 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpected Return Causes Outcome-Level Mode Collapse in Reinforcement Learning and How to Fix It with Inverse Probability Scaling
Jan 29, 2026Many reinforcement learning (RL) problems admit multiple terminal solutions of comparable quality, where the goal is not to identify a single optimum but to represent a diverse set of high-quality outcomes. Nevertheless, policies trained by standard expected return maximization routinely collapse onto a small subset of outcomes, a phenomenon commonly attributed to insufficient exploration or weak regularization. We show that this explanation is incomplete: outcome level mode collapse is a structural consequence of the expected-return objective itself. Under idealized learning dynamics, the log-probability ratio between any two outcomes evolves linearly in their reward difference, implying exponential ratio divergence and inevitable collapse independent of the exploration strategy, entropy regularization, or optimization algorithm. We identify the source of this pathology as the probability multiplier inside the expectation and propose a minimal correction: inverse probability scaling, which removes outcome-frequency amplification from the learning signal, fundamentally changes the learning dynamics, and provably yields reward-proportional terminal distributions, preventing collapse in multimodal settings. We instantiate this principle in Group Relative Policy Optimization (GRPO) as a drop-in modification, IPS-GRPO, requiring no auxiliary models or architectural changes. Across different reasoning and molecular generation tasks, IPS-GRPO consistently reduces outcome-level mode collapse while matching or exceeding baseline performance, suggesting that correcting the objective rather than adding exploration heuristics is key to reliable multimodal policy optimization.
How does My Model Fail? Automatic Identification and Interpretation of Physical Plausibility Failure Modes with Matryoshka Transcoders
Nov 18, 2025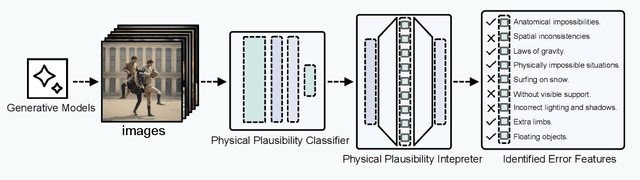
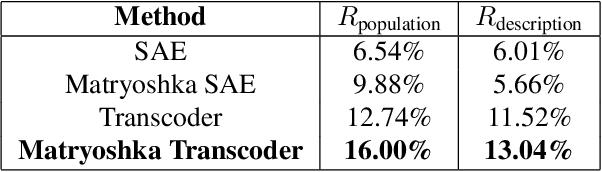
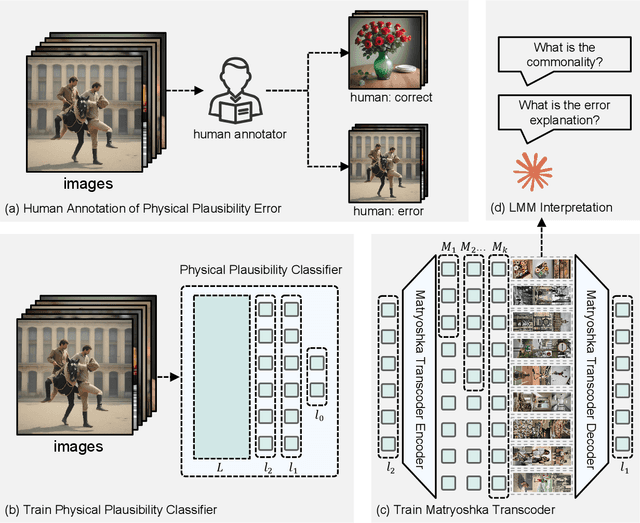
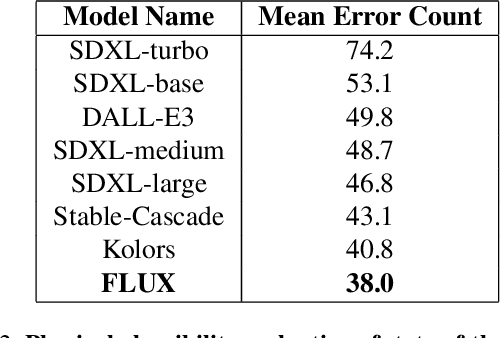
Although recent generative models are remarkably capable of producing instruction-following and realistic outputs, they remain prone to notable physical plausibility failures. Though critical in applications, these physical plausibility errors often escape detection by existing evaluation methods. Furthermore, no framework exists for automatically identifying and interpreting specific physical error patterns in natural language, preventing targeted model improvements. We introduce Matryoshka Transcoders, a novel framework for the automatic discovery and interpretation of physical plausibility features in generative models. Our approach extends the Matryoshka representation learning paradigm to transcoder architectures, enabling hierarchical sparse feature learning at multiple granularity levels. By training on intermediate representations from a physical plausibility classifier and leveraging large multimodal models for interpretation, our method identifies diverse physics-related failure modes without manual feature engineering, achieving superior feature relevance and feature accuracy compared to existing approaches. We utilize the discovered visual patterns to establish a benchmark for evaluating physical plausibility in generative models. Our analysis of eight state-of-the-art generative models provides valuable insights into how these models fail to follow physical constraints, paving the way for further model improvements.