 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Multi-Agent Debate as Test-Time Scaling: A Systematic Study of Conditional Effectiveness
May 29, 2025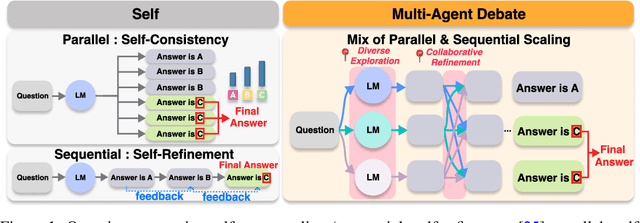
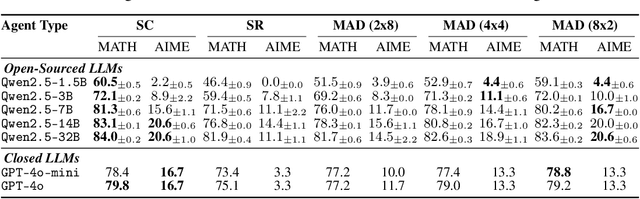
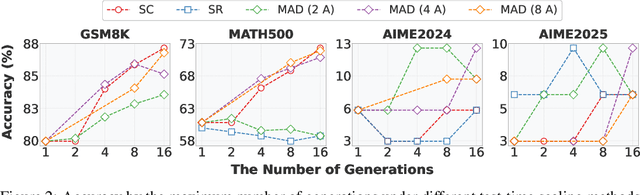
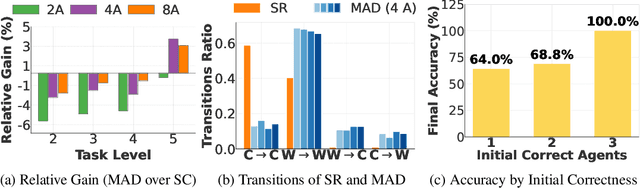
The remarkable growth in large language model (LLM) capabilities has spurred exploration into multi-agent systems, with debate frameworks emerging as a promising avenue for enhanced problem-solving. These multi-agent debate (MAD) approaches, where agents collaboratively present, critique, and refine arguments, potentially offer improved reasoning, robustness, and diverse perspectives over monolithic models. Despite prior studies leveraging MAD, a systematic understanding of its effectiveness compared to self-agent methods, particularly under varying conditions, remains elusive. This paper seeks to fill this gap by conceptualizing MAD as a test-time computational scaling technique, distinguished by collaborative refinement and diverse exploration capabilities. We conduct a comprehensive empirical investigation comparing MAD with strong self-agent test-time scaling baselines on mathematical reasoning and safety-related tasks. Our study systematically examines the influence of task difficulty, model scale, and agent diversity on MAD's performance. Key findings reveal that, for mathematical reasoning, MAD offers limited advantages over self-agent scaling but becomes more effective with increased problem difficulty and decreased model capability, while agent diversity shows little benefit. Conversely, for safety tasks, MAD's collaborative refinement can increase vulnerability, but incorporating diverse agent configurations facilitates a gradual reduction in attack success through the collaborative refinement process. We believe our findings provide critical guidance for the future development of more effective and strategically deployed MAD systems.
Guiding Reasoning in Small Language Models with LLM Assistance
Apr 14, 2025



The limited reasoning capabilities of small language models (SLMs) cast doubt on their suitability for tasks demanding deep, multi-step logical deduction. This paper introduces a framework called Small Reasons, Large Hints (SMART), which selectively augments SLM reasoning with targeted guidance from large language models (LLMs). Inspired by the concept of cognitive scaffolding, SMART employs a score-based evaluation to identify uncertain reasoning steps and injects corrective LLM-generated reasoning only when necessary. By framing structured reasoning as an optimal policy search, our approach steers the reasoning trajectory toward correct solutions without exhaustive sampling. Our experiments on mathematical reasoning datasets demonstrate that targeted external scaffolding significantly improves performance, paving the way for collaborative use of both SLM and LLM to tackle complex reasoning tasks that are currently unsolvable by SLMs alone.
Towards Fast Multilingual LLM Inference: Speculative Decoding and Specialized Drafters
Jun 24, 2024



Large language models (LLMs) have revolutionized natural language processing and broadened their applicability across diverse commercial applications. However, the deployment of these models is constrained by high inference time in multilingual settings. To mitigate this challenge, this paper explores a training recipe of an assistant model in speculative decoding, which are leveraged to draft and-then its future tokens are verified by the target LLM. We show that language-specific draft models, optimized through a targeted pretrain-and-finetune strategy, substantially brings a speedup of inference time compared to the previous methods. We validate these models across various languages in inference time, out-of-domain speedup, and GPT-4o evaluation.