 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Memory Networks with Self-supervised Learning for Unsupervised Anomaly Detection
Jan 03, 2022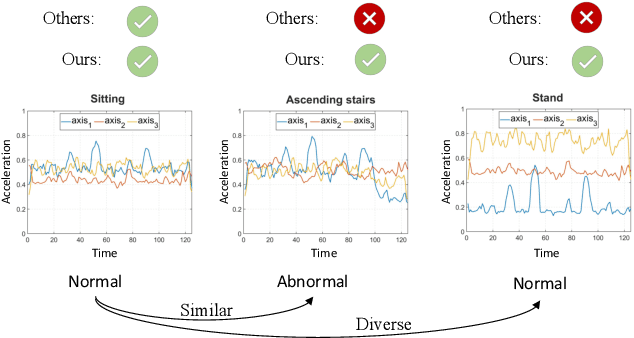

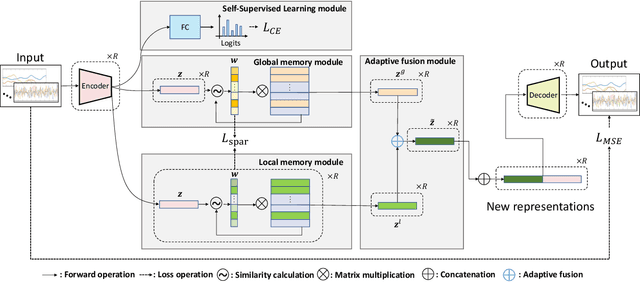
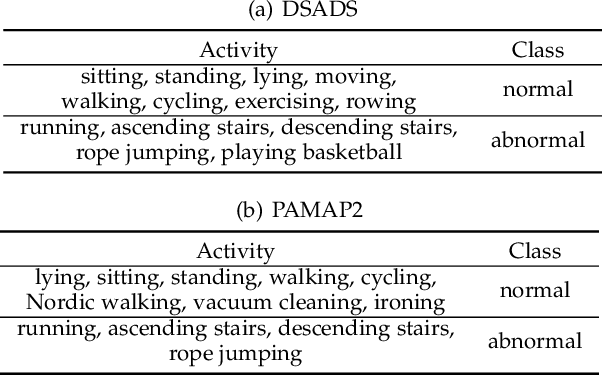
Unsupervised anomaly detection aims to build models to effectively detect unseen anomalies by only training on the normal data. Although previous reconstruction-based methods have made fruitful progress, their generalization ability is limited due to two critical challenges. First, the training dataset only contains normal patterns, which limits the model generalization ability. Second, the feature representations learned by existing models often lack representativeness which hampers the ability to preserve the diversity of normal patterns. In this paper, we propose a novel approach called Adaptive Memory Network with Self-supervised Learning (AMSL) to address these challenges and enhance the generalization ability in unsupervised anomaly detection. Based on the convolutional autoencoder structure, AMSL incorporates a self-supervised learning module to learn general normal patterns and an adaptive memory fusion module to learn rich feature representations. Experiments on four public multivariate time series datasets demonstrate that AMSL significantly improves the performance compared to other state-of-the-art methods. Specifically, on the largest CAP sleep stage detection dataset with 900 million samples, AMSL outperforms the second-best baseline by \textbf{4}\%+ in both accuracy and F1 score. Apart from the enhanced generalization ability, AMSL is also more robust against input noise.
Federated Learning with Adaptive Batchnorm for Personalized Healthcare
Dec 01, 2021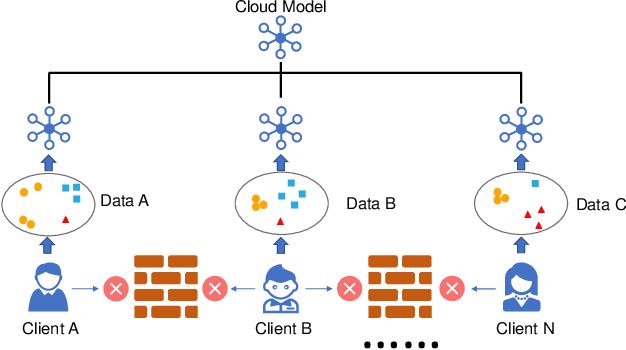

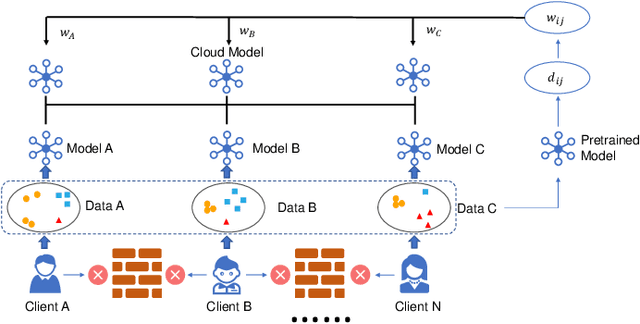

There is a growing interest in applying machine learning techniques for healthcare. Recently, federated machine learning (FL) is gaining popularity since it allows researchers to train powerful models without compromising data privacy and security. However, the performance of existing FL approaches often deteriorates when encountering non-iid situations where there exist distribution gaps among clients, and few previous efforts focus on personalization in healthcare. In this article, we propose AdaFed to tackle domain shifts and obtain personalized models for local clients. AdaFed learns the similarity between clients via the statistics of the batch normalization layers while preserving the specificity of each client with different local batch normalization. Comprehensive experiments on five healthcare benchmarks demonstrate that AdaFed achieves better accuracy compared to state-of-the-art methods (e.g., \textbf{10}\%+ accuracy improvement for PAMAP2) with faster convergence speed.
Unsupervised Deep Anomaly Detection for Multi-Sensor Time-Series Signals
Aug 02, 2021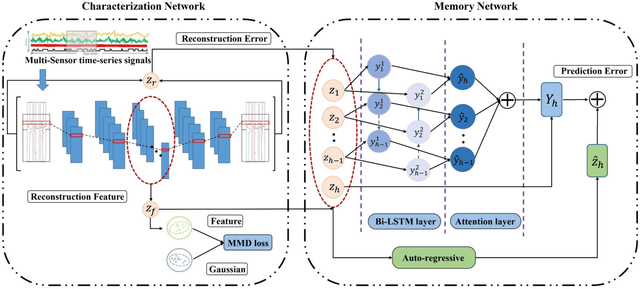

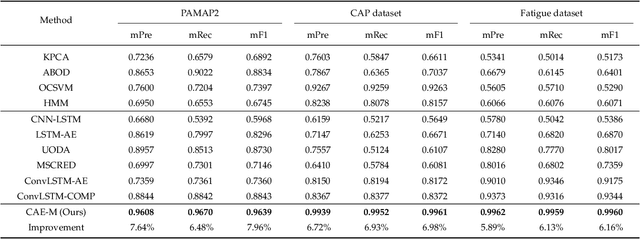
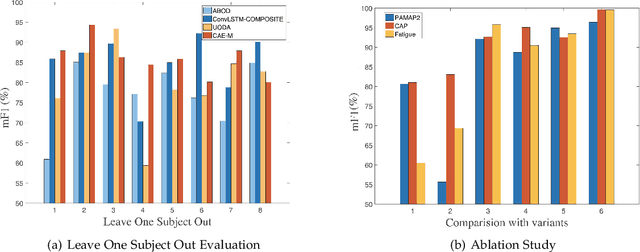
Nowadays, multi-sensor technologies are applied in many fields, e.g., Health Care (HC), Human Activity Recognition (HAR), and Industrial Control System (ICS). These sensors can generate a substantial amount of multivariate time-series data. Unsupervised anomaly detection on multi-sensor time-series data has been proven critical in machine learning researches. The key challenge is to discover generalized normal patterns by capturing spatial-temporal correlation in multi-sensor data. Beyond this challenge, the noisy data is often intertwined with the training data, which is likely to mislead the model by making it hard to distinguish between the normal, abnormal, and noisy data. Few of previous researches can jointly address these two challenges. In this paper, we propose a novel deep learning-based anomaly detection algorithm called Deep Convolutional Autoencoding Memory network (CAE-M). We first build a Deep Convolutional Autoencoder to characterize spatial dependence of multi-sensor data with a Maximum Mean Discrepancy (MMD) to better distinguish between the noisy, normal, and abnormal data. Then, we construct a Memory Network consisting of linear (Autoregressive Model) and non-linear predictions (Bidirectional LSTM with Attention) to capture temporal dependence from time-series data. Finally, CAE-M jointly optimizes these two subnetworks. We empirically compare the proposed approach with several state-of-the-art anomaly detection methods on HAR and HC datasets. Experimental results demonstrate that our proposed model outperforms these existing methods.
FedHealth 2: Weighted Federated Transfer Learning via Batch Normalization for Personalized Healthcare
Jun 02, 2021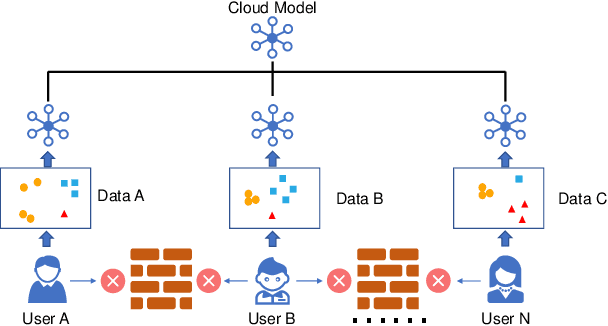

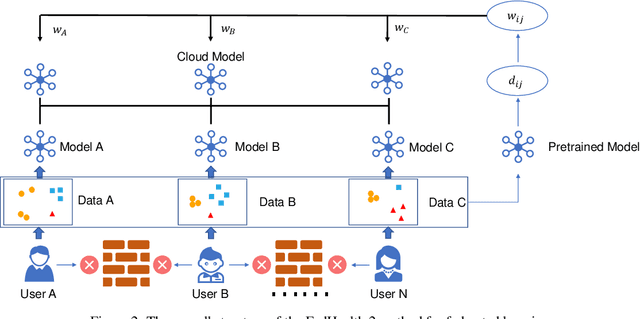
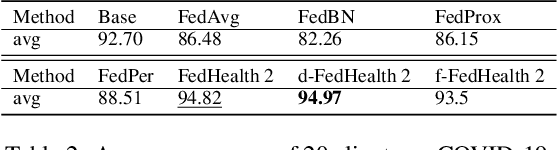
The success of machine learning applications often needs a large quantity of data. Recently, federated learning (FL) is attracting increasing attention due to the demand for data privacy and security, especially in the medical field. However, the performance of existing FL approaches often deteriorates when there exist domain shifts among clients, and few previous works focus on personalization in healthcare. In this article, we propose FedHealth 2, an extension of FedHealth \cite{chen2020fedhealth} to tackle domain shifts and get personalized models for local clients. FedHealth 2 obtains the client similarities via a pretrained model, and then it averages all weighted models with preserving local batch normalization. Wearable activity recognition and COVID-19 auxiliary diagnosis experiments have evaluated that FedHealth 2 can achieve better accuracy (10%+ improvement for activity recognition) and personalized healthcare without compromising privacy and security.
Cross-domain Activity Recognition via Substructural Optimal Transport
Jan 29, 2021

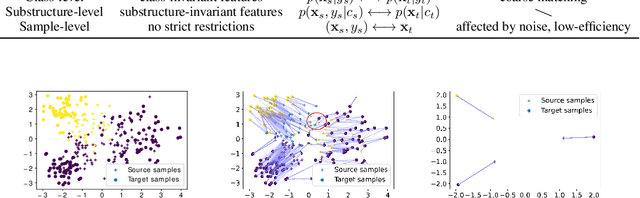

It is expensive and time-consuming to collect sufficient labeled data for human activity recognition (HAR). Recently, lots of work solves the problem via domain adaptation which leverages the labeled samples from the source domain to annotate the target domain. Existing domain adaptation methods mainly focus on adapting cross-domain representations via domain-level, class-level, or sample-level distribution matching. However, the domain- and class-level matching are too coarse that may result in under-adaptation, while sample-level matching may be affected by the noise seriously and eventually cause over-adaptation. In this paper, we propose substructure-level matching for domain adaptation (SSDA) to utilize the internal substructures of the domain to perform accurate and efficient knowledge transfer. Based on SSDA, we propose an optimal transport-based implementation, Substructural Optimal Transport (SOT), for cross-domain HAR. We obtain the substructures of activities via clustering methods and seeks the coupling of the weighted substructures between different domains. We conduct comprehensive experiments on four large public activity recognition datasets (i.e. UCI-DSADS, UCI-HAR, USC-HAD, PAMAP2), which demonstrates that SOT significantly outperforms other state-of-the-art methods w.r.t classification accuracy (10%+ improvement). In addition, SOT is much faster than comparison methods.
Learning to Match Distributions for Domain Adaptation
Jul 27, 2020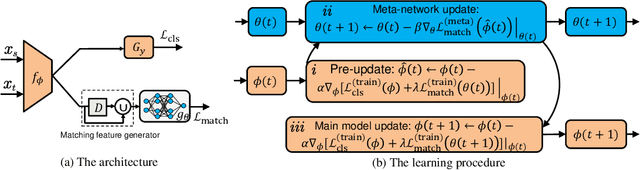

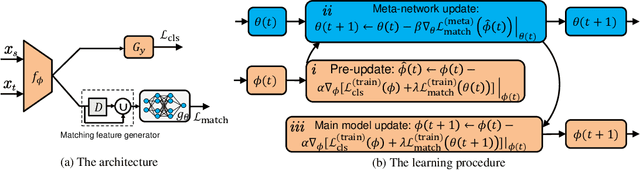
When the training and test data are from different distributions, domain adaptation is needed to reduce dataset bias to improve the model's generalization ability. Since it is difficult to directly match the cross-domain joint distributions, existing methods tend to reduce the marginal or conditional distribution divergence using predefined distances such as MMD and adversarial-based discrepancies. However, it remains challenging to determine which method is suitable for a given application since they are built with certain priors or bias. Thus they may fail to uncover the underlying relationship between transferable features and joint distributions. This paper proposes Learning to Match (L2M) to automatically learn the cross-domain distribution matching without relying on hand-crafted priors on the matching loss. Instead, L2M reduces the inductive bias by using a meta-network to learn the distribution matching loss in a data-driven way. L2M is a general framework that unifies task-independent and human-designed matching features. We design a novel optimization algorithm for this challenging objective with self-supervised label propagation. Experiments on public datasets substantiate the superiority of L2M over SOTA methods. Moreover, we apply L2M to transfer from pneumonia to COVID-19 chest X-ray images with remarkable performance. L2M can also be extended in other distribution matching applications where we show in a trial experiment that L2M generates more realistic and sharper MNIST samples.
FOCUS: Dealing with Label Quality Disparity in Federated Learning
Jan 29, 2020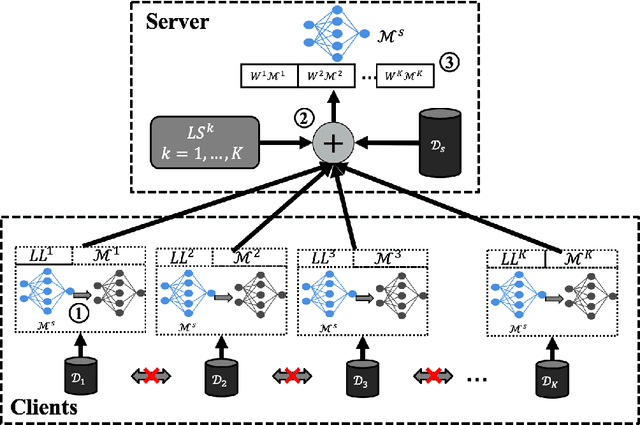
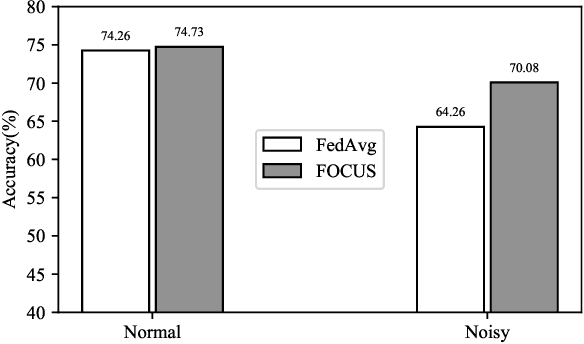
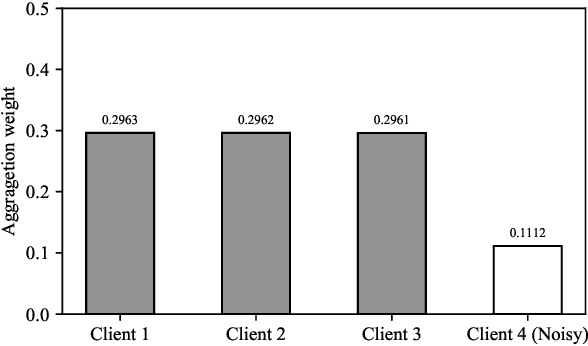
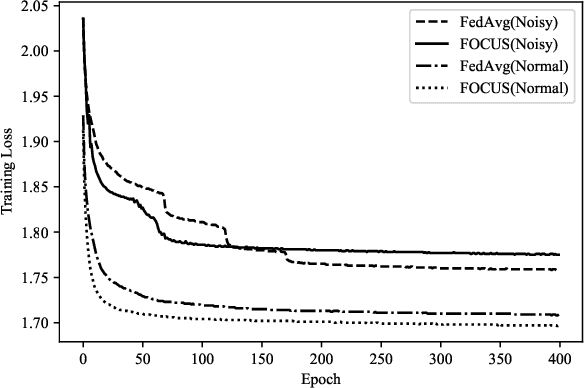
Ubiquitous systems with End-Edge-Cloud architecture are increasingly being used in healthcare applications. Federated Learning (FL) is highly useful for such applications, due to silo effect and privacy preserving. Existing FL approaches generally do not account for disparities in the quality of local data labels. However, the clients in ubiquitous systems tend to suffer from label noise due to varying skill-levels, biases or malicious tampering of the annotators. In this paper, we propose Federated Opportunistic Computing for Ubiquitous Systems (FOCUS) to address this challenge. It maintains a small set of benchmark samples on the FL server and quantifies the credibility of the client local data without directly observing them by computing the mutual cross-entropy between performance of the FL model on the local datasets and that of the client local FL model on the benchmark dataset. Then, a credit weighted orchestration is performed to adjust the weight assigned to clients in the FL model based on their credibility values. FOCUS has been experimentally evaluated on both synthetic data and real-world data. The results show that it effectively identifies clients with noisy labels and reduces their impact on the model performance, thereby significantly outperforming existing FL approaches.
Transfer Learning with Dynamic Adversarial Adaptation Network
Sep 18, 2019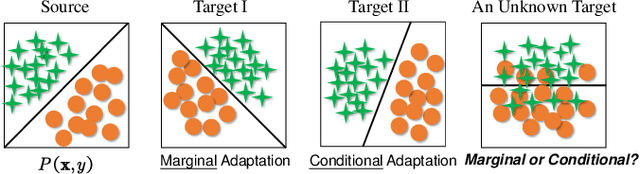
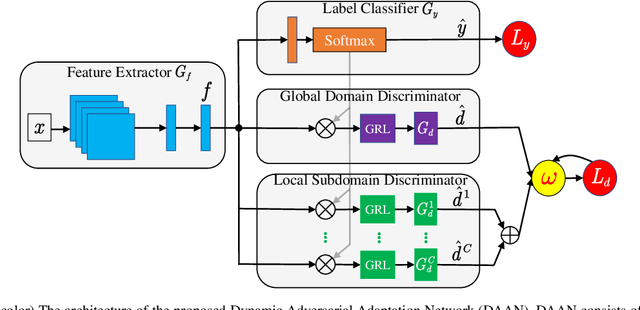

The recent advances in deep transfer learning reveal that adversarial learning can be embedded into deep networks to learn more transferable features to reduce the distribution discrepancy between two domains. Existing adversarial domain adaptation methods either learn a single domain discriminator to align the global source and target distributions or pay attention to align subdomains based on multiple discriminators. However, in real applications, the marginal (global) and conditional (local) distributions between domains are often contributing differently to the adaptation. There is currently no method to dynamically and quantitatively evaluate the relative importance of these two distributions for adversarial learning. In this paper, we propose a novel Dynamic Adversarial Adaptation Network (DAAN) to dynamically learn domain-invariant representations while quantitatively evaluate the relative importance of global and local domain distributions. To the best of our knowledge, DAAN is the first attempt to perform dynamic adversarial distribution adaptation for deep adversarial learning. DAAN is extremely easy to implement and train in real applications. We theoretically analyze the effectiveness of DAAN, and it can also be explained in an attention strategy. Extensive experiments demonstrate that DAAN achieves better classification accuracy compared to state-of-the-art deep and adversarial methods. Results also imply the necessity and effectiveness of the dynamic distribution adaptation in adversarial transfer learning.
Transfer Learning with Dynamic Distribution Adaptation
Sep 17, 2019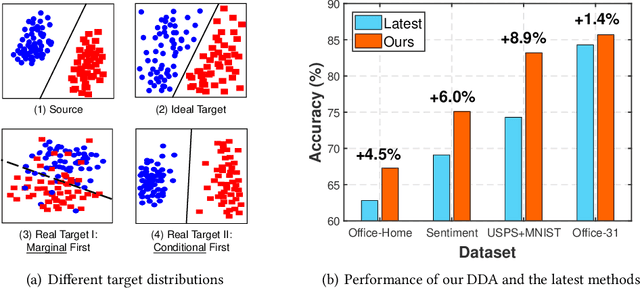
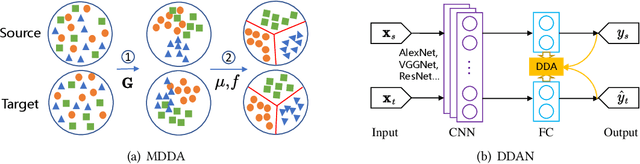

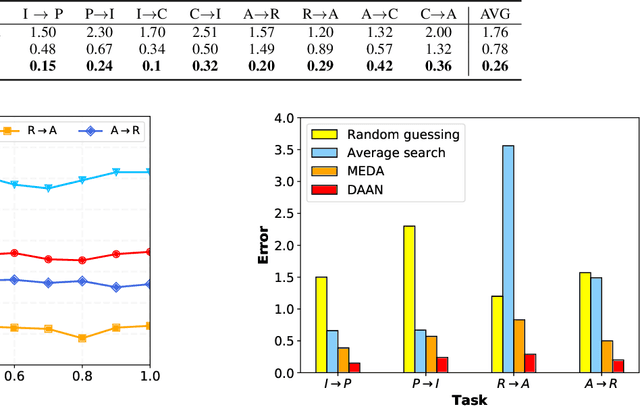
Transfer learning aims to learn robust classifiers for the target domain by leveraging knowledge from a source domain. Since the source and the target domains are usually from different distributions, existing methods mainly focus on adapting the cross-domain marginal or conditional distributions. However, in real applications, the marginal and conditional distributions usually have different contributions to the domain discrepancy. Existing methods fail to quantitatively evaluate the different importance of these two distributions, which will result in unsatisfactory transfer performance. In this paper, we propose a novel concept called Dynamic Distribution Adaptation (DDA), which is capable of quantitatively evaluating the relative importance of each distribution. DDA can be easily incorporated into the framework of structural risk minimization to solve transfer learning problems. On the basis of DDA, we propose two novel learning algorithms: (1) Manifold Dynamic Distribution Adaptation (MDDA) for traditional transfer learning, and (2) Dynamic Distribution Adaptation Network (DDAN) for deep transfer learning. Extensive experiments demonstrate that MDDA and DDAN significantly improve the transfer learning performance and setup a strong baseline over the latest deep and adversarial methods on digits recognition, sentiment analysis, and image classification. More importantly, it is shown that marginal and conditional distributions have different contributions to the domain divergence, and our DDA is able to provide good quantitative evaluation of their relative importance which leads to better performance. We believe this observation can be helpful for future research in transfer learning.
* Accepted to ACM Transactions on Intelligent Systems and Technology (ACM TIST) 2019, 25 pages. arXiv admin note: text overlap with arXiv:1807.07258
FedHealth: A Federated Transfer Learning Framework for Wearable Healthcare
Jul 22, 2019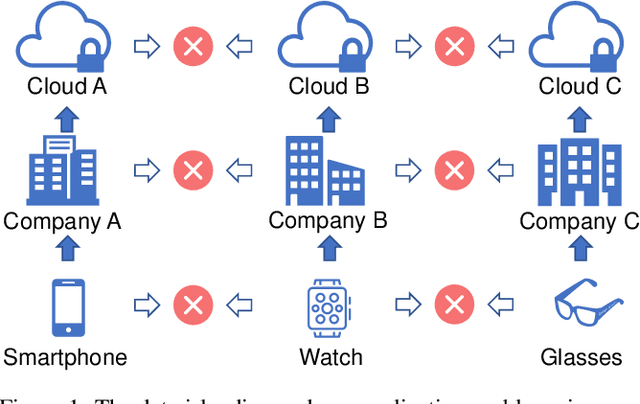

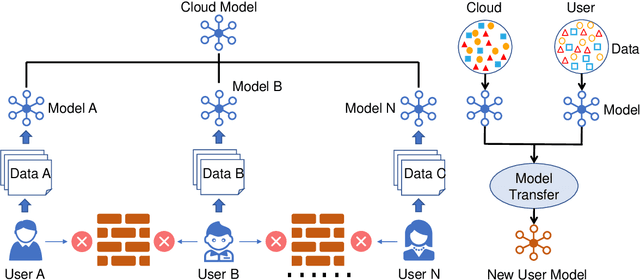
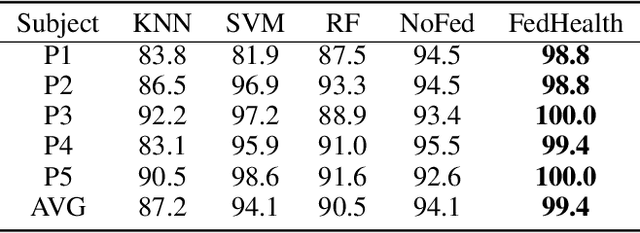
With the rapid development of computing technology, wearable devices such as smart phones and wristbands make it easy to get access to people's health information including activities, sleep, sports, etc. Smart healthcare achieves great success by training machine learning models on a large quantity of user data. However, there are two critical challenges. Firstly, user data often exists in the form of isolated islands, making it difficult to perform aggregation without compromising privacy security. Secondly, the models trained on the cloud fail on personalization. In this paper, we propose FedHealth, the first federated transfer learning framework for wearable healthcare to tackle these challenges. FedHealth performs data aggregation through federated learning, and then builds personalized models by transfer learning. It is able to achieve accurate and personalized healthcare without compromising privacy and security. Experiments demonstrate that FedHealth produces higher accuracy (5.3% improvement) for wearable activity recognition when compared to traditional methods. FedHealth is general and extensible and has the potential to be used in many healthcare applications.