 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Representation Adaptation Network for Cross-domain Image Classification
Jan 04, 2022
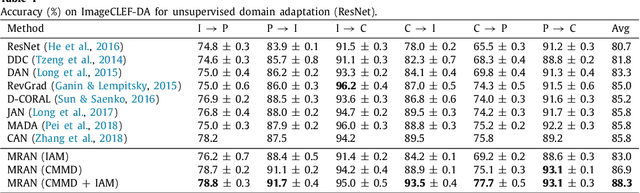
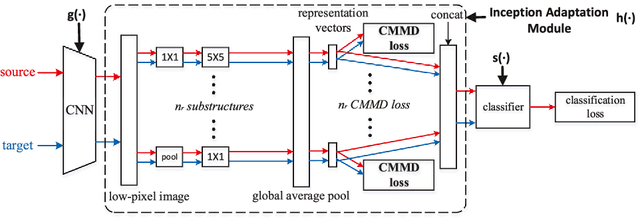
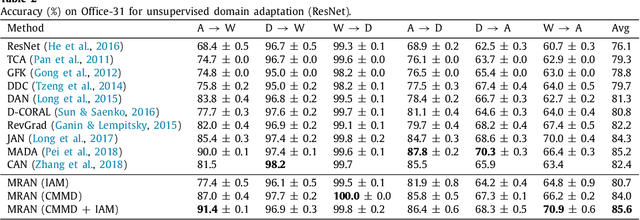
In image classification, it is often expensive and time-consuming to acquire sufficient labels. To solve this problem, domain adaptation often provides an attractive option given a large amount of labeled data from a similar nature but different domain. Existing approaches mainly align the distributions of representations extracted by a single structure and the representations may only contain partial information, e.g., only contain part of the saturation, brightness, and hue information. Along this line, we propose Multi-Representation Adaptation which can dramatically improve the classification accuracy for cross-domain image classification and specially aims to align the distributions of multiple representations extracted by a hybrid structure named Inception Adaptation Module (IAM). Based on this, we present Multi-Representation Adaptation Network (MRAN) to accomplish the cross-domain image classification task via multi-representation alignment which can capture the information from different aspects. In addition, we extend Maximum Mean Discrepancy (MMD) to compute the adaptation loss. Our approach can be easily implemented by extending most feed-forward models with IAM, and the network can be trained efficiently via back-propagation. Experiments conducted on three benchmark image datasets demonstrate the effectiveness of MRAN. The code has been available at https://github.com/easezyc/deep-transfer-learning.
MDFEND: Multi-domain Fake News Detection
Jan 04, 2022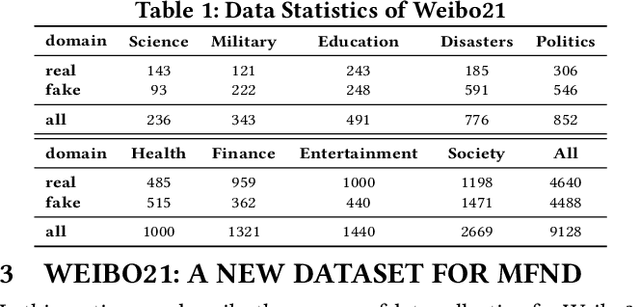

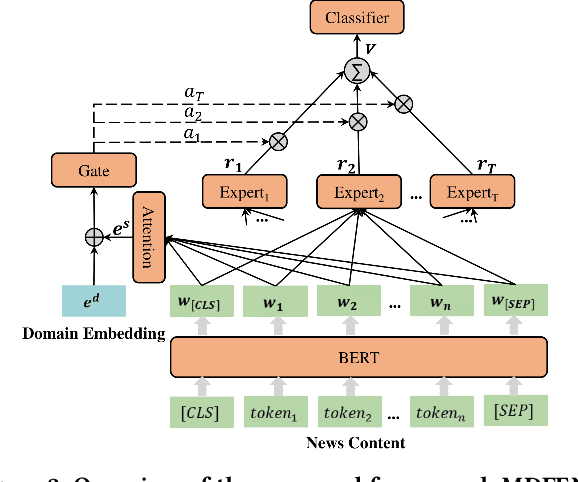
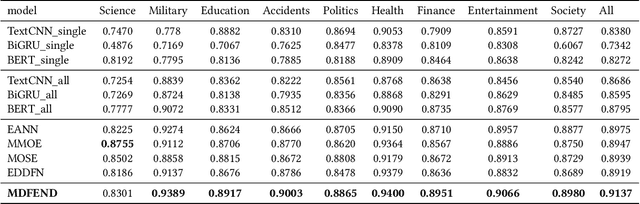
Fake news spread widely on social media in various domains, which lead to real-world threats in many aspects like politics, disasters, and finance. Most existing approaches focus on single-domain fake news detection (SFND), which leads to unsatisfying performance when these methods are applied to multi-domain fake news detection. As an emerging field, multi-domain fake news detection (MFND) is increasingly attracting attention. However, data distributions, such as word frequency and propagation patterns, vary from domain to domain, namely domain shift. Facing the challenge of serious domain shift, existing fake news detection techniques perform poorly for multi-domain scenarios. Therefore, it is demanding to design a specialized model for MFND. In this paper, we first design a benchmark of fake news dataset for MFND with domain label annotated, namely Weibo21, which consists of 4,488 fake news and 4,640 real news from 9 different domains. We further propose an effective Multi-domain Fake News Detection Model (MDFEND) by utilizing a domain gate to aggregate multiple representations extracted by a mixture of experts. The experiments show that MDFEND can significantly improve the performance of multi-domain fake news detection. Our dataset and code are available at https://github.com/kennqiang/MDFEND-Weibo21.
Neural Hierarchical Factorization Machines for User's Event Sequence Analysis
Dec 31, 2021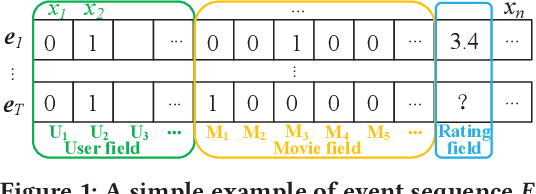
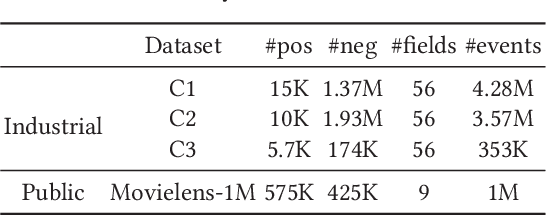
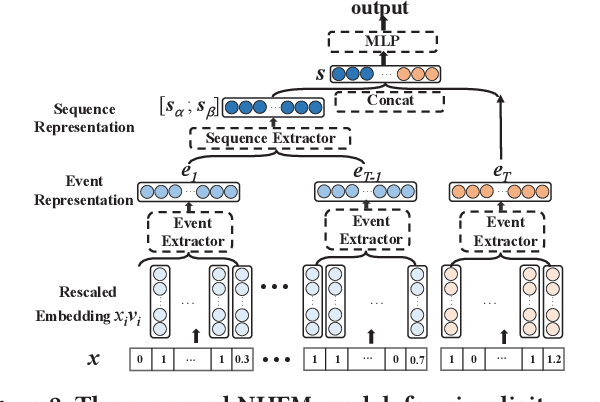
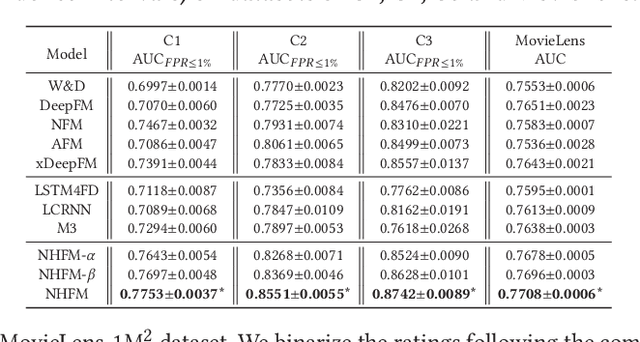
Many prediction tasks of real-world applications need to model multi-order feature interactions in user's event sequence for better detection performance. However, existing popular solutions usually suffer two key issues: 1) only focusing on feature interactions and failing to capture the sequence influence; 2) only focusing on sequence information, but ignoring internal feature relations of each event, thus failing to extract a better event representation. In this paper, we consider a two-level structure for capturing the hierarchical information over user's event sequence: 1) learning effective feature interactions based event representation; 2) modeling the sequence representation of user's historical events. Experimental results on both industrial and public datasets clearly demonstrate that our model achieves significantly better performance compared with state-of-the-art baselines.
Personalized Transfer of User Preferences for Cross-domain Recommendation
Oct 22, 2021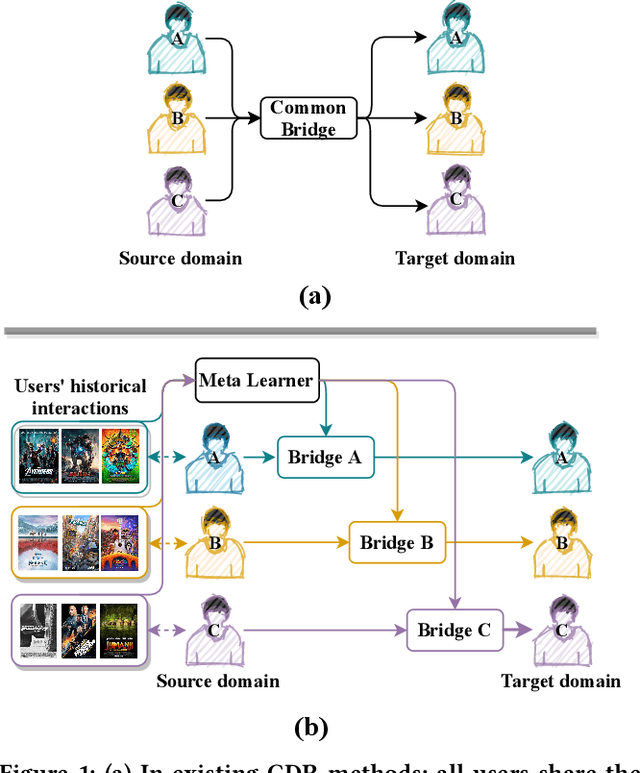

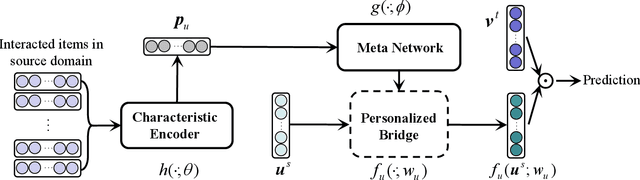
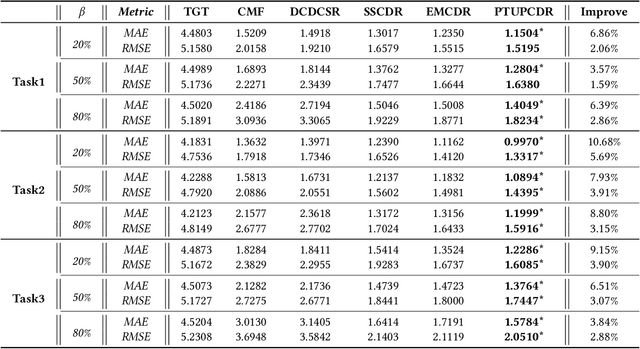
Cold-start problem is still a very challenging problem in recommender systems. Fortunately, the interactions of the cold-start users in the auxiliary source domain can help cold-start recommendations in the target domain. How to transfer user's preferences from the source domain to the target domain, is the key issue in Cross-domain Recommendation (CDR) which is a promising solution to deal with the cold-start problem. Most existing methods model a common preference bridge to transfer preferences for all users. Intuitively, since preferences vary from user to user, the preference bridges of different users should be different. Along this line, we propose a novel framework named Personalized Transfer of User Preferences for Cross-domain Recommendation (PTUPCDR). Specifically, a meta network fed with users' characteristic embeddings is learned to generate personalized bridge functions to achieve personalized transfer of preferences for each user. To learn the meta network stably, we employ a task-oriented optimization procedure. With the meta-generated personalized bridge function, the user's preference embedding in the source domain can be transformed into the target domain, and the transformed user preference embedding can be utilized as the initial embedding for the cold-start user in the target domain. Using large real-world datasets, we conduct extensive experiments to evaluate the effectiveness of PTUPCDR on both cold-start and warm-start stages. The code has been available at \url{https://github.com/easezyc/WSDM2022-PTUPCDR}.
Deep Subdomain Adaptation Network for Image Classification
Jun 17, 2021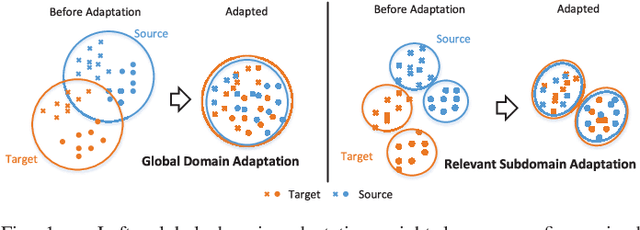
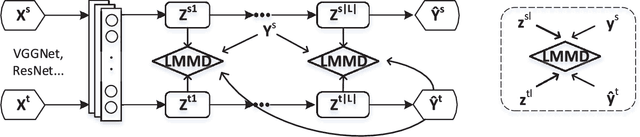
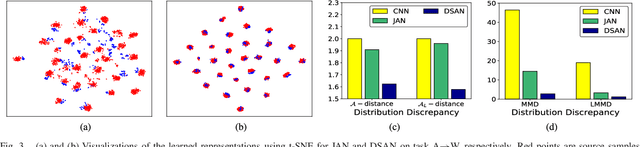
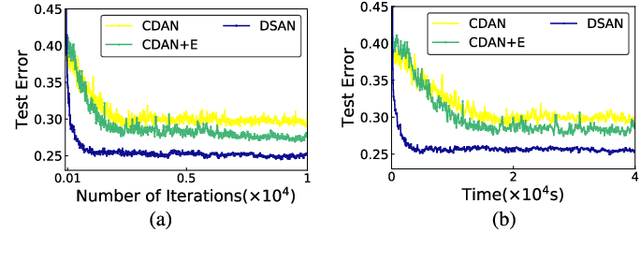
For a target task where labeled data is unavailable, domain adaptation can transfer a learner from a different source domain. Previous deep domain adaptation methods mainly learn a global domain shift, i.e., align the global source and target distributions without considering the relationships between two subdomains within the same category of different domains, leading to unsatisfying transfer learning performance without capturing the fine-grained information. Recently, more and more researchers pay attention to Subdomain Adaptation which focuses on accurately aligning the distributions of the relevant subdomains. However, most of them are adversarial methods which contain several loss functions and converge slowly. Based on this, we present Deep Subdomain Adaptation Network (DSAN) which learns a transfer network by aligning the relevant subdomain distributions of domain-specific layer activations across different domains based on a local maximum mean discrepancy (LMMD). Our DSAN is very simple but effective which does not need adversarial training and converges fast. The adaptation can be achieved easily with most feed-forward network models by extending them with LMMD loss, which can be trained efficiently via back-propagation. Experiments demonstrate that DSAN can achieve remarkable results on both object recognition tasks and digit classification tasks. Our code will be available at: https://github.com/easezyc/deep-transfer-learning
Learning to Expand Audience via Meta Hybrid Experts and Critics for Recommendation and Advertising
May 31, 2021

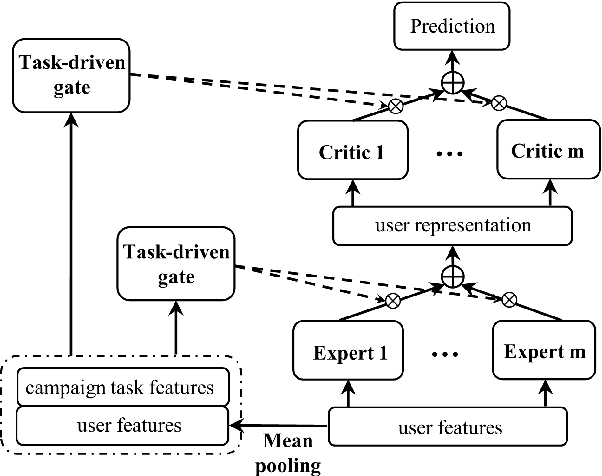
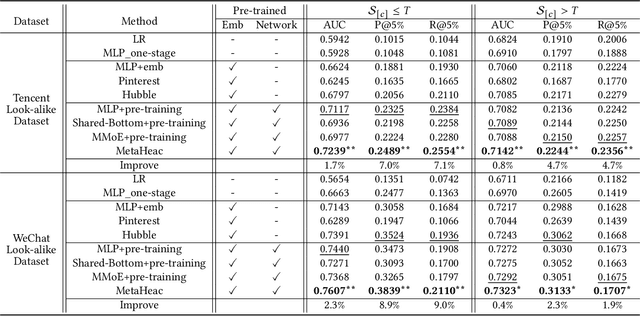
In recommender systems and advertising platforms, marketers always want to deliver products, contents, or advertisements to potential audiences over media channels such as display, video, or social. Given a set of audiences or customers (seed users), the audience expansion technique (look-alike modeling) is a promising solution to identify more potential audiences, who are similar to the seed users and likely to finish the business goal of the target campaign. However, look-alike modeling faces two challenges: (1) In practice, a company could run hundreds of marketing campaigns to promote various contents within completely different categories every day, e.g., sports, politics, society. Thus, it is difficult to utilize a common method to expand audiences for all campaigns. (2) The seed set of a certain campaign could only cover limited users. Therefore, a customized approach based on such a seed set is likely to be overfitting. In this paper, to address these challenges, we propose a novel two-stage framework named Meta Hybrid Experts and Critics (MetaHeac) which has been deployed in WeChat Look-alike System. In the offline stage, a general model which can capture the relationships among various tasks is trained from a meta-learning perspective on all existing campaign tasks. In the online stage, for a new campaign, a customized model is learned with the given seed set based on the general model. According to both offline and online experiments, the proposed MetaHeac shows superior effectiveness for both content marketing campaigns in recommender systems and advertising campaigns in advertising platforms. Besides, MetaHeac has been successfully deployed in WeChat for the promotion of both contents and advertisements, leading to great improvement in the quality of marketing. The code has been available at \url{https://github.com/easezyc/MetaHeac}.
Modeling the Sequential Dependence among Audience Multi-step Conversions with Multi-task Learning in Targeted Display Advertising
May 24, 2021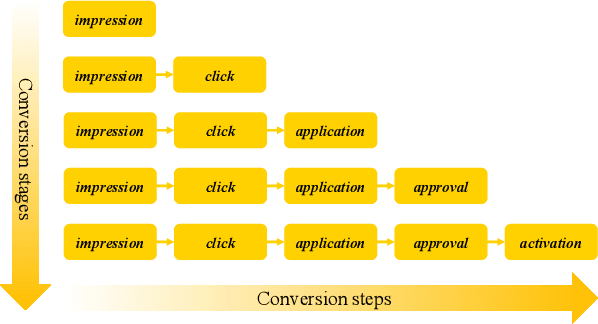

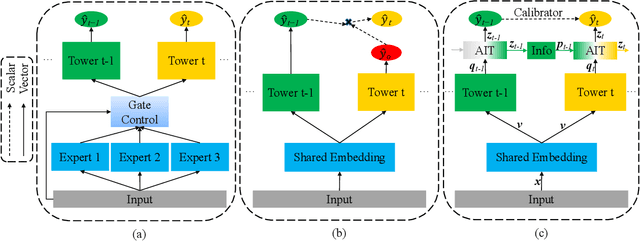
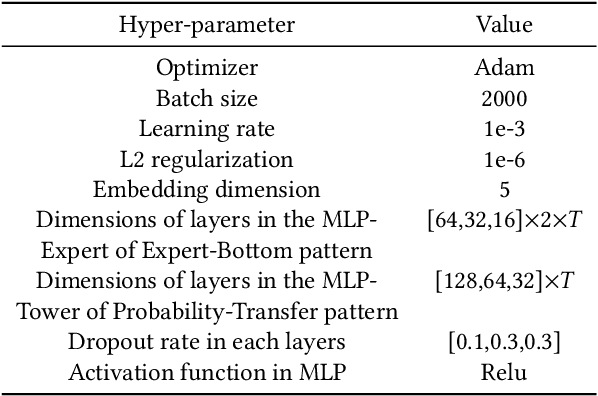
In most real-world large-scale online applications (e.g., e-commerce or finance), customer acquisition is usually a multi-step conversion process of audiences. For example, an impression->click->purchase process is usually performed of audiences for e-commerce platforms. However, it is more difficult to acquire customers in financial advertising (e.g., credit card advertising) than in traditional advertising. On the one hand, the audience multi-step conversion path is longer. On the other hand, the positive feedback is sparser (class imbalance) step by step, and it is difficult to obtain the final positive feedback due to the delayed feedback of activation. Multi-task learning is a typical solution in this direction. While considerable multi-task efforts have been made in this direction, a long-standing challenge is how to explicitly model the long-path sequential dependence among audience multi-step conversions for improving the end-to-end conversion. In this paper, we propose an Adaptive Information Transfer Multi-task (AITM) framework, which models the sequential dependence among audience multi-step conversions via the Adaptive Information Transfer (AIT) module. The AIT module can adaptively learn what and how much information to transfer for different conversion stages. Besides, by combining the Behavioral Expectation Calibrator in the loss function, the AITM framework can yield more accurate end-to-end conversion identification. The proposed framework is deployed in Meituan app, which utilizes it to real-timely show a banner to the audience with a high end-to-end conversion rate for Meituan Co-Branded Credit Cards. Offline experimental results on both industrial and public real-world datasets clearly demonstrate that the proposed framework achieves significantly better performance compared with state-of-the-art baselines.
Learning to Warm Up Cold Item Embeddings for Cold-start Recommendation with Meta Scaling and Shifting Networks
May 11, 2021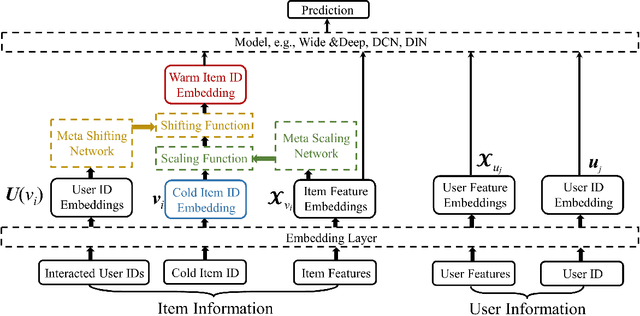
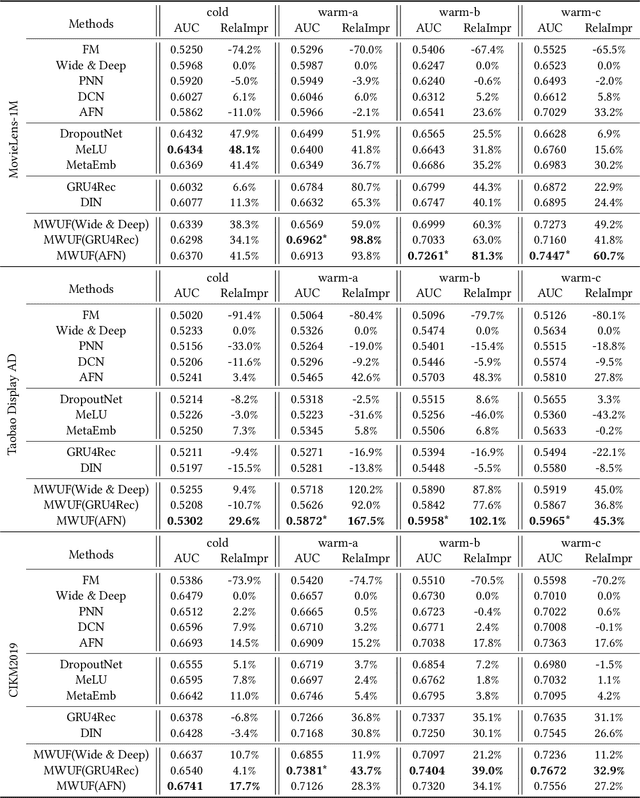
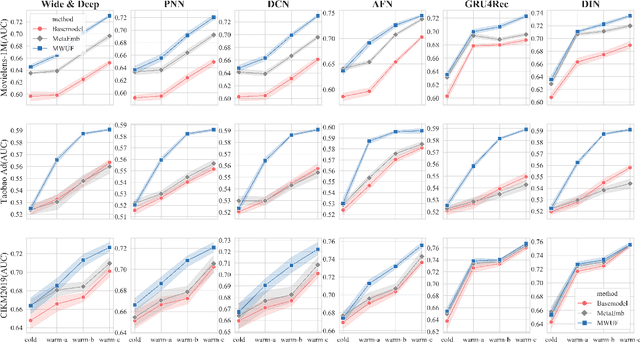
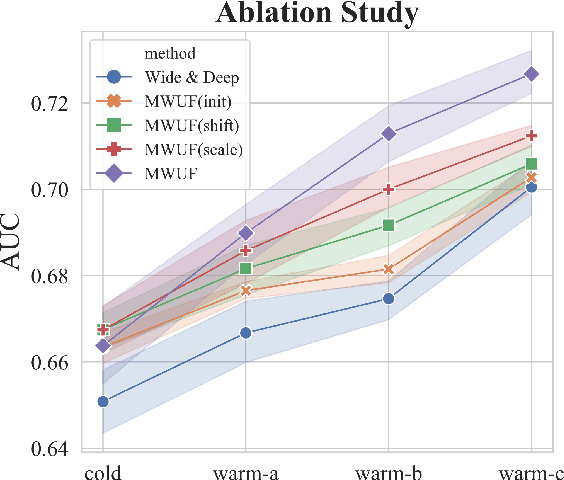
Recently, embedding techniques have achieved impressive success in recommender systems. However, the embedding techniques are data demanding and suffer from the cold-start problem. Especially, for the cold-start item which only has limited interactions, it is hard to train a reasonable item ID embedding, called cold ID embedding, which is a major challenge for the embedding techniques. The cold item ID embedding has two main problems: (1) A gap is existing between the cold ID embedding and the deep model. (2) Cold ID embedding would be seriously affected by noisy interaction. However, most existing methods do not consider both two issues in the cold-start problem, simultaneously. To address these problems, we adopt two key ideas: (1) Speed up the model fitting for the cold item ID embedding (fast adaptation). (2) Alleviate the influence of noise. Along this line, we propose Meta Scaling and Shifting Networks to generate scaling and shifting functions for each item, respectively. The scaling function can directly transform cold item ID embeddings into warm feature space which can fit the model better, and the shifting function is able to produce stable embeddings from the noisy embeddings. With the two meta networks, we propose Meta Warm Up Framework (MWUF) which learns to warm up cold ID embeddings. Moreover, MWUF is a general framework that can be applied upon various existing deep recommendation models. The proposed model is evaluated on three popular benchmarks, including both recommendation and advertising datasets. The evaluation results demonstrate its superior performance and compatibility.
Transfer-Meta Framework for Cross-domain Recommendation to Cold-Start Users
May 11, 2021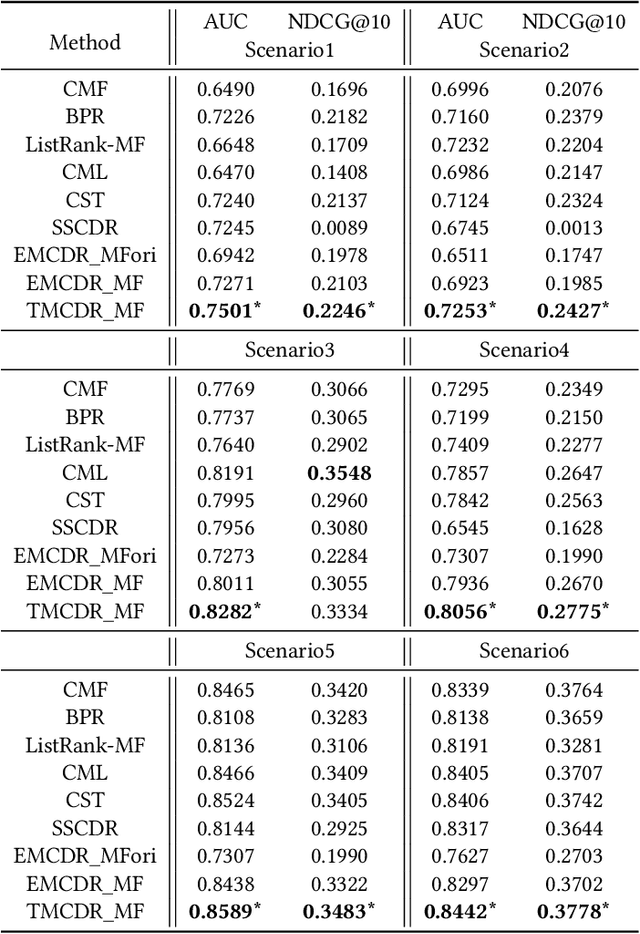
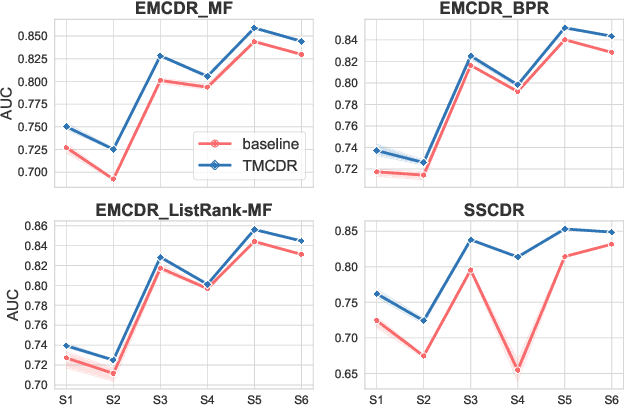
Cold-start problems are enormous challenges in practical recommender systems. One promising solution for this problem is cross-domain recommendation (CDR) which leverages rich information from an auxiliary (source) domain to improve the performance of recommender system in the target domain. In these CDR approaches, the family of Embedding and Mapping methods for CDR (EMCDR) is very effective, which explicitly learn a mapping function from source embeddings to target embeddings with overlapping users. However, these approaches suffer from one serious problem: the mapping function is only learned on limited overlapping users, and the function would be biased to the limited overlapping users, which leads to unsatisfying generalization ability and degrades the performance on cold-start users in the target domain. With the advantage of meta learning which has good generalization ability to novel tasks, we propose a transfer-meta framework for CDR (TMCDR) which has a transfer stage and a meta stage. In the transfer (pre-training) stage, a source model and a target model are trained on source and target domains, respectively. In the meta stage, a task-oriented meta network is learned to implicitly transform the user embedding in the source domain to the target feature space. In addition, the TMCDR is a general framework that can be applied upon various base models, e.g., MF, BPR, CML. By utilizing data from Amazon and Douban, we conduct extensive experiments on 6 cross-domain tasks to demonstrate the superior performance and compatibility of TMCDR.
Combat Data Shift in Few-shot Learning with Knowledge Graph
Feb 26, 2021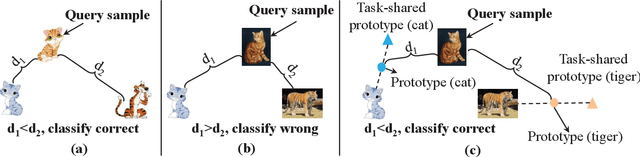
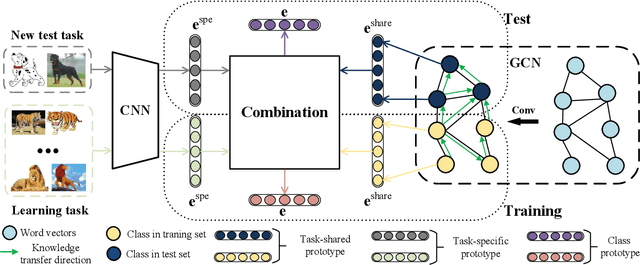
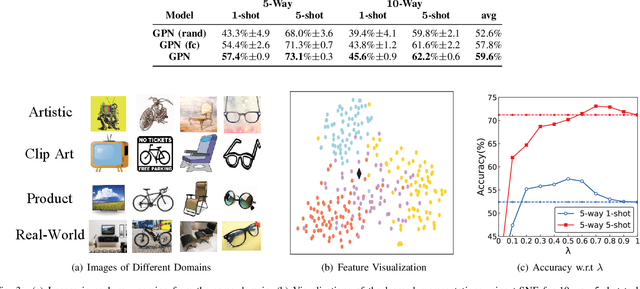
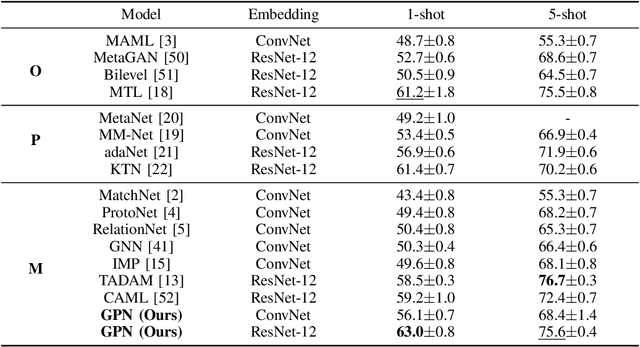
Many few-shot learning approaches have been designed under the meta-learning framework, which learns from a variety of learning tasks and generalizes to new tasks. These meta-learning approaches achieve the expected performance in the scenario where all samples are drawn from the same distributions (i.i.d. observations). However, in real-world applications, few-shot learning paradigm often suffers from data shift, i.e., samples in different tasks, even in the same task, could be drawn from various data distributions. Most existing few-shot learning approaches are not designed with the consideration of data shift, and thus show downgraded performance when data distribution shifts. However, it is non-trivial to address the data shift problem in few-shot learning, due to the limited number of labeled samples in each task. Targeting at addressing this problem, we propose a novel metric-based meta-learning framework to extract task-specific representations and task-shared representations with the help of knowledge graph. The data shift within/between tasks can thus be combated by the combination of task-shared and task-specific representations. The proposed model is evaluated on popular benchmarks and two constructed new challenging datasets. The evaluation results demonstrate its remarkable performance.