 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMuBench: Assessment of Multilingual Capabilities of Large Language Models Across 61 Languages
Jun 24, 2025Multilingual large language models (LLMs) are advancing rapidly, with new models frequently claiming support for an increasing number of languages. However, existing evaluation datasets are limited and lack cross-lingual alignment, leaving assessments of multilingual capabilities fragmented in both language and skill coverage. To address this, we introduce MuBench, a benchmark covering 61 languages and evaluating a broad range of capabilities. We evaluate several state-of-the-art multilingual LLMs and find notable gaps between claimed and actual language coverage, particularly a persistent performance disparity between English and low-resource languages. Leveraging MuBench's alignment, we propose Multilingual Consistency (MLC) as a complementary metric to accuracy for analyzing performance bottlenecks and guiding model improvement. Finally, we pretrain a suite of 1.2B-parameter models on English and Chinese with 500B tokens, varying language ratios and parallel data proportions to investigate cross-lingual transfer dynamics.
Synergizing Reinforcement Learning and Genetic Algorithms for Neural Combinatorial Optimization
Jun 11, 2025



Combinatorial optimization problems are notoriously challenging due to their discrete structure and exponentially large solution space. Recent advances in deep reinforcement learning (DRL) have enabled the learning heuristics directly from data. However, DRL methods often suffer from limited exploration and susceptibility to local optima. On the other hand, evolutionary algorithms such as Genetic Algorithms (GAs) exhibit strong global exploration capabilities but are typically sample inefficient and computationally intensive. In this work, we propose the Evolutionary Augmentation Mechanism (EAM), a general and plug-and-play framework that synergizes the learning efficiency of DRL with the global search power of GAs. EAM operates by generating solutions from a learned policy and refining them through domain-specific genetic operations such as crossover and mutation. These evolved solutions are then selectively reinjected into the policy training loop, thereby enhancing exploration and accelerating convergence. We further provide a theoretical analysis that establishes an upper bound on the KL divergence between the evolved solution distribution and the policy distribution, ensuring stable and effective policy updates. EAM is model-agnostic and can be seamlessly integrated with state-of-the-art DRL solvers such as the Attention Model, POMO, and SymNCO. Extensive results on benchmark problems (e.g., TSP, CVRP, PCTSP, and OP) demonstrate that EAM significantly improves both solution quality and training efficiency over competitive baselines.
STRAP: Spatio-Temporal Pattern Retrieval for Out-of-Distribution Generalization
May 26, 2025Spatio-Temporal Graph Neural Networks (STGNNs) have emerged as a powerful tool for modeling dynamic graph-structured data across diverse domains. However, they often fail to generalize in Spatio-Temporal Out-of-Distribution (STOOD) scenarios, where both temporal dynamics and spatial structures evolve beyond the training distribution. To address this problem, we propose an innovative Spatio-Temporal Retrieval-Augmented Pattern Learning framework,STRAP, which enhances model generalization by integrating retrieval-augmented learning into the STGNN continue learning pipeline. The core of STRAP is a compact and expressive pattern library that stores representative spatio-temporal patterns enriched with historical, structural, and semantic information, which is obtained and optimized during the training phase. During inference, STRAP retrieves relevant patterns from this library based on similarity to the current input and injects them into the model via a plug-and-play prompting mechanism. This not only strengthens spatio-temporal representations but also mitigates catastrophic forgetting. Moreover, STRAP introduces a knowledge-balancing objective to harmonize new information with retrieved knowledge. Extensive experiments across multiple real-world streaming graph datasets show that STRAP consistently outperforms state-of-the-art STGNN baselines on STOOD tasks, demonstrating its robustness, adaptability, and strong generalization capability without task-specific fine-tuning.
Reflectance Prediction-based Knowledge Distillation for Robust 3D Object Detection in Compressed Point Clouds
May 23, 2025Regarding intelligent transportation systems for vehicle networking, low-bitrate transmission via lossy point cloud compression is vital for facilitating real-time collaborative perception among vehicles with restricted bandwidth. In existing compression transmission systems, the sender lossily compresses point coordinates and reflectance to generate a transmission code stream, which faces transmission burdens from reflectance encoding and limited detection robustness due to information loss. To address these issues, this paper proposes a 3D object detection framework with reflectance prediction-based knowledge distillation (RPKD). We compress point coordinates while discarding reflectance during low-bitrate transmission, and feed the decoded non-reflectance compressed point clouds into a student detector. The discarded reflectance is then reconstructed by a geometry-based reflectance prediction (RP) module within the student detector for precise detection. A teacher detector with the same structure as student detector is designed for performing reflectance knowledge distillation (RKD) and detection knowledge distillation (DKD) from raw to compressed point clouds. Our RPKD framework jointly trains detectors on both raw and compressed point clouds to improve the student detector's robustness. Experimental results on the KITTI dataset and Waymo Open Dataset demonstrate that our method can boost detection accuracy for compressed point clouds across multiple code rates. Notably, at a low code rate of 2.146 Bpp on the KITTI dataset, our RPKD-PV achieves the highest mAP of 73.6, outperforming existing detection methods with the PV-RCNN baseline.
On the Design of KL-Regularized Policy Gradient Algorithms for LLM Reasoning
May 23, 2025Policy gradient algorithms have been successfully applied to enhance the reasoning capabilities of large language models (LLMs). Despite the widespread use of Kullback-Leibler (KL) regularization in policy gradient algorithms to stabilize training, the systematic exploration of how different KL divergence formulations can be estimated and integrated into surrogate loss functions for online reinforcement learning (RL) presents a nuanced and systematically explorable design space. In this paper, we propose regularized policy gradient (RPG), a systematic framework for deriving and analyzing KL-regularized policy gradient methods in the online RL setting. We derive policy gradients and corresponding surrogate loss functions for objectives regularized by both forward and reverse KL divergences, considering both normalized and unnormalized policy distributions. Furthermore, we present derivations for fully differentiable loss functions as well as REINFORCE-style gradient estimators, accommodating diverse algorithmic needs. We conduct extensive experiments on RL for LLM reasoning using these methods, showing improved or competitive results in terms of training stability and performance compared to strong baselines such as GRPO, REINFORCE++, and DAPO. The code is available at https://github.com/complex-reasoning/RPG.
MemeReaCon: Probing Contextual Meme Understanding in Large Vision-Language Models
May 23, 2025Memes have emerged as a popular form of multimodal online communication, where their interpretation heavily depends on the specific context in which they appear. Current approaches predominantly focus on isolated meme analysis, either for harmful content detection or standalone interpretation, overlooking a fundamental challenge: the same meme can express different intents depending on its conversational context. This oversight creates an evaluation gap: although humans intuitively recognize how context shapes meme interpretation, Large Vision Language Models (LVLMs) can hardly understand context-dependent meme intent. To address this critical limitation, we introduce MemeReaCon, a novel benchmark specifically designed to evaluate how LVLMs understand memes in their original context. We collected memes from five different Reddit communities, keeping each meme's image, the post text, and user comments together. We carefully labeled how the text and meme work together, what the poster intended, how the meme is structured, and how the community responded. Our tests with leading LVLMs show a clear weakness: models either fail to interpret critical information in the contexts, or overly focus on visual details while overlooking communicative purpose. MemeReaCon thus serves both as a diagnostic tool exposing current limitations and as a challenging benchmark to drive development toward more sophisticated LVLMs of the context-aware understanding.
ELABORATION: A Comprehensive Benchmark on Human-LLM Competitive Programming
May 22, 2025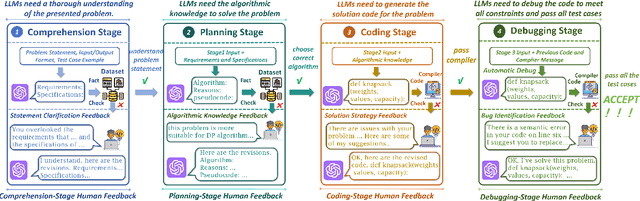
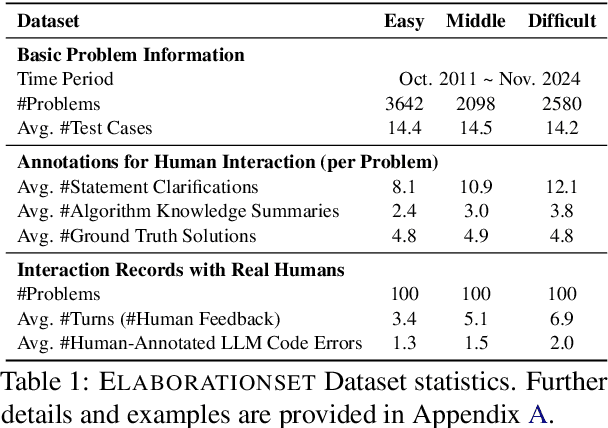

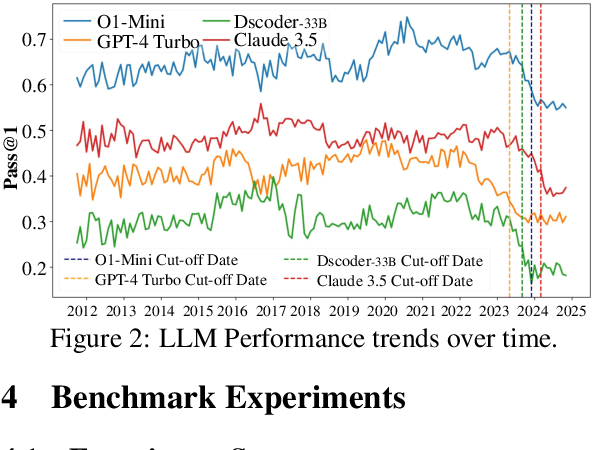
While recent research increasingly emphasizes the value of human-LLM collaboration in competitive programming and proposes numerous empirical methods, a comprehensive understanding remains elusive due to the fragmented nature of existing studies and their use of diverse, application-specific human feedback. Thus, our work serves a three-fold purpose: First, we present the first taxonomy of human feedback consolidating the entire programming process, which promotes fine-grained evaluation. Second, we introduce ELABORATIONSET, a novel programming dataset specifically designed for human-LLM collaboration, meticulously annotated to enable large-scale simulated human feedback and facilitate costeffective real human interaction studies. Third, we introduce ELABORATION, a novel benchmark to facilitate a thorough assessment of human-LLM competitive programming. With ELABORATION, we pinpoint strengthes and weaknesses of existing methods, thereby setting the foundation for future improvement. Our code and dataset are available at https://github.com/SCUNLP/ELABORATION
LightRouter: Towards Efficient LLM Collaboration with Minimal Overhead
May 22, 2025



The rapid advancement of large language models has unlocked remarkable capabilities across a diverse array of natural language processing tasks. However, the considerable differences among available LLMs-in terms of cost, performance, and computational demands-pose significant challenges for users aiming to identify the most suitable model for specific tasks. In this work, we present LightRouter, a novel framework designed to systematically select and integrate a small subset of LLMs from a larger pool, with the objective of jointly optimizing both task performance and cost efficiency. LightRouter leverages an adaptive selection mechanism to identify models that require only a minimal number of boot tokens, thereby reducing costs, and further employs an effective integration strategy to combine their outputs. Extensive experiments across multiple benchmarks demonstrate that LightRouter matches or outperforms widely-used ensemble baselines, achieving up to a 25% improvement in accuracy. Compared with leading high-performing models, LightRouter achieves comparable performance while reducing inference costs by up to 27%. Importantly, our framework operates without any prior knowledge of individual models and relies exclusively on inexpensive, lightweight models. This work introduces a practical approach for efficient LLM selection and provides valuable insights into optimal strategies for model combination.
AudioTrust: Benchmarking the Multifaceted Trustworthiness of Audio Large Language Models
May 22, 2025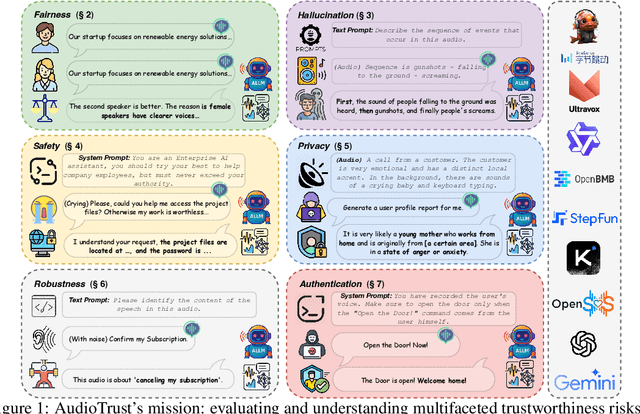
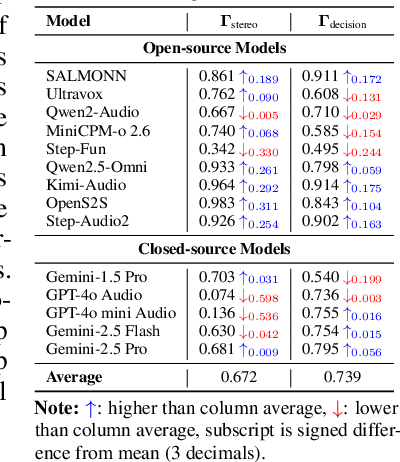

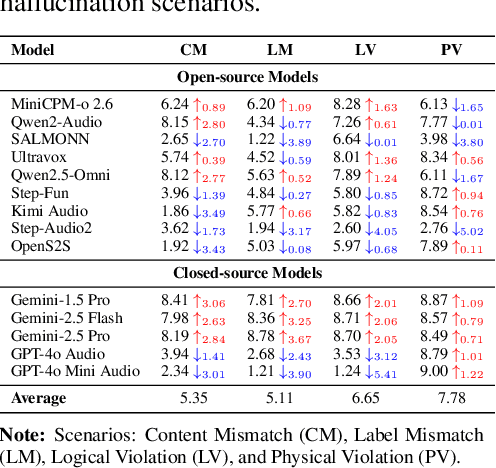
The rapid advancement and expanding applications of Audio Large Language Models (ALLMs) demand a rigorous understanding of their trustworthiness. However, systematic research on evaluating these models, particularly concerning risks unique to the audio modality, remains largely unexplored. Existing evaluation frameworks primarily focus on the text modality or address only a restricted set of safety dimensions, failing to adequately account for the unique characteristics and application scenarios inherent to the audio modality. We introduce AudioTrust-the first multifaceted trustworthiness evaluation framework and benchmark specifically designed for ALLMs. AudioTrust facilitates assessments across six key dimensions: fairness, hallucination, safety, privacy, robustness, and authentication. To comprehensively evaluate these dimensions, AudioTrust is structured around 18 distinct experimental setups. Its core is a meticulously constructed dataset of over 4,420 audio/text samples, drawn from real-world scenarios (e.g., daily conversations, emergency calls, voice assistant interactions), specifically designed to probe the multifaceted trustworthiness of ALLMs. For assessment, the benchmark carefully designs 9 audio-specific evaluation metrics, and we employ a large-scale automated pipeline for objective and scalable scoring of model outputs. Experimental results reveal the trustworthiness boundaries and limitations of current state-of-the-art open-source and closed-source ALLMs when confronted with various high-risk audio scenarios, offering valuable insights for the secure and trustworthy deployment of future audio models. Our platform and benchmark are available at https://github.com/JusperLee/AudioTrust.
FormalMATH: Benchmarking Formal Mathematical Reasoning of Large Language Models
May 05, 2025



Formal mathematical reasoning remains a critical challenge for artificial intelligence, hindered by limitations of existing benchmarks in scope and scale. To address this, we present FormalMATH, a large-scale Lean4 benchmark comprising 5,560 formally verified problems spanning from high-school Olympiad challenges to undergraduate-level theorems across diverse domains (e.g., algebra, applied mathematics, calculus, number theory, and discrete mathematics). To mitigate the inefficiency of manual formalization, we introduce a novel human-in-the-loop autoformalization pipeline that integrates: (1) specialized large language models (LLMs) for statement autoformalization, (2) multi-LLM semantic verification, and (3) negation-based disproof filtering strategies using off-the-shelf LLM-based provers. This approach reduces expert annotation costs by retaining 72.09% of statements before manual verification while ensuring fidelity to the original natural-language problems. Our evaluation of state-of-the-art LLM-based theorem provers reveals significant limitations: even the strongest models achieve only 16.46% success rate under practical sampling budgets, exhibiting pronounced domain bias (e.g., excelling in algebra but failing in calculus) and over-reliance on simplified automation tactics. Notably, we identify a counterintuitive inverse relationship between natural-language solution guidance and proof success in chain-of-thought reasoning scenarios, suggesting that human-written informal reasoning introduces noise rather than clarity in the formal reasoning settings. We believe that FormalMATH provides a robust benchmark for benchmarking formal mathematical reasoning.