 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEVA: An Open-Domain Chinese Dialogue System with Large-Scale Generative Pre-Training
Aug 03, 2021
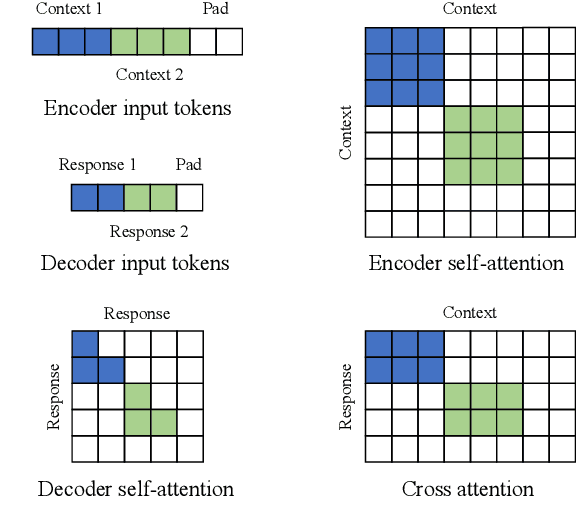
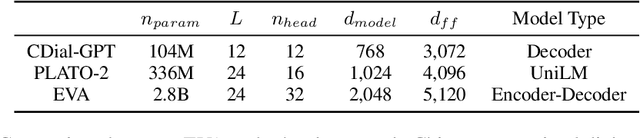
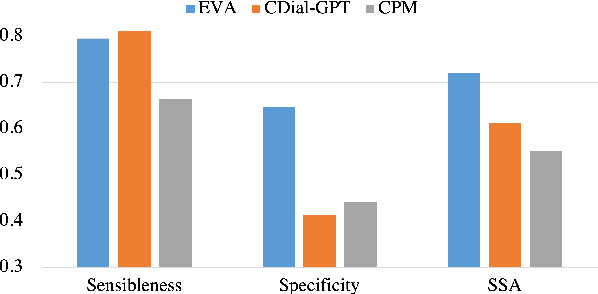
Although pre-trained language models have remarkably enhanced the generation ability of dialogue systems, open-domain Chinese dialogue systems are still limited by the dialogue data and the model size compared with English ones. In this paper, we propose EVA, a Chinese dialogue system that contains the largest Chinese pre-trained dialogue model with 2.8B parameters. To build this model, we collect the largest Chinese dialogue dataset named WDC-Dialogue from various public social media. This dataset contains 1.4B context-response pairs and is used as the pre-training corpus of EVA. Extensive experiments on automatic and human evaluation show that EVA outperforms other Chinese pre-trained dialogue models especially in the multi-turn interaction of human-bot conversations.
Semantic-Enhanced Explainable Finetuning for Open-Domain Dialogues
Jun 06, 2021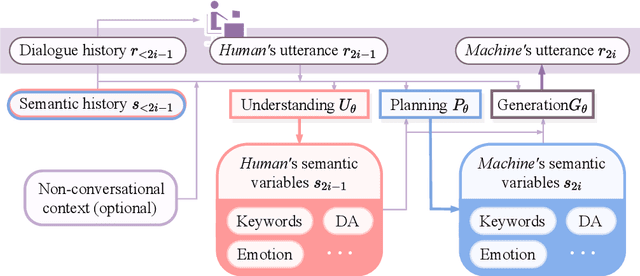
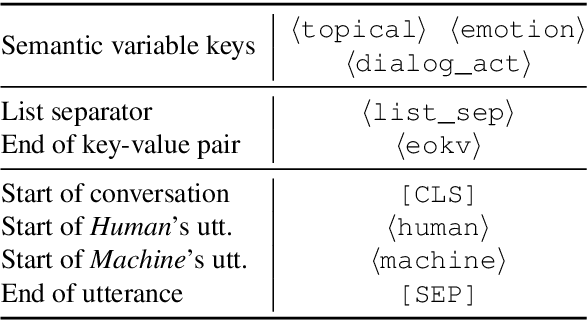
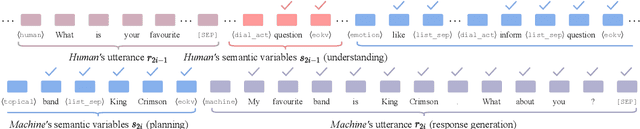
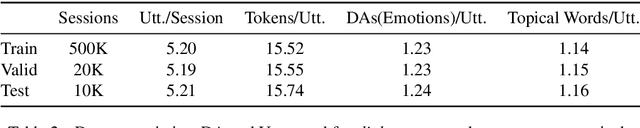
In this paper, we propose to combine pretrained language models with the modular dialogue paradigm for open-domain dialogue modeling. Our method, semantic-enhanced finetuning, instantiates conversation understanding, planning, and response generation as a language model finetuning task. At inference, we disentangle semantic and token variations by specifying sampling methods and constraints for each module separately. For training and evaluation, we present X-Weibo, a Chinese multi-turn open-domain dialogue dataset with automatic annotation for emotions, DAs, and topical words. Experiments show that semantic-enhanced finetuning outperforms strong baselines on non-semantic and semantic metrics, improves the human-evaluated relevance, coherence, and informativeness, and exhibits considerable controllability over semantic variables.
Diversifying Dialog Generation via Adaptive Label Smoothing
May 30, 2021
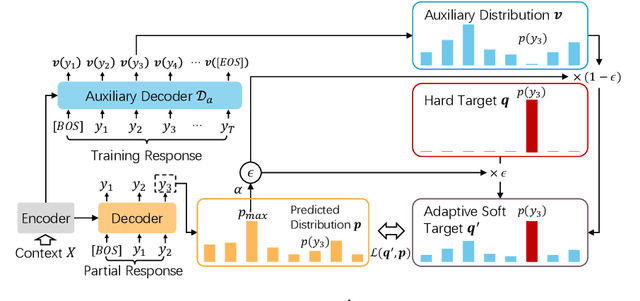
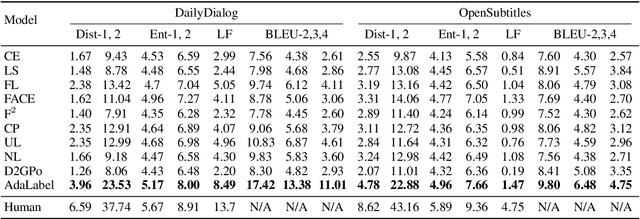
Neural dialogue generation models trained with the one-hot target distribution suffer from the over-confidence issue, which leads to poor generation diversity as widely reported in the literature. Although existing approaches such as label smoothing can alleviate this issue, they fail to adapt to diverse dialog contexts. In this paper, we propose an Adaptive Label Smoothing (AdaLabel) approach that can adaptively estimate a target label distribution at each time step for different contexts. The maximum probability in the predicted distribution is used to modify the soft target distribution produced by a novel light-weight bi-directional decoder module. The resulting target distribution is aware of both previous and future contexts and is adjusted to avoid over-training the dialogue model. Our model can be trained in an end-to-end manner. Extensive experiments on two benchmark datasets show that our approach outperforms various competitive baselines in producing diverse responses.
Listener's Social Identity Matters in Personalised Response Generation
Oct 27, 2020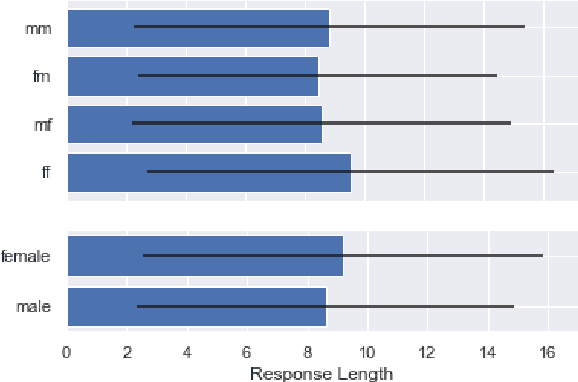
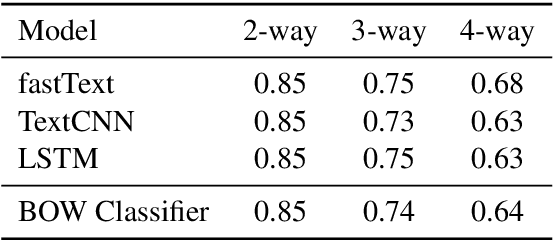
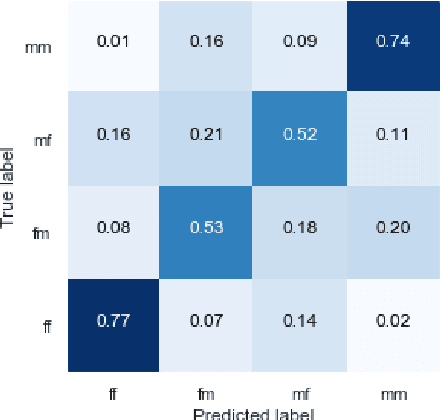
Personalised response generation enables generating human-like responses by means of assigning the generator a social identity. However, pragmatics theory suggests that human beings adjust the way of speaking based on not only who they are but also whom they are talking to. In other words, when modelling personalised dialogues, it might be favourable if we also take the listener's social identity into consideration. To validate this idea, we use gender as a typical example of a social variable to investigate how the listener's identity influences the language used in Chinese dialogues on social media. Also, we build personalised generators. The experiment results demonstrate that the listener's identity indeed matters in the language use of responses and that the response generator can capture such differences in language use. More interestingly, by additionally modelling the listener's identity, the personalised response generator performs better in its own identity.
Stylized Dialogue Response Generation Using Stylized Unpaired Texts
Sep 27, 2020
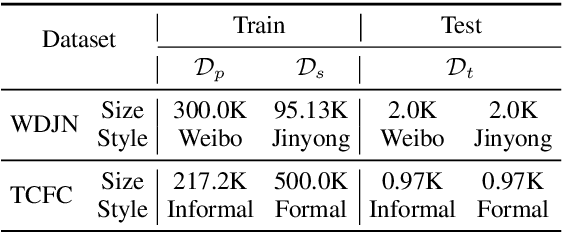
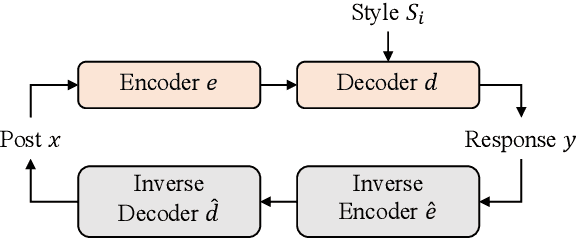
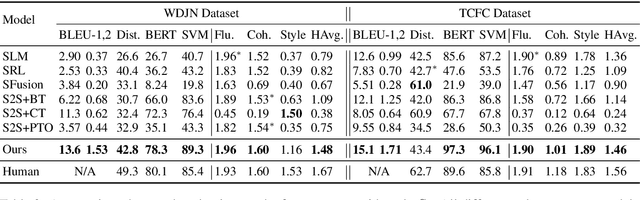
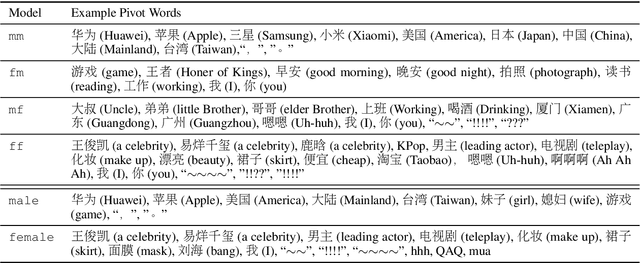
Generating stylized responses is essential to build intelligent and engaging dialogue systems. However, this task is far from well-explored due to the difficulties of rendering a particular style in coherent responses, especially when the target style is embedded only in unpaired texts that cannot be directly used to train the dialogue model. This paper proposes a stylized dialogue generation method that can capture stylistic features embedded in unpaired texts. Specifically, our method can produce dialogue responses that are both coherent to the given context and conform to the target style. In this study, an inverse dialogue model is first introduced to predict possible posts for the input responses, and then this inverse model is used to generate stylized pseudo dialogue pairs based on these stylized unpaired texts. Further, these pseudo pairs are employed to train the stylized dialogue model with a joint training process, and a style routing approach is proposed to intensify stylistic features in the decoder. Automatic and manual evaluations on two datasets demonstrate that our method outperforms competitive baselines in producing coherent and style-intensive dialogue responses.
Dialogue Distillation: Open-domain Dialogue Augmentation Using Unpaired Data
Sep 20, 2020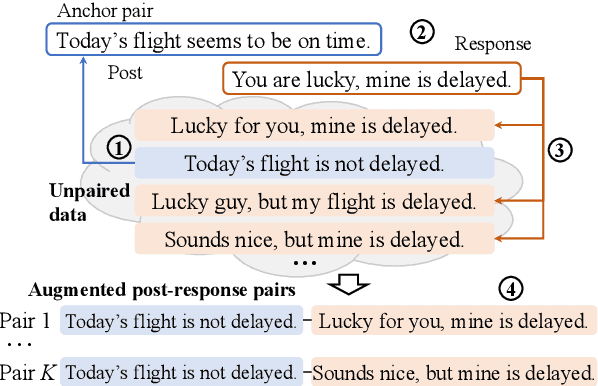
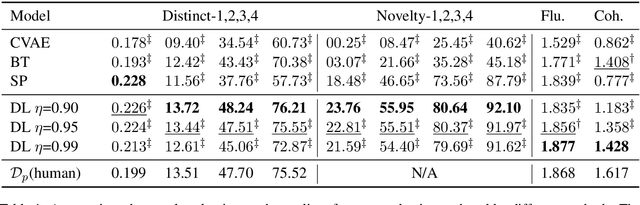
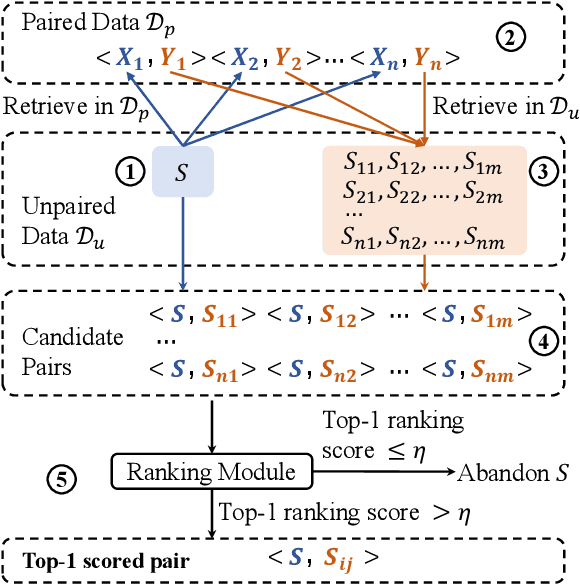
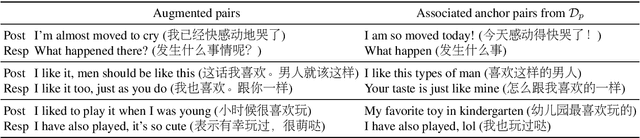
Recent advances in open-domain dialogue systems rely on the success of neural models that are trained on large-scale data. However, collecting large-scale dialogue data is usually time-consuming and labor-intensive. To address this data dilemma, we propose a novel data augmentation method for training open-domain dialogue models by utilizing unpaired data. Specifically, a data-level distillation process is first proposed to construct augmented dialogues where both post and response are retrieved from the unpaired data. A ranking module is employed to filter out low-quality dialogues. Further, a model-level distillation process is employed to distill a teacher model trained on high-quality paired data to augmented dialogue pairs, thereby preventing dialogue models from being affected by the noise in the augmented data. Automatic and manual evaluation indicates that our method can produce high-quality dialogue pairs with diverse contents, and the proposed data-level and model-level dialogue distillation can improve the performance of competitive baselines.
A Large-Scale Chinese Short-Text Conversation Dataset
Aug 10, 2020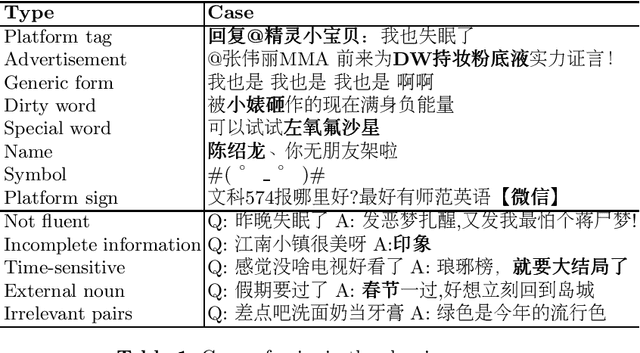
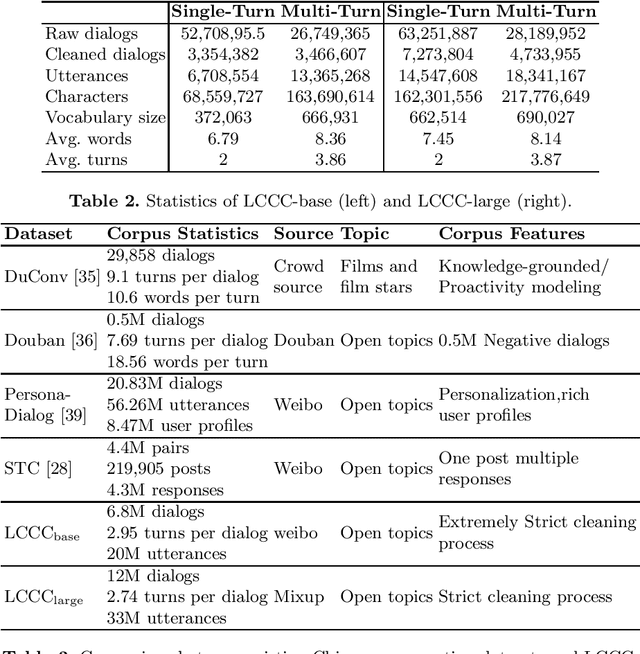


The advancements of neural dialogue generation models show promising results on modeling short-text conversations. However, training such models usually needs a large-scale high-quality dialogue corpus, which is hard to access. In this paper, we present a large-scale cleaned Chinese conversation dataset, LCCC, which contains a base version (6.8million dialogues) and a large version (12.0 million dialogues). The quality of our dataset is ensured by a rigorous data cleaning pipeline, which is built based on a set of rules and a classifier that is trained on manually annotated 110K dialogue pairs. We also release pre-training dialogue models which are trained on LCCC-base and LCCC-large respectively. The cleaned dataset and the pre-training models will facilitate the research of short-text conversation modeling. All the models and datasets are available at https://github.com/thu-coai/CDial-GPT.
A Pre-training Based Personalized Dialogue Generation Model with Persona-sparse Data
Nov 12, 2019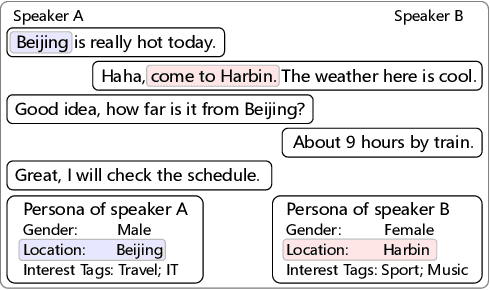

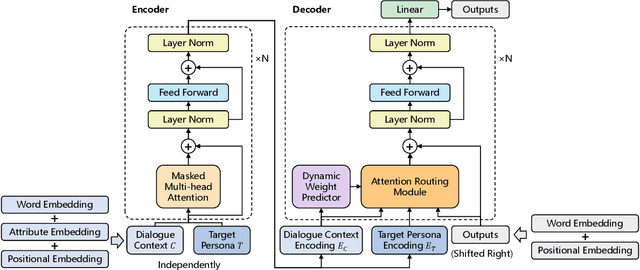
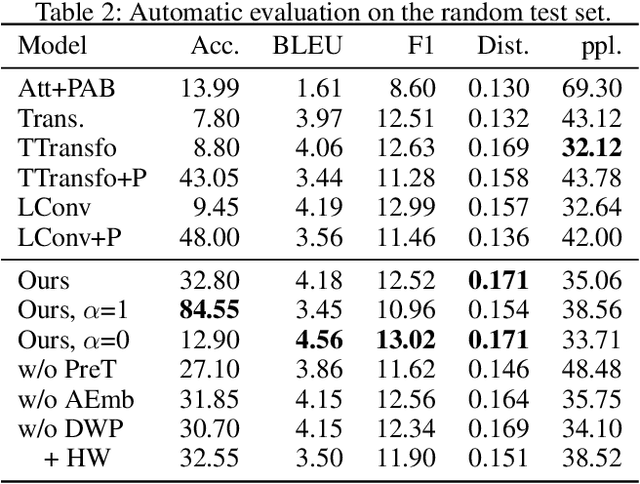
Endowing dialogue systems with personas is essential to deliver more human-like conversations. However, this problem is still far from well explored due to the difficulties of both embodying personalities in natural languages and the persona sparsity issue observed in most dialogue corpora. This paper proposes a pre-training based personalized dialogue model that can generate coherent responses using persona-sparse dialogue data. In this method, a pre-trained language model is used to initialize an encoder and decoder, and personal attribute embeddings are devised to model richer dialogue contexts by encoding speakers' personas together with dialogue histories. Further, to incorporate the target persona in the decoding process and to balance its contribution, an attention routing structure is devised in the decoder to merge features extracted from the target persona and dialogue contexts using dynamically predicted weights. Our model can utilize persona-sparse dialogues in a unified manner during the training process, and can also control the amount of persona-related features to exhibit during the inference process. Both automatic and manual evaluation demonstrates that the proposed model outperforms state-of-the-art methods for generating more coherent and persona consistent responses with persona-sparse data.
Out-of-domain Detection for Natural Language Understanding in Dialog Systems
Sep 09, 2019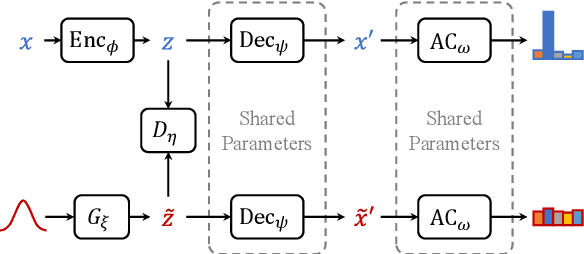
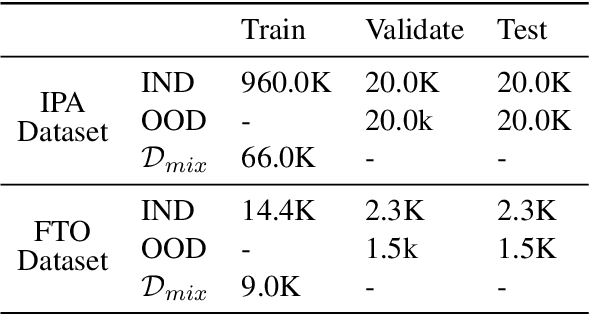
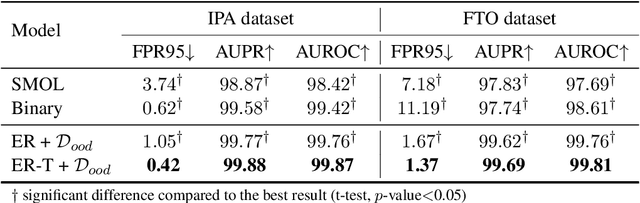
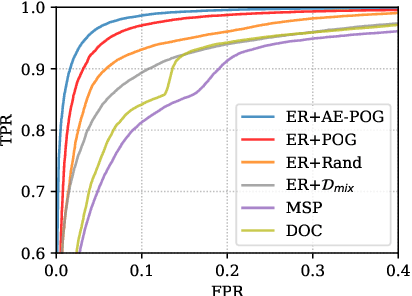
In natural language understanding components, detecting out-of-domain (OOD) inputs is important for dialogue systems since wrongly accepting these OOD utterances that are not currently supported may lead to catastrophic failures of the entire system. Entropy regularization is an effective solution to avoid such failures, however, its computation heavily depends on OOD data, which are expensive to collect. In this paper, we propose a novel text generation model to produce high-quality OOD samples and thereby improve the performance of OOD detection. The proposed model can also utilize a set of unlabeled data to improve the effectiveness of these generated OOD samples. Experiments show that our method can effectively improve the OOD detection performance of a NLU module.
Personalized Dialogue Generation with Diversified Traits
Jan 28, 2019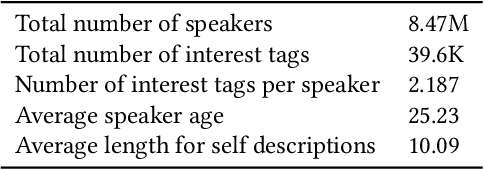
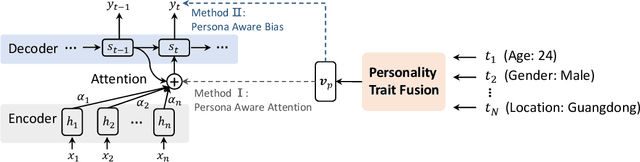

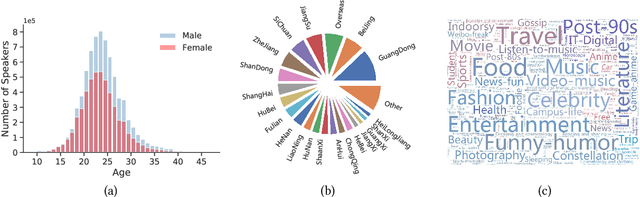
Endowing a dialogue system with particular personality traits is essential to deliver more human-like conversations. However, due to the challenge of embodying personality via language expression and the lack of large-scale persona-labeled dialogue data, this research problem is still far from well-studied. In this paper, we investigate the problem of incorporating explicit personality traits in dialogue generation to deliver personalized dialogues. To this end, firstly, we construct PersonalDialog, a large-scale multi-turn dialogue dataset containing various traits from a large number of speakers. The dataset consists of 20.83M sessions and 56.25M utterances from 8.47M speakers. Each utterance is associated with a speaker who is marked with traits like Age, Gender, Location, Interest Tags, etc. Several anonymization schemes are designed to protect the privacy of each speaker. This large-scale dataset will facilitate not only the study of personalized dialogue generation, but also other researches on sociolinguistics or social science. Secondly, to study how personality traits can be captured and addressed in dialogue generation, we propose persona-aware dialogue generation models within the sequence to sequence learning framework. Explicit personality traits (structured by key-value pairs) are embedded using a trait fusion module. During the decoding process, two techniques, namely persona-aware attention and persona-aware bias, are devised to capture and address trait-related information. Experiments demonstrate that our model is able to address proper traits in different contexts. Case studies also show interesting results for this challenging research problem.