 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLM: Bridge the thin gap between speech and text foundation models
Sep 30, 2023



We present a joint Speech and Language Model (SLM), a multitask, multilingual, and dual-modal model that takes advantage of pretrained foundational speech and language models. SLM freezes the pretrained foundation models to maximally preserves their capabilities, and only trains a simple adapter with just 1\% (156M) of the foundation models' parameters. This adaptation not only leads SLM to achieve strong performance on conventional tasks such as speech recognition (ASR) and speech translation (AST), but also introduces the novel capability of zero-shot instruction-following for more diverse tasks: given a speech input and a text instruction, SLM is able to perform unseen generation tasks including contextual biasing ASR using real-time context, dialog generation, speech continuation, and question answering, etc. Our approach demonstrates that the representational gap between pretrained speech and language models might be narrower than one would expect, and can be bridged by a simple adaptation mechanism. As a result, SLM is not only efficient to train, but also inherits strong capabilities already acquired in foundation models of different modalities.
USM-SCD: Multilingual Speaker Change Detection Based on Large Pretrained Foundation Models
Sep 14, 2023We introduce a multilingual speaker change detection model (USM-SCD) that can simultaneously detect speaker turns and perform ASR for 96 languages. This model is adapted from a speech foundation model trained on a large quantity of supervised and unsupervised data, demonstrating the utility of fine-tuning from a large generic foundation model for a downstream task. We analyze the performance of this multilingual speaker change detection model through a series of ablation studies. We show that the USM-SCD model can achieve more than 75% average speaker change detection F1 score across a test set that consists of data from 96 languages. On American English, the USM-SCD model can achieve an 85.8% speaker change detection F1 score across various public and internal test sets, beating the previous monolingual baseline model by 21% relative. We also show that we only need to fine-tune one-quarter of the trainable model parameters to achieve the best model performance. The USM-SCD model exhibits state-of-the-art ASR quality compared with a strong public ASR baseline, making it suitable to handle both tasks with negligible additional computational cost.
Undergraduate Research of Decentralized Localization of Roombas Through Usage of Wall-Finding Software
Sep 11, 2023This paper introduces the research effort of an undergraduate research team in realizing robot localization. More specifically, the undergraduate research team developed and tested wall-following software that allowed a ground robot Roombas to independently find their positions within a defined space. The software also allows a robot to send its localized position to other Roombas, so that each Roomba knows its relative location to realize robot cooperation.
Fast and High-Performance Learned Image Compression With Improved Checkerboard Context Model, Deformable Residual Module, and Knowledge Distillation
Sep 05, 2023



Deep learning-based image compression has made great progresses recently. However, many leading schemes use serial context-adaptive entropy model to improve the rate-distortion (R-D) performance, which is very slow. In addition, the complexities of the encoding and decoding networks are quite high and not suitable for many practical applications. In this paper, we introduce four techniques to balance the trade-off between the complexity and performance. We are the first to introduce deformable convolutional module in compression framework, which can remove more redundancies in the input image, thereby enhancing compression performance. Second, we design a checkerboard context model with two separate distribution parameter estimation networks and different probability models, which enables parallel decoding without sacrificing the performance compared to the sequential context-adaptive model. Third, we develop an improved three-step knowledge distillation and training scheme to achieve different trade-offs between the complexity and the performance of the decoder network, which transfers both the final and intermediate results of the teacher network to the student network to help its training. Fourth, we introduce $L_{1}$ regularization to make the numerical values of the latent representation more sparse. Then we only encode non-zero channels in the encoding and decoding process, which can greatly reduce the encoding and decoding time. Experiments show that compared to the state-of-the-art learned image coding scheme, our method can be about 20 times faster in encoding and 70-90 times faster in decoding, and our R-D performance is also $2.3 \%$ higher. Our method outperforms the traditional approach in H.266/VVC-intra (4:4:4) and some leading learned schemes in terms of PSNR and MS-SSIM metrics when testing on Kodak and Tecnick-40 datasets.
Enhanced Residual SwinV2 Transformer for Learned Image Compression
Aug 23, 2023



Recently, the deep learning technology has been successfully applied in the field of image compression, leading to superior rate-distortion performance. However, a challenge of many learning-based approaches is that they often achieve better performance via sacrificing complexity, which making practical deployment difficult. To alleviate this issue, in this paper, we propose an effective and efficient learned image compression framework based on an enhanced residual Swinv2 transformer. To enhance the nonlinear representation of images in our framework, we use a feature enhancement module that consists of three consecutive convolutional layers. In the subsequent coding and hyper coding steps, we utilize a SwinV2 transformer-based attention mechanism to process the input image. The SwinV2 model can help to reduce model complexity while maintaining high performance. Experimental results show that the proposed method achieves comparable performance compared to some recent learned image compression methods on Kodak and Tecnick datasets, and outperforms some traditional codecs including VVC. In particular, our method achieves comparable results while reducing model complexity by 56% compared to these recent methods.
Microvasculature Segmentation in Human BioMolecular Atlas Program (HuBMAP)
Aug 06, 2023Image segmentation serves as a critical tool across a range of applications, encompassing autonomous driving's pedestrian detection and pre-operative tumor delineation in the medical sector. Among these applications, we focus on the National Institutes of Health's (NIH) Human BioMolecular Atlas Program (HuBMAP), a significant initiative aimed at creating detailed cellular maps of the human body. In this study, we concentrate on segmenting various microvascular structures in human kidneys, utilizing 2D Periodic Acid-Schiff (PAS)-stained histology images. Our methodology begins with a foundational FastAI U-Net model, upon which we investigate alternative backbone architectures, delve into deeper models, and experiment with Feature Pyramid Networks. We rigorously evaluate these varied approaches by benchmarking their performance against our baseline U-Net model. This study thus offers a comprehensive exploration of cutting-edge segmentation techniques, providing valuable insights for future research in the field.
MFMAN-YOLO: A Method for Detecting Pole-like Obstacles in Complex Environment
Jul 24, 2023



In real-world traffic, there are various uncertainties and complexities in road and weather conditions. To solve the problem that the feature information of pole-like obstacles in complex environments is easily lost, resulting in low detection accuracy and low real-time performance, a multi-scale hybrid attention mechanism detection algorithm is proposed in this paper. First, the optimal transport function Monge-Kantorovich (MK) is incorporated not only to solve the problem of overlapping multiple prediction frames with optimal matching but also the MK function can be regularized to prevent model over-fitting; then, the features at different scales are up-sampled separately according to the optimized efficient multi-scale feature pyramid. Finally, the extraction of multi-scale feature space channel information is enhanced in complex environments based on the hybrid attention mechanism, which suppresses the irrelevant complex environment background information and focuses the feature information of pole-like obstacles. Meanwhile, this paper conducts real road test experiments in a variety of complex environments. The experimental results show that the detection precision, recall, and average precision of the method are 94.7%, 93.1%, and 97.4%, respectively, and the detection frame rate is 400 f/s. This research method can detect pole-like obstacles in a complex road environment in real time and accurately, which further promotes innovation and progress in the field of automatic driving.
Locally Differentially Private Distributed Online Learning with Guaranteed Optimality
Jun 25, 2023Distributed online learning is gaining increased traction due to its unique ability to process large-scale datasets and streaming data. To address the growing public awareness and concern on privacy protection, plenty of private distributed online learning algorithms have been proposed, mostly based on differential privacy which has emerged as the ``gold standard" for privacy protection. However, these algorithms often face the dilemma of trading learning accuracy for privacy. By exploiting the unique characteristics of online learning, this paper proposes an approach that tackles the dilemma and ensures both differential privacy and learning accuracy in distributed online learning. More specifically, while ensuring a diminishing expected instantaneous regret, the approach can simultaneously ensure a finite cumulative privacy budget, even on the infinite time horizon. To cater for the fully distributed setting, we adopt the local differential-privacy framework which avoids the reliance on a trusted data curator, and hence, provides stronger protection than the classic ``centralized" (global) differential privacy. To the best of our knowledge, this is the first algorithm that successfully ensures both rigorous local differential privacy and learning accuracy. The effectiveness of the proposed algorithm is evaluated using machine learning tasks, including logistic regression on the ``Mushrooms" and ``Covtype" datasets and CNN based image classification on the ``MNIST" and ``CIFAR-10" datasets.
AudioPaLM: A Large Language Model That Can Speak and Listen
Jun 22, 2023



We introduce AudioPaLM, a large language model for speech understanding and generation. AudioPaLM fuses text-based and speech-based language models, PaLM-2 [Anil et al., 2023] and AudioLM [Borsos et al., 2022], into a unified multimodal architecture that can process and generate text and speech with applications including speech recognition and speech-to-speech translation. AudioPaLM inherits the capability to preserve paralinguistic information such as speaker identity and intonation from AudioLM and the linguistic knowledge present only in text large language models such as PaLM-2. We demonstrate that initializing AudioPaLM with the weights of a text-only large language model improves speech processing, successfully leveraging the larger quantity of text training data used in pretraining to assist with the speech tasks. The resulting model significantly outperforms existing systems for speech translation tasks and has the ability to perform zero-shot speech-to-text translation for many languages for which input/target language combinations were not seen in training. AudioPaLM also demonstrates features of audio language models, such as transferring a voice across languages based on a short spoken prompt. We release examples of our method at https://google-research.github.io/seanet/audiopalm/examples
Google USM: Scaling Automatic Speech Recognition Beyond 100 Languages
Mar 03, 2023
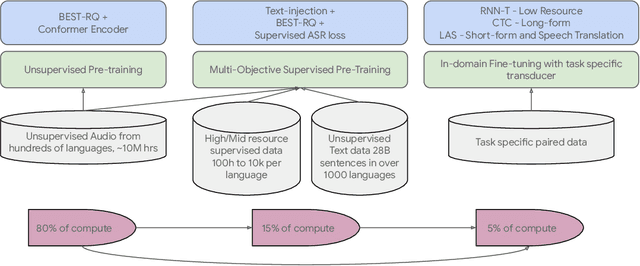
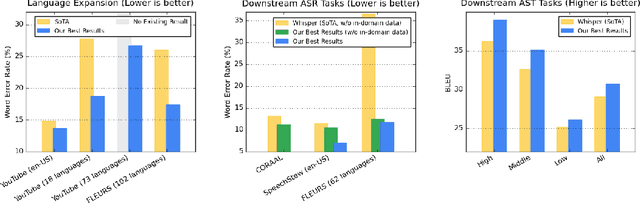

We introduce the Universal Speech Model (USM), a single large model that performs automatic speech recognition (ASR) across 100+ languages. This is achieved by pre-training the encoder of the model on a large unlabeled multilingual dataset of 12 million (M) hours spanning over 300 languages, and fine-tuning on a smaller labeled dataset. We use multilingual pre-training with random-projection quantization and speech-text modality matching to achieve state-of-the-art performance on downstream multilingual ASR and speech-to-text translation tasks. We also demonstrate that despite using a labeled training set 1/7-th the size of that used for the Whisper model, our model exhibits comparable or better performance on both in-domain and out-of-domain speech recognition tasks across many languages.