 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDivergence-aware Federated Self-Supervised Learning
Apr 09, 2022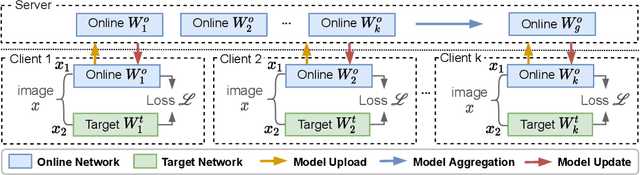
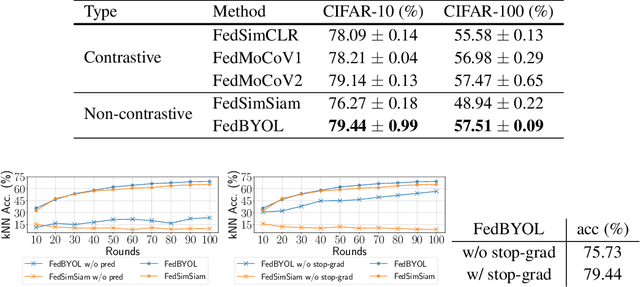
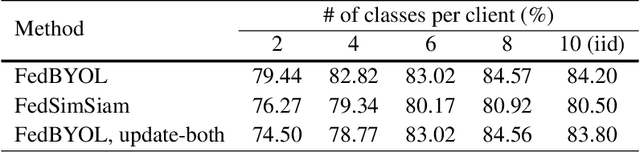
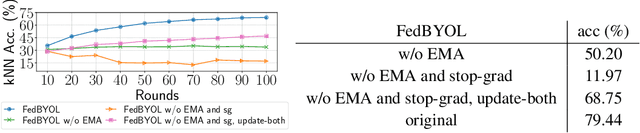
Self-supervised learning (SSL) is capable of learning remarkable representations from centrally available data. Recent works further implement federated learning with SSL to learn from rapidly growing decentralized unlabeled images (e.g., from cameras and phones), often resulted from privacy constraints. Extensive attention has been paid to SSL approaches based on Siamese networks. However, such an effort has not yet revealed deep insights into various fundamental building blocks for the federated self-supervised learning (FedSSL) architecture. We aim to fill in this gap via in-depth empirical study and propose a new method to tackle the non-independently and identically distributed (non-IID) data problem of decentralized data. Firstly, we introduce a generalized FedSSL framework that embraces existing SSL methods based on Siamese networks and presents flexibility catering to future methods. In this framework, a server coordinates multiple clients to conduct SSL training and periodically updates local models of clients with the aggregated global model. Using the framework, our study uncovers unique insights of FedSSL: 1) stop-gradient operation, previously reported to be essential, is not always necessary in FedSSL; 2) retaining local knowledge of clients in FedSSL is particularly beneficial for non-IID data. Inspired by the insights, we then propose a new approach for model update, Federated Divergence-aware Exponential Moving Average update (FedEMA). FedEMA updates local models of clients adaptively using EMA of the global model, where the decay rate is dynamically measured by model divergence. Extensive experiments demonstrate that FedEMA outperforms existing methods by 3-4% on linear evaluation. We hope that this work will provide useful insights for future research.
Federated Unsupervised Domain Adaptation for Face Recognition
Apr 09, 2022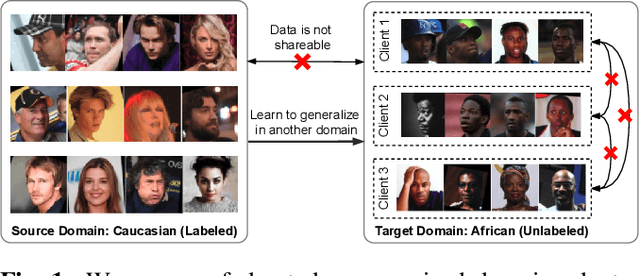

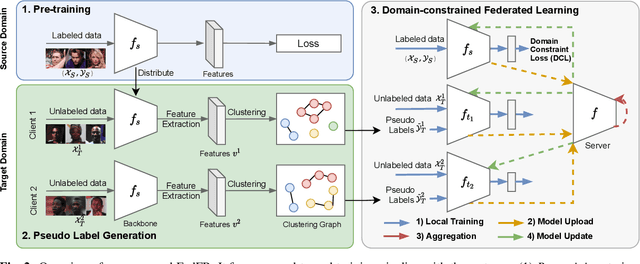
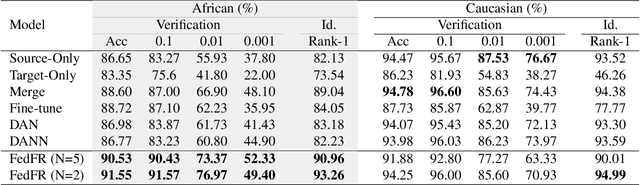
Given labeled data in a source domain, unsupervised domain adaptation has been widely adopted to generalize models for unlabeled data in a target domain, whose data distributions are different. However, existing works are inapplicable to face recognition under privacy constraints because they require sharing of sensitive face images between domains. To address this problem, we propose federated unsupervised domain adaptation for face recognition, FedFR. FedFR jointly optimizes clustering-based domain adaptation and federated learning to elevate performance on the target domain. Specifically, for unlabeled data in the target domain, we enhance a clustering algorithm with distance constrain to improve the quality of predicted pseudo labels. Besides, we propose a new domain constraint loss (DCL) to regularize source domain training in federated learning. Extensive experiments on a newly constructed benchmark demonstrate that FedFR outperforms the baseline and classic methods on the target domain by 3% to 14% on different evaluation metrics.
Characterization and Prediction of Deep Learning Workloads in Large-Scale GPU Datacenters
Sep 06, 2021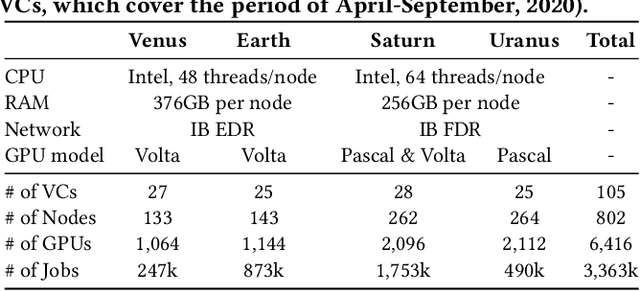
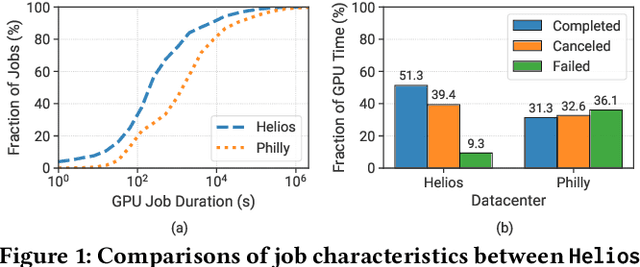

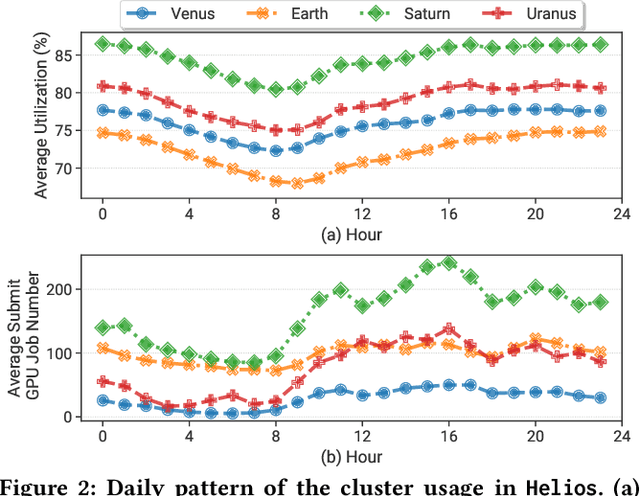
Modern GPU datacenters are critical for delivering Deep Learning (DL) models and services in both the research community and industry. When operating a datacenter, optimization of resource scheduling and management can bring significant financial benefits. Achieving this goal requires a deep understanding of the job features and user behaviors. We present a comprehensive study about the characteristics of DL jobs and resource management. First, we perform a large-scale analysis of real-world job traces from SenseTime. We uncover some interesting conclusions from the perspectives of clusters, jobs and users, which can facilitate the cluster system designs. Second, we introduce a general-purpose framework, which manages resources based on historical data. As case studies, we design: a Quasi-Shortest-Service-First scheduling service, which can minimize the cluster-wide average job completion time by up to 6.5x; and a Cluster Energy Saving service, which improves overall cluster utilization by up to 13%.
Are Missing Links Predictable? An Inferential Benchmark for Knowledge Graph Completion
Aug 25, 2021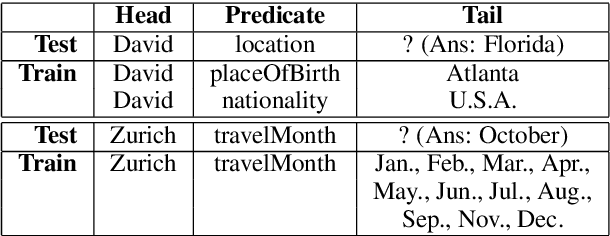
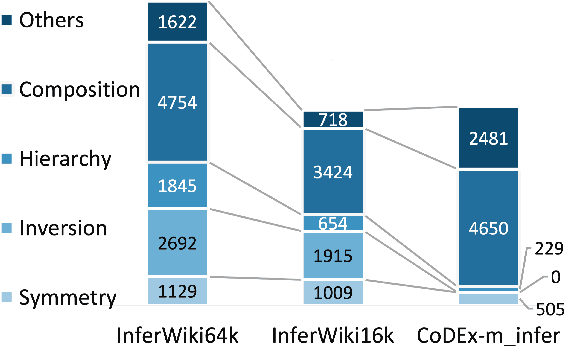
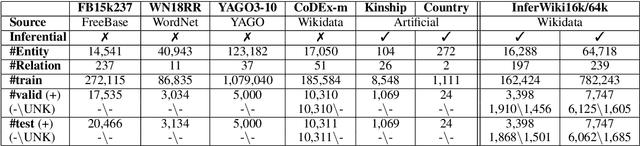
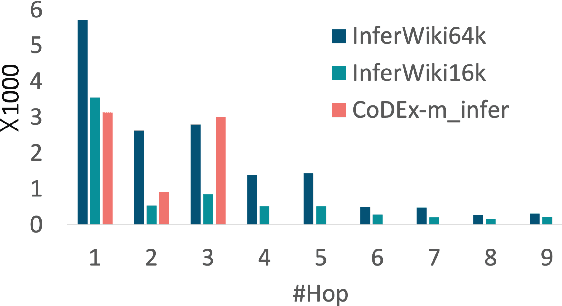
We present InferWiki, a Knowledge Graph Completion (KGC) dataset that improves upon existing benchmarks in inferential ability, assumptions, and patterns. First, each testing sample is predictable with supportive data in the training set. To ensure it, we propose to utilize rule-guided train/test generation, instead of conventional random split. Second, InferWiki initiates the evaluation following the open-world assumption and improves the inferential difficulty of the closed-world assumption, by providing manually annotated negative and unknown triples. Third, we include various inference patterns (e.g., reasoning path length and types) for comprehensive evaluation. In experiments, we curate two settings of InferWiki varying in sizes and structures, and apply the construction process on CoDEx as comparative datasets. The results and empirical analyses demonstrate the necessity and high-quality of InferWiki. Nevertheless, the performance gap among various inferential assumptions and patterns presents the difficulty and inspires future research direction. Our datasets can be found in https://github.com/TaoMiner/inferwiki
Joint Optimization in Edge-Cloud Continuum for Federated Unsupervised Person Re-identification
Aug 14, 2021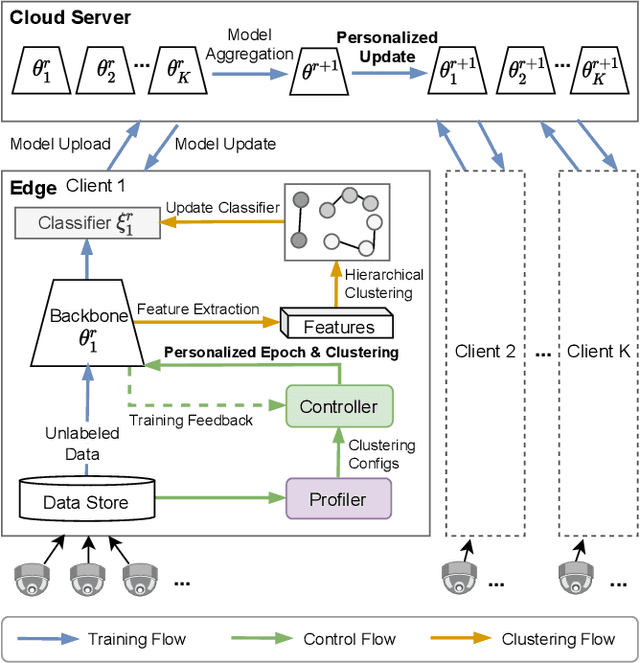
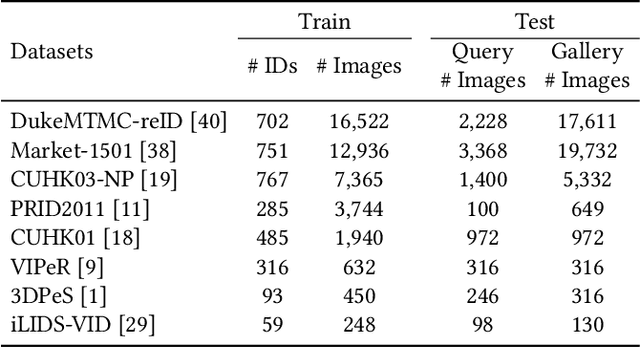
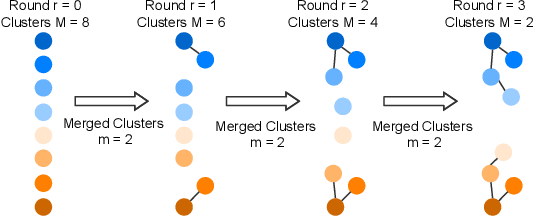
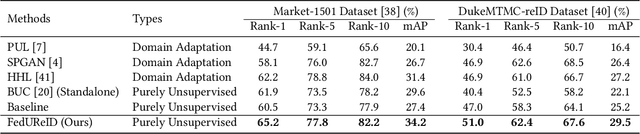
Person re-identification (ReID) aims to re-identify a person from non-overlapping camera views. Since person ReID data contains sensitive personal information, researchers have adopted federated learning, an emerging distributed training method, to mitigate the privacy leakage risks. However, existing studies rely on data labels that are laborious and time-consuming to obtain. We present FedUReID, a federated unsupervised person ReID system to learn person ReID models without any labels while preserving privacy. FedUReID enables in-situ model training on edges with unlabeled data. A cloud server aggregates models from edges instead of centralizing raw data to preserve data privacy. Moreover, to tackle the problem that edges vary in data volumes and distributions, we personalize training in edges with joint optimization of cloud and edge. Specifically, we propose personalized epoch to reassign computation throughout training, personalized clustering to iteratively predict suitable labels for unlabeled data, and personalized update to adapt the server aggregated model to each edge. Extensive experiments on eight person ReID datasets demonstrate that FedUReID not only achieves higher accuracy but also reduces computation cost by 29%. Our FedUReID system with the joint optimization will shed light on implementing federated learning to more multimedia tasks without data labels.
Collaborative Unsupervised Visual Representation Learning from Decentralized Data
Aug 14, 2021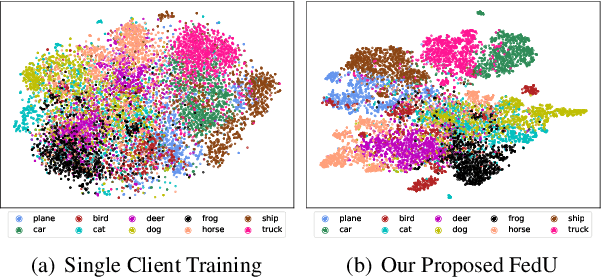
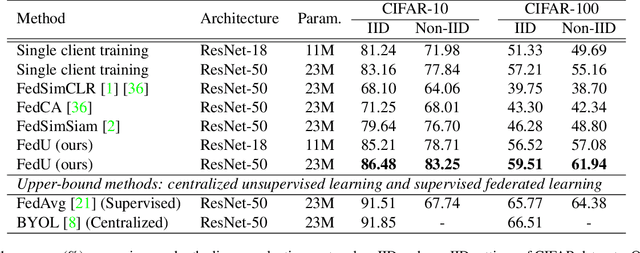
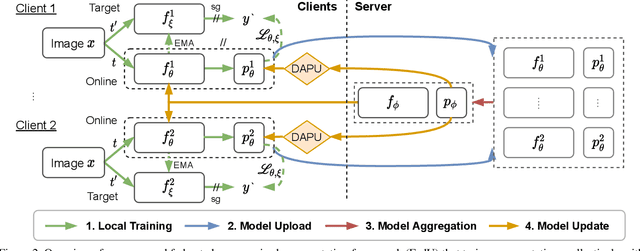
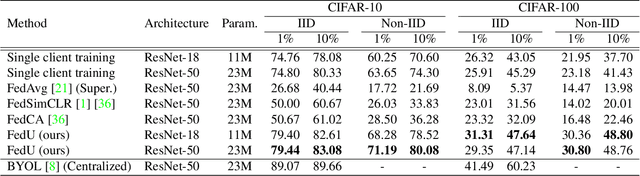
Unsupervised representation learning has achieved outstanding performances using centralized data available on the Internet. However, the increasing awareness of privacy protection limits sharing of decentralized unlabeled image data that grows explosively in multiple parties (e.g., mobile phones and cameras). As such, a natural problem is how to leverage these data to learn visual representations for downstream tasks while preserving data privacy. To address this problem, we propose a novel federated unsupervised learning framework, FedU. In this framework, each party trains models from unlabeled data independently using contrastive learning with an online network and a target network. Then, a central server aggregates trained models and updates clients' models with the aggregated model. It preserves data privacy as each party only has access to its raw data. Decentralized data among multiple parties are normally non-independent and identically distributed (non-IID), leading to performance degradation. To tackle this challenge, we propose two simple but effective methods: 1) We design the communication protocol to upload only the encoders of online networks for server aggregation and update them with the aggregated encoder; 2) We introduce a new module to dynamically decide how to update predictors based on the divergence caused by non-IID. The predictor is the other component of the online network. Extensive experiments and ablations demonstrate the effectiveness and significance of FedU. It outperforms training with only one party by over 5% and other methods by over 14% in linear and semi-supervised evaluation on non-IID data.
Exploring Sequence Feature Alignment for Domain Adaptive Detection Transformers
Aug 05, 2021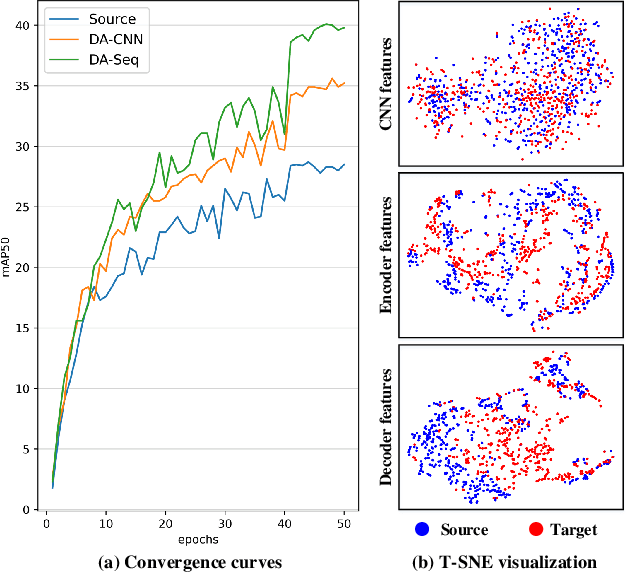
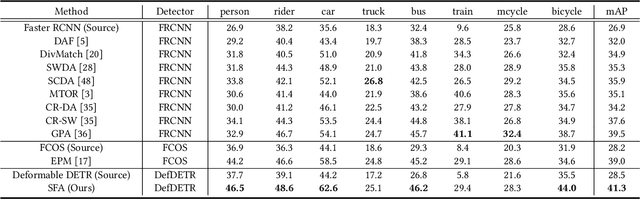
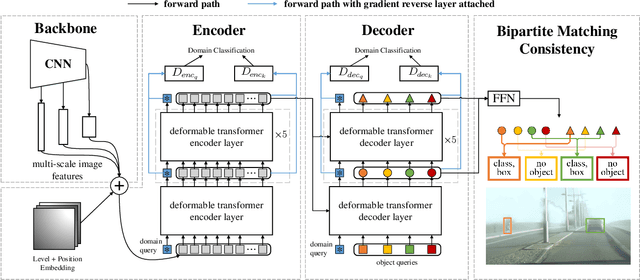
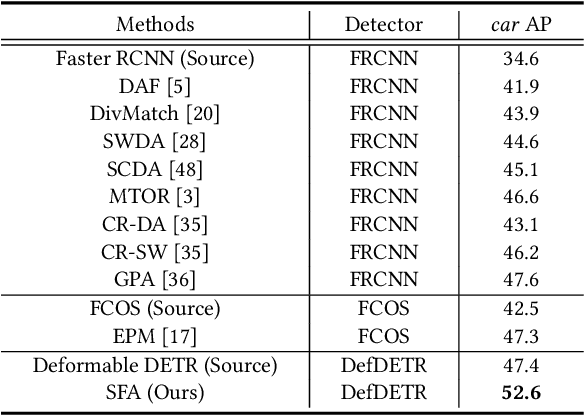
Detection transformers have recently shown promising object detection results and attracted increasing attention. However, how to develop effective domain adaptation techniques to improve its cross-domain performance remains unexplored and unclear. In this paper, we delve into this topic and empirically find that direct feature distribution alignment on the CNN backbone only brings limited improvements, as it does not guarantee domain-invariant sequence features in the transformer for prediction. To address this issue, we propose a novel Sequence Feature Alignment (SFA) method that is specially designed for the adaptation of detection transformers. Technically, SFA consists of a domain query-based feature alignment (DQFA) module and a token-wise feature alignment (TDA) module. In DQFA, a novel domain query is used to aggregate and align global context from the token sequence of both domains. DQFA reduces the domain discrepancy in global feature representations and object relations when deploying in the transformer encoder and decoder, respectively. Meanwhile, TDA aligns token features in the sequence from both domains, which reduces the domain gaps in local and instance-level feature representations in the transformer encoder and decoder, respectively. Besides, a novel bipartite matching consistency loss is proposed to enhance the feature discriminability for robust object detection. Experiments on three challenging benchmarks show that SFA outperforms state-of-the-art domain adaptive object detection methods. Code has been made available at: https://github.com/encounter1997/SFA.
ModelCI-e: Enabling Continual Learning in Deep Learning Serving Systems
Jun 06, 2021
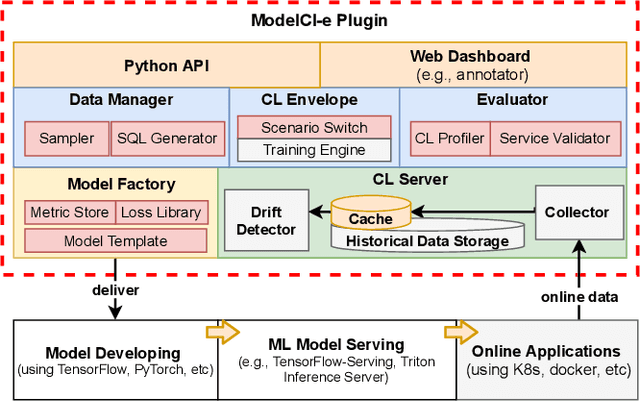
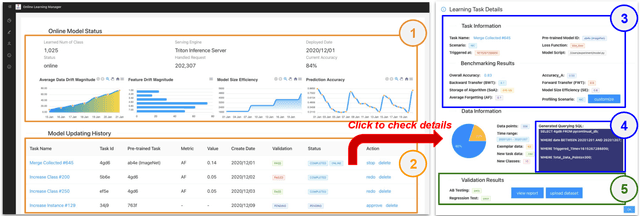

MLOps is about taking experimental ML models to production, i.e., serving the models to actual users. Unfortunately, existing ML serving systems do not adequately handle the dynamic environments in which online data diverges from offline training data, resulting in tedious model updating and deployment works. This paper implements a lightweight MLOps plugin, termed ModelCI-e (continuous integration and evolution), to address the issue. Specifically, it embraces continual learning (CL) and ML deployment techniques, providing end-to-end supports for model updating and validation without serving engine customization. ModelCI-e includes 1) a model factory that allows CL researchers to prototype and benchmark CL models with ease, 2) a CL backend to automate and orchestrate the model updating efficiently, and 3) a web interface for an ML team to manage CL service collaboratively. Our preliminary results demonstrate the usability of ModelCI-e, and indicate that eliminating the interference between model updating and inference workloads is crucial for higher system efficiency.
ModelPS: An Interactive and Collaborative Platform for Editing Pre-trained Models at Scale
May 26, 2021
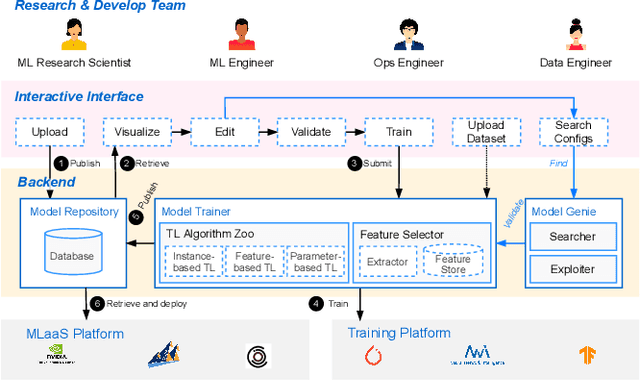
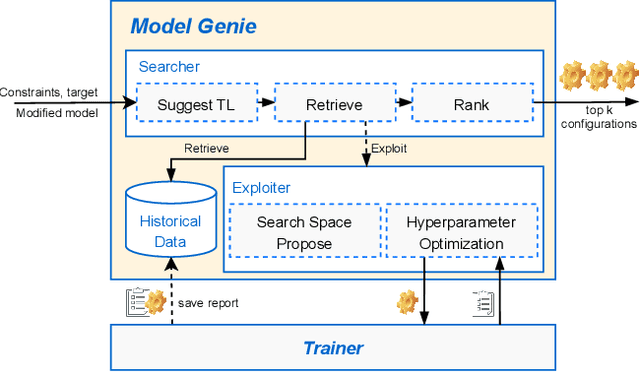
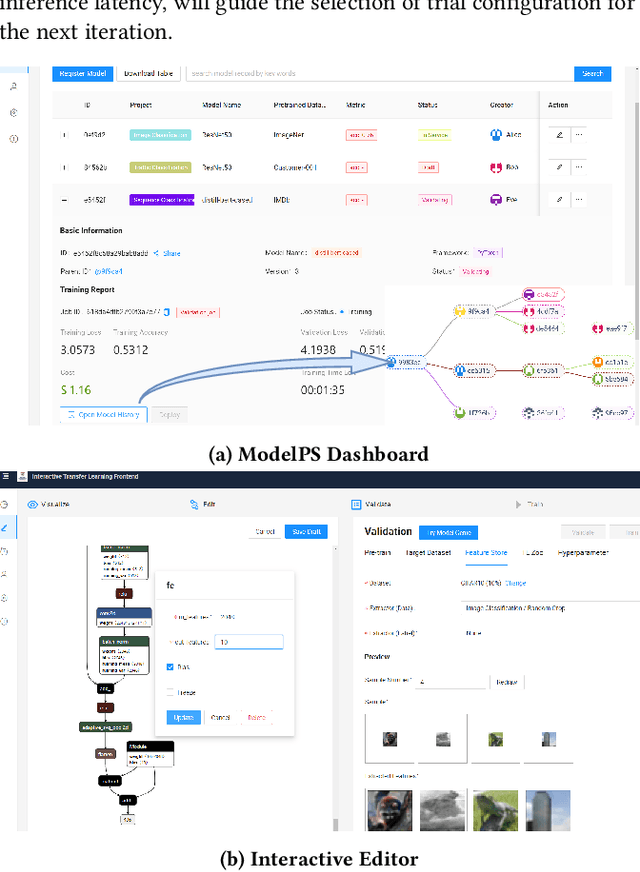
AI engineering has emerged as a crucial discipline to democratize deep neural network (DNN) models among software developers with a diverse background. In particular, altering these DNN models in the deployment stage posits a tremendous challenge. In this research, we propose and develop a low-code solution, ModelPS (an acronym for "Model Photoshop"), to enable and empower collaborative DNN model editing and intelligent model serving. The ModelPS solution embodies two transformative features: 1) a user-friendly web interface for a developer team to share and edit DNN models pictorially, in a low-code fashion, and 2) a model genie engine in the backend to aid developers in customizing model editing configurations for given deployment requirements or constraints. Our case studies with a wide range of deep learning (DL) models show that the system can tremendously reduce both development and communication overheads with improved productivity. The code has been released as an open-source package at GitHub.
Towards Unsupervised Domain Adaptation for Deep Face Recognition under Privacy Constraints via Federated Learning
May 17, 2021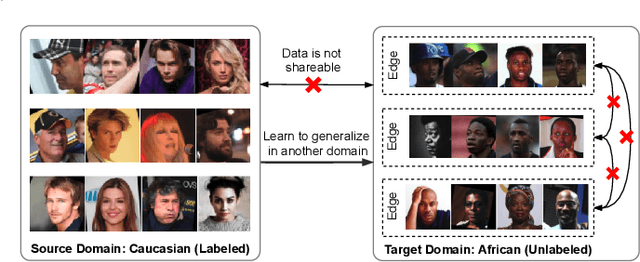

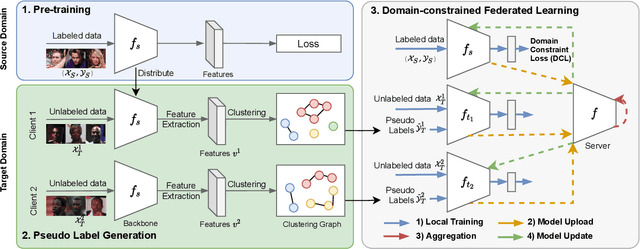
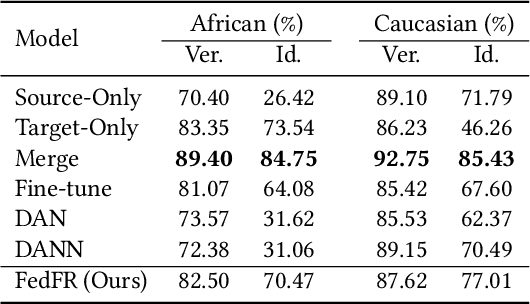
Unsupervised domain adaptation has been widely adopted to generalize models for unlabeled data in a target domain, given labeled data in a source domain, whose data distributions differ from the target domain. However, existing works are inapplicable to face recognition under privacy constraints because they require sharing sensitive face images between two domains. To address this problem, we propose a novel unsupervised federated face recognition approach (FedFR). FedFR improves the performance in the target domain by iteratively aggregating knowledge from the source domain through federated learning. It protects data privacy by transferring models instead of raw data between domains. Besides, we propose a new domain constraint loss (DCL) to regularize source domain training. DCL suppresses the data volume dominance of the source domain. We also enhance a hierarchical clustering algorithm to predict pseudo labels for the unlabeled target domain accurately. To this end, FedFR forms an end-to-end training pipeline: (1) pre-train in the source domain; (2) predict pseudo labels by clustering in the target domain; (3) conduct domain-constrained federated learning across two domains. Extensive experiments and analysis on two newly constructed benchmarks demonstrate the effectiveness of FedFR. It outperforms the baseline and classic methods in the target domain by over 4% on the more realistic benchmark. We believe that FedFR will shed light on applying federated learning to more computer vision tasks under privacy constraints.