 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinding Safe Zones of policies Markov Decision Processes
Feb 23, 2022
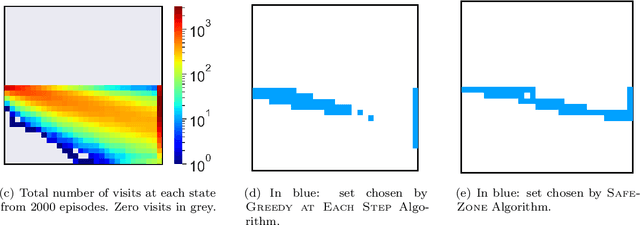
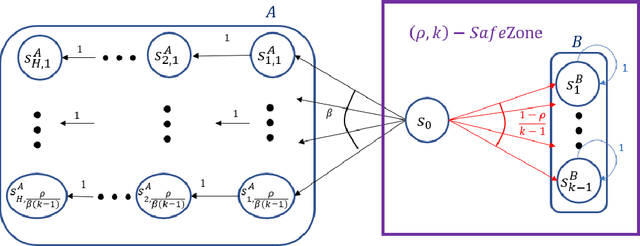
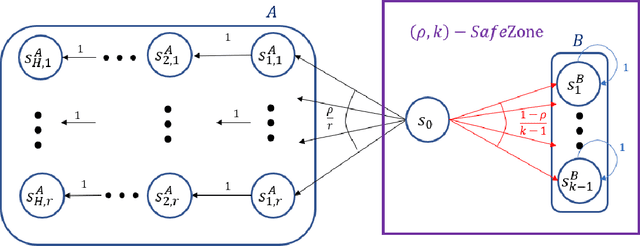
Given a policy, we define a SafeZone as a subset of states, such that most of the policy's trajectories are confined to this subset. The quality of the SafeZone is parameterized by the number of states and the escape probability, i.e., the probability that a random trajectory will leave the subset. SafeZones are especially interesting when they have a small number of states and low escape probability. We study the complexity of finding optimal SafeZones, and show that in general the problem is computationally hard. For this reason we concentrate on computing approximate SafeZones. Our main result is a bi-criteria approximation algorithm which gives a factor of almost $2$ approximation for both the escape probability and SafeZone size, using a polynomial size sample complexity. We conclude the paper with an empirical evaluation of our algorithm.
Fair Wrapping for Black-box Predictions
Feb 16, 2022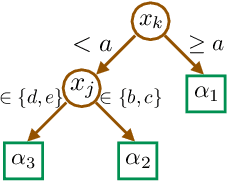
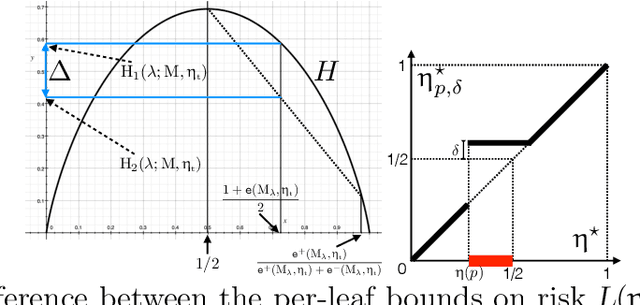
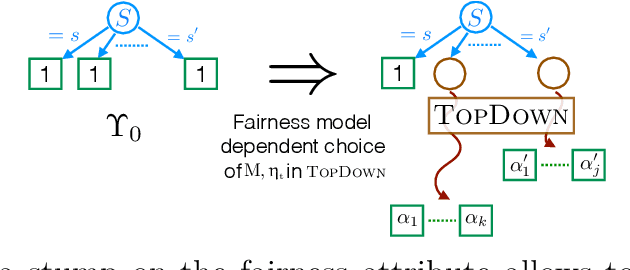
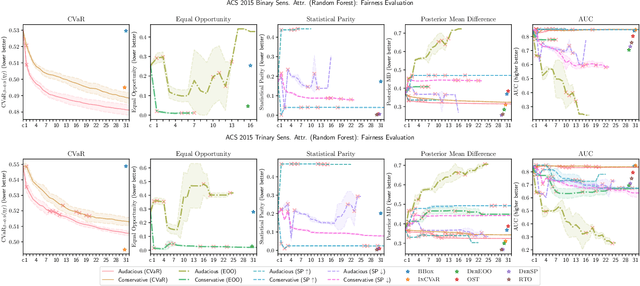
We introduce a new family of techniques to post-process ("wrap") a black-box classifier in order to reduce its bias. Our technique builds on the recent analysis of improper loss functions whose optimisation can correct any twist in prediction, unfairness being treated as a twist. In the post-processing, we learn a wrapper function which we define as an {\alpha}-tree, which modifies the prediction. We provide two generic boosting algorithms to learn {\alpha}-trees. We show that our modification has appealing properties in terms of composition of{\alpha}-trees, generalization, interpretability, and KL divergence between modified and original predictions. We exemplify the use of our technique in three fairness notions: conditional value at risk, equality of opportunity, and statistical parity; and provide experiments on several readily available datasets.
Stochastic Strategic Patient Buyers: Revenue maximization using posted prices
Feb 12, 2022We consider a seller faced with buyers which have the ability to delay their decision, which we call patience. Each buyer's type is composed of value and patience, and it is sampled i.i.d. from a distribution. The seller, using posted prices, would like to maximize her revenue from selling to the buyer. Our main results are the following. $\bullet$ We formalize this setting and characterize the resulting Stackelberg equilibrium, where the seller first commits to her strategy and then the buyers best respond. $\bullet$ We show a separation between the best fixed price, the best pure strategy, which is a fixed sequence of prices, and the best mixed strategy, which is a distribution over price sequences. $\bullet$ We characterize both the optimal pure strategy of the seller and the buyer's best response strategy to any seller's mixed strategy. $\bullet$ We show how to compute efficiently the optimal pure strategy and give an algorithm for the optimal mixed strategy (which is exponential in the maximum patience). We then consider a learning setting, where the seller does not have access to the distribution over buyer's types. Our main results are the following. $\bullet$ We derive a sample complexity bound for the learning of an approximate optimal pure strategy, by computing the fat-shattering dimension of this setting. $\bullet$ We give a general sample complexity bound for the approximate optimal mixed strategy. $\bullet$ We consider an online setting and derive a vanishing regret bound with respect to both the optimal pure strategy and the optimal mixed strategy.
A Characterization of Semi-Supervised Adversarially-Robust PAC Learnability
Feb 11, 2022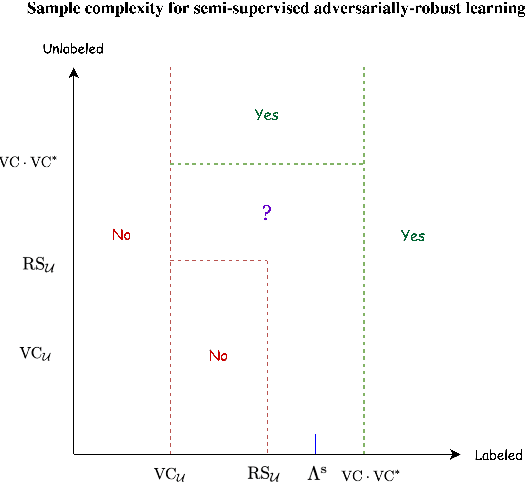
We study the problem of semi-supervised learning of an adversarially-robust predictor in the PAC model, where the learner has access to both labeled and unlabeled examples. The sample complexity in semi-supervised learning has two parameters, the number of labeled examples and the number of unlabeled examples. We consider the complexity measures, $VC_U \leq dim_U \leq VC$ and $VC^*$, where $VC$ is the standard $VC$-dimension, $VC^*$ is its dual, and the other two measures appeared in Montasser et al. (2019). The best sample bound known for robust supervised PAC learning is $O(VC \cdot VC^*)$, and we will compare our sample bounds to $\Lambda$ which is the minimal number of labeled examples required by any robust supervised PAC learning algorithm. Our main results are the following: (1) in the realizable setting it is sufficient to have $O(VC_U)$ labeled examples and $O(\Lambda)$ unlabeled examples. (2) In the agnostic setting, let $\eta$ be the minimal agnostic error. The sample complexity depends on the resulting error rate. If we allow an error of $2\eta+\epsilon$, it is still sufficient to have $O(VC_U)$ labeled examples and $O(\Lambda)$ unlabeled examples. If we insist on having an error $\eta+\epsilon$ then $\Omega(dim_U)$ labeled examples are necessary, as in the supervised case. The above results show that there is a significant benefit in semi-supervised robust learning, as there are hypothesis classes with $VC_U=0$ and $dim_U$ arbitrary large. In supervised learning, having access only to labeled examples requires at least $\Lambda \geq dim_U$ labeled examples. Semi-supervised require only $O(1)$ labeled examples and $O(\Lambda)$ unlabeled examples. A byproduct of our result is that if we assume that the distribution is robustly realizable by a hypothesis class, then with respect to the 0-1 loss we can learn with only $O(VC_U)$ labeled examples, even if the $VC$ is infinite.
Monotone Learning
Feb 10, 2022
The amount of training-data is one of the key factors which determines the generalization capacity of learning algorithms. Intuitively, one expects the error rate to decrease as the amount of training-data increases. Perhaps surprisingly, natural attempts to formalize this intuition give rise to interesting and challenging mathematical questions. For example, in their classical book on pattern recognition, Devroye, Gyorfi, and Lugosi (1996) ask whether there exists a {monotone} Bayes-consistent algorithm. This question remained open for over 25 years, until recently Pestov (2021) resolved it for binary classification, using an intricate construction of a monotone Bayes-consistent algorithm. We derive a general result in multiclass classification, showing that every learning algorithm A can be transformed to a monotone one with similar performance. Further, the transformation is efficient and only uses a black-box oracle access to A. This demonstrates that one can provably avoid non-monotonic behaviour without compromising performance, thus answering questions asked by Devroye et al (1996), Viering, Mey, and Loog (2019), Viering and Loog (2021), and by Mhammedi (2021). Our transformation readily implies monotone learners in a variety of contexts: for example it extends Pestov's result to classification tasks with an arbitrary number of labels. This is in contrast with Pestov's work which is tailored to binary classification. In addition, we provide uniform bounds on the error of the monotone algorithm. This makes our transformation applicable in distribution-free settings. For example, in PAC learning it implies that every learnable class admits a monotone PAC learner. This resolves questions by Viering, Mey, and Loog (2019); Viering and Loog (2021); Mhammedi (2021).
Near-Optimal Regret for Adversarial MDP with Delayed Bandit Feedback
Jan 31, 2022The standard assumption in reinforcement learning (RL) is that agents observe feedback for their actions immediately. However, in practice feedback is often observed in delay. This paper studies online learning in episodic Markov decision process (MDP) with unknown transitions, adversarially changing costs, and unrestricted delayed bandit feedback. More precisely, the feedback for the agent in episode $k$ is revealed only in the end of episode $k + d^k$, where the delay $d^k$ can be changing over episodes and chosen by an oblivious adversary. We present the first algorithms that achieve near-optimal $\sqrt{K + D}$ regret, where $K$ is the number of episodes and $D = \sum_{k=1}^K d^k$ is the total delay, significantly improving upon the best known regret bound of $(K + D)^{2/3}$.
Cooperative Online Learning in Stochastic and Adversarial MDPs
Jan 31, 2022
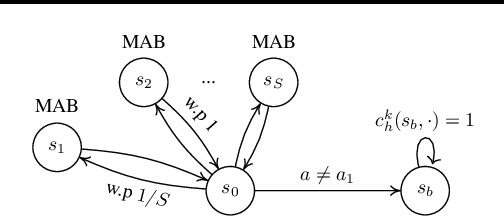
We study cooperative online learning in stochastic and adversarial Markov decision process (MDP). That is, in each episode, $m$ agents interact with an MDP simultaneously and share information in order to minimize their individual regret. We consider environments with two types of randomness: \emph{fresh} -- where each agent's trajectory is sampled i.i.d, and \emph{non-fresh} -- where the realization is shared by all agents (but each agent's trajectory is also affected by its own actions). More precisely, with non-fresh randomness the realization of every cost and transition is fixed at the start of each episode, and agents that take the same action in the same state at the same time observe the same cost and next state. We thoroughly analyze all relevant settings, highlight the challenges and differences between the models, and prove nearly-matching regret lower and upper bounds. To our knowledge, we are the first to consider cooperative reinforcement learning (RL) with either non-fresh randomness or in adversarial MDPs.
Differentially-Private Clustering of Easy Instances
Dec 29, 2021

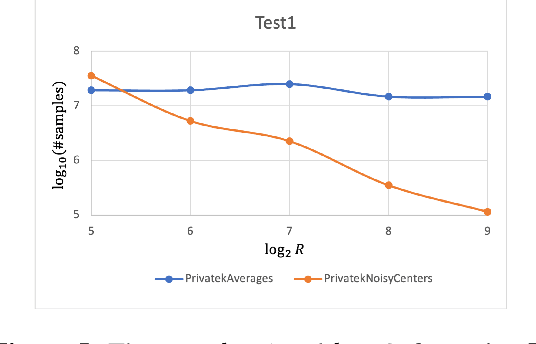
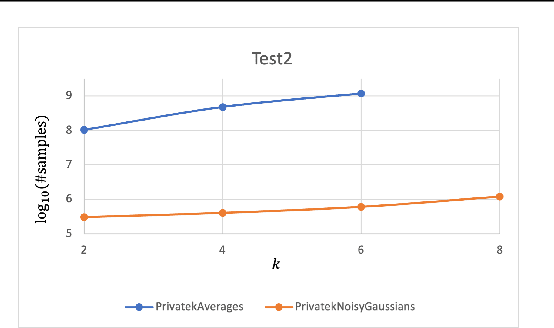
Clustering is a fundamental problem in data analysis. In differentially private clustering, the goal is to identify $k$ cluster centers without disclosing information on individual data points. Despite significant research progress, the problem had so far resisted practical solutions. In this work we aim at providing simple implementable differentially private clustering algorithms that provide utility when the data is "easy," e.g., when there exists a significant separation between the clusters. We propose a framework that allows us to apply non-private clustering algorithms to the easy instances and privately combine the results. We are able to get improved sample complexity bounds in some cases of Gaussian mixtures and $k$-means. We complement our theoretical analysis with an empirical evaluation on synthetic data.
Nonstochastic Bandits with Composite Anonymous Feedback
Dec 06, 2021
We investigate a nonstochastic bandit setting in which the loss of an action is not immediately charged to the player, but rather spread over the subsequent rounds in an adversarial way. The instantaneous loss observed by the player at the end of each round is then a sum of many loss components of previously played actions. This setting encompasses as a special case the easier task of bandits with delayed feedback, a well-studied framework where the player observes the delayed losses individually. Our first contribution is a general reduction transforming a standard bandit algorithm into one that can operate in the harder setting: We bound the regret of the transformed algorithm in terms of the stability and regret of the original algorithm. Then, we show that the transformation of a suitably tuned FTRL with Tsallis entropy has a regret of order $\sqrt{(d+1)KT}$, where $d$ is the maximum delay, $K$ is the number of arms, and $T$ is the time horizon. Finally, we show that our results cannot be improved in general by exhibiting a matching (up to a log factor) lower bound on the regret of any algorithm operating in this setting.
FriendlyCore: Practical Differentially Private Aggregation
Oct 19, 2021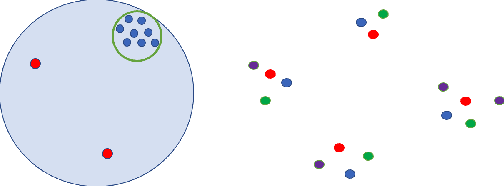
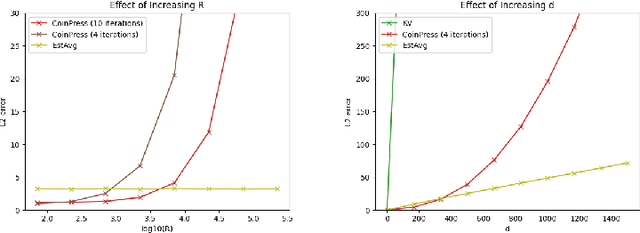
Differentially private algorithms for common metric aggregation tasks, such as clustering or averaging, often have limited practicality due to their complexity or a large number of data points that is required for accurate results. We propose a simple and practical tool $\mathsf{FriendlyCore}$ that takes a set of points ${\cal D}$ from an unrestricted (pseudo) metric space as input. When ${\cal D}$ has effective diameter $r$, $\mathsf{FriendlyCore}$ returns a "stable" subset ${\cal D}_G\subseteq {\cal D}$ that includes all points, except possibly few outliers, and is {\em certified} to have diameter $r$. $\mathsf{FriendlyCore}$ can be used to preprocess the input before privately aggregating it, potentially simplifying the aggregation or boosting its accuracy. Surprisingly, $\mathsf{FriendlyCore}$ is light-weight with no dependence on the dimension. We empirically demonstrate its advantages in boosting the accuracy of mean estimation, outperforming tailored methods.