 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUltraEP: Unleash MoE Training and Inference on Rack-Scale Nodes with Near-Optimal Load Balancing
Jun 02, 2026Large-scale expert parallelism (EP) is becoming pivotal for training and serving frontier MoE models, but it also amplifies device-level expert load imbalance into compute stragglers, token all-to-all bottlenecks, and activation-memory spikes. Existing balancers redistribute experts periodically based on historical load, which becomes unreliable for production deployments with non-stationary load patterns. We present UltraEP, the first exact-load, real-time balancer for large-EP MoE training and serving prefill on rack-scale nodes (RSNs). Built upon the extended scale-up connectivity of RSNs, UltraEP rebalances every microbatch and layer on critical paths, which requires nontrivial co-design of plan solving and expert replication communication to minimize exposed overhead. To this end, UltraEP eagerly reacts to post-gating load with efficient quota-driven planning, and executes the resulting irregular expert-state transfers with RSN-native persistent tile streaming and relay-based fan-out mitigation. Averaged across MoE models from 106B to 671B parameters in training and prefill, UltraEP achieves 94.3% of the force-balanced ideal throughput, delivering 1.49$\times$ improvement over non-balancing, while reducing the final inter-rank imbalance from 1.30$-$4.01 to 1.01$-$1.04. Additionally, we validate UltraEP's scalability and robustness in production MoE training with 2560 GPUs.
BigMac: Breaking the Pareto Frontier of Compute and Memory in Multimodal LLM Training
May 25, 2026Training multimodal large language models (MLLMs) is challenged by both model and data heterogeneity. Existing systems redesign the training pipeline to address these challenges, but remain bound by a Pareto frontier between compute and memory efficiency, improving one only at the expense of the other. We present BigMac, a new training pipeline for multimodal LLMs. The core idea of BigMac is to elegantly nest the encoder and generator computation into the original LLM pipeline, forming a dependency-safe nested pipeline structure. With this design, BigMac reduces the activation memory complexity of the encoder and generator to O(1) while keeping the activation memory complexity of the LLM unchanged. At the same time, it achieves the same computational efficiency as the idealized setting with unlimited memory. As a result, BigMac breaks the Pareto frontier between computational efficiency and memory usage, enabling simultaneous optimization of both computation and memory in MLLM training. We evaluate BigMac on multiple MLLMs and training workloads. Experimental results show that BigMac achieves a 1.08$\times$-1.9$\times$ training speedup over baseline systems while maintaining stable memory usage as batch size increases.
Heddle: A Distributed Orchestration System for Agentic RL Rollout
Mar 30, 2026Agentic Reinforcement Learning (RL) enables LLMs to solve complex tasks by alternating between a data-collection rollout phase and a policy training phase. During rollout, the agent generates trajectories, i.e., multi-step interactions between LLMs and external tools. Yet, frequent tool calls induce long-tailed trajectory generation that bottlenecks rollouts. This stems from step-centric designs that ignore trajectory context, triggering three system problems for long-tail trajectory generation: queueing delays, interference overhead, and inflated per-token time. We propose Heddle, a trajectory-centric system to optimize the when, where, and how of agentic rollout execution. Heddle integrates three core mechanisms: trajectory-level scheduling using runtime prediction and progressive priority to minimize cumulative queueing; trajectory-aware placement via presorted dynamic programming and opportunistic migration during idle tool call intervals to minimize interference; and trajectory-adaptive resource manager that dynamically tunes model parallelism to accelerate the per-token time of long-tail trajectories while maintaining high throughput for short trajectories. Evaluations across diverse agentic RL workloads demonstrate that Heddle effectively neutralizes the long-tail bottleneck, achieving up to 2.5$\times$ higher end-to-end rollout throughput compared to state-of-the-art baselines.
Visual Attention Drifts,but Anchors Hold:Mitigating Hallucination in Multimodal Large Language Models via Cross-Layer Visual Anchors
Mar 26, 2026Multimodal Large Language Models often suffer from object hallucination. While existing research utilizes attention enhancement and visual retracing, we find these works lack sufficient interpretability regarding attention drift in final model stages. In this paper, we investigate the layer wise evolution of visual features and discover that hallucination stems from deep layer attention regressing toward initial visual noise from early layers. We observe that output reliability depends on acquiring visual anchors at intermediate layers rather than final layers. Based on these insights, we propose CLVA, which stands for Cross-Layer Visual Anchors, a training free method that reinforces critical mid layer features while suppressing regressive noise. This approach effectively pulls deep layer attention back to correct visual regions by utilizing essential anchors captured from attention dynamics. We evaluate our method across diverse architectures and benchmarks, demonstrating outstanding performance without significant increase in computational time and GPU memory.
Heaven-Sent or Hell-Bent? Benchmarking the Intelligence and Defectiveness of LLM Hallucinations
Dec 25, 2025



Hallucinations in large language models (LLMs) are commonly regarded as errors to be minimized. However, recent perspectives suggest that some hallucinations may encode creative or epistemically valuable content, a dimension that remains underquantified in current literature. Existing hallucination detection methods primarily focus on factual consistency, struggling to handle heterogeneous scientific tasks and balance creativity with accuracy. To address these challenges, we propose HIC-Bench, a novel evaluation framework that categorizes hallucinations into Intelligent Hallucinations (IH) and Defective Hallucinations (DH), enabling systematic investigation of their interplay in LLM creativity. HIC-Bench features three core characteristics: (1) Structured IH/DH Assessment. using a multi-dimensional metric matrix integrating Torrance Tests of Creative Thinking (TTCT) metrics (Originality, Feasibility, Value) with hallucination-specific dimensions (scientific plausibility, factual deviation); (2) Cross-Domain Applicability. spanning ten scientific domains with open-ended innovation tasks; and (3) Dynamic Prompt Optimization. leveraging the Dynamic Hallucination Prompt (DHP) to guide models toward creative and reliable outputs. The evaluation process employs multiple LLM judges, averaging scores to mitigate bias, with human annotators verifying IH/DH classifications. Experimental results reveal a nonlinear relationship between IH and DH, demonstrating that creativity and correctness can be jointly optimized. These insights position IH as a catalyst for creativity and reveal the ability of LLM hallucinations to drive scientific innovation.Additionally, the HIC-Bench offers a valuable platform for advancing research into the creative intelligence of LLM hallucinations.
MIND: A Noise-Adaptive Denoising Framework for Medical Images Integrating Multi-Scale Transformer
Aug 13, 2025The core role of medical images in disease diagnosis makes their quality directly affect the accuracy of clinical judgment. However, due to factors such as low-dose scanning, equipment limitations and imaging artifacts, medical images are often accompanied by non-uniform noise interference, which seriously affects structure recognition and lesion detection. This paper proposes a medical image adaptive denoising model (MI-ND) that integrates multi-scale convolutional and Transformer architecture, introduces a noise level estimator (NLE) and a noise adaptive attention module (NAAB), and realizes channel-spatial attention regulation and cross-modal feature fusion driven by noise perception. Systematic testing is carried out on multimodal public datasets. Experiments show that this method significantly outperforms the comparative methods in image quality indicators such as PSNR, SSIM, and LPIPS, and improves the F1 score and ROC-AUC in downstream diagnostic tasks, showing strong prac-tical value and promotional potential. The model has outstanding benefits in structural recovery, diagnostic sensitivity, and cross-modal robustness, and provides an effective solution for medical image enhancement and AI-assisted diagnosis and treatment.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
Automatic Text Pronunciation Correlation Generation and Application for Contextual Biasing
Jan 01, 2025



Effectively distinguishing the pronunciation correlations between different written texts is a significant issue in linguistic acoustics. Traditionally, such pronunciation correlations are obtained through manually designed pronunciation lexicons. In this paper, we propose a data-driven method to automatically acquire these pronunciation correlations, called automatic text pronunciation correlation (ATPC). The supervision required for this method is consistent with the supervision needed for training end-to-end automatic speech recognition (E2E-ASR) systems, i.e., speech and corresponding text annotations. First, the iteratively-trained timestamp estimator (ITSE) algorithm is employed to align the speech with their corresponding annotated text symbols. Then, a speech encoder is used to convert the speech into speech embeddings. Finally, we compare the speech embeddings distances of different text symbols to obtain ATPC. Experimental results on Mandarin show that ATPC enhances E2E-ASR performance in contextual biasing and holds promise for dialects or languages lacking artificial pronunciation lexicons.
Heterogeneity-Aware Federated Learning
Jun 12, 2020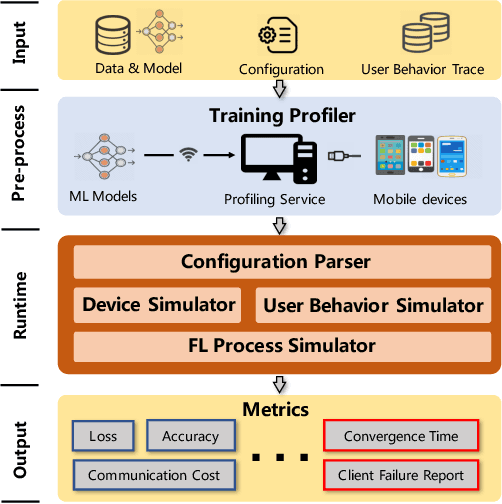
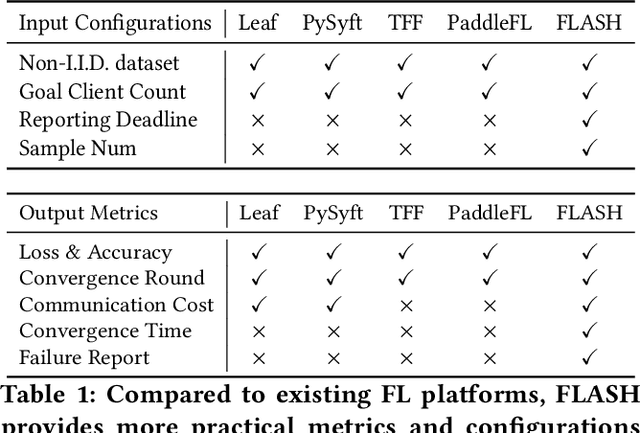
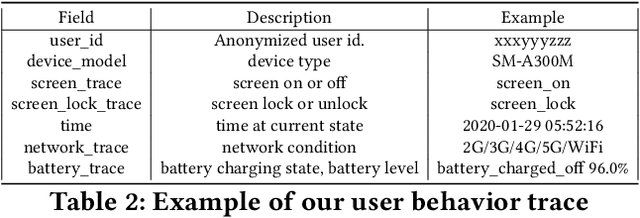
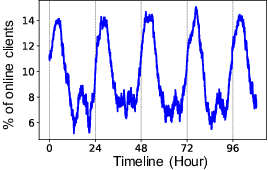
Federated learning (FL) is an emerging distributed machine learning paradigm that stands out with its inherent privacy-preserving advantages. Heterogeneity is one of the core challenges in FL, which resides in the diverse user behaviors and hardware capacity across devices who participate in the training. Heterogeneity inherently exerts a huge influence on the FL training process, e.g., causing device unavailability. However, existing FL literature usually ignores the impacts of heterogeneity. To fill in the knowledge gap, we build FLASH, the first heterogeneity-aware FL platform. Based on FLASH and a large-scale user trace from 136k real-world users, we demonstrate the usefulness of FLASH in anatomizing the impacts of heterogeneity in FL by exploring three previously unaddressed research questions: whether and how can heterogeneity affect FL performance; how to configure a heterogeneity-aware FL system; and what are heterogeneity's impacts on existing FL optimizations. It shows that heterogeneity causes nontrivial performance degradation in FL from various aspects, and even invalidates some typical FL optimizations.