 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Do Answer Tokens Read Reasoning Traces? Self-Reading Patterns in Thinking LLMs for Quantitative Reasoning
Apr 21, 2026Thinking LLMs produce reasoning traces before answering. Prior activation steering work mainly targets on shaping these traces. It remains less understood how answer tokens actually read and integrate the reasoning to produce reliable outcomes. Focusing on quantitative reasoning, we analyze the answer-to-reasoning attention and observe a benign self-reading pattern aligned with correctness, characterized by a forward drift of the reading focus along the reasoning trace and a persistent concentration on key semantic anchors, whereas incorrect solutions exhibit diffuse and irregular attention pattern. We interpret this as internal certainty during answer decoding, where the model commits to a viable solution branch and integrates key evidence. Following this, we propose a training-free steering method driven by Self-Reading Quality (SRQ) scores combining geometric metrics for process control with semantic metrics for content monitoring. SRQ selects data to build steering vectors that guide inference toward benign self-reading and away from uncertain and disorganized reading. Experiments show that our method yields consistent accuracy gains.
Dialogue Distillation: Open-domain Dialogue Augmentation Using Unpaired Data
Sep 20, 2020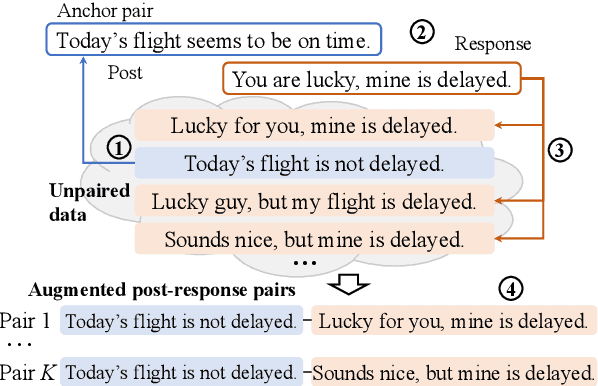
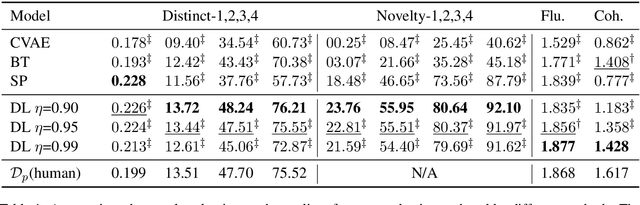
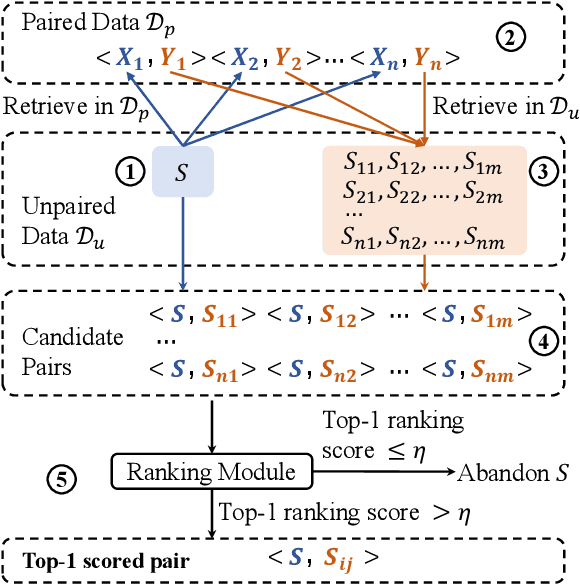
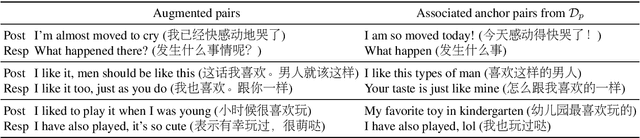
Recent advances in open-domain dialogue systems rely on the success of neural models that are trained on large-scale data. However, collecting large-scale dialogue data is usually time-consuming and labor-intensive. To address this data dilemma, we propose a novel data augmentation method for training open-domain dialogue models by utilizing unpaired data. Specifically, a data-level distillation process is first proposed to construct augmented dialogues where both post and response are retrieved from the unpaired data. A ranking module is employed to filter out low-quality dialogues. Further, a model-level distillation process is employed to distill a teacher model trained on high-quality paired data to augmented dialogue pairs, thereby preventing dialogue models from being affected by the noise in the augmented data. Automatic and manual evaluation indicates that our method can produce high-quality dialogue pairs with diverse contents, and the proposed data-level and model-level dialogue distillation can improve the performance of competitive baselines.