 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNormAUG: Normalization-guided Augmentation for Domain Generalization
Jul 25, 2023



Deep learning has made significant advancements in supervised learning. However, models trained in this setting often face challenges due to domain shift between training and test sets, resulting in a significant drop in performance during testing. To address this issue, several domain generalization methods have been developed to learn robust and domain-invariant features from multiple training domains that can generalize well to unseen test domains. Data augmentation plays a crucial role in achieving this goal by enhancing the diversity of the training data. In this paper, inspired by the observation that normalizing an image with different statistics generated by different batches with various domains can perturb its feature, we propose a simple yet effective method called NormAUG (Normalization-guided Augmentation). Our method includes two paths: the main path and the auxiliary (augmented) path. During training, the auxiliary path includes multiple sub-paths, each corresponding to batch normalization for a single domain or a random combination of multiple domains. This introduces diverse information at the feature level and improves the generalization of the main path. Moreover, our NormAUG method effectively reduces the existing upper boundary for generalization based on theoretical perspectives. During the test stage, we leverage an ensemble strategy to combine the predictions from the auxiliary path of our model, further boosting performance. Extensive experiments are conducted on multiple benchmark datasets to validate the effectiveness of our proposed method.
MultiMatch: Multi-task Learning for Semi-supervised Domain Generalization
Aug 11, 2022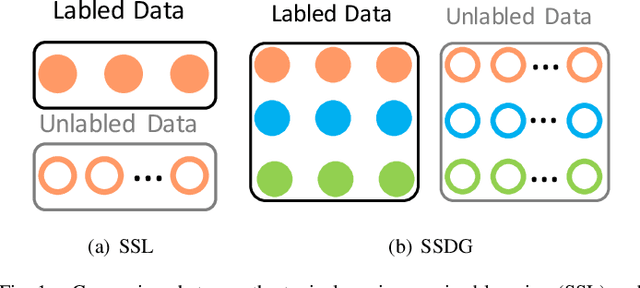
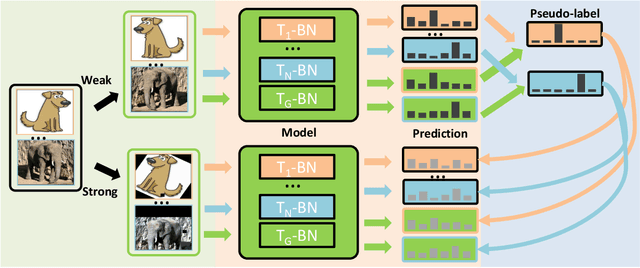
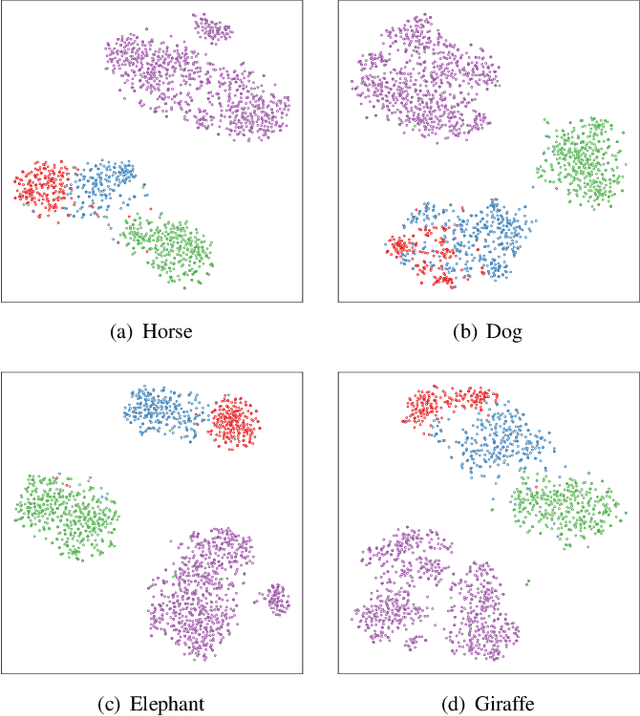
Domain generalization (DG) aims at learning a model on source domains to well generalize on the unseen target domain. Although it has achieved great success, most of existing methods require the label information for all training samples in source domains, which is time-consuming and expensive in the real-world application. In this paper, we resort to solving the semi-supervised domain generalization (SSDG) task, where there are a few label information in each source domain. To address the task, we first analyze the theory of the multi-domain learning, which highlights that 1) mitigating the impact of domain gap and 2) exploiting all samples to train the model can effectively reduce the generalization error in each source domain so as to improve the quality of pseudo-labels. According to the analysis, we propose MultiMatch, i.e., extending FixMatch to the multi-task learning framework, producing the high-quality pseudo-label for SSDG. To be specific, we consider each training domain as a single task (i.e., local task) and combine all training domains together (i.e., global task) to train an extra task for the unseen test domain. In the multi-task framework, we utilize the independent BN and classifier for each task, which can effectively alleviate the interference from different domains during pseudo-labeling. Also, most of parameters in the framework are shared, which can be trained by all training samples sufficiently. Moreover, to further boost the pseudo-label accuracy and the model's generalization, we fuse the predictions from the global task and local task during training and testing, respectively. A series of experiments validate the effectiveness of the proposed method, and it outperforms the existing semi-supervised methods and the SSDG method on several benchmark DG datasets.