 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePause or Fabricate? Training Language Models for Grounded Reasoning
Apr 21, 2026Large language models have achieved remarkable progress on complex reasoning tasks. However, they often implicitly fabricate information when inputs are incomplete, producing confident but unreliable conclusions -- a failure mode we term ungrounded reasoning. We argue that this issue arises not from insufficient reasoning capability, but from the lack of inferential boundary awareness -- the ability to recognize when the necessary premises for valid inference are missing. To address this issue, we propose Grounded Reasoning via Interactive Reinforcement Learning (GRIL), a multi-turn reinforcement learning framework for grounded reasoning under incomplete information. GRIL decomposes the reasoning process into two stages: clarify and pause, which identifies whether the available information is sufficient, and grounded reasoning, which performs task solving once the necessary premises are established. We design stage-specific rewards to penalize hallucinations, enabling models to detect gaps, stop proactively, and resume reasoning after clarification. Experiments on GSM8K-Insufficient and MetaMATH-Insufficient show that GRIL significantly improves premise detection (up to 45%), leading to a 30% increase in task success while reducing average response length by over 20%. Additional analyses confirm robustness to noisy user responses and generalization to out-of-distribution tasks.
Latent Variable Causal Discovery under Selection Bias
Dec 12, 2025Addressing selection bias in latent variable causal discovery is important yet underexplored, largely due to a lack of suitable statistical tools: While various tools beyond basic conditional independencies have been developed to handle latent variables, none have been adapted for selection bias. We make an attempt by studying rank constraints, which, as a generalization to conditional independence constraints, exploits the ranks of covariance submatrices in linear Gaussian models. We show that although selection can significantly complicate the joint distribution, interestingly, the ranks in the biased covariance matrices still preserve meaningful information about both causal structures and selection mechanisms. We provide a graph-theoretic characterization of such rank constraints. Using this tool, we demonstrate that the one-factor model, a classical latent variable model, can be identified under selection bias. Simulations and real-world experiments confirm the effectiveness of using our rank constraints.
* Appears at ICML 2025
Identifying Selections for Unsupervised Subtask Discovery
Oct 28, 2024



When solving long-horizon tasks, it is intriguing to decompose the high-level task into subtasks. Decomposing experiences into reusable subtasks can improve data efficiency, accelerate policy generalization, and in general provide promising solutions to multi-task reinforcement learning and imitation learning problems. However, the concept of subtasks is not sufficiently understood and modeled yet, and existing works often overlook the true structure of the data generation process: subtasks are the results of a $\textit{selection}$ mechanism on actions, rather than possible underlying confounders or intermediates. Specifically, we provide a theory to identify, and experiments to verify the existence of selection variables in such data. These selections serve as subgoals that indicate subtasks and guide policy. In light of this idea, we develop a sequential non-negative matrix factorization (seq- NMF) method to learn these subgoals and extract meaningful behavior patterns as subtasks. Our empirical results on a challenging Kitchen environment demonstrate that the learned subtasks effectively enhance the generalization to new tasks in multi-task imitation learning scenarios. The codes are provided at https://anonymous.4open.science/r/Identifying\_Selections\_for\_Unsupervised\_Subtask\_Discovery/README.md.
Detecting and Identifying Selection Structure in Sequential Data
Jun 29, 2024



We argue that the selective inclusion of data points based on latent objectives is common in practical situations, such as music sequences. Since this selection process often distorts statistical analysis, previous work primarily views it as a bias to be corrected and proposes various methods to mitigate its effect. However, while controlling this bias is crucial, selection also offers an opportunity to provide a deeper insight into the hidden generation process, as it is a fundamental mechanism underlying what we observe. In particular, overlooking selection in sequential data can lead to an incomplete or overcomplicated inductive bias in modeling, such as assuming a universal autoregressive structure for all dependencies. Therefore, rather than merely viewing it as a bias, we explore the causal structure of selection in sequential data to delve deeper into the complete causal process. Specifically, we show that selection structure is identifiable without any parametric assumptions or interventional experiments. Moreover, even in cases where selection variables coexist with latent confounders, we still establish the nonparametric identifiability under appropriate structural conditions. Meanwhile, we also propose a provably correct algorithm to detect and identify selection structures as well as other types of dependencies. The framework has been validated empirically on both synthetic data and real-world music.
Out-of-Dynamics Imitation Learning from Multimodal Demonstrations
Nov 13, 2022



Existing imitation learning works mainly assume that the demonstrator who collects demonstrations shares the same dynamics as the imitator. However, the assumption limits the usage of imitation learning, especially when collecting demonstrations for the imitator is difficult. In this paper, we study out-of-dynamics imitation learning (OOD-IL), which relaxes the assumption to that the demonstrator and the imitator have the same state spaces but could have different action spaces and dynamics. OOD-IL enables imitation learning to utilize demonstrations from a wide range of demonstrators but introduces a new challenge: some demonstrations cannot be achieved by the imitator due to the different dynamics. Prior works try to filter out such demonstrations by feasibility measurements, but ignore the fact that the demonstrations exhibit a multimodal distribution since the different demonstrators may take different policies in different dynamics. We develop a better transferability measurement to tackle this newly-emerged challenge. We firstly design a novel sequence-based contrastive clustering algorithm to cluster demonstrations from the same mode to avoid the mutual interference of demonstrations from different modes, and then learn the transferability of each demonstration with an adversarial-learning based algorithm in each cluster. Experiment results on several MuJoCo environments, a driving environment, and a simulated robot environment show that the proposed transferability measurement more accurately finds and down-weights non-transferable demonstrations and outperforms prior works on the final imitation learning performance. We show the videos of our experiment results on our website.
When to Trust Your Simulator: Dynamics-Aware Hybrid Offline-and-Online Reinforcement Learning
Jun 27, 2022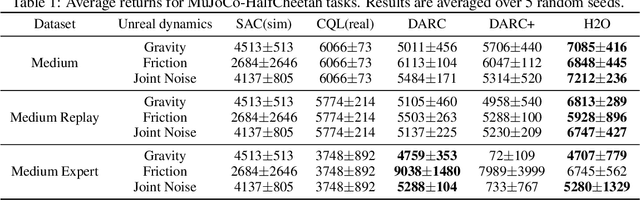
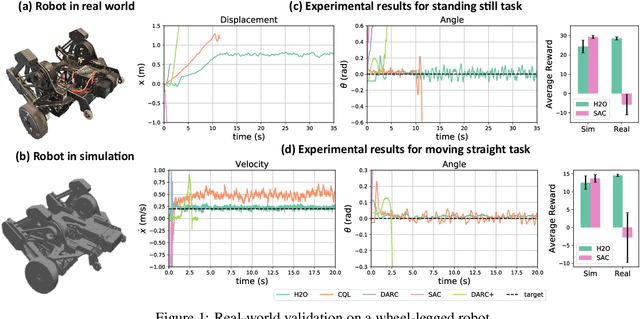
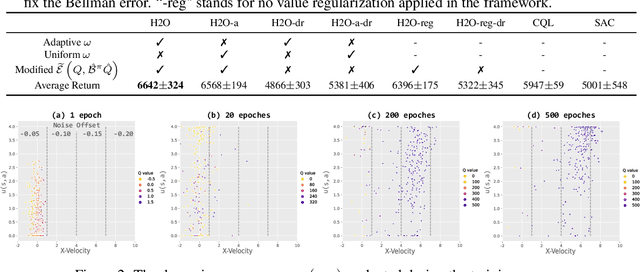
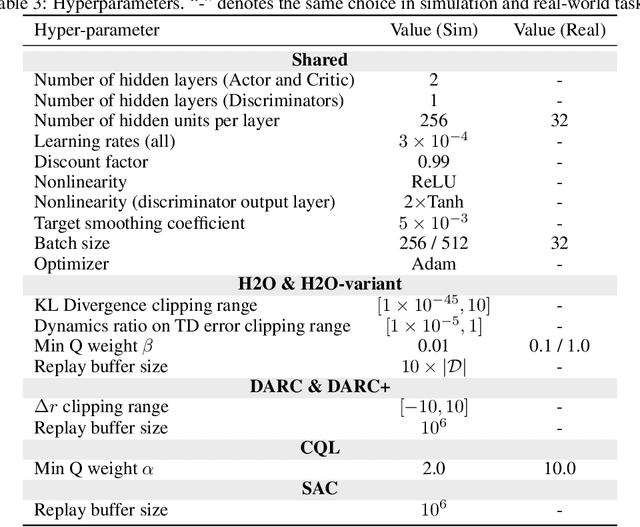
Learning effective reinforcement learning (RL) policies to solve real-world complex tasks can be quite challenging without a high-fidelity simulation environment. In most cases, we are only given imperfect simulators with simplified dynamics, which inevitably lead to severe sim-to-real gaps in RL policy learning. The recently emerged field of offline RL provides another possibility to learn policies directly from pre-collected historical data. However, to achieve reasonable performance, existing offline RL algorithms need impractically large offline data with sufficient state-action space coverage for training. This brings up a new question: is it possible to combine learning from limited real data in offline RL and unrestricted exploration through imperfect simulators in online RL to address the drawbacks of both approaches? In this study, we propose the Dynamics-Aware Hybrid Offline-and-Online Reinforcement Learning (H2O) framework to provide an affirmative answer to this question. H2O introduces a dynamics-aware policy evaluation scheme, which adaptively penalizes the Q function learning on simulated state-action pairs with large dynamics gaps, while also simultaneously allowing learning from a fixed real-world dataset. Through extensive simulation and real-world tasks, as well as theoretical analysis, we demonstrate the superior performance of H2O against other cross-domain online and offline RL algorithms. H2O provides a brand new hybrid offline-and-online RL paradigm, which can potentially shed light on future RL algorithm design for solving practical real-world tasks.