relearned while adapting to the change. It motivates using the speed of adaptation to a modified distribution as a meta-learning objective. We demonstrate how this can be used to determine the cause-effect relationship between two observed variables. The distributional changes do not need to correspond to standard interventions (clamping a variable), and the learner has no direct knowledge of these interventions. We show that causal structures can be parameterized via continuous variables and learned end-to-end. We then explore how these ideas could be used to also learn an encoder that would map low-level observed variables to unobserved causal variables leading to faster adaptation out-of-distribution, learning a representation space where one can satisfy the assumptions of independent mechanisms and of small and sparse changes in these mechanisms due to actions and non-stationarities.
Maximum Entropy Generators for Energy-Based Models
Jan 24, 2019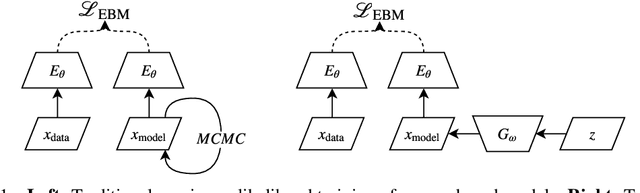
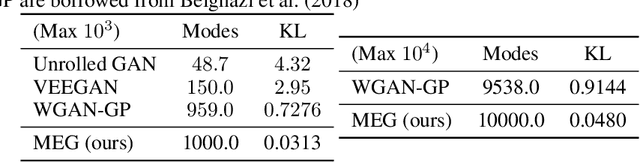
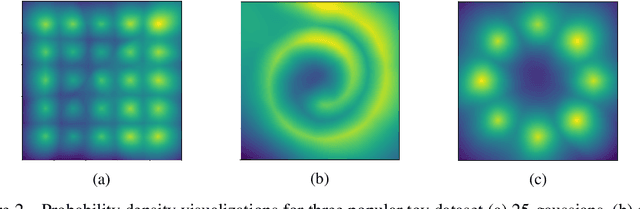
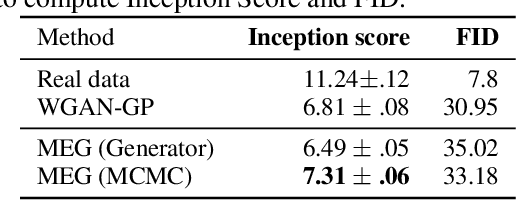
Unsupervised learning is about capturing dependencies between variables and is driven by the contrast between the probable vs. improbable configurations of these variables, often either via a generative model that only samples probable ones or with an energy function (unnormalized log-density) that is low for probable ones and high for improbable ones. Here, we consider learning both an energy function and an efficient approximate sampling mechanism. Whereas the discriminator in generative adversarial networks (GANs) learns to separate data and generator samples, introducing an entropy maximization regularizer on the generator can turn the interpretation of the critic into an energy function, which separates the training distribution from everything else, and thus can be used for tasks like anomaly or novelty detection. Then, we show how Markov Chain Monte Carlo can be done in the generator latent space whose samples can be mapped to data space, producing better samples. These samples are used for the negative phase gradient required to estimate the log-likelihood gradient of the data space energy function. To maximize entropy at the output of the generator, we take advantage of recently introduced neural estimators of mutual information. We find that in addition to producing a useful scoring function for anomaly detection, the resulting approach produces sharp samples while covering the modes well, leading to high Inception and Frechet scores.