 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Learning for Solving the Travelling Salesman Problem
Mar 19, 2023



We propose UTSP, an unsupervised learning (UL) framework for solving the Travelling Salesman Problem (TSP). We train a Graph Neural Network (GNN) using a surrogate loss. The GNN outputs a heat map representing the probability for each edge to be part of the optimal path. We then apply local search to generate our final prediction based on the heat map. Our loss function consists of two parts: one pushes the model to find the shortest path and the other serves as a surrogate for the constraint that the route should form a Hamiltonian Cycle. Experimental results show that UTSP outperforms the existing data-driven TSP heuristics. Our approach is parameter efficient as well as data efficient: the model takes $\sim$ 10\% of the number of parameters and $\sim$ 0.2\% of training samples compared with reinforcement learning or supervised learning methods.
Automating Crystal-Structure Phase Mapping: Combining Deep Learning with Constraint Reasoning
Aug 21, 2021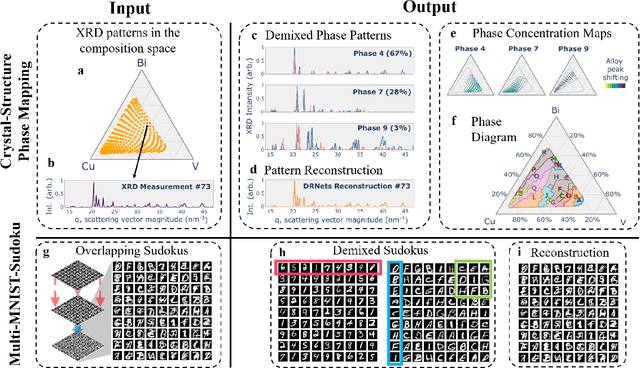
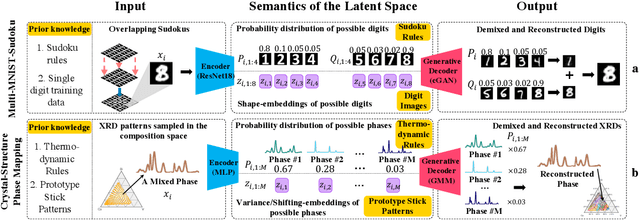
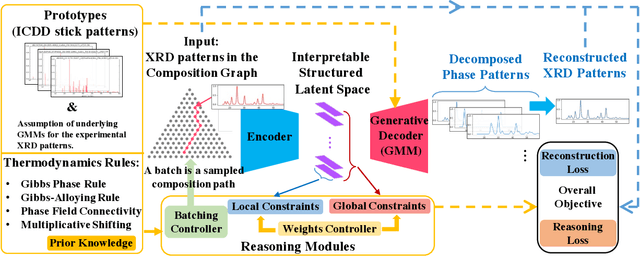
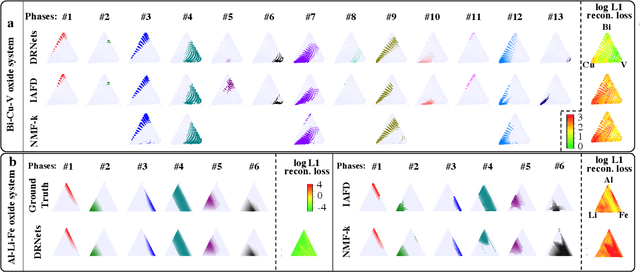
Crystal-structure phase mapping is a core, long-standing challenge in materials science that requires identifying crystal structures, or mixtures thereof, in synthesized materials. Materials science experts excel at solving simple systems but cannot solve complex systems, creating a major bottleneck in high-throughput materials discovery. Herein we show how to automate crystal-structure phase mapping. We formulate phase mapping as an unsupervised pattern demixing problem and describe how to solve it using Deep Reasoning Networks (DRNets). DRNets combine deep learning with constraint reasoning for incorporating scientific prior knowledge and consequently require only a modest amount of (unlabeled) data. DRNets compensate for the limited data by exploiting and magnifying the rich prior knowledge about the thermodynamic rules governing the mixtures of crystals with constraint reasoning seamlessly integrated into neural network optimization. DRNets are designed with an interpretable latent space for encoding prior-knowledge domain constraints and seamlessly integrate constraint reasoning into neural network optimization. DRNets surpass previous approaches on crystal-structure phase mapping, unraveling the Bi-Cu-V oxide phase diagram, and aiding the discovery of solar-fuels materials.
Fairness of Exposure in Stochastic Bandits
Mar 03, 2021
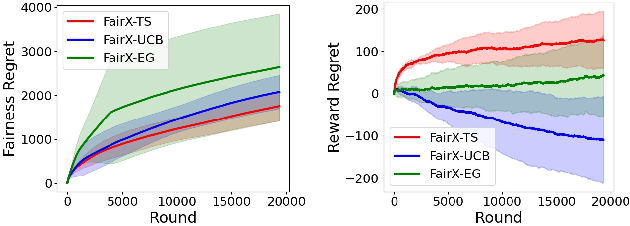
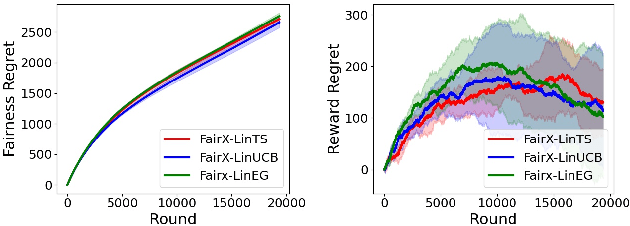

Contextual bandit algorithms have become widely used for recommendation in online systems (e.g. marketplaces, music streaming, news), where they now wield substantial influence on which items get exposed to the users. This raises questions of fairness to the items -- and to the sellers, artists, and writers that benefit from this exposure. We argue that the conventional bandit formulation can lead to an undesirable and unfair winner-takes-all allocation of exposure. To remedy this problem, we propose a new bandit objective that guarantees merit-based fairness of exposure to the items while optimizing utility to the users. We formulate fairness regret and reward regret in this setting, and present algorithms for both stochastic multi-armed bandits and stochastic linear bandits. We prove that the algorithms achieve sub-linear fairness regret and reward regret. Beyond the theoretical analysis, we also provide empirical evidence that these algorithms can fairly allocate exposure to different arms effectively.
Zero Training Overhead Portfolios for Learning to Solve Combinatorial Problems
Feb 05, 2021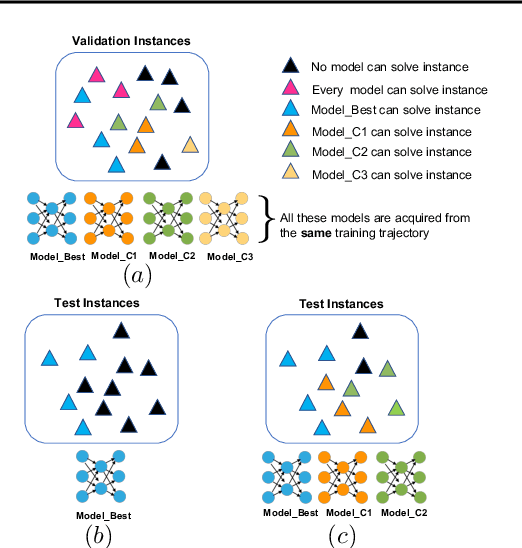
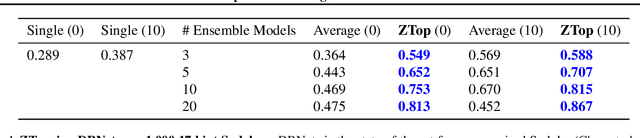
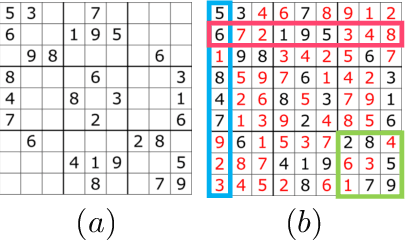
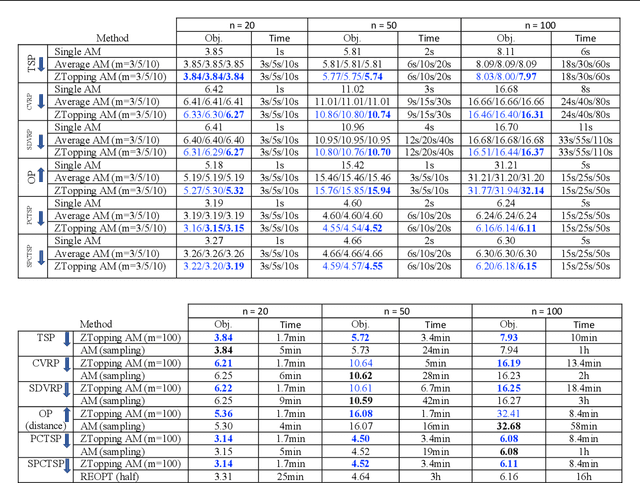
There has been an increasing interest in harnessing deep learning to tackle combinatorial optimization (CO) problems in recent years. Typical CO deep learning approaches leverage the problem structure in the model architecture. Nevertheless, the model selection is still mainly based on the conventional machine learning setting. Due to the discrete nature of CO problems, a single model is unlikely to learn the problem entirely. We introduce ZTop, which stands for Zero Training Overhead Portfolio, a simple yet effective model selection and ensemble mechanism for learning to solve combinatorial problems. ZTop is inspired by algorithm portfolios, a popular CO ensembling strategy, particularly restart portfolios, which periodically restart a randomized CO algorithm, de facto exploring the search space with different heuristics. We have observed that well-trained models acquired in the same training trajectory, with similar top validation performance, perform well on very different validation instances. Following this observation, ZTop ensembles a set of well-trained models, each providing a unique heuristic with zero training overhead, and applies them, sequentially or in parallel, to solve the test instances. We show how ZTopping, i.e., using a ZTop ensemble strategy with a given deep learning approach, can significantly improve the performance of the current state-of-the-art deep learning approaches on three prototypical CO domains, the hardest unique-solution Sudoku instances, challenging routing problems, and the graph maximum cut problem, as well as on multi-label classification, a machine learning task with a large combinatorial label space.
Deep Reasoning Networks: Thinking Fast and Slow
Jun 04, 2019
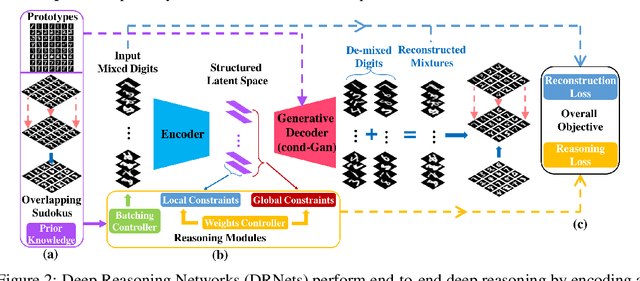

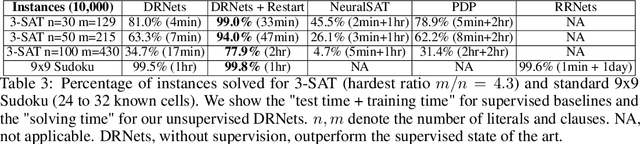
We introduce Deep Reasoning Networks (DRNets), an end-to-end framework that combines deep learning with reasoning for solving complex tasks, typically in an unsupervised or weakly-supervised setting. DRNets exploit problem structure and prior knowledge by tightly combining logic and constraint reasoning with stochastic-gradient-based neural network optimization. We illustrate the power of DRNets on de-mixing overlapping hand-written Sudokus (Multi-MNIST-Sudoku) and on a substantially more complex task in scientific discovery that concerns inferring crystal structures of materials from X-ray diffraction data under thermodynamic rules (Crystal-Structure-Phase-Mapping). At a high level, DRNets encode a structured latent space of the input data, which is constrained to adhere to prior knowledge by a reasoning module. The structured latent encoding is used by a generative decoder to generate the targeted output. Finally, an overall objective combines responses from the generative decoder (thinking fast) and the reasoning module (thinking slow), which is optimized using constraint-aware stochastic gradient descent. We show how to encode different tasks as DRNets and demonstrate DRNets' effectiveness with detailed experiments: DRNets significantly outperform the state of the art and experts' capabilities on Crystal-Structure-Phase-Mapping, recovering more precise and physically meaningful crystal structures. On Multi-MNIST-Sudoku, DRNets perfectly recovered the mixed Sudokus' digits, with 100% digit accuracy, outperforming the supervised state-of-the-art MNIST de-mixing models. Finally, as a proof of concept, we also show how DRNets can solve standard combinatorial problems -- 9-by-9 Sudoku puzzles and Boolean satisfiability problems (SAT), outperforming other specialized deep learning models. DRNets are general and can be adapted and expanded to tackle other tasks.
A Study of AI Population Dynamics with Million-agent Reinforcement Learning
May 14, 2018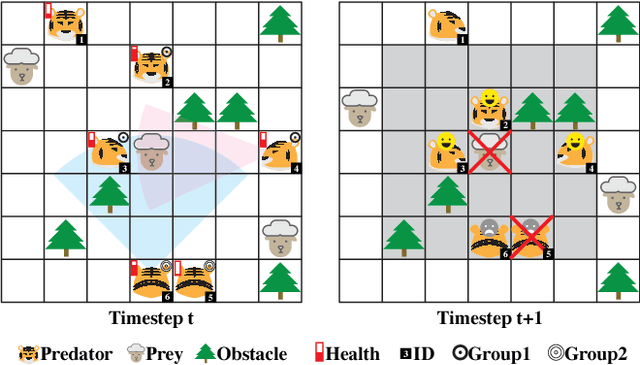
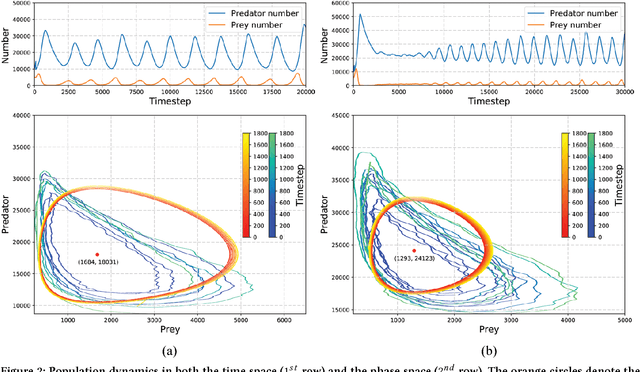
We conduct an empirical study on discovering the ordered collective dynamics obtained by a population of intelligence agents, driven by million-agent reinforcement learning. Our intention is to put intelligent agents into a simulated natural context and verify if the principles developed in the real world could also be used in understanding an artificially-created intelligent population. To achieve this, we simulate a large-scale predator-prey world, where the laws of the world are designed by only the findings or logical equivalence that have been discovered in nature. We endow the agents with the intelligence based on deep reinforcement learning (DRL). In order to scale the population size up to millions agents, a large-scale DRL training platform with redesigned experience buffer is proposed. Our results show that the population dynamics of AI agents, driven only by each agent's individual self-interest, reveals an ordered pattern that is similar to the Lotka-Volterra model studied in population biology. We further discover the emergent behaviors of collective adaptations in studying how the agents' grouping behaviors will change with the environmental resources. Both of the two findings could be explained by the self-organization theory in nature.
Scalable Relaxations of Sparse Packing Constraints: Optimal Biocontrol in Predator-Prey Network
Feb 08, 2018
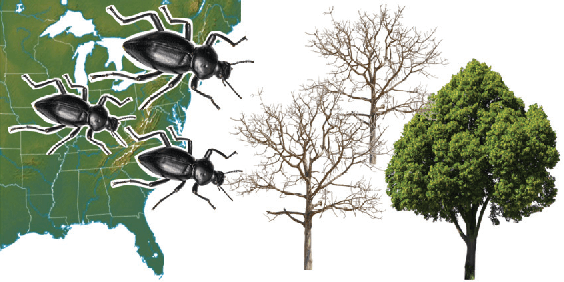
Cascades represent rapid changes in networks. A cascading phenomenon of ecological and economic impact is the spread of invasive species in geographic landscapes. The most promising management strategy is often biocontrol, which entails introducing a natural predator able to control the invading population, a setting that can be treated as two interacting cascades of predator and prey populations. We formulate and study a nonlinear problem of optimal biocontrol: optimally seeding the predator cascade over time to minimize the harmful prey population. Recurring budgets, which typically face conservation organizations, naturally leads to sparse constraints which make the problem amenable to approximation algorithms. Available methods based on continuous relaxations scale poorly, to remedy this we develop a novel and scalable randomized algorithm based on a width relaxation, applicable to a broad class of combinatorial optimization problems. We evaluate our contributions in the context of biocontrol for the insect pest Hemlock Wolly Adelgid (HWA) in eastern North America. Our algorithm outperforms competing methods in terms of scalability and solution quality, and finds near optimal strategies for the control of the HWA for fine-grained networks -- an important problem in computational sustainability.