 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResolving the bias-precision paradox with stochastic causal representation learning for personalized medicine
May 07, 2026Estimating individualized treatment effects from longitudinal observational data is central to data-driven medicine, yet existing methods face a fundamental limitation: reducing confounding bias often suppresses clinically informative heterogeneity, degrading patient-specific predictions. Here, we identify this tension as a bias-precision paradox in causal representation learning and introduce sampling-based maximum mean discrepancy (sMMD), a stochastic alignment strategy that replaces global adversarial balancing with subset-level matching. We instantiate this approach in a framework for counterfactual outcome prediction with attribution-grounded interpretability. Across two large-scale ICU cohorts (n = 27,783), our framework improves accuracy under distribution shift, reducing error by up to 11.5% and substantially increasing recall in high-risk tasks. Mechanistic analyses show that sMMD selectively preserves clinically decisive variables. In human-AI evaluation, our method outperforms clinicians-in-training and large language models, and improves clinician accuracy by 14.7% while reducing decision time, enabling interpretable, real-time clinical decision support.
A Meta-Transfer Objective for Learning to Disentangle Causal Mechanisms
Feb 04, 2019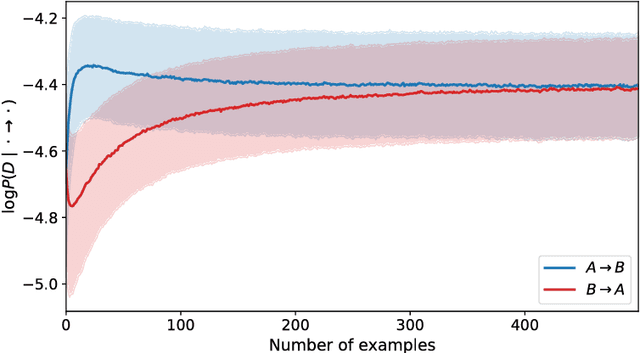
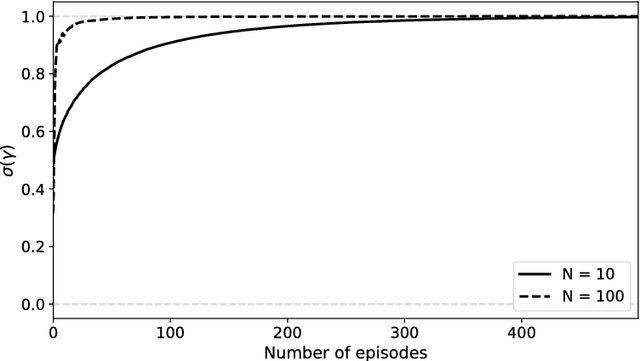
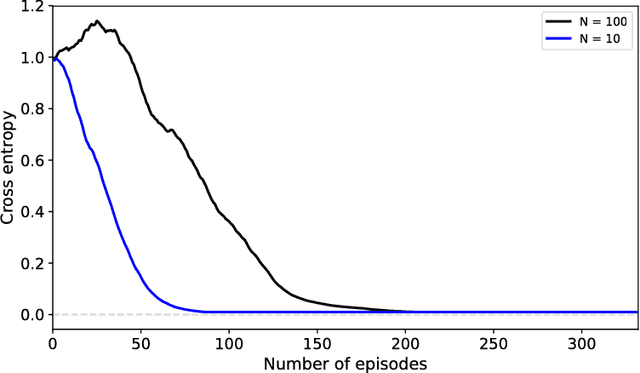

We propose to meta-learn causal structures based on how fast a learner adapts to new distributions arising from sparse distributional changes, e.g. due to interventions, actions of agents and other sources of non-stationarities. We show that under this assumption, the correct causal structural choices lead to faster adaptation to modified distributions because the changes are concentrated in one or just a few mechanisms when the learned knowledge is modularized appropriately. This leads to sparse expected gradients and a lower effective number of degrees of freedom needing to be relearned while adapting to the change. It motivates using the speed of adaptation to a modified distribution as a meta-learning objective. We demonstrate how this can be used to determine the cause-effect relationship between two observed variables. The distributional changes do not need to correspond to standard interventions (clamping a variable), and the learner has no direct knowledge of these interventions. We show that causal structures can be parameterized via continuous variables and learned end-to-end. We then explore how these ideas could be used to also learn an encoder that would map low-level observed variables to unobserved causal variables leading to faster adaptation out-of-distribution, learning a representation space where one can satisfy the assumptions of independent mechanisms and of small and sparse changes in these mechanisms due to actions and non-stationarities.