 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNormAUG: Normalization-guided Augmentation for Domain Generalization
Jul 25, 2023



Deep learning has made significant advancements in supervised learning. However, models trained in this setting often face challenges due to domain shift between training and test sets, resulting in a significant drop in performance during testing. To address this issue, several domain generalization methods have been developed to learn robust and domain-invariant features from multiple training domains that can generalize well to unseen test domains. Data augmentation plays a crucial role in achieving this goal by enhancing the diversity of the training data. In this paper, inspired by the observation that normalizing an image with different statistics generated by different batches with various domains can perturb its feature, we propose a simple yet effective method called NormAUG (Normalization-guided Augmentation). Our method includes two paths: the main path and the auxiliary (augmented) path. During training, the auxiliary path includes multiple sub-paths, each corresponding to batch normalization for a single domain or a random combination of multiple domains. This introduces diverse information at the feature level and improves the generalization of the main path. Moreover, our NormAUG method effectively reduces the existing upper boundary for generalization based on theoretical perspectives. During the test stage, we leverage an ensemble strategy to combine the predictions from the auxiliary path of our model, further boosting performance. Extensive experiments are conducted on multiple benchmark datasets to validate the effectiveness of our proposed method.
Generalizable Metric Network for Cross-domain Person Re-identification
Jun 21, 2023



Person Re-identification (Re-ID) is a crucial technique for public security and has made significant progress in supervised settings. However, the cross-domain (i.e., domain generalization) scene presents a challenge in Re-ID tasks due to unseen test domains and domain-shift between the training and test sets. To tackle this challenge, most existing methods aim to learn domain-invariant or robust features for all domains. In this paper, we observe that the data-distribution gap between the training and test sets is smaller in the sample-pair space than in the sample-instance space. Based on this observation, we propose a Generalizable Metric Network (GMN) to further explore sample similarity in the sample-pair space. Specifically, we add a Metric Network (M-Net) after the main network and train it on positive and negative sample-pair features, which is then employed during the test stage. Additionally, we introduce the Dropout-based Perturbation (DP) module to enhance the generalization capability of the metric network by enriching the sample-pair diversity. Moreover, we develop a Pair-Identity Center (PIC) loss to enhance the model's discrimination by ensuring that sample-pair features with the same pair-identity are consistent. We validate the effectiveness of our proposed method through a lot of experiments on multiple benchmark datasets and confirm the value of each module in our GMN.
Patch-aware Batch Normalization for Improving Cross-domain Robustness
Apr 06, 2023
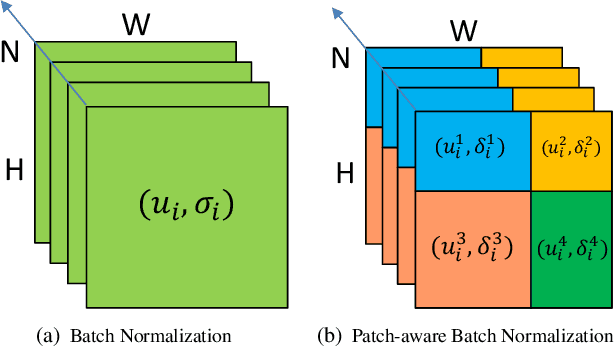
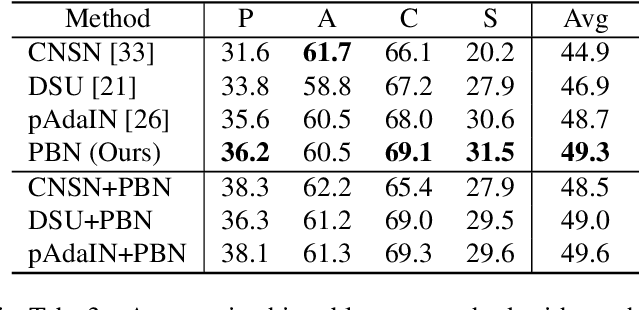
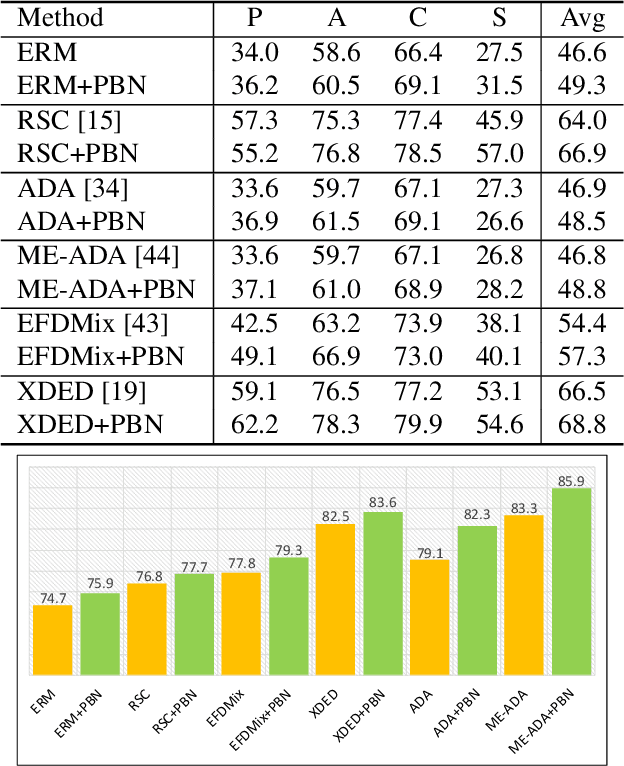
Despite the significant success of deep learning in computer vision tasks, cross-domain tasks still present a challenge in which the model's performance will degrade when the training set and the test set follow different distributions. Most existing methods employ adversarial learning or instance normalization for achieving data augmentation to solve this task. In contrast, considering that the batch normalization (BN) layer may not be robust for unseen domains and there exist the differences between local patches of an image, we propose a novel method called patch-aware batch normalization (PBN). To be specific, we first split feature maps of a batch into non-overlapping patches along the spatial dimension, and then independently normalize each patch to jointly optimize the shared BN parameter at each iteration. By exploiting the differences between local patches of an image, our proposed PBN can effectively enhance the robustness of the model's parameters. Besides, considering the statistics from each patch may be inaccurate due to their smaller size compared to the global feature maps, we incorporate the globally accumulated statistics with the statistics from each batch to obtain the final statistics for normalizing each patch. Since the proposed PBN can replace the typical BN, it can be integrated into most existing state-of-the-art methods. Extensive experiments and analysis demonstrate the effectiveness of our PBN in multiple computer vision tasks, including classification, object detection, instance retrieval, and semantic segmentation.
ALOFT: A Lightweight MLP-like Architecture with Dynamic Low-frequency Transform for Domain Generalization
Mar 31, 2023



Domain generalization (DG) aims to learn a model that generalizes well to unseen target domains utilizing multiple source domains without re-training. Most existing DG works are based on convolutional neural networks (CNNs). However, the local operation of the convolution kernel makes the model focus too much on local representations (e.g., texture), which inherently causes the model more prone to overfit to the source domains and hampers its generalization ability. Recently, several MLP-based methods have achieved promising results in supervised learning tasks by learning global interactions among different patches of the image. Inspired by this, in this paper, we first analyze the difference between CNN and MLP methods in DG and find that MLP methods exhibit a better generalization ability because they can better capture the global representations (e.g., structure) than CNN methods. Then, based on a recent lightweight MLP method, we obtain a strong baseline that outperforms most state-of-the-art CNN-based methods. The baseline can learn global structure representations with a filter to suppress structure irrelevant information in the frequency space. Moreover, we propose a dynAmic LOw-Frequency spectrum Transform (ALOFT) that can perturb local texture features while preserving global structure features, thus enabling the filter to remove structure-irrelevant information sufficiently. Extensive experiments on four benchmarks have demonstrated that our method can achieve great performance improvement with a small number of parameters compared to SOTA CNN-based DG methods. Our code is available at https://github.com/lingeringlight/ALOFT/.
Orthogonal Annotation Benefits Barely-supervised Medical Image Segmentation
Mar 23, 2023



Recent trends in semi-supervised learning have significantly boosted the performance of 3D semi-supervised medical image segmentation. Compared with 2D images, 3D medical volumes involve information from different directions, e.g., transverse, sagittal, and coronal planes, so as to naturally provide complementary views. These complementary views and the intrinsic similarity among adjacent 3D slices inspire us to develop a novel annotation way and its corresponding semi-supervised model for effective segmentation. Specifically, we firstly propose the orthogonal annotation by only labeling two orthogonal slices in a labeled volume, which significantly relieves the burden of annotation. Then, we perform registration to obtain the initial pseudo labels for sparsely labeled volumes. Subsequently, by introducing unlabeled volumes, we propose a dual-network paradigm named Dense-Sparse Co-training (DeSCO) that exploits dense pseudo labels in early stage and sparse labels in later stage and meanwhile forces consistent output of two networks. Experimental results on three benchmark datasets validated our effectiveness in performance and efficiency in annotation. For example, with only 10 annotated slices, our method reaches a Dice up to 86.93% on KiTS19 dataset.
Revisiting Weak-to-Strong Consistency in Semi-Supervised Semantic Segmentation
Aug 21, 2022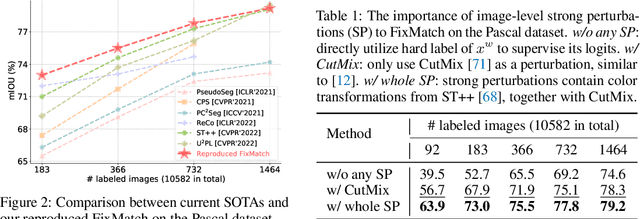
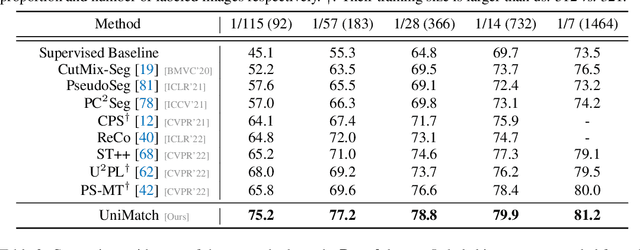

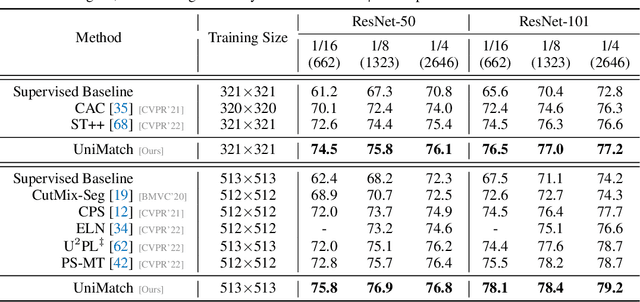
In this work, we revisit the weak-to-strong consistency framework, popularized by FixMatch from semi-supervised classification, where the prediction of a weakly perturbed image serves as supervision for its strongly perturbed version. Intriguingly, we observe that such a simple pipeline already achieves competitive results against recent advanced works, when transferred to our segmentation scenario. Its success heavily relies on the manual design of strong data augmentations, however, which may be limited and inadequate to explore a broader perturbation space. Motivated by this, we propose an auxiliary feature perturbation stream as a supplement, leading to an expanded perturbation space. On the other, to sufficiently probe original image-level augmentations, we present a dual-stream perturbation technique, enabling two strong views to be simultaneously guided by a common weak view. Consequently, our overall Unified Dual-Stream Perturbations approach (UniMatch) surpasses all existing methods significantly across all evaluation protocols on the Pascal, Cityscapes, and COCO benchmarks. We also demonstrate the superiority of our method in remote sensing interpretation and medical image analysis. Code is available at https://github.com/LiheYoung/UniMatch.
RDA: Reciprocal Distribution Alignment for Robust Semi-supervised Learning
Aug 12, 2022
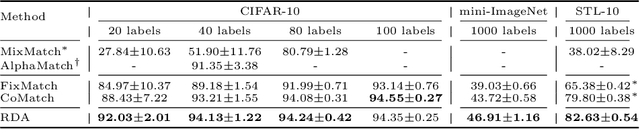
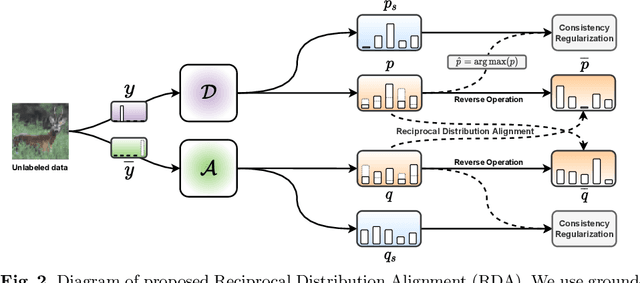
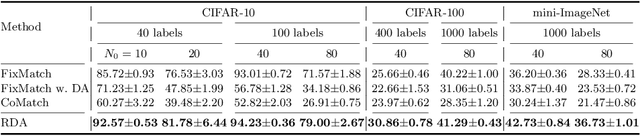
In this work, we propose Reciprocal Distribution Alignment (RDA) to address semi-supervised learning (SSL), which is a hyperparameter-free framework that is independent of confidence threshold and works with both the matched (conventionally) and the mismatched class distributions. Distribution mismatch is an often overlooked but more general SSL scenario where the labeled and the unlabeled data do not fall into the identical class distribution. This may lead to the model not exploiting the labeled data reliably and drastically degrade the performance of SSL methods, which could not be rescued by the traditional distribution alignment. In RDA, we enforce a reciprocal alignment on the distributions of the predictions from two classifiers predicting pseudo-labels and complementary labels on the unlabeled data. These two distributions, carrying complementary information, could be utilized to regularize each other without any prior of class distribution. Moreover, we theoretically show that RDA maximizes the input-output mutual information. Our approach achieves promising performance in SSL under a variety of scenarios of mismatched distributions, as well as the conventional matched SSL setting. Our code is available at: https://github.com/NJUyued/RDA4RobustSSL.
MultiMatch: Multi-task Learning for Semi-supervised Domain Generalization
Aug 11, 2022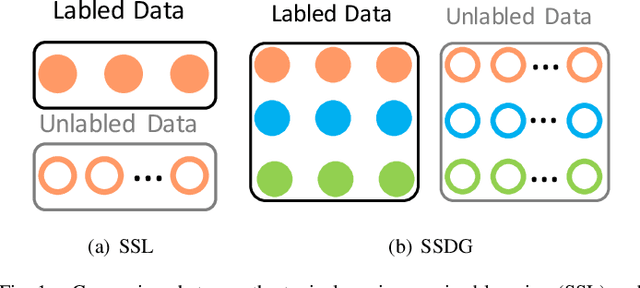
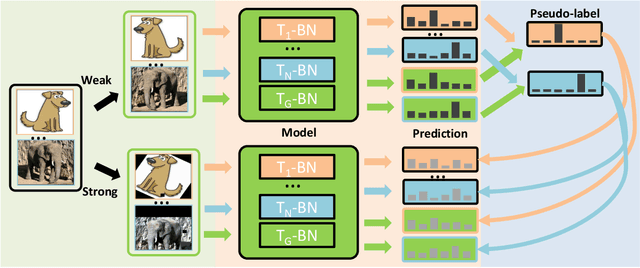
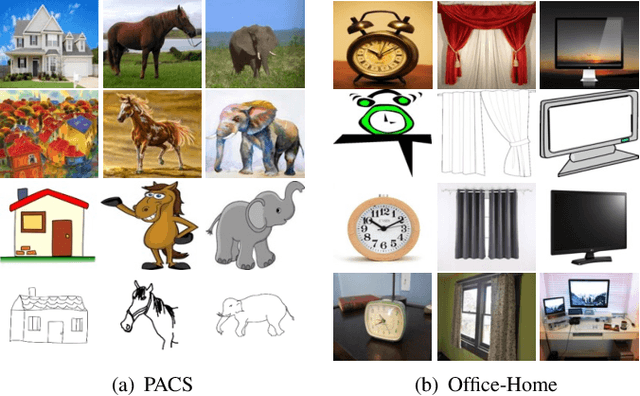
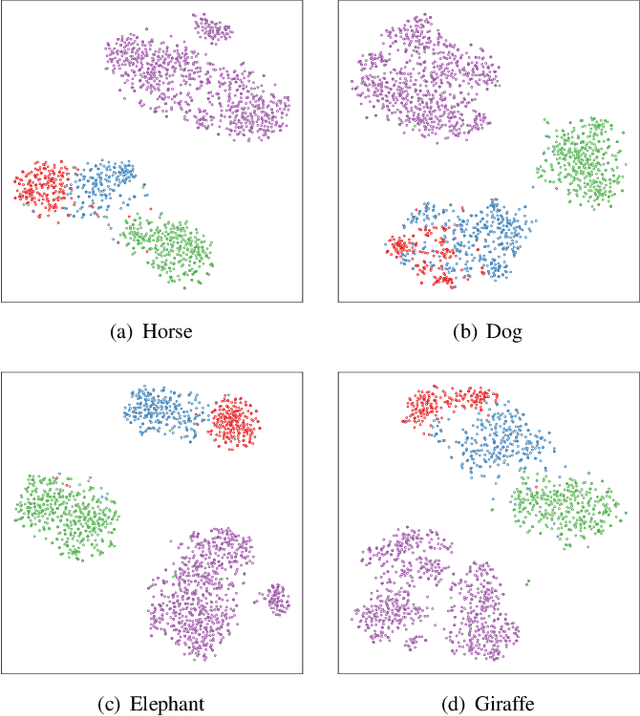
Domain generalization (DG) aims at learning a model on source domains to well generalize on the unseen target domain. Although it has achieved great success, most of existing methods require the label information for all training samples in source domains, which is time-consuming and expensive in the real-world application. In this paper, we resort to solving the semi-supervised domain generalization (SSDG) task, where there are a few label information in each source domain. To address the task, we first analyze the theory of the multi-domain learning, which highlights that 1) mitigating the impact of domain gap and 2) exploiting all samples to train the model can effectively reduce the generalization error in each source domain so as to improve the quality of pseudo-labels. According to the analysis, we propose MultiMatch, i.e., extending FixMatch to the multi-task learning framework, producing the high-quality pseudo-label for SSDG. To be specific, we consider each training domain as a single task (i.e., local task) and combine all training domains together (i.e., global task) to train an extra task for the unseen test domain. In the multi-task framework, we utilize the independent BN and classifier for each task, which can effectively alleviate the interference from different domains during pseudo-labeling. Also, most of parameters in the framework are shared, which can be trained by all training samples sufficiently. Moreover, to further boost the pseudo-label accuracy and the model's generalization, we fuse the predictions from the global task and local task during training and testing, respectively. A series of experiments validate the effectiveness of the proposed method, and it outperforms the existing semi-supervised methods and the SSDG method on several benchmark DG datasets.
Generalizable Medical Image Segmentation via Random Amplitude Mixup and Domain-Specific Image Restoration
Aug 08, 2022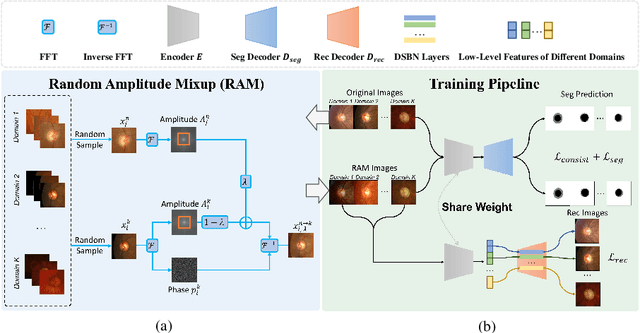
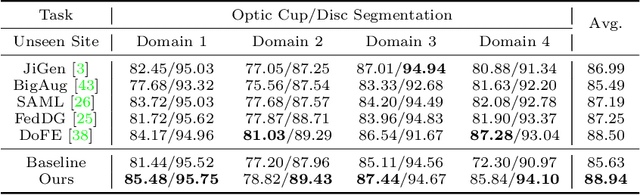
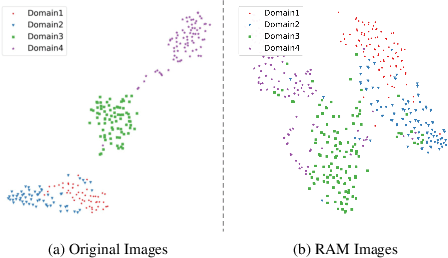
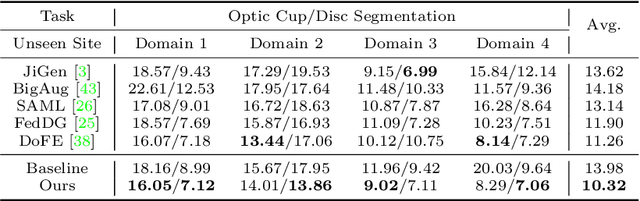
For medical image analysis, segmentation models trained on one or several domains lack generalization ability to unseen domains due to discrepancies between different data acquisition policies. We argue that the degeneration in segmentation performance is mainly attributed to overfitting to source domains and domain shift. To this end, we present a novel generalizable medical image segmentation method. To be specific, we design our approach as a multi-task paradigm by combining the segmentation model with a self-supervision domain-specific image restoration (DSIR) module for model regularization. We also design a random amplitude mixup (RAM) module, which incorporates low-level frequency information of different domain images to synthesize new images. To guide our model be resistant to domain shift, we introduce a semantic consistency loss. We demonstrate the performance of our method on two public generalizable segmentation benchmarks in medical images, which validates our method could achieve the state-of-the-art performance.
Label Distribution Learning for Generalizable Multi-source Person Re-identification
Apr 12, 2022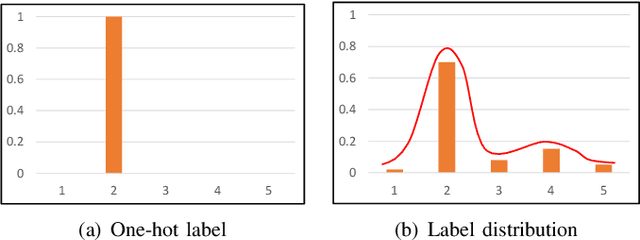
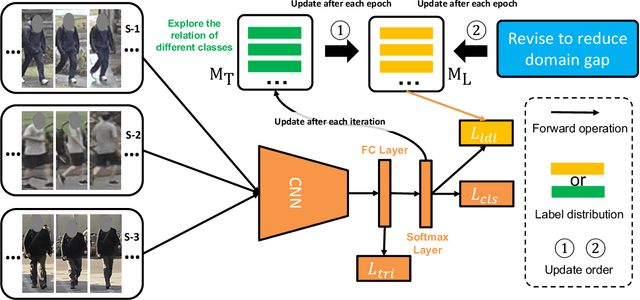
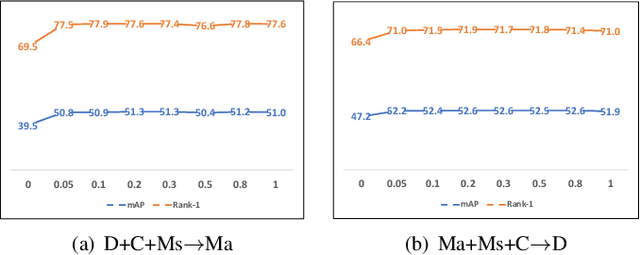
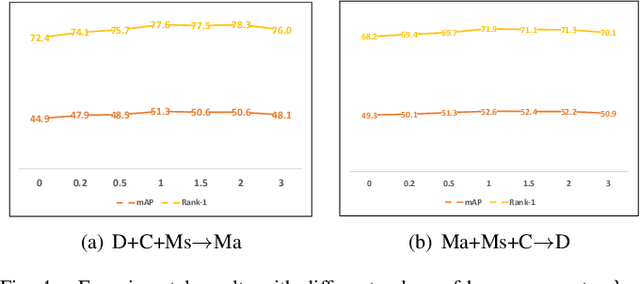
Person re-identification (Re-ID) is a critical technique in the video surveillance system, which has achieved significant success in the supervised setting. However, it is difficult to directly apply the supervised model to arbitrary unseen domains due to the domain gap between the available source domains and unseen target domains. In this paper, we propose a novel label distribution learning (LDL) method to address the generalizable multi-source person Re-ID task (i.e., there are multiple available source domains, and the testing domain is unseen during training), which aims to explore the relation of different classes and mitigate the domain-shift across different domains so as to improve the discrimination of the model and learn the domain-invariant feature, simultaneously. Specifically, during the training process, we produce the label distribution via the online manner to mine the relation information of different classes, thus it is beneficial for extracting the discriminative feature. Besides, for the label distribution of each class, we further revise it to give more and equal attention to the other domains that the class does not belong to, which can effectively reduce the domain gap across different domains and obtain the domain-invariant feature. Furthermore, we also give the theoretical analysis to demonstrate that the proposed method can effectively deal with the domain-shift issue. Extensive experiments on multiple benchmark datasets validate the effectiveness of the proposed method and show that the proposed method can outperform the state-of-the-art methods. Besides, further analysis also reveals the superiority of the proposed method.