 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmall-GAN: Speeding Up GAN Training Using Core-sets
Oct 29, 2019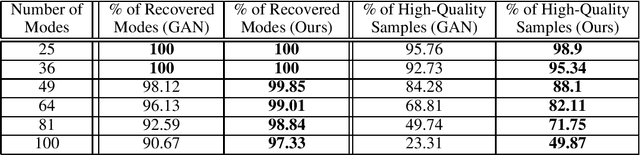
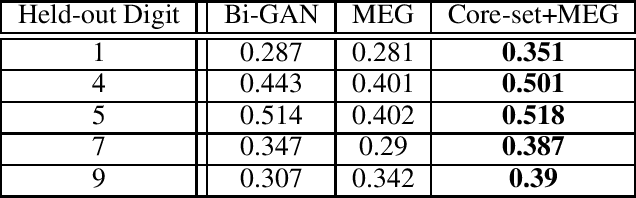


Recent work by Brock et al. (2018) suggests that Generative Adversarial Networks (GANs) benefit disproportionately from large mini-batch sizes. Unfortunately, using large batches is slow and expensive on conventional hardware. Thus, it would be nice if we could generate batches that were effectively large though actually small. In this work, we propose a method to do this, inspired by the use of Coreset-selection in active learning. When training a GAN, we draw a large batch of samples from the prior and then compress that batch using Coreset-selection. To create effectively large batches of 'real' images, we create a cached dataset of Inception activations of each training image, randomly project them down to a smaller dimension, and then use Coreset-selection on those projected activations at training time. We conduct experiments showing that this technique substantially reduces training time and memory usage for modern GAN variants, that it reduces the fraction of dropped modes in a synthetic dataset, and that it allows GANs to reach a new state of the art in anomaly detection.
MelGAN: Generative Adversarial Networks for Conditional Waveform Synthesis
Oct 28, 2019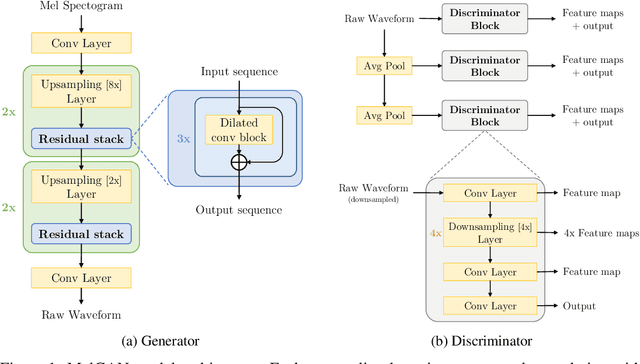


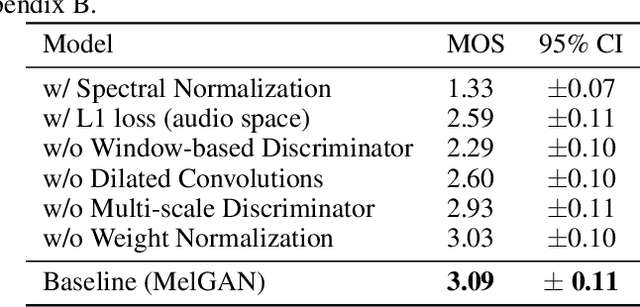
Previous works (Donahue et al., 2018a; Engel et al., 2019a) have found that generating coherent raw audio waveforms with GANs is challenging. In this paper, we show that it is possible to train GANs reliably to generate high quality coherent waveforms by introducing a set of architectural changes and simple training techniques. Subjective evaluation metric (Mean Opinion Score, or MOS) shows the effectiveness of the proposed approach for high quality mel-spectrogram inversion. To establish the generality of the proposed techniques, we show qualitative results of our model in speech synthesis, music domain translation and unconditional music synthesis. We evaluate the various components of the model through ablation studies and suggest a set of guidelines to design general purpose discriminators and generators for conditional sequence synthesis tasks. Our model is non-autoregressive, fully convolutional, with significantly fewer parameters than competing models and generalizes to unseen speakers for mel-spectrogram inversion. Our pytorch implementation runs at more than 100x faster than realtime on GTX 1080Ti GPU and more than 2x faster than real-time on CPU, without any hardware specific optimization tricks.
Establishing an Evaluation Metric to Quantify Climate Change Image Realism
Oct 22, 2019

With success on controlled tasks, generative models are being increasingly applied to humanitarian applications [1,2]. In this paper, we focus on the evaluation of a conditional generative model that illustrates the consequences of climate change-induced flooding to encourage public interest and awareness on the issue. Because metrics for comparing the realism of different modes in a conditional generative model do not exist, we propose several automated and human-based methods for evaluation. To do this, we adapt several existing metrics, and assess the automated metrics against gold standard human evaluation. We find that using Fr\'echet Inception Distance (FID) with embeddings from an intermediary Inception-V3 layer that precedes the auxiliary classifier produces results most correlated with human realism. While insufficient alone to establish a human-correlated automatic evaluation metric, we believe this work begins to bridge the gap between human and automated generative evaluation procedures.
Icentia11K: An Unsupervised Representation Learning Dataset for Arrhythmia Subtype Discovery
Oct 21, 2019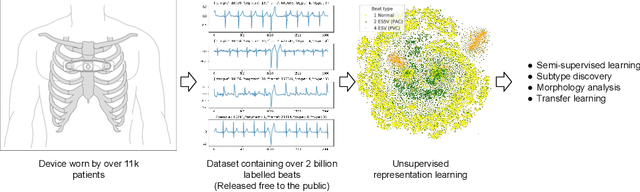
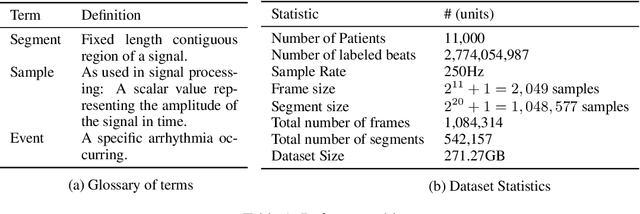

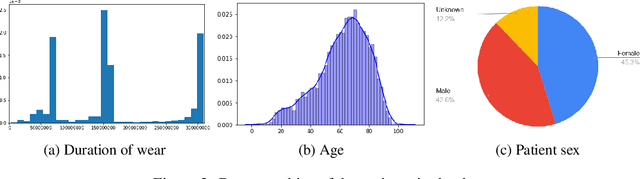
We release the largest public ECG dataset of continuous raw signals for representation learning containing 11 thousand patients and 2 billion labelled beats. Our goal is to enable semi-supervised ECG models to be made as well as to discover unknown subtypes of arrhythmia and anomalous ECG signal events. To this end, we propose an unsupervised representation learning task, evaluated in a semi-supervised fashion. We provide a set of baselines for different feature extractors that can be built upon. Additionally, we perform qualitative evaluations on results from PCA embeddings, where we identify some clustering of known subtypes indicating the potential for representation learning in arrhythmia sub-type discovery.
Predicting ice flow using machine learning
Oct 20, 2019
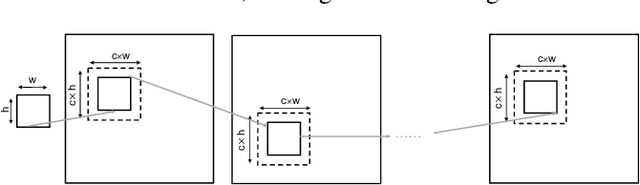

Though machine learning has achieved notable success in modeling sequential and spatial data for speech recognition and in computer vision, applications to remote sensing and climate science problems are seldom considered. In this paper, we demonstrate techniques from unsupervised learning of future video frame prediction, to increase the accuracy of ice flow tracking in multi-spectral satellite images. As the volume of cryosphere data increases in coming years, this is an interesting and important opportunity for machine learning to address a global challenge for climate change, risk management from floods, and conserving freshwater resources. Future frame prediction of ice melt and tracking the optical flow of ice dynamics presents modeling difficulties, due to uncertainties in global temperature increase, changing precipitation patterns, occlusion from cloud cover, rapid melting and glacier retreat due to black carbon aerosol deposition, from wildfires or human fossil emissions. We show the adversarial learning method helps improve the accuracy of tracking the optical flow of ice dynamics compared to existing methods in climate science. We present a dataset, IceNet, to encourage machine learning research and to help facilitate further applications in the areas of cryospheric science and climate change.
Learning Neural Causal Models from Unknown Interventions
Oct 02, 2019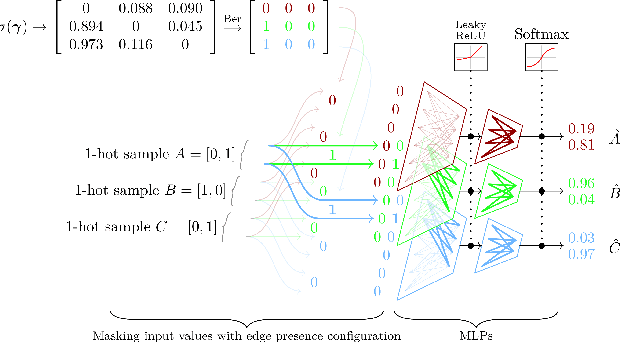



Meta-learning over a set of distributions can be interpreted as learning different types of parameters corresponding to short-term vs long-term aspects of the mechanisms underlying the generation of data. These are respectively captured by quickly-changing parameters and slowly-changing meta-parameters. We present a new framework for meta-learning causal models where the relationship between each variable and its parents is modeled by a neural network, modulated by structural meta-parameters which capture the overall topology of a directed graphical model. Our approach avoids a discrete search over models in favour of a continuous optimization procedure. We study a setting where interventional distributions are induced as a result of a random intervention on a single unknown variable of an unknown ground truth causal model, and the observations arising after such an intervention constitute one meta-example. To disentangle the slow-changing aspects of each conditional from the fast-changing adaptations to each intervention, we parametrize the neural network into fast parameters and slow meta-parameters. We introduce a meta-learning objective that favours solutions robust to frequent but sparse interventional distribution change, and which generalize well to previously unseen interventions. Optimizing this objective is shown experimentally to recover the structure of the causal graph.
Variational Temporal Abstraction
Oct 02, 2019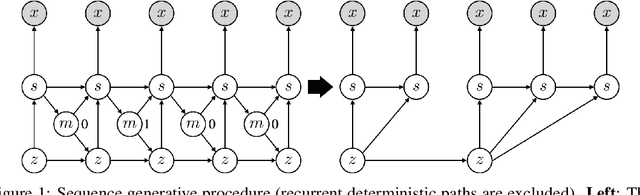
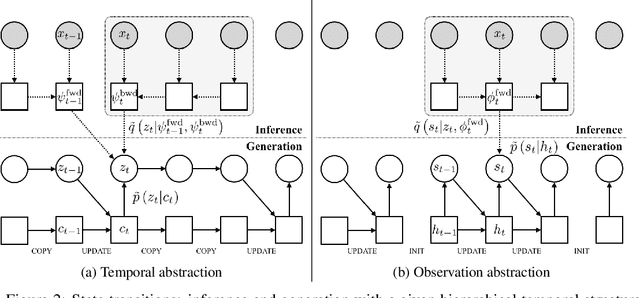
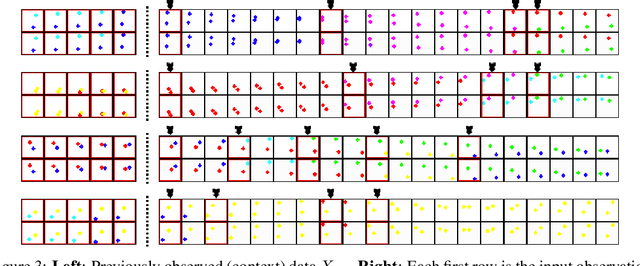
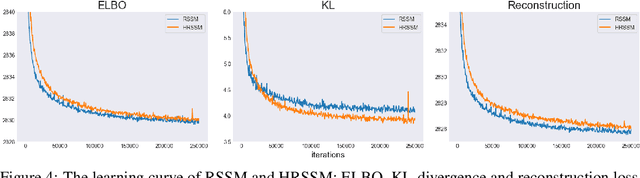
We introduce a variational approach to learning and inference of temporally hierarchical structure and representation for sequential data. We propose the Variational Temporal Abstraction (VTA), a hierarchical recurrent state space model that can infer the latent temporal structure and thus perform the stochastic state transition hierarchically. We also propose to apply this model to implement the jumpy-imagination ability in imagination-augmented agent-learning in order to improve the efficiency of the imagination. In experiments, we demonstrate that our proposed method can model 2D and 3D visual sequence datasets with interpretable temporal structure discovery and that its application to jumpy imagination enables more efficient agent-learning in a 3D navigation task.
Underwhelming Generalization Improvements From Controlling Feature Attribution
Oct 01, 2019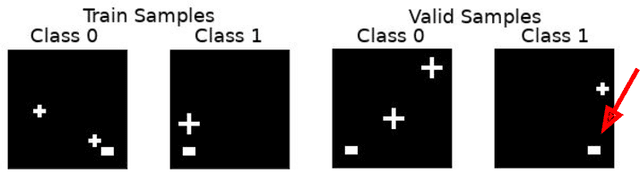
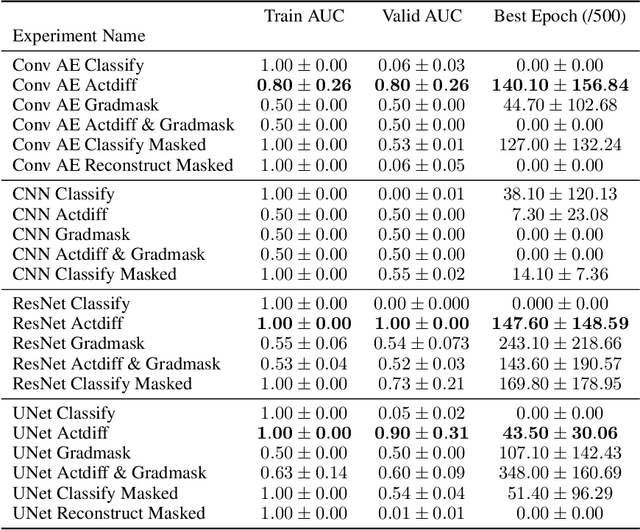
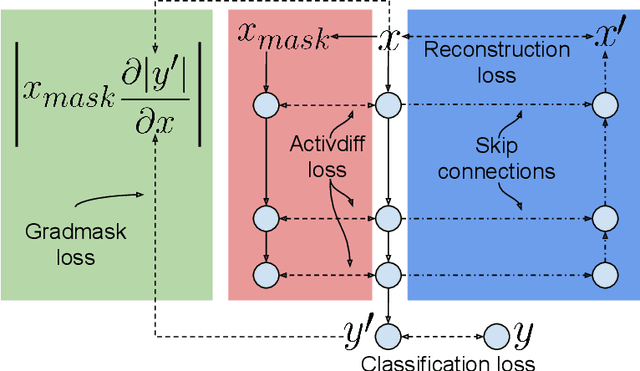
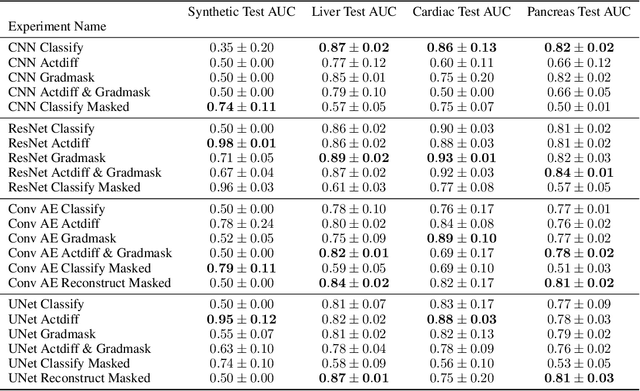
Overfitting is a common issue in machine learning, which can arise when the model learns to predict class membership using convenient but spuriously-correlated image features instead of the true image features that denote a class. These are typically visualized using saliency maps. In some object classification tasks such as for medical images, one may have some images with masks, indicating a region of interest, i.e., which part of the image contains the most relevant information for the classification. We describe a simple method for taking advantage of such auxiliary labels, by training networks to ignore the distracting features which may be extracted outside of the region of interest, on the training images for which such masks are available. This mask information is only used during training and has an impact on generalization accuracy in a dataset-dependent way. We observe an underwhelming relationship between controlling saliency maps and improving generalization performance.
Recurrent Independent Mechanisms
Sep 26, 2019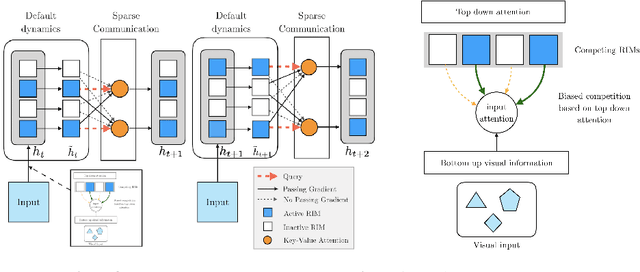
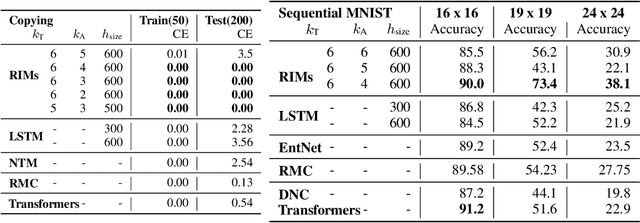
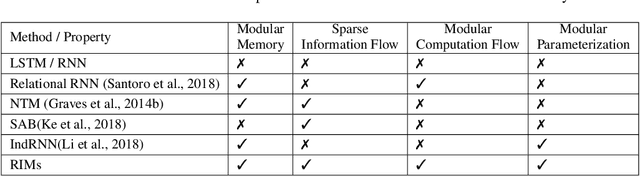

Learning modular structures which reflect the dynamics of the environment can lead to better generalization and robustness to changes which only affect a few of the underlying causes. We propose Recurrent Independent Mechanisms (RIMs), a new recurrent architecture in which multiple groups of recurrent cells operate with nearly independent transition dynamics, communicate only sparingly through the bottleneck of attention, and are only updated at time steps where they are most relevant. We show that this leads to specialization amongst the RIMs, which in turn allows for dramatically improved generalization on tasks where some factors of variation differ systematically between training and evaluation.
GraphMix: Regularized Training of Graph Neural Networks for Semi-Supervised Learning
Sep 25, 2019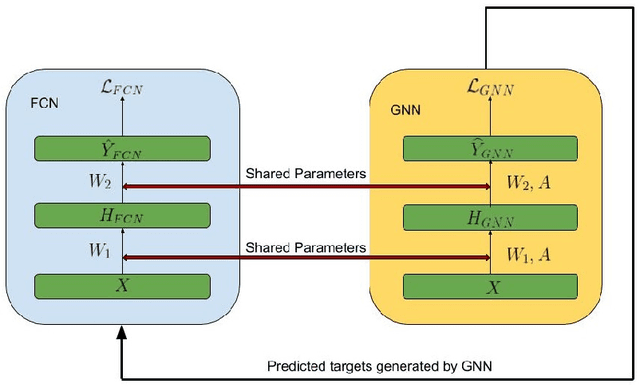
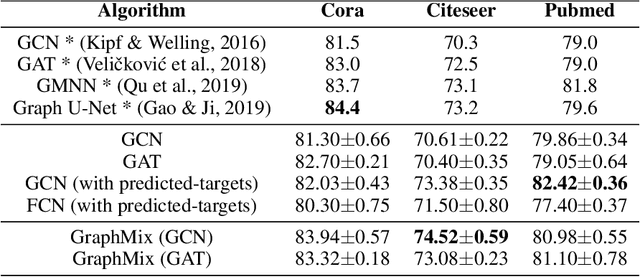

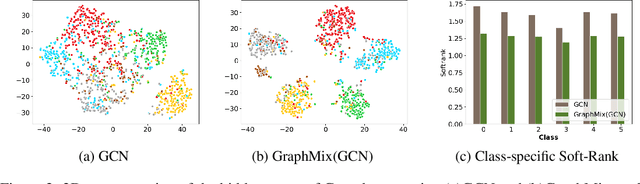
We present GraphMix, a regularization technique for Graph Neural Network based semi-supervised object classification, leveraging the recent advances in the regularization of classical deep neural networks. Specifically, we propose a unified approach in which we train a fully-connected network jointly with the graph neural network via parameter sharing, interpolation-based regularization, and self-predicted-targets. Our proposed method is architecture agnostic in the sense that it can be applied to any variant of graph neural networks which applies a parametric transformation to the features of the graph nodes. Despite its simplicity, with GraphMix we can consistently improve results and achieve or closely match state-of-the-art performance using even simpler architectures such as Graph Convolutional Networks, across three established graph benchmarks: the Cora, Citeseer and Pubmed citation network datasets, as well as three newly proposed datasets : Cora-Full, Co-author-CS and Co-author-Physics.