 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAvoidance Learning Using Observational Reinforcement Learning
Sep 24, 2019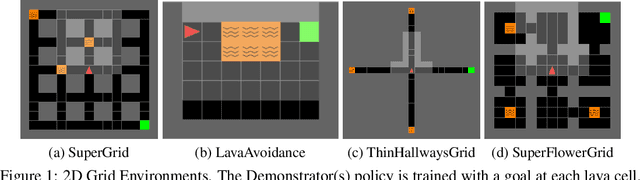


Imitation learning seeks to learn an expert policy from sampled demonstrations. However, in the real world, it is often difficult to find a perfect expert and avoiding dangerous behaviors becomes relevant for safety reasons. We present the idea of \textit{learning to avoid}, an objective opposite to imitation learning in some sense, where an agent learns to avoid a demonstrator policy given an environment. We define avoidance learning as the process of optimizing the agent's reward while avoiding dangerous behaviors given by a demonstrator. In this work we develop a framework of avoidance learning by defining a suitable objective function for these problems which involves the \emph{distance} of state occupancy distributions of the expert and demonstrator policies. We use density estimates for state occupancy measures and use the aforementioned distance as the reward bonus for avoiding the demonstrator. We validate our theory with experiments using a wide range of partially observable environments. Experimental results show that we are able to improve sample efficiency during training compared to state of the art policy optimization and safety methods.
Torchmeta: A Meta-Learning library for PyTorch
Sep 14, 2019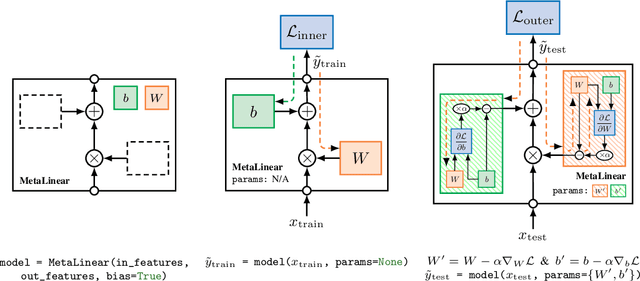
The constant introduction of standardized benchmarks in the literature has helped accelerating the recent advances in meta-learning research. They offer a way to get a fair comparison between different algorithms, and the wide range of datasets available allows full control over the complexity of this evaluation. However, for a large majority of code available online, the data pipeline is often specific to one dataset, and testing on another dataset requires significant rework. We introduce Torchmeta, a library built on top of PyTorch that enables seamless and consistent evaluation of meta-learning algorithms on multiple datasets, by providing data-loaders for most of the standard benchmarks in few-shot classification and regression, with a new meta-dataset abstraction. It also features some extensions for PyTorch to simplify the development of models compatible with meta-learning algorithms. The code is available here: https://github.com/tristandeleu/pytorch-meta
Data-Driven Approach to Encoding and Decoding 3-D Crystal Structures
Sep 03, 2019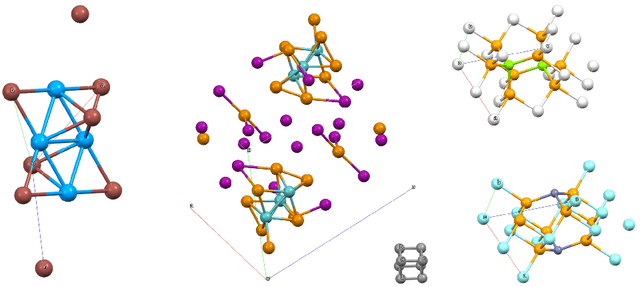
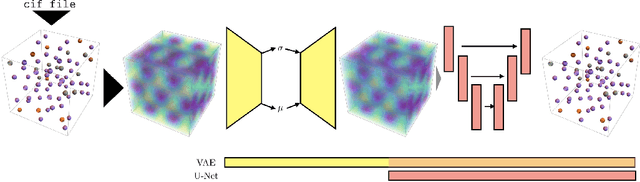
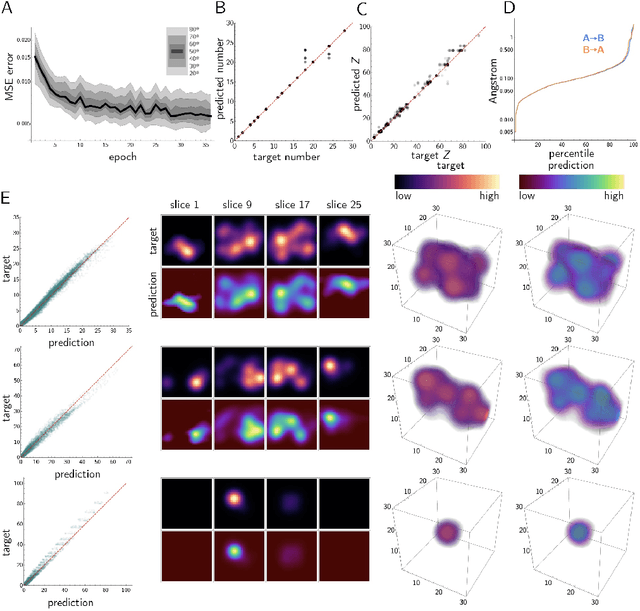
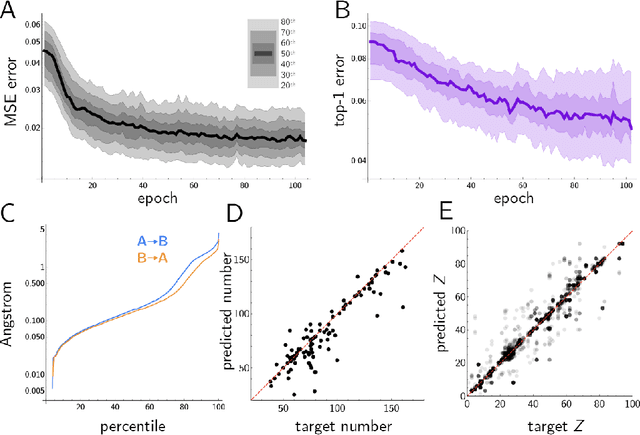
Generative models have achieved impressive results in many domains including image and text generation. In the natural sciences, generative models have led to rapid progress in automated drug discovery. Many of the current methods focus on either 1-D or 2-D representations of typically small, drug-like molecules. However, many molecules require 3-D descriptors and exceed the chemical complexity of commonly used dataset. We present a method to encode and decode the position of atoms in 3-D molecules from a dataset of nearly 50,000 stable crystal unit cells that vary from containing 1 to over 100 atoms. We construct a smooth and continuous 3-D density representation of each crystal based on the positions of different atoms. Two different neural networks were trained on a dataset of over 120,000 three-dimensional samples of single and repeating crystal structures, made by rotating the single unit cells. The first, an Encoder-Decoder pair, constructs a compressed latent space representation of each molecule and then decodes this description into an accurate reconstruction of the input. The second network segments the resulting output into atoms and assigns each atom an atomic number. By generating compressed, continuous latent spaces representations of molecules we are able to decode random samples, interpolate between two molecules, and alter known molecules.
Learning Fixed Points in Generative Adversarial Networks: From Image-to-Image Translation to Disease Detection and Localization
Aug 29, 2019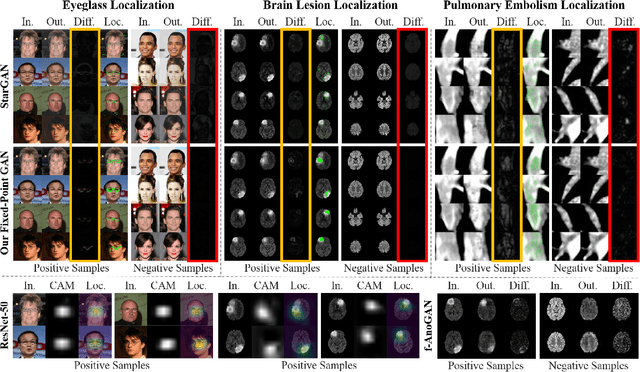

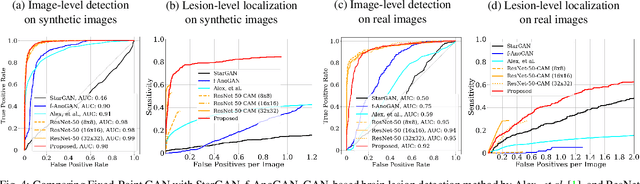
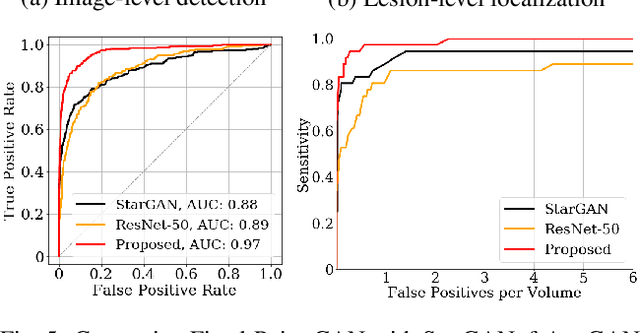
Generative adversarial networks (GANs) have ushered in a revolution in image-to-image translation. The development and proliferation of GANs raises an interesting question: can we train a GAN to remove an object, if present, from an image while otherwise preserving the image? Specifically, can a GAN "virtually heal" anyone by turning his medical image, with an unknown health status (diseased or healthy), into a healthy one, so that diseased regions could be revealed by subtracting those two images? Such a task requires a GAN to identify a minimal subset of target pixels for domain translation, an ability that we call fixed-point translation, which no GAN is equipped with yet. Therefore, we propose a new GAN, called Fixed-Point GAN, trained by (1) supervising same-domain translation through a conditional identity loss, and (2) regularizing cross-domain translation through revised adversarial, domain classification, and cycle consistency loss. Based on fixed-point translation, we further derive a novel framework for disease detection and localization using only image-level annotation. Qualitative and quantitative evaluations demonstrate that the proposed method outperforms the state of the art in multi-domain image-to-image translation and that it surpasses predominant weakly-supervised localization methods in both disease detection and localization. Implementation is available at https://github.com/jlianglab/Fixed-Point-GAN.
Interactive Language Learning by Question Answering
Aug 28, 2019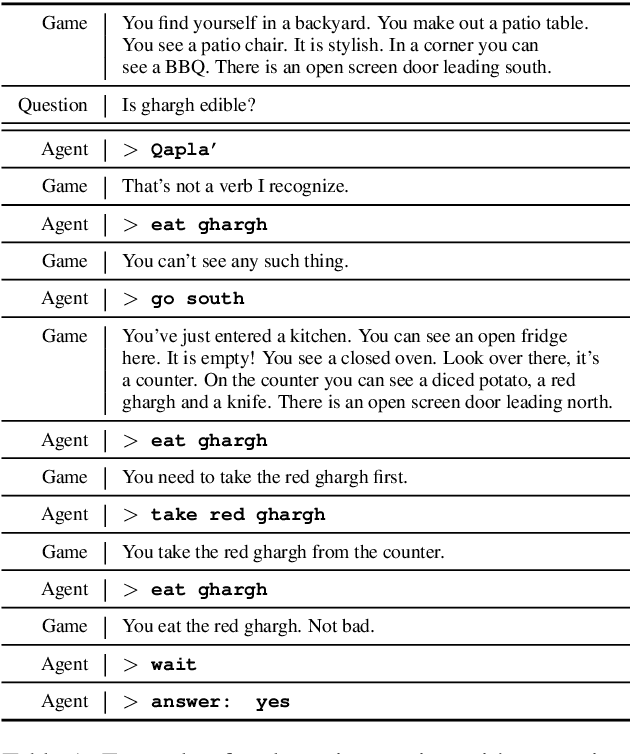
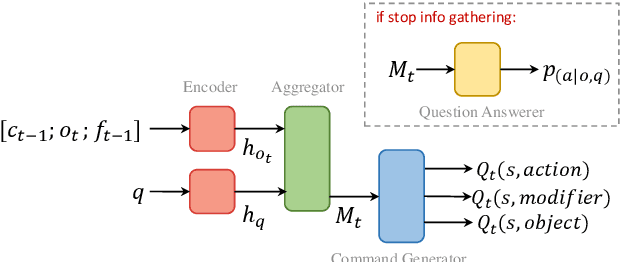
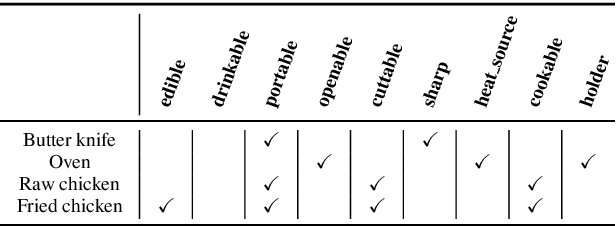
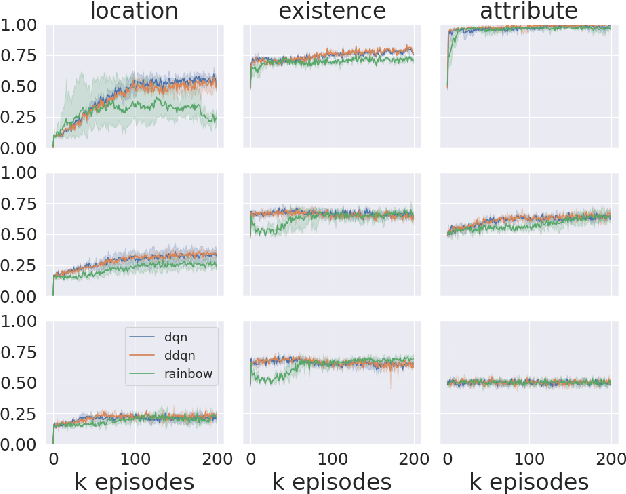
Humans observe and interact with the world to acquire knowledge. However, most existing machine reading comprehension (MRC) tasks miss the interactive, information-seeking component of comprehension. Such tasks present models with static documents that contain all necessary information, usually concentrated in a single short substring. Thus, models can achieve strong performance through simple word- and phrase-based pattern matching. We address this problem by formulating a novel text-based question answering task: Question Answering with Interactive Text (QAit). In QAit, an agent must interact with a partially observable text-based environment to gather information required to answer questions. QAit poses questions about the existence, location, and attributes of objects found in the environment. The data is built using a text-based game generator that defines the underlying dynamics of interaction with the environment. We propose and evaluate a set of baseline models for the QAit task that includes deep reinforcement learning agents. Experiments show that the task presents a major challenge for machine reading systems, while humans solve it with relative ease.
Weakly-supervised Knowledge Graph Alignment with Adversarial Learning
Jul 06, 2019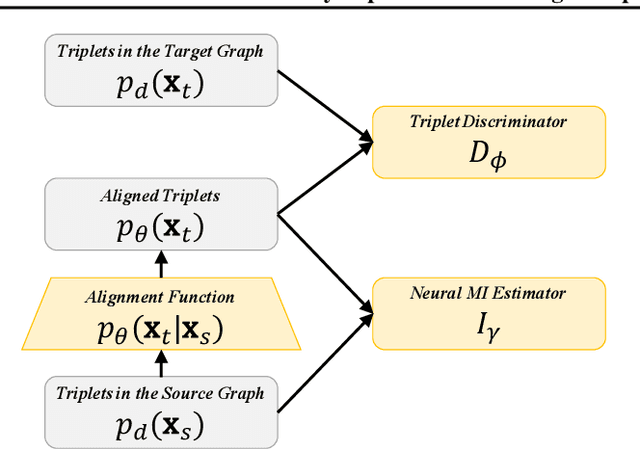


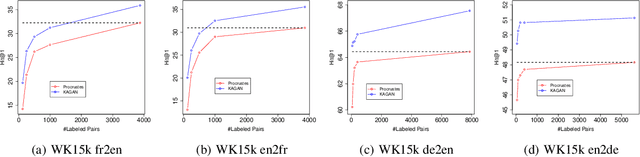
This paper studies aligning knowledge graphs from different sources or languages. Most existing methods train supervised methods for the alignment, which usually require a large number of aligned knowledge triplets. However, such a large number of aligned knowledge triplets may not be available or are expensive to obtain in many domains. Therefore, in this paper we propose to study aligning knowledge graphs in fully-unsupervised or weakly-supervised fashion, i.e., without or with only a few aligned triplets. We propose an unsupervised framework to align the entity and relation embddings of different knowledge graphs with an adversarial learning framework. Moreover, a regularization term which maximizes the mutual information between the embeddings of different knowledge graphs is used to mitigate the problem of mode collapse when learning the alignment functions. Such a framework can be further seamlessly integrated with existing supervised methods by utilizing a limited number of aligned triples as guidance. Experimental results on multiple datasets prove the effectiveness of our proposed approach in both the unsupervised and the weakly-supervised settings.
Learning the Arrow of Time
Jul 02, 2019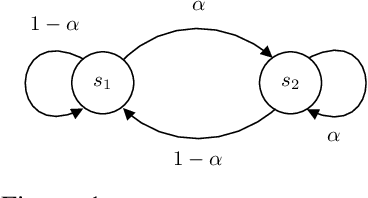
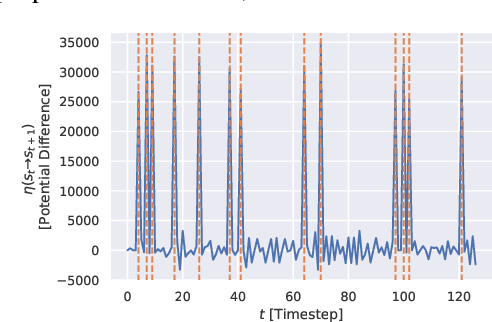
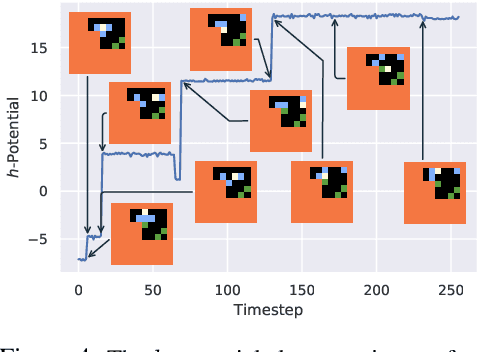
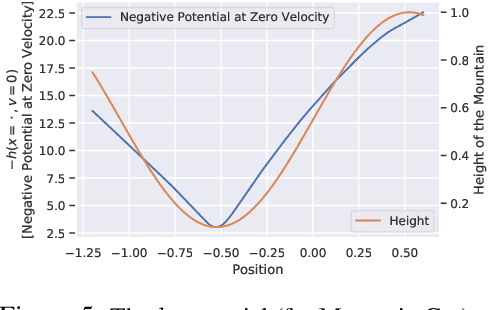
We humans seem to have an innate understanding of the asymmetric progression of time, which we use to efficiently and safely perceive and manipulate our environment. Drawing inspiration from that, we address the problem of learning an arrow of time in a Markov (Decision) Process. We illustrate how a learned arrow of time can capture meaningful information about the environment, which in turn can be used to measure reachability, detect side-effects and to obtain an intrinsic reward signal. We show empirical results on a selection of discrete and continuous environments, and demonstrate for a class of stochastic processes that the learned arrow of time agrees reasonably well with a known notion of an arrow of time given by the celebrated Jordan-Kinderlehrer-Otto result.
Interpolated Adversarial Training: Achieving Robust Neural Networks without Sacrificing Too Much Accuracy
Jun 29, 2019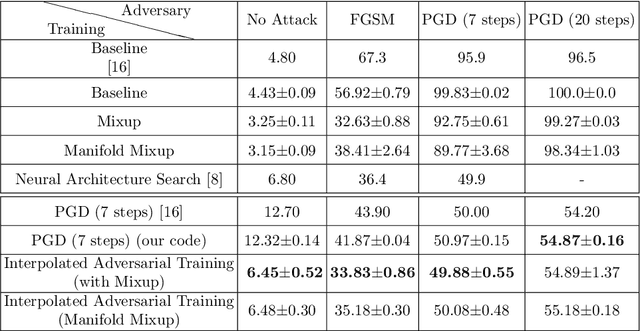
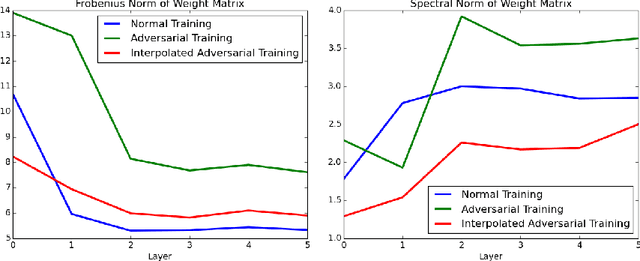
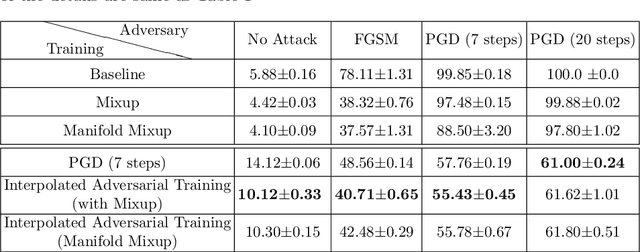
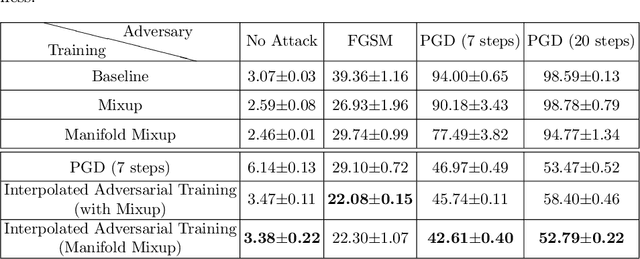
Adversarial robustness has become a central goal in deep learning, both in the theory and the practice. However, successful methods to improve the adversarial robustness (such as adversarial training) greatly hurt generalization performance on the unperturbed data. This could have a major impact on how the adversarial robustness affects real world systems (i.e. many may opt to forgo robustness if it can improve accuracy on the unperturbed data). We propose Interpolated Adversarial Training, which employs recently proposed interpolation based training methods in the framework of adversarial training. On CIFAR-10, adversarial training increases the standard test error ( when there is no adversary) from 4.43% to 12.32%, whereas with our Interpolated adversarial training we retain the adversarial robustness while achieving a standard test error of only 6.45%. With our technique, the relative increase in the standard error for the robust model is reduced from 178.1% to just 45.5%.
Unsupervised State Representation Learning in Atari
Jun 26, 2019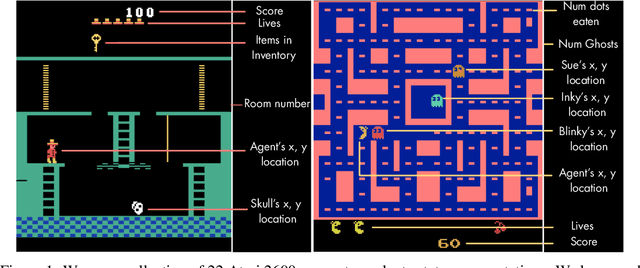
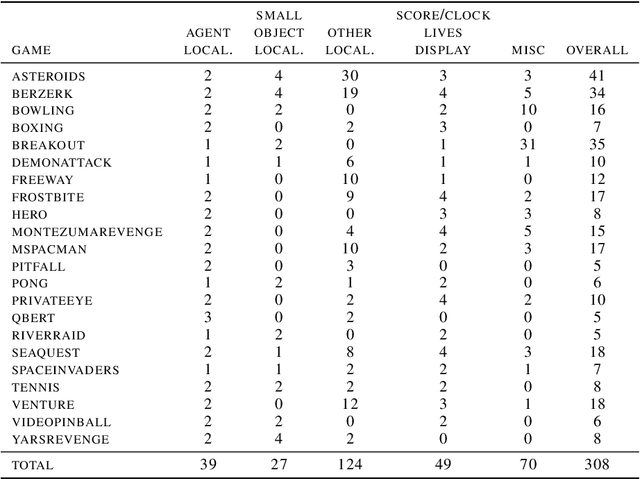
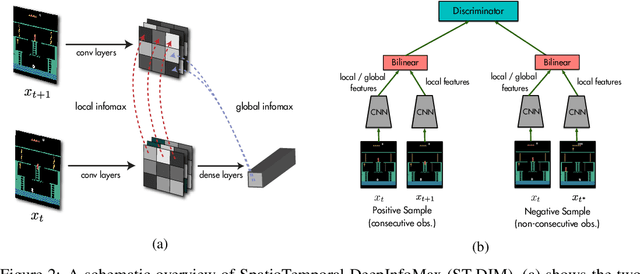
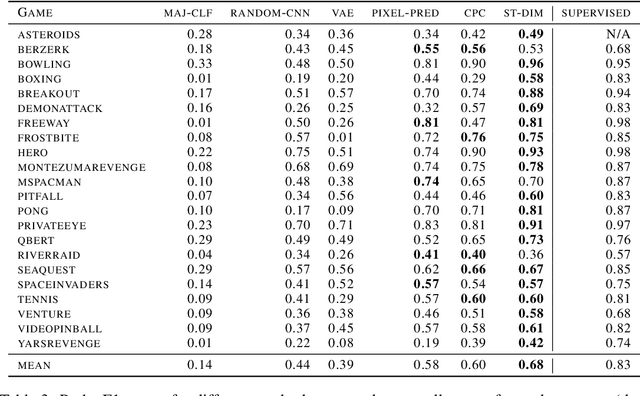
State representation learning, or the ability to capture latent generative factors of an environment, is crucial for building intelligent agents that can perform a wide variety of tasks. Learning such representations without supervision from rewards is a challenging open problem. We introduce a method that learns state representations by maximizing mutual information across spatially and temporally distinct features of a neural encoder of the observations. We also introduce a new benchmark based on Atari 2600 games where we evaluate representations based on how well they capture the ground truth state variables. We believe this new framework for evaluating representation learning models will be crucial for future representation learning research. Finally, we compare our technique with other state-of-the-art generative and contrastive representation learning methods.
Reinforcement Learning with Competitive Ensembles of Information-Constrained Primitives
Jun 25, 2019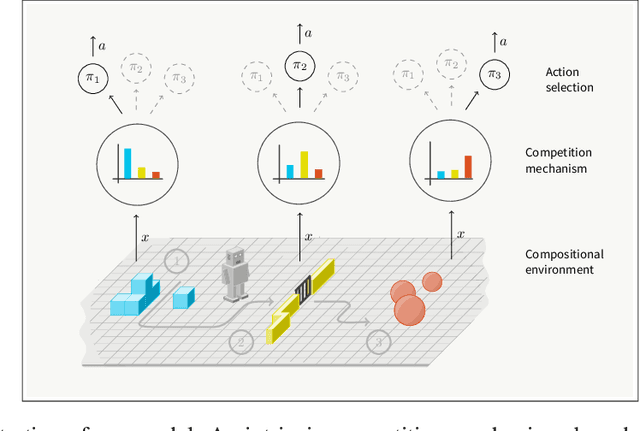

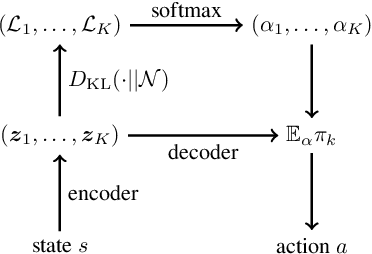
Reinforcement learning agents that operate in diverse and complex environments can benefit from the structured decomposition of their behavior. Often, this is addressed in the context of hierarchical reinforcement learning, where the aim is to decompose a policy into lower-level primitives or options, and a higher-level meta-policy that triggers the appropriate behaviors for a given situation. However, the meta-policy must still produce appropriate decisions in all states. In this work, we propose a policy design that decomposes into primitives, similarly to hierarchical reinforcement learning, but without a high-level meta-policy. Instead, each primitive can decide for themselves whether they wish to act in the current state. We use an information-theoretic mechanism for enabling this decentralized decision: each primitive chooses how much information it needs about the current state to make a decision and the primitive that requests the most information about the current state acts in the world. The primitives are regularized to use as little information as possible, which leads to natural competition and specialization. We experimentally demonstrate that this policy architecture improves over both flat and hierarchical policies in terms of generalization.