 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaDeep: A Usage-Driven, Automated Deep Model Compression Framework for Enabling Ubiquitous Intelligent Mobiles
Jun 08, 2020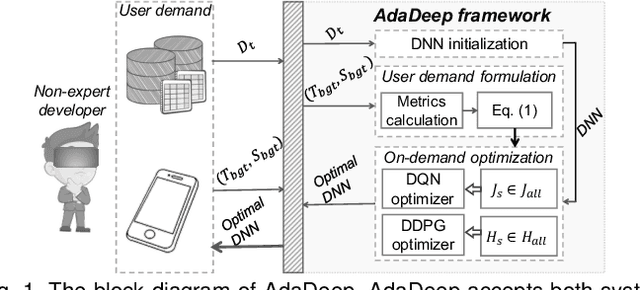
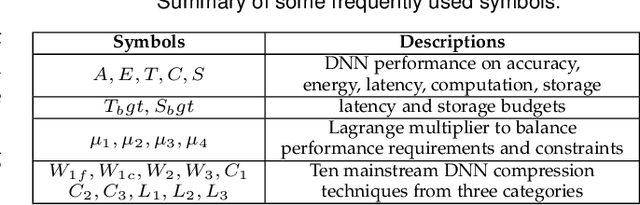
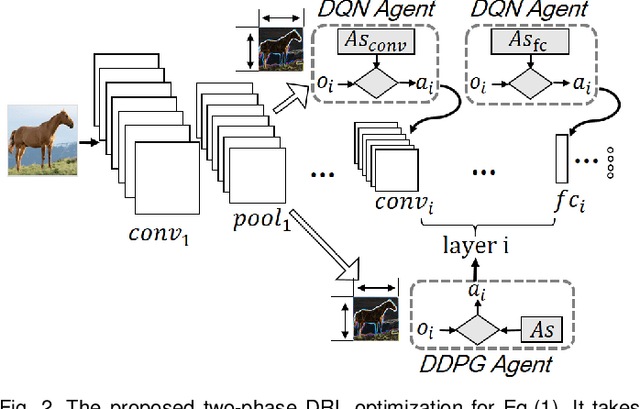

Recent breakthroughs in Deep Neural Networks (DNNs) have fueled a tremendously growing demand for bringing DNN-powered intelligence into mobile platforms. While the potential of deploying DNNs on resource-constrained platforms has been demonstrated by DNN compression techniques, the current practice suffers from two limitations: 1) merely stand-alone compression schemes are investigated even though each compression technique only suit for certain types of DNN layers; and 2) mostly compression techniques are optimized for DNNs' inference accuracy, without explicitly considering other application-driven system performance (e.g., latency and energy cost) and the varying resource availability across platforms (e.g., storage and processing capability). To this end, we propose AdaDeep, a usage-driven, automated DNN compression framework for systematically exploring the desired trade-off between performance and resource constraints, from a holistic system level. Specifically, in a layer-wise manner, AdaDeep automatically selects the most suitable combination of compression techniques and the corresponding compression hyperparameters for a given DNN. Thorough evaluations on six datasets and across twelve devices demonstrate that AdaDeep can achieve up to $18.6\times$ latency reduction, $9.8\times$ energy-efficiency improvement, and $37.3\times$ storage reduction in DNNs while incurring negligible accuracy loss. Furthermore, AdaDeep also uncovers multiple novel combinations of compression techniques.
SmartExchange: Trading Higher-cost Memory Storage/Access for Lower-cost Computation
May 08, 2020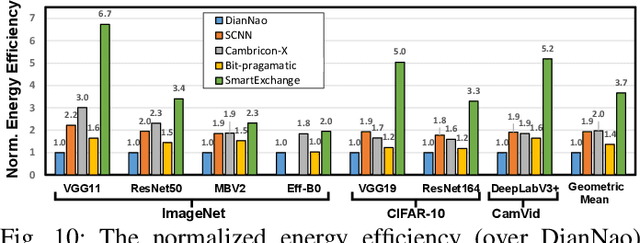
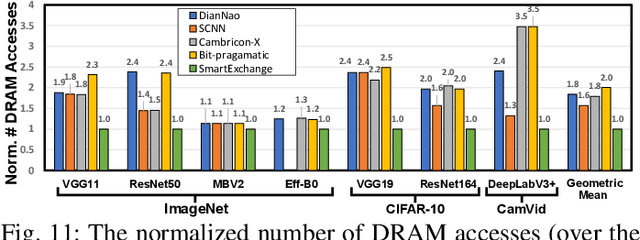
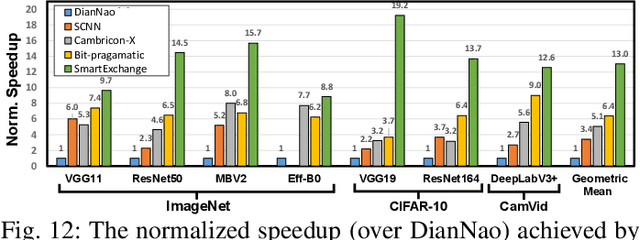
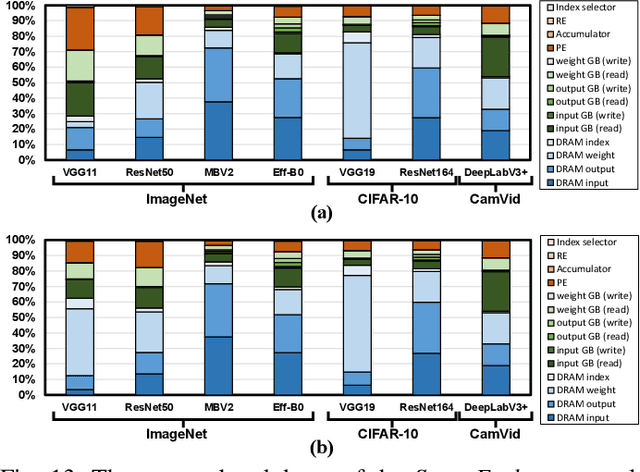
We present SmartExchange, an algorithm-hardware co-design framework to trade higher-cost memory storage/access for lower-cost computation, for energy-efficient inference of deep neural networks (DNNs). We develop a novel algorithm to enforce a specially favorable DNN weight structure, where each layerwise weight matrix can be stored as the product of a small basis matrix and a large sparse coefficient matrix whose non-zero elements are all power-of-2. To our best knowledge, this algorithm is the first formulation that integrates three mainstream model compression ideas: sparsification or pruning, decomposition, and quantization, into one unified framework. The resulting sparse and readily-quantized DNN thus enjoys greatly reduced energy consumption in data movement as well as weight storage. On top of that, we further design a dedicated accelerator to fully utilize the SmartExchange-enforced weights to improve both energy efficiency and latency performance. Extensive experiments show that 1) on the algorithm level, SmartExchange outperforms state-of-the-art compression techniques, including merely sparsification or pruning, decomposition, and quantization, in various ablation studies based on nine DNN models and four datasets; and 2) on the hardware level, the proposed SmartExchange based accelerator can improve the energy efficiency by up to 6.7$\times$ and the speedup by up to 19.2$\times$ over four state-of-the-art DNN accelerators, when benchmarked on seven DNN models (including four standard DNNs, two compact DNN models, and one segmentation model) and three datasets.
TIMELY: Pushing Data Movements and Interfaces in PIM Accelerators Towards Local and in Time Domain
May 03, 2020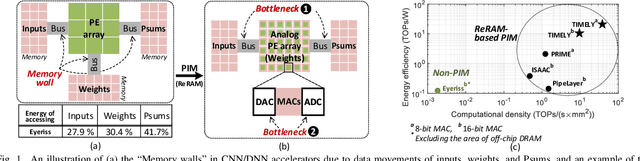
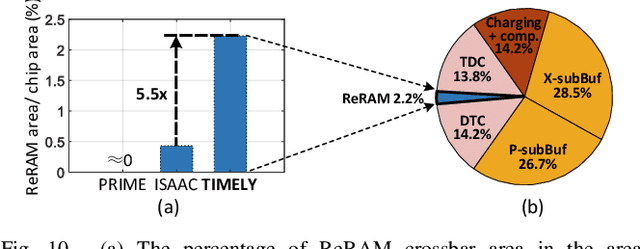
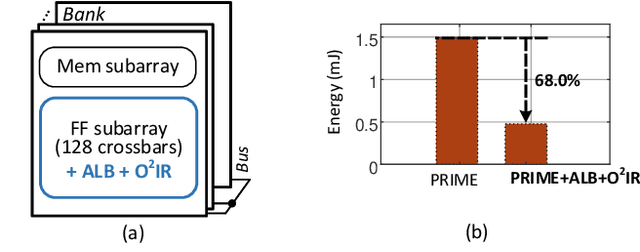
Resistive-random-access-memory (ReRAM) based processing-in-memory (R$^2$PIM) accelerators show promise in bridging the gap between Internet of Thing devices' constrained resources and Convolutional/Deep Neural Networks' (CNNs/DNNs') prohibitive energy cost. Specifically, R$^2$PIM accelerators enhance energy efficiency by eliminating the cost of weight movements and improving the computational density through ReRAM's high density. However, the energy efficiency is still limited by the dominant energy cost of input and partial sum (Psum) movements and the cost of digital-to-analog (D/A) and analog-to-digital (A/D) interfaces. In this work, we identify three energy-saving opportunities in R$^2$PIM accelerators: analog data locality, time-domain interfacing, and input access reduction, and propose an innovative R$^2$PIM accelerator called TIMELY, with three key contributions: (1) TIMELY adopts analog local buffers (ALBs) within ReRAM crossbars to greatly enhance the data locality, minimizing the energy overheads of both input and Psum movements; (2) TIMELY largely reduces the energy of each single D/A (and A/D) conversion and the total number of conversions by using time-domain interfaces (TDIs) and the employed ALBs, respectively; (3) we develop an only-once input read (O$^2$IR) mapping method to further decrease the energy of input accesses and the number of D/A conversions. The evaluation with more than 10 CNN/DNN models and various chip configurations shows that, TIMELY outperforms the baseline R$^2$PIM accelerator, PRIME, by one order of magnitude in energy efficiency while maintaining better computational density (up to 31.2$\times$) and throughput (up to 736.6$\times$). Furthermore, comprehensive studies are performed to evaluate the effectiveness of the proposed ALB, TDI, and O$^2$IR innovations in terms of energy savings and area reduction.
A New MRAM-based Process In-Memory Accelerator for Efficient Neural Network Training with Floating Point Precision
Mar 02, 2020
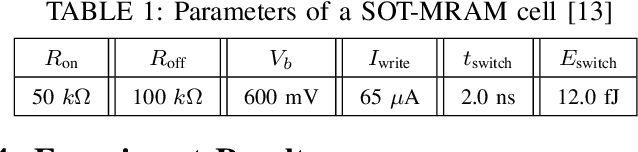
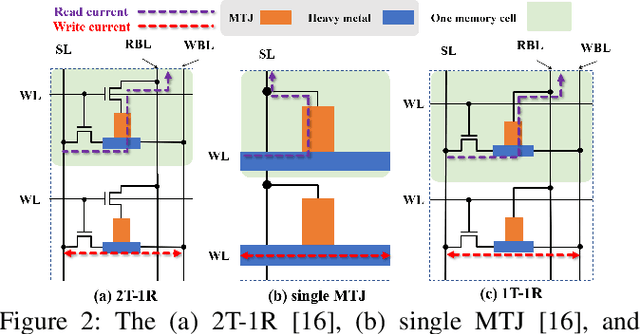
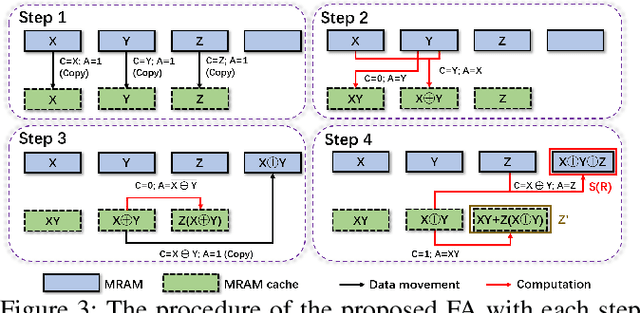
The excellent performance of modern deep neural networks (DNNs) comes at an often prohibitive training cost, limiting the rapid development of DNN innovations and raising various environmental concerns. To reduce the dominant data movement cost of training, process in-memory (PIM) has emerged as a promising solution as it alleviates the need to access DNN weights. However, state-of-the-art PIM DNN training accelerators employ either analog/mixed signal computing which has limited precision or digital computing based on a memory technology that supports limited logic functions and thus requires complicated procedure to realize floating point computation. In this paper, we propose a spin orbit torque magnetic random access memory (SOT-MRAM) based digital PIM accelerator that supports floating point precision. Specifically, this new accelerator features an innovative (1) SOT-MRAM cell, (2) full addition design, and (3) floating point computation. Experiment results show that the proposed SOT-MRAM PIM based DNN training accelerator can achieve 3.3x, 1.8x, and 2.5x improvement in terms of energy, latency, and area, respectively, compared with a state-of-the-art PIM based DNN training accelerator.
DNN-Chip Predictor: An Analytical Performance Predictor for DNN Accelerators with Various Dataflows and Hardware Architectures
Feb 26, 2020
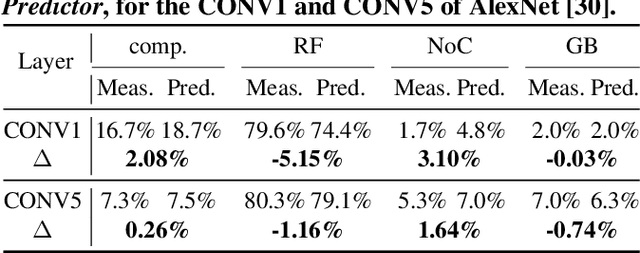
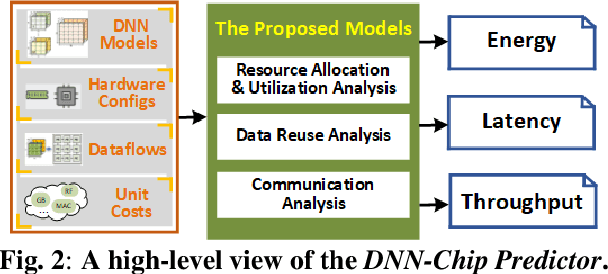
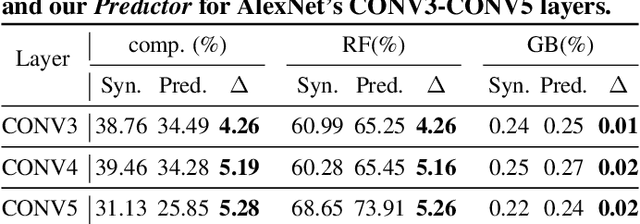
The recent breakthroughs in deep neural networks (DNNs) have spurred a tremendously increased demand for DNN accelerators. However, designing DNN accelerators is non-trivial as it often takes months/years and requires cross-disciplinary knowledge. To enable fast and effective DNN accelerator development, we propose DNN-Chip Predictor, an analytical performance predictor which can accurately predict DNN accelerators' energy, throughput, and latency prior to their actual implementation. Our Predictor features two highlights: (1) its analytical performance formulation of DNN ASIC/FPGA accelerators facilitates fast design space exploration and optimization; and (2) it supports DNN accelerators with different algorithm-to-hardware mapping methods (i.e., dataflows) and hardware architectures. Experiment results based on 2 DNN models and 3 different ASIC/FPGA implementations show that our DNN-Chip Predictor's predicted performance differs from those of chip measurements of FPGA/ASIC implementation by no more than 17.66% when using different DNN models, hardware architectures, and dataflows. We will release code upon acceptance.
AutoDNNchip: An Automated DNN Chip Predictor and Builder for Both FPGAs and ASICs
Jan 06, 2020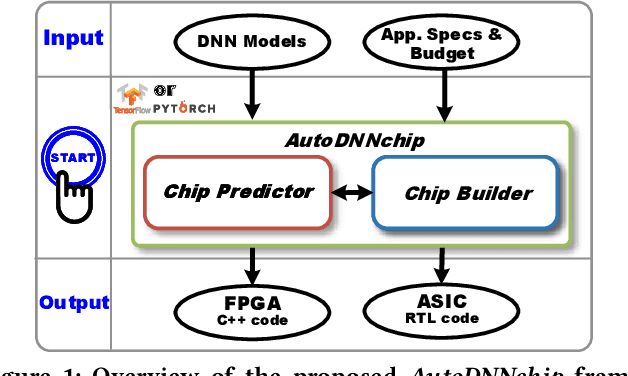
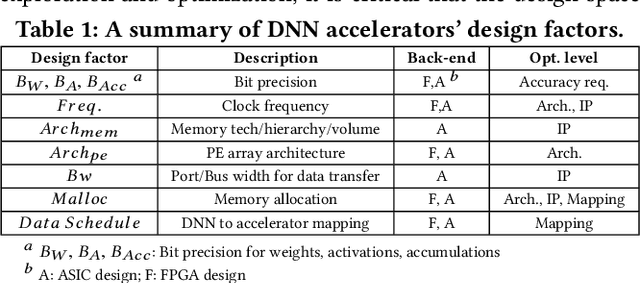
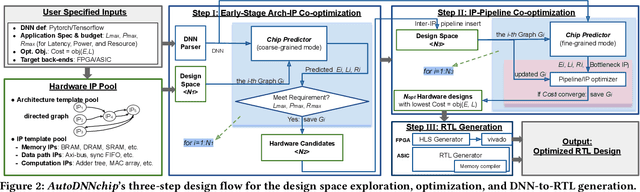

Recent breakthroughs in Deep Neural Networks (DNNs) have fueled a growing demand for DNN chips. However, designing DNN chips is non-trivial because: (1) mainstream DNNs have millions of parameters and operations; (2) the large design space due to the numerous design choices of dataflows, processing elements, memory hierarchy, etc.; and (3) an algorithm/hardware co-design is needed to allow the same DNN functionality to have a different decomposition, which would require different hardware IPs to meet the application specifications. Therefore, DNN chips take a long time to design and require cross-disciplinary experts. To enable fast and effective DNN chip design, we propose AutoDNNchip - a DNN chip generator that can automatically generate both FPGA- and ASIC-based DNN chip implementation given DNNs from machine learning frameworks (e.g., PyTorch) for a designated application and dataset. Specifically, AutoDNNchip consists of two integrated enablers: (1) a Chip Predictor, built on top of a graph-based accelerator representation, which can accurately and efficiently predict a DNN accelerator's energy, throughput, and area based on the DNN model parameters, hardware configuration, technology-based IPs, and platform constraints; and (2) a Chip Builder, which can automatically explore the design space of DNN chips (including IP selection, block configuration, resource balancing, etc.), optimize chip design via the Chip Predictor, and then generate optimized synthesizable RTL to achieve the target design metrics. Experimental results show that our Chip Predictor's predicted performance differs from real-measured ones by < 10% when validated using 15 DNN models and 4 platforms (edge-FPGA/TPU/GPU and ASIC). Furthermore, accelerators generated by our AutoDNNchip can achieve better (up to 3.86X improvement) performance than that of expert-crafted state-of-the-art accelerators.
Fractional Skipping: Towards Finer-Grained Dynamic CNN Inference
Jan 03, 2020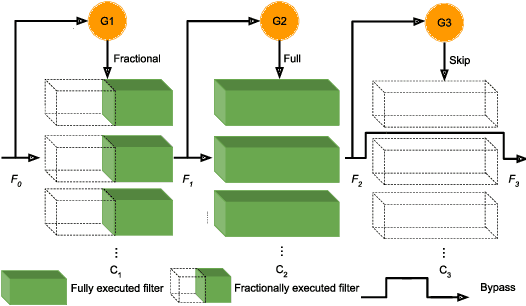

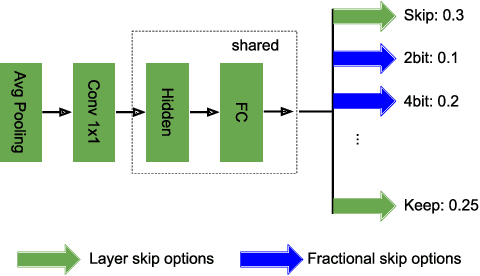
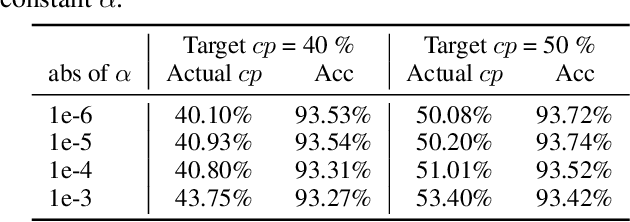
While increasingly deep networks are still in general desired for achieving state-of-the-art performance, for many specific inputs a simpler network might already suffice. Existing works exploited this observation by learning to skip convolutional layers in an input-dependent manner. However, we argue their binary decision scheme, i.e., either fully executing or completely bypassing one layer for a specific input, can be enhanced by introducing finer-grained, "softer" decisions. We therefore propose a Dynamic Fractional Skipping (DFS) framework. The core idea of DFS is to hypothesize layer-wise quantization (to different bitwidths) as intermediate "soft" choices to be made between fully utilizing and skipping a layer. For each input, DFS dynamically assigns a bitwidth to both weights and activations of each layer, where fully executing and skipping could be viewed as two "extremes" (i.e., full bitwidth and zero bitwidth). In this way, DFS can "fractionally" exploit a layer's expressive power during input-adaptive inference, enabling finer-grained accuracy-computational cost trade-offs. It presents a unified view to link input-adaptive layer skipping and input-adaptive hybrid quantization. Extensive experimental results demonstrate the superior tradeoff between computational cost and model expressive power (accuracy) achieved by DFS. More visualizations also indicate a smooth and consistent transition in the DFS behaviors, especially the learned choices between layer skipping and different quantizations when the total computational budgets vary, validating our hypothesis that layer quantization could be viewed as intermediate variants of layer skipping. Our source code and supplementary material are available at \link{https://github.com/Torment123/DFS}.
E2-Train: Training State-of-the-art CNNs with Over 80% Energy Savings
Dec 06, 2019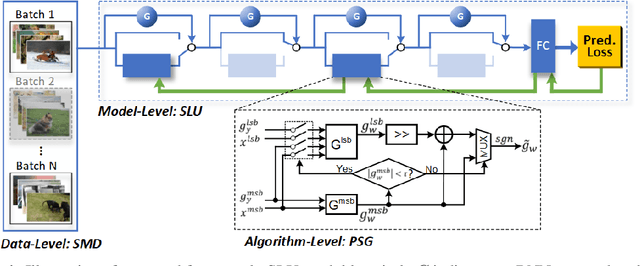

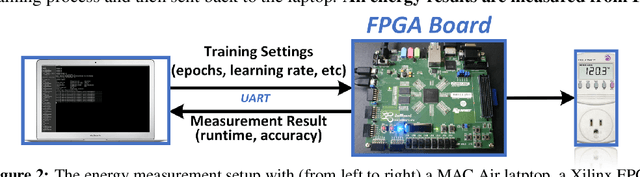

Convolutional neural networks (CNNs) have been increasingly deployed to edge devices. Hence, many efforts have been made towards efficient CNN inference in resource-constrained platforms. This paper attempts to explore an orthogonal direction: how to conduct more energy-efficient training of CNNs, so as to enable on-device training. We strive to reduce the energy cost during training, by dropping unnecessary computations from three complementary levels: stochastic mini-batch dropping on the data level; selective layer update on the model level; and sign prediction for low-cost, low-precision back-propagation, on the algorithm level. Extensive simulations and ablation studies, with real energy measurements from an FPGA board, confirm the superiority of our proposed strategies and demonstrate remarkable energy savings for training. For example, when training ResNet-74 on CIFAR-10, we achieve aggressive energy savings of >90% and >60%, while incurring a top-1 accuracy loss of only about 2% and 1.2%, respectively. When training ResNet-110 on CIFAR-100, an over 84% training energy saving is achieved without degrading inference accuracy.
Drawing early-bird tickets: Towards more efficient training of deep networks
Sep 26, 2019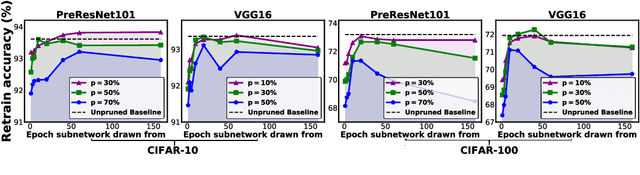
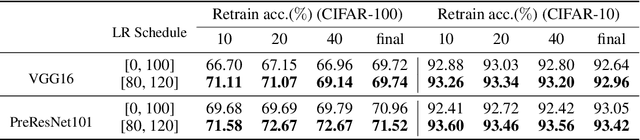
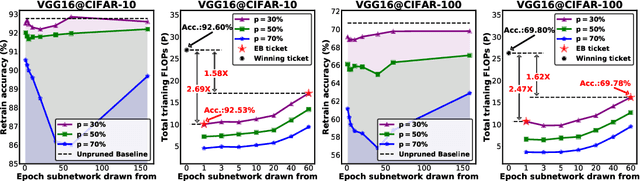
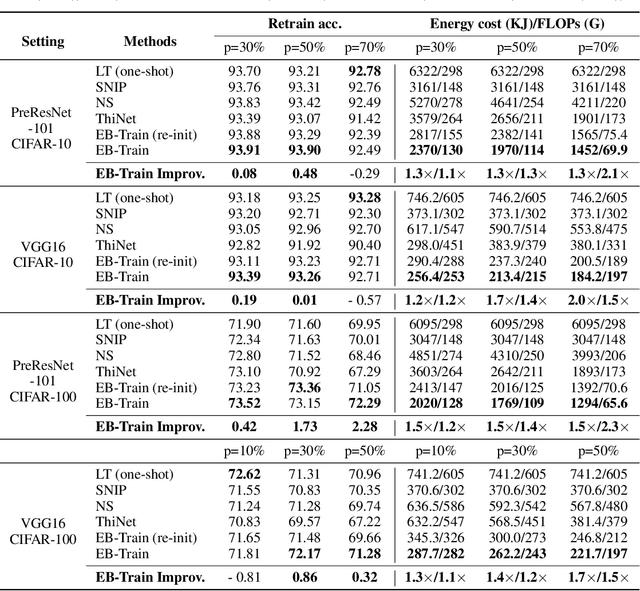
(Frankle & Carbin, 2019) shows that there exist winning tickets (small but critical subnetworks) for dense, randomly initialized networks, that can be trained alone to achieve comparable accuracies to the latter in a similar number of iterations. However, the identification of these winning tickets still requires the costly train-prune-retrain process, limiting their practical benefits. In this paper, we discover for the first time that the winning tickets can be identified at the very early training stage, which we term as early-bird (EB) tickets, via low-cost training schemes (e.g., early stopping and low-precision training) at large learning rates. Our finding of EB tickets is consistent with recently reported observations that the key connectivity patterns of neural networks emerge early. Furthermore, we propose a mask distance metric that can be used to identify EB tickets with low computational overhead, without needing to know the true winning tickets that emerge after the full training. Finally, we leverage the existence of EB tickets and the proposed mask distance to develop efficient training methods, which are achieved by first identifying EB tickets via low-cost schemes, and then continuing to train merely the EB tickets towards the target accuracy. Experiments based on various deep networks and datasets validate: 1) the existence of EB tickets, and the effectiveness of mask distance in efficiently identifying them; and 2) that the proposed efficient training via EB tickets can achieve up to 4.7x energy savings while maintaining comparable or even better accuracy, demonstrating a promising and easily adopted method for tackling cost-prohibitive deep network training.
Dual Dynamic Inference: Enabling More Efficient, Adaptive and Controllable Deep Inference
Jul 17, 2019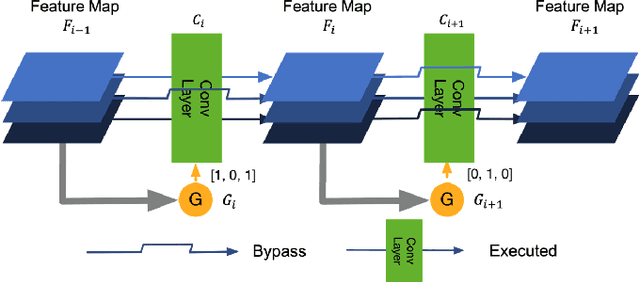
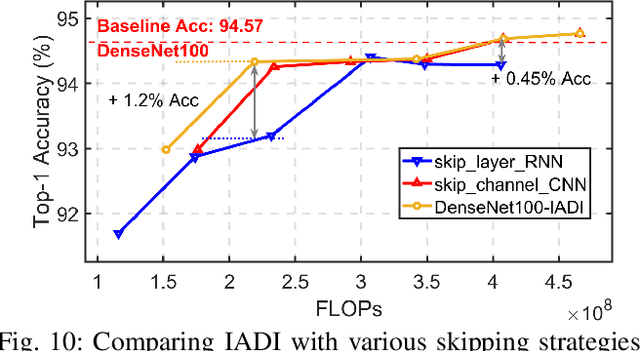
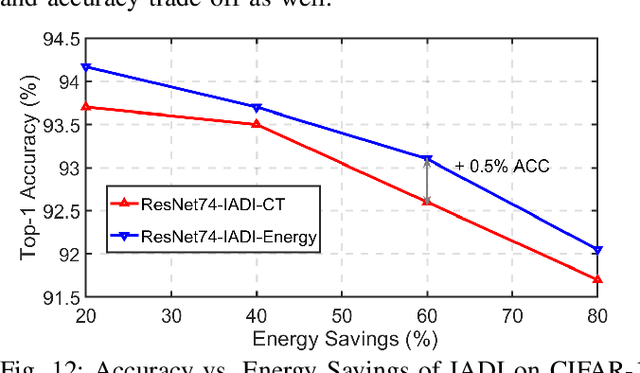
State-of-the-art convolutional neural networks (CNNs) yield record-breaking predictive performance, yet at the cost of high-energy-consumption inference, that prohibits their widely deployments in resource-constrained Internet of Things (IoT) applications. We propose a dual dynamic inference (DDI) framework that highlights the following aspects: 1) we integrate both input-dependent and resource-dependent dynamic inference mechanisms under a unified framework in order to fit the varying IoT resource requirements in practice. DDI is able to both constantly suppress unnecessary costs for easy samples, and to halt inference for all samples to meet hard resource constraints enforced; 2) we propose a flexible multi-grained learning to skip (MGL2S) approach for input-dependent inference which allows simultaneous layer-wise and channel-wise skipping; 3) we extend DDI to complex CNN backbones such as DenseNet and show that DDI can be applied towards optimizing any specific resource goals including inference latency or energy cost. Extensive experiments demonstrate the superior inference accuracy-resource trade-off achieved by DDI, as well as the flexibility to control such trade-offs compared to existing peer methods. Specifically, DDI can achieve up to 4 times computational savings with the same or even higher accuracy as compared to existing competitive baselines.