 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGEM: Generative Entropy-Guided Preference Modeling for Few-shot Alignment of LLMs
Nov 17, 2025



Alignment of large language models (LLMs) with human preferences typically relies on supervised reward models or external judges that demand abundant annotations. However, in fields that rely on professional knowledge, such as medicine and law, such large-scale preference labels are often unachievable. In this paper, we propose a generative entropy-guided preference modeling approach named GEM for LLMs aligment at low-resource and domain-specific scenarios. Instead of training a discriminative reward model on preference data, we directly train the LLM to internalize a closed-loop optimization architecture that can extract and exploit the multi-dimensional, fine-grained cognitive signals implicit in human preferences. Specifically, our Cognitive Filtering module, based on entropy theory in decision making, first leverages Chain-of-Thought (CoT) prompting to generate diverse candidate reasoning chains (CoTs) from preference data. Subsequently, it introduces a token scoring mechanism to rank and weight the sampled CoTs, boosting the importance of high-confidence answers and strategically high-entropy tokens. Building on these filtered preferences, we fine-tune the LLM using a novel self-evaluated group advantage algorithm, SEGA, which effectively aggregates group-level cognitive signals and transforms the entropy-based scores into implicit rewards for policy optimization. In these ways, GEM empowers the LLM to rely on its own judgments and establishes an entropy-guided closed-loop cognitive optimization framework, enabling highly efficient few-shot alignment of LLMs. Experiments on general benchmarks and domain-specific tasks (such as mathematical reasoning and medical dialogues) demonstrate that our GEM achieves significant improvements with few-shot preference data.
GFRIEND: Generative Few-shot Reward Inference through EfficieNt DPO
Jun 10, 2025The ability to train high-performing reward models with few-shot data is critical for enhancing the efficiency and scalability of Reinforcement Learning from Human Feedback (RLHF). We propose a data augmentation and expansion framework that enables generative reward models trained on small datasets to achieve comparable performance to those trained on large-scale datasets. Traditional methods to train a generative reward model, such as Direct Preference Optimization (DPO), are constrained by inefficiencies in sample pairing and limited data diversity. This work introduces preference refinement, which employs Chain-of-Thought (CoT) sampling to uncover diverse and high-quality preference relationships. It also incorporates a perplexity-based scoring mechanism to assign nuanced preference levels and utilizes Multi-level Direct Preference Optimization (M-DPO) to enable the model to capture finer-grained preference differences between samples. Experimental results demonstrate that the proposed method significantly enhances data efficiency and model performance, enabling reward models trained in a few-shot setting to achieve results on par with those trained on large-scale datasets. This study underscores the potential of data-efficient strategies in advancing reward model optimization, offering a robust solution for low-resource RLHF applications.
Negative Metric Learning for Graphs
May 15, 2025Graph contrastive learning (GCL) often suffers from false negatives, which degrades the performance on downstream tasks. The existing methods addressing the false negative issue usually rely on human prior knowledge, still leading GCL to suboptimal results. In this paper, we propose a novel Negative Metric Learning (NML) enhanced GCL (NML-GCL). NML-GCL employs a learnable Negative Metric Network (NMN) to build a negative metric space, in which false negatives can be distinguished better from true negatives based on their distance to anchor node. To overcome the lack of explicit supervision signals for NML, we propose a joint training scheme with bi-level optimization objective, which implicitly utilizes the self-supervision signals to iteratively optimize the encoder and the negative metric network. The solid theoretical analysis and the extensive experiments conducted on widely used benchmarks verify the superiority of the proposed method.
Whisper-PMFA: Partial Multi-Scale Feature Aggregation for Speaker Verification using Whisper Models
Aug 28, 2024In this paper, Whisper, a large-scale pre-trained model for automatic speech recognition, is proposed to apply to speaker verification. A partial multi-scale feature aggregation (PMFA) approach is proposed based on a subset of Whisper encoder blocks to derive highly discriminative speaker embeddings.Experimental results demonstrate that using the middle to later blocks of the Whisper encoder keeps more speaker information. On the VoxCeleb1 and CN-Celeb1 datasets, our system achieves 1.42% and 8.23% equal error rates (EERs) respectively, receiving 0.58% and 1.81% absolute EER reductions over the ECAPA-TDNN baseline, and 0.46% and 0.97% over the ResNet34 baseline. Furthermore, our results indicate that using Whisper models trained on multilingual data can effectively enhance the model's robustness across languages. Finally, the low-rank adaptation approach is evaluated, which reduces the trainable model parameters by approximately 45 times while only slightly increasing EER by 0.2%.
CE-NAS: An End-to-End Carbon-Efficient Neural Architecture Search Framework
Jun 03, 2024This work presents a novel approach to neural architecture search (NAS) that aims to increase carbon efficiency for the model design process. The proposed framework CE-NAS addresses the key challenge of high carbon cost associated with NAS by exploring the carbon emission variations of energy and energy differences of different NAS algorithms. At the high level, CE-NAS leverages a reinforcement-learning agent to dynamically adjust GPU resources based on carbon intensity, predicted by a time-series transformer, to balance energy-efficient sampling and energy-intensive evaluation tasks. Furthermore, CE-NAS leverages a recently proposed multi-objective optimizer to effectively reduce the NAS search space. We demonstrate the efficacy of CE-NAS in lowering carbon emissions while achieving SOTA results for both NAS datasets and open-domain NAS tasks. For example, on the HW-NasBench dataset, CE-NAS reduces carbon emissions by up to 7.22X while maintaining a search efficiency comparable to vanilla NAS. For open-domain NAS tasks, CE-NAS achieves SOTA results with 97.35% top-1 accuracy on CIFAR-10 with only 1.68M parameters and a carbon consumption of 38.53 lbs of CO2. On ImageNet, our searched model achieves 80.6% top-1 accuracy with a 0.78 ms TensorRT latency using FP16 on NVIDIA V100, consuming only 909.86 lbs of CO2, making it comparable to other one-shot-based NAS baselines.
Multi-objective Neural Architecture Search by Learning Search Space Partitions
Jun 01, 2024Deploying deep learning models requires taking into consideration neural network metrics such as model size, inference latency, and #FLOPs, aside from inference accuracy. This results in deep learning model designers leveraging multi-objective optimization to design effective deep neural networks in multiple criteria. However, applying multi-objective optimizations to neural architecture search (NAS) is nontrivial because NAS tasks usually have a huge search space, along with a non-negligible searching cost. This requires effective multi-objective search algorithms to alleviate the GPU costs. In this work, we implement a novel multi-objectives optimizer based on a recently proposed meta-algorithm called LaMOO on NAS tasks. In a nutshell, LaMOO speedups the search process by learning a model from observed samples to partition the search space and then focusing on promising regions likely to contain a subset of the Pareto frontier. Using LaMOO, we observe an improvement of more than 200% sample efficiency compared to Bayesian optimization and evolutionary-based multi-objective optimizers on different NAS datasets. For example, when combined with LaMOO, qEHVI achieves a 225% improvement in sample efficiency compared to using qEHVI alone in NasBench201. For real-world tasks, LaMOO achieves 97.36% accuracy with only 1.62M #Params on CIFAR10 in only 600 search samples. On ImageNet, our large model reaches 80.4% top-1 accuracy with only 522M #FLOPs.
Carbon-Efficient Neural Architecture Search
Jul 09, 2023This work presents a novel approach to neural architecture search (NAS) that aims to reduce energy costs and increase carbon efficiency during the model design process. The proposed framework, called carbon-efficient NAS (CE-NAS), consists of NAS evaluation algorithms with different energy requirements, a multi-objective optimizer, and a heuristic GPU allocation strategy. CE-NAS dynamically balances energy-efficient sampling and energy-consuming evaluation tasks based on current carbon emissions. Using a recent NAS benchmark dataset and two carbon traces, our trace-driven simulations demonstrate that CE-NAS achieves better carbon and search efficiency than the three baselines.
Multi-objective Optimization by Learning Space Partitions
Oct 10, 2021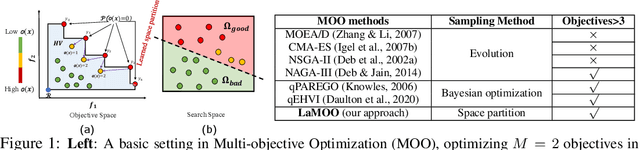
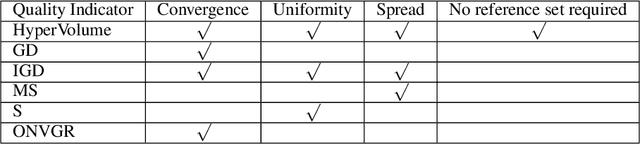
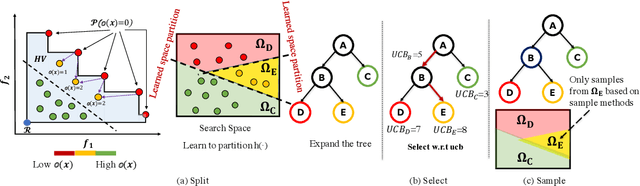
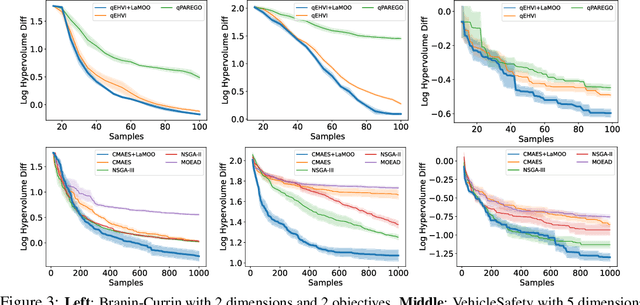
In contrast to single-objective optimization (SOO), multi-objective optimization (MOO) requires an optimizer to find the Pareto frontier, a subset of feasible solutions that are not dominated by other feasible solutions. In this paper, we propose LaMOO, a novel multi-objective optimizer that learns a model from observed samples to partition the search space and then focus on promising regions that are likely to contain a subset of the Pareto frontier. The partitioning is based on the dominance number, which measures "how close" a data point is to the Pareto frontier among existing samples. To account for possible partition errors due to limited samples and model mismatch, we leverage Monte Carlo Tree Search (MCTS) to exploit promising regions while exploring suboptimal regions that may turn out to contain good solutions later. Theoretically, we prove the efficacy of learning space partitioning via LaMOO under certain assumptions. Empirically, on the HyperVolume (HV) benchmark, a popular MOO metric, LaMOO substantially outperforms strong baselines on multiple real-world MOO tasks, by up to 225% in sample efficiency for neural architecture search on Nasbench201, and up to 10% for molecular design.
Few-shot Neural Architecture Search
Jun 19, 2020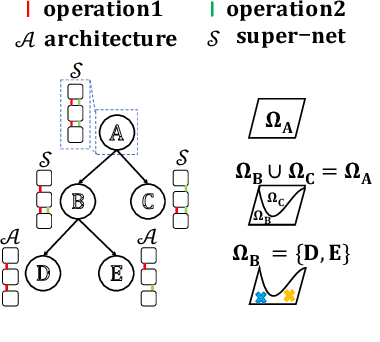
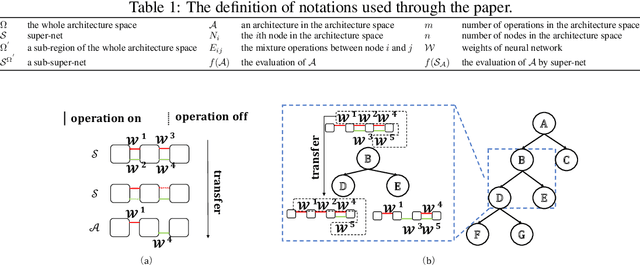
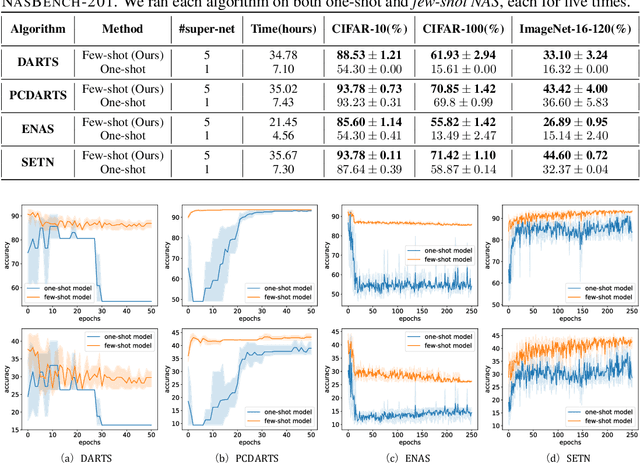
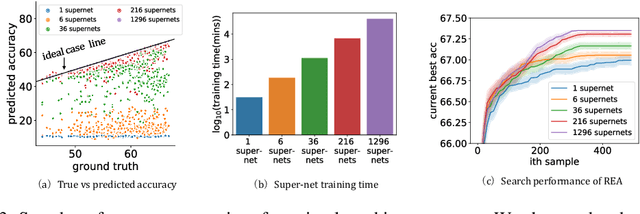
To improve the search efficiency for Neural Architecture Search (NAS), One-shot NAS proposes to train a single super-net to approximate the performance of proposal architectures during search via weight-sharing. While this greatly reduces the computation cost, due to approximation error, the performance prediction by a single super-net is less accurate than training each proposal architecture from scratch, leading to search inefficiency. In this work, we propose few-shot NAS that explores the choice of using multiple super-nets: each super-net is pre-trained to be in charge of a sub-region of the search space. This reduces the prediction error of each super-net. Moreover, training these super-nets can be done jointly via sequential fine-tuning. A natural choice of sub-region is to follow the splitting of search space in NAS. We empirically evaluate our approach on three different tasks in NAS-Bench-201. Extensive results have demonstrated that few-shot NAS, using only 5 super-nets, significantly improves performance of many search methods with slight increase of search time. The architectures found by DARTs and ENAS with few-shot models achieved 88.53% and 86.50% test accuracy on CIFAR-10 in NAS-Bench-201, significantly outperformed their one-shot counterparts (with 54.30% and 54.30% test accuracy). Moreover, on AUTOGAN and DARTS, few-shot NAS also outperforms previously state-of-the-art models.
AlphaX: eXploring Neural Architectures with Deep Neural Networks and Monte Carlo Tree Search
Mar 26, 2019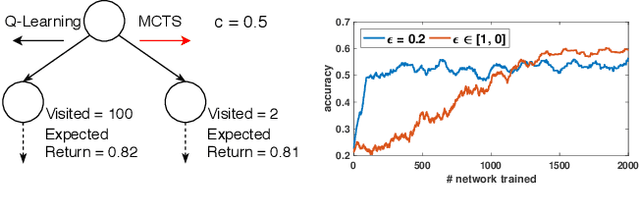
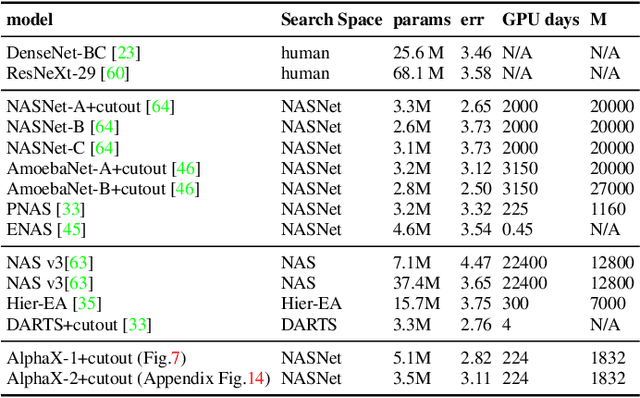
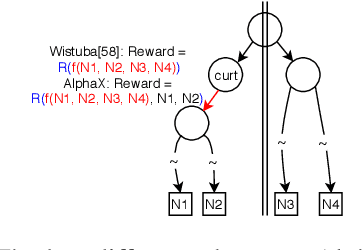
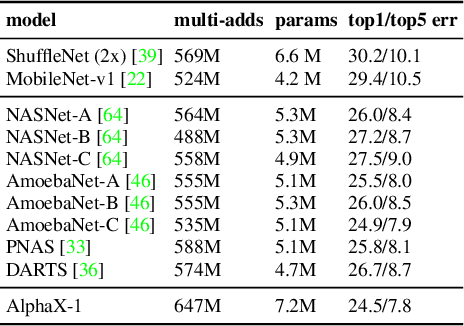
We present AlphaX, a fully automated agent that designs complex neural architectures from scratch. AlphaX explores the exponentially grown search space with a distributed Monte Carlo Tree Search (MCTS) and a Meta-Deep Neural Network (DNN). MCTS intrinsically improves the search efficiency by dynamically balancing the exploration and exploitation at fine-grained states, while Meta-DNN predicts the network accuracy to guide the search, and to provide an estimated reward to speed up the rollout. As the search progresses, AlphaX also generates the training data for Meta-DNN. So, the learning of Meta-DNN is end-to-end. In 14 days with only 16 GPUs (1832 samples), AlphaX found an architecture that reaches the state-of-the-art accuracies on both CIFAR-10(97.18%) and ImageNet(75.5% top-1 and 92.2% top-5). This demonstrates up to 10x speedup over the original searching for NASNet that used 500 GPUs in 4 days (20000 samples). On NASBench-101, AlphaX demonstrates 3x and 2.8x speedup over Random Search and Regularized Evolution. Finally, we show the searched architecture improves a variety of vision applications from Neural Style Transfer, to Image Captioning and Object Detection. Our implementation is available at https://github.com/linnanwang/AlphaX-NASBench101.