 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSS-Auto: A Single-Shot, Automatic Structured Weight Pruning Framework of DNNs with Ultra-High Efficiency
Jan 23, 2020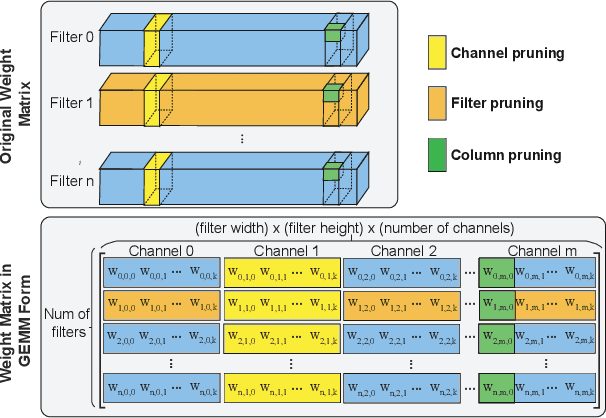
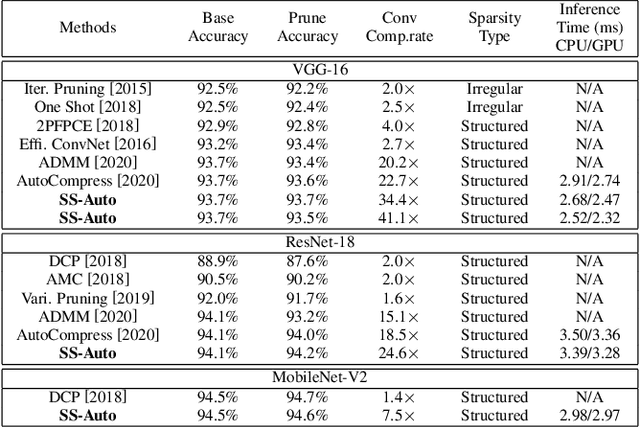
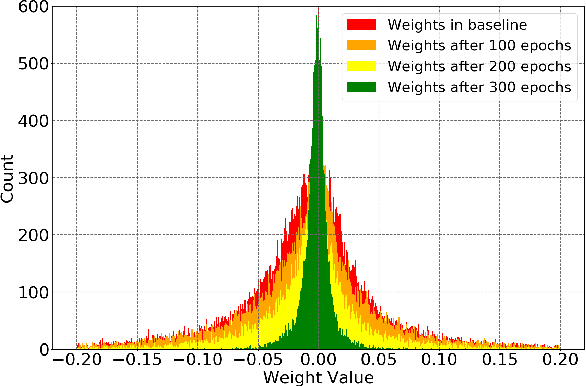
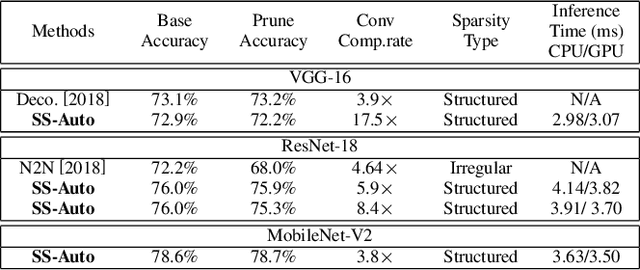
Structured weight pruning is a representative model compression technique of DNNs for hardware efficiency and inference accelerations. Previous works in this area leave great space for improvement since sparse structures with combinations of different structured pruning schemes are not exploited fully and efficiently. To mitigate the limitations, we propose SS-Auto, a single-shot, automatic structured pruning framework that can achieve row pruning and column pruning simultaneously. We adopt soft constraint-based formulation to alleviate the strong non-convexity of l0-norm constraints used in state-of-the-art ADMM-based methods for faster convergence and fewer hyperparameters. Instead of solving the problem directly, a Primal-Proximal solution is proposed to avoid the pitfall of penalizing all weights equally, thereby enhancing the accuracy. Extensive experiments on CIFAR-10 and CIFAR-100 datasets demonstrate that the proposed framework can achieve ultra-high pruning rates while maintaining accuracy. Furthermore, significant inference speedup has been observed from the proposed framework through actual measurements on the smartphone.
Domain Adaptation via Teacher-Student Learning for End-to-End Speech Recognition
Jan 06, 2020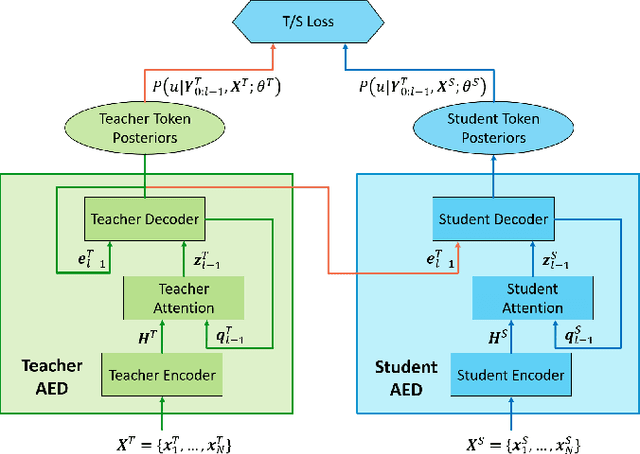
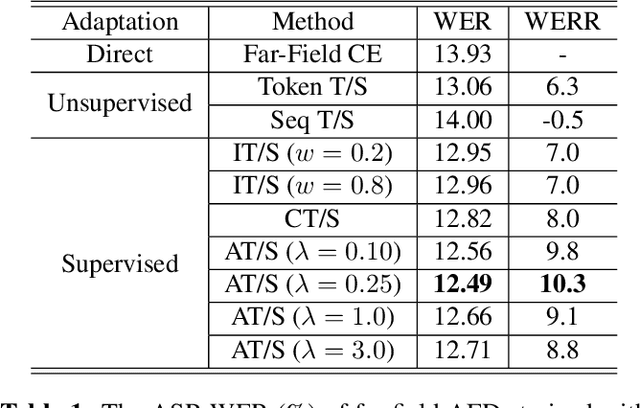
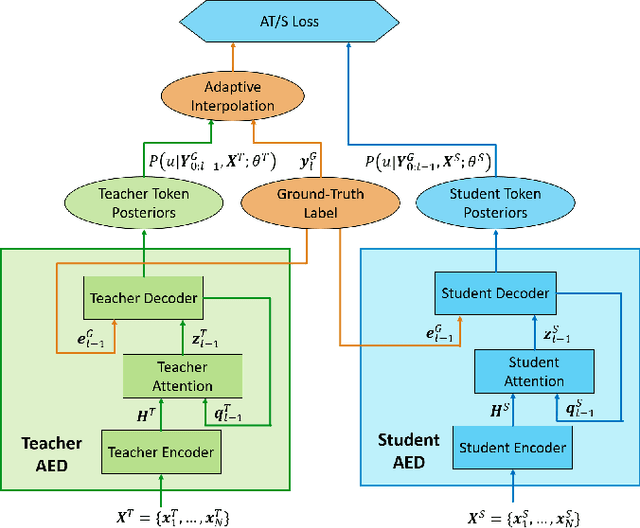
Teacher-student (T/S) has shown to be effective for domain adaptation of deep neural network acoustic models in hybrid speech recognition systems. In this work, we extend the T/S learning to large-scale unsupervised domain adaptation of an attention-based end-to-end (E2E) model through two levels of knowledge transfer: teacher's token posteriors as soft labels and one-best predictions as decoder guidance. To further improve T/S learning with the help of ground-truth labels, we propose adaptive T/S (AT/S) learning. Instead of conditionally choosing from either the teacher's soft token posteriors or the one-hot ground-truth label, in AT/S, the student always learns from both the teacher and the ground truth with a pair of adaptive weights assigned to the soft and one-hot labels quantifying the confidence on each of the knowledge sources. The confidence scores are dynamically estimated at each decoder step as a function of the soft and one-hot labels. With 3400 hours parallel close-talk and far-field Microsoft Cortana data for domain adaptation, T/S and AT/S achieve 6.3% and 10.3% relative word error rate improvement over a strong E2E model trained with the same amount of far-field data.
* 8 pages, 2 figures, ASRU 2019
Character-Aware Attention-Based End-to-End Speech Recognition
Jan 06, 2020
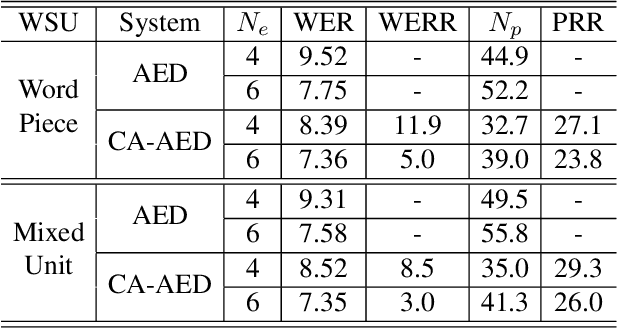
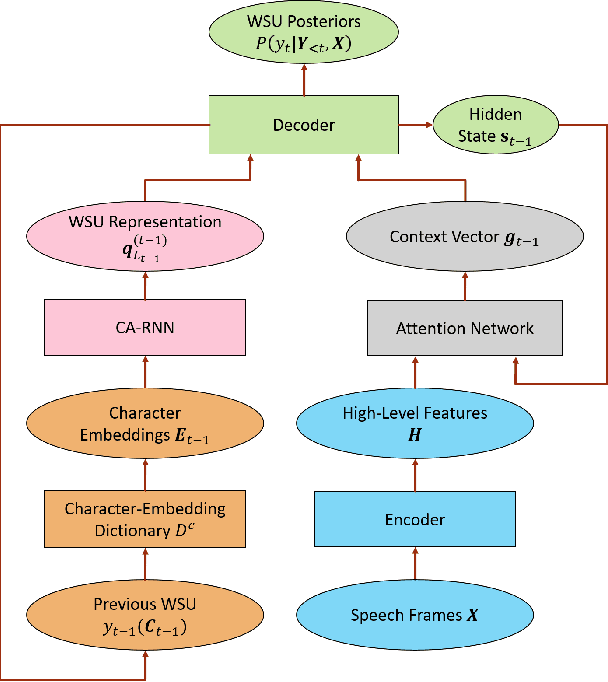
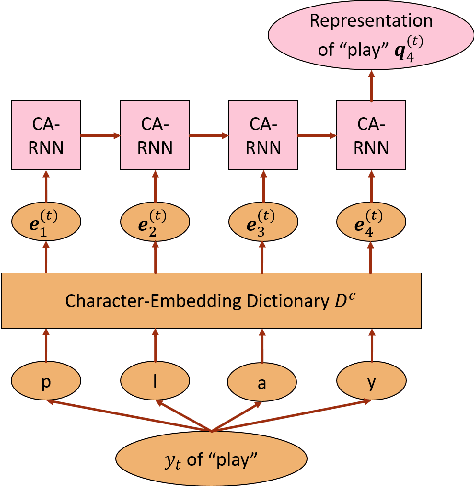
Predicting words and subword units (WSUs) as the output has shown to be effective for the attention-based encoder-decoder (AED) model in end-to-end speech recognition. However, as one input to the decoder recurrent neural network (RNN), each WSU embedding is learned independently through context and acoustic information in a purely data-driven fashion. Little effort has been made to explicitly model the morphological relationships among WSUs. In this work, we propose a novel character-aware (CA) AED model in which each WSU embedding is computed by summarizing the embeddings of its constituent characters using a CA-RNN. This WSU-independent CA-RNN is jointly trained with the encoder, the decoder and the attention network of a conventional AED to predict WSUs. With CA-AED, the embeddings of morphologically similar WSUs are naturally and directly correlated through the CA-RNN in addition to the semantic and acoustic relations modeled by a traditional AED. Moreover, CA-AED significantly reduces the model parameters in a traditional AED by replacing the large pool of WSU embeddings with a much smaller set of character embeddings. On a 3400 hours Microsoft Cortana dataset, CA-AED achieves up to 11.9% relative WER improvement over a strong AED baseline with 27.1% fewer model parameters.
* 7 pages, 3 figures, ASRU 2019
Advances in Online Audio-Visual Meeting Transcription
Dec 10, 2019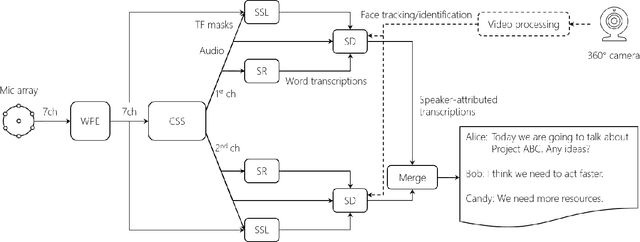

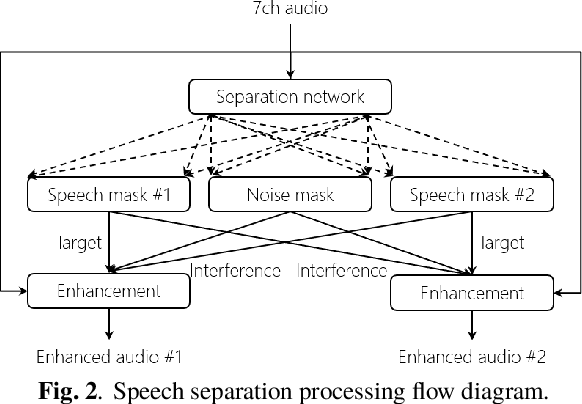
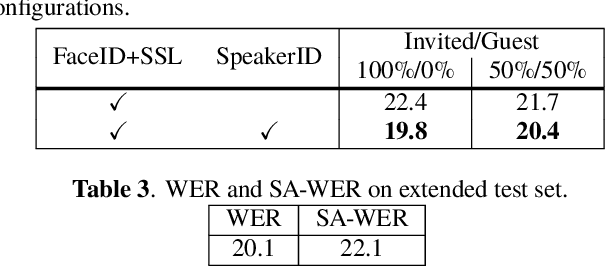
This paper describes a system that generates speaker-annotated transcripts of meetings by using a microphone array and a 360-degree camera. The hallmark of the system is its ability to handle overlapped speech, which has been an unsolved problem in realistic settings for over a decade. We show that this problem can be addressed by using a continuous speech separation approach. In addition, we describe an online audio-visual speaker diarization method that leverages face tracking and identification, sound source localization, speaker identification, and, if available, prior speaker information for robustness to various real world challenges. All components are integrated in a meeting transcription framework called SRD, which stands for "separate, recognize, and diarize". Experimental results using recordings of natural meetings involving up to 11 attendees are reported. The continuous speech separation improves a word error rate (WER) by 16.1% compared with a highly tuned beamformer. When a complete list of meeting attendees is available, the discrepancy between WER and speaker-attributed WER is only 1.0%, indicating accurate word-to-speaker association. This increases marginally to 1.6% when 50% of the attendees are unknown to the system.
Speaker Adaptation for Attention-Based End-to-End Speech Recognition
Nov 09, 2019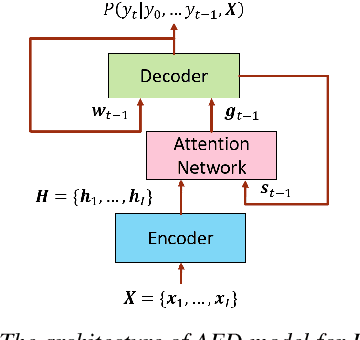
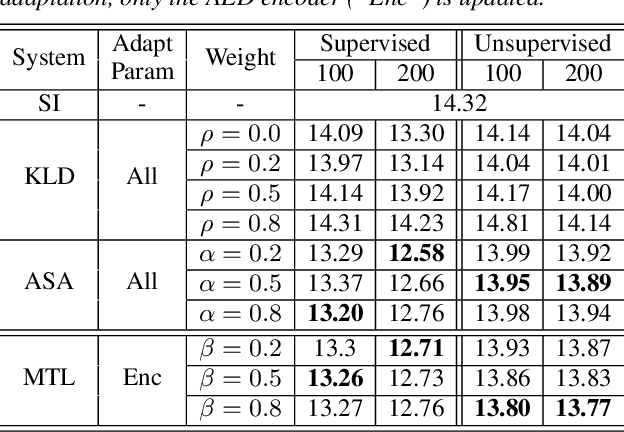
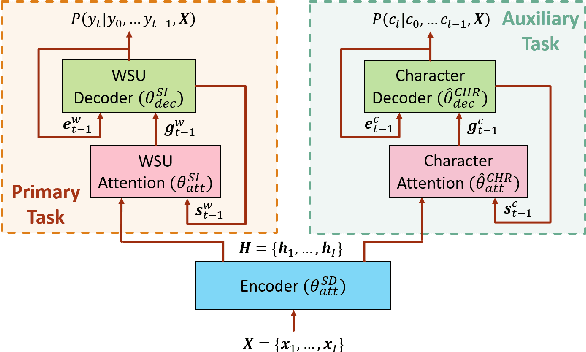
We propose three regularization-based speaker adaptation approaches to adapt the attention-based encoder-decoder (AED) model with very limited adaptation data from target speakers for end-to-end automatic speech recognition. The first method is Kullback-Leibler divergence (KLD) regularization, in which the output distribution of a speaker-dependent (SD) AED is forced to be close to that of the speaker-independent (SI) model by adding a KLD regularization to the adaptation criterion. To compensate for the asymmetric deficiency in KLD regularization, an adversarial speaker adaptation (ASA) method is proposed to regularize the deep-feature distribution of the SD AED through the adversarial learning of an auxiliary discriminator and the SD AED. The third approach is the multi-task learning, in which an SD AED is trained to jointly perform the primary task of predicting a large number of output units and an auxiliary task of predicting a small number of output units to alleviate the target sparsity issue. Evaluated on a Microsoft short message dictation task, all three methods are highly effective in adapting the AED model, achieving up to 12.2% and 3.0% word error rate improvement over an SI AED trained from 3400 hours data for supervised and unsupervised adaptation, respectively.
* 5 pages, 3 figures, Interspeech 2019
Improving RNN Transducer Modeling for End-to-End Speech Recognition
Sep 26, 2019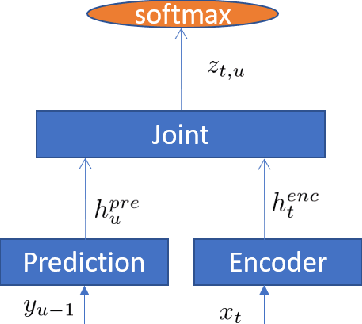
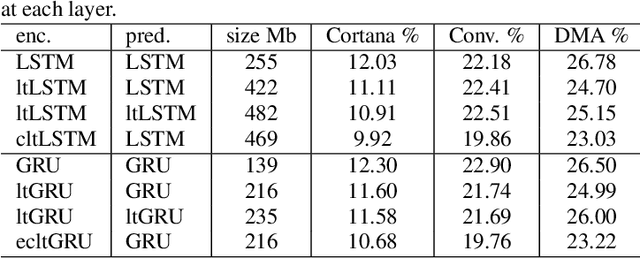
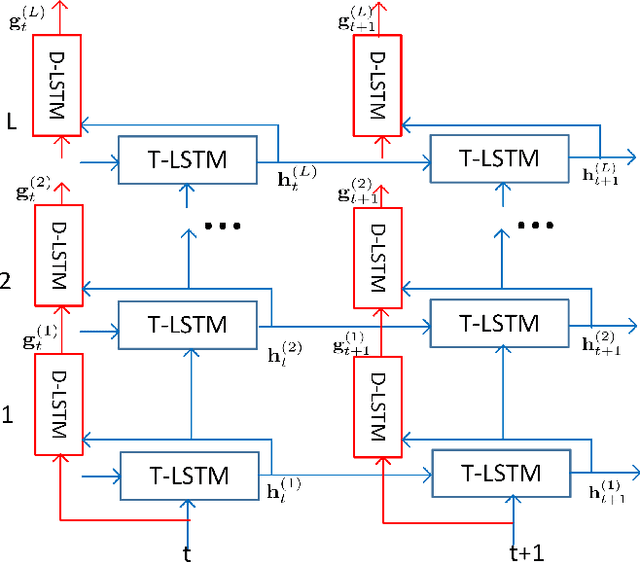
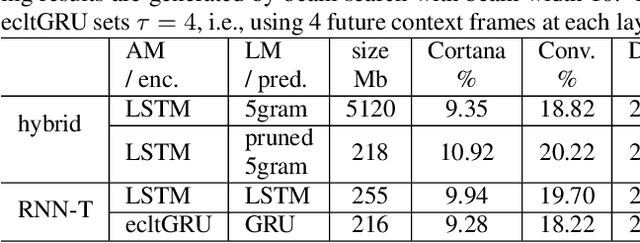
In the last few years, an emerging trend in automatic speech recognition research is the study of end-to-end (E2E) systems. Connectionist Temporal Classification (CTC), Attention Encoder-Decoder (AED), and RNN Transducer (RNN-T) are the most popular three methods. Among these three methods, RNN-T has the advantages to do online streaming which is challenging to AED and it doesn't have CTC's frame-independence assumption. In this paper, we improve the RNN-T training in two aspects. First, we optimize the training algorithm of RNN-T to reduce the memory consumption so that we can have larger training minibatch for faster training speed. Second, we propose better model structures so that we obtain RNN-T models with the very good accuracy but small footprint. Trained with 30 thousand hours anonymized and transcribed Microsoft production data, the best RNN-T model with even smaller model size (216 Megabytes) achieves up-to 11.8% relative word error rate (WER) reduction from the baseline RNN-T model. This best RNN-T model is significantly better than the device hybrid model with similar size by achieving up-to 15.0% relative WER reduction, and obtains similar WERs as the server hybrid model of 5120 Megabytes in size.
Self-Teaching Networks
Sep 09, 2019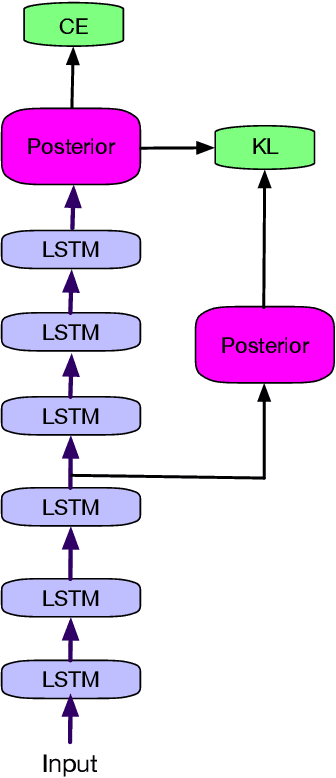
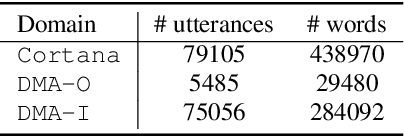
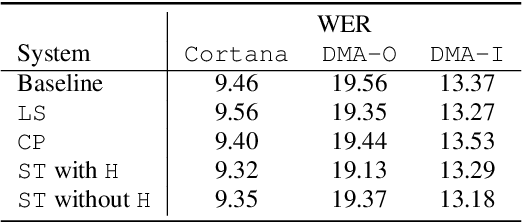
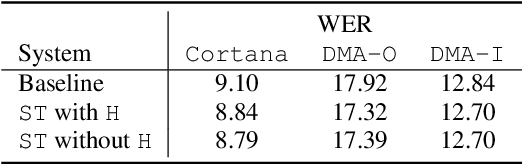
We propose self-teaching networks to improve the generalization capacity of deep neural networks. The idea is to generate soft supervision labels using the output layer for training the lower layers of the network. During the network training, we seek an auxiliary loss that drives the lower layer to mimic the behavior of the output layer. The connection between the two network layers through the auxiliary loss can help the gradient flow, which works similar to the residual networks. Furthermore, the auxiliary loss also works as a regularizer, which improves the generalization capacity of the network. We evaluated the self-teaching network with deep recurrent neural networks on speech recognition tasks, where we trained the acoustic model using 30 thousand hours of data. We tested the acoustic model using data collected from 4 scenarios. We show that the self-teaching network can achieve consistent improvements and outperform existing methods such as label smoothing and confidence penalization.
PyKaldi2: Yet another speech toolkit based on Kaldi and PyTorch
Jul 30, 2019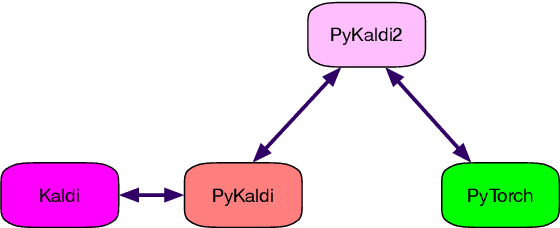


We introduce PyKaldi2 speech recognition toolkit implemented based on Kaldi and PyTorch. While similar toolkits are available built on top of the two, a key feature of PyKaldi2 is sequence training with criteria such as MMI, sMBR and MPE. In particular, we implemented the sequence training module with on-the-fly lattice generation during model training in order to simplify the training pipeline. To address the challenging acoustic environments in real applications, PyKaldi2 also supports on-the-fly noise and reverberation simulation to improve the model robustness. With this feature, it is possible to backpropogate the gradients from the sequence-level loss to the front-end feature extraction module, which, hopefully, can foster more research in the direction of joint front-end and backend learning. We performed benchmark experiments on Librispeech, and show that PyKaldi2 can achieve reasonable recognition accuracy. The toolkit is released under the MIT license.
Encrypted Speech Recognition using Deep Polynomial Networks
May 11, 2019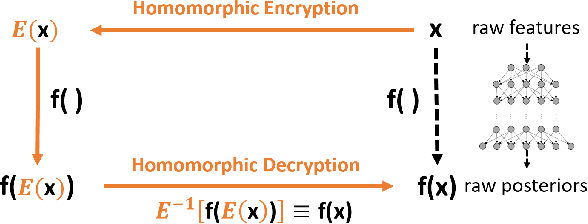
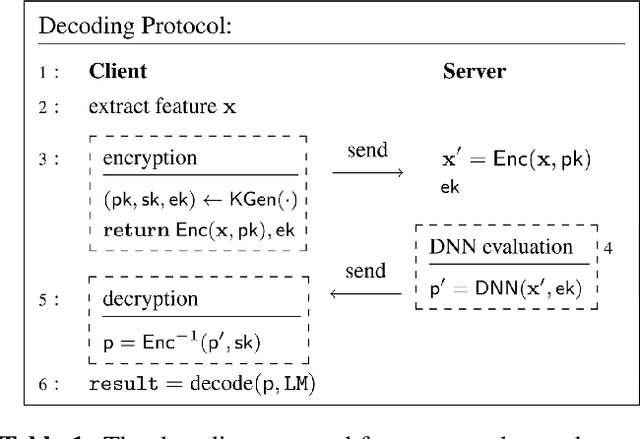
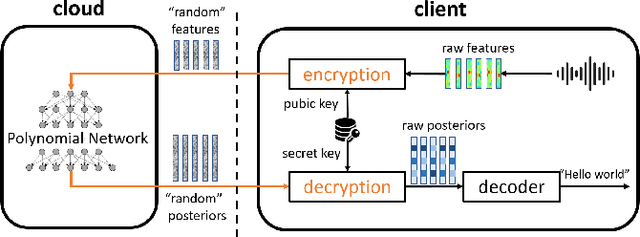
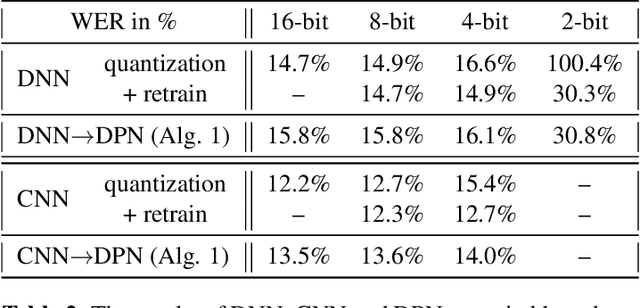
The cloud-based speech recognition/API provides developers or enterprises an easy way to create speech-enabled features in their applications. However, sending audios about personal or company internal information to the cloud, raises concerns about the privacy and security issues. The recognition results generated in cloud may also reveal some sensitive information. This paper proposes a deep polynomial network (DPN) that can be applied to the encrypted speech as an acoustic model. It allows clients to send their data in an encrypted form to the cloud to ensure that their data remains confidential, at mean while the DPN can still make frame-level predictions over the encrypted speech and return them in encrypted form. One good property of the DPN is that it can be trained on unencrypted speech features in the traditional way. To keep the cloud away from the raw audio and recognition results, a cloud-local joint decoding framework is also proposed. We demonstrate the effectiveness of model and framework on the Switchboard and Cortana voice assistant tasks with small performance degradation and latency increased comparing with the traditional cloud-based DNNs.
Adversarial Speaker Adaptation
Apr 29, 2019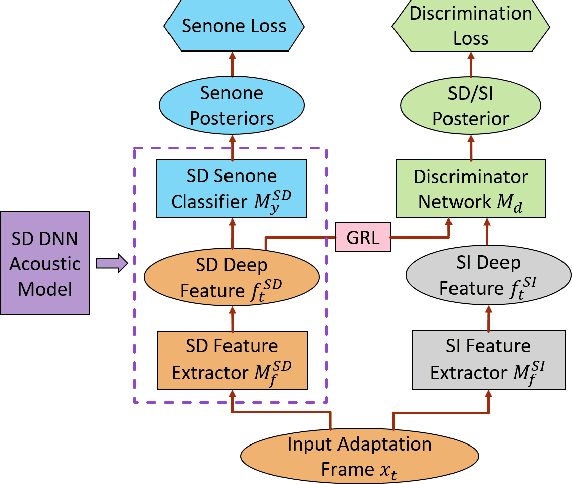
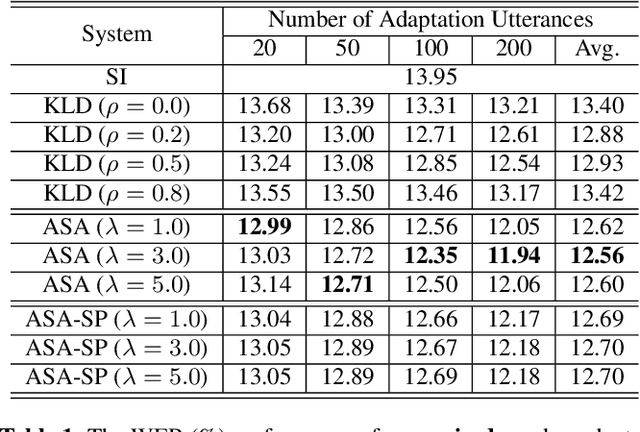
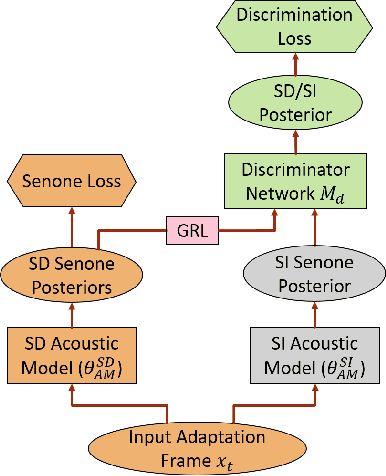
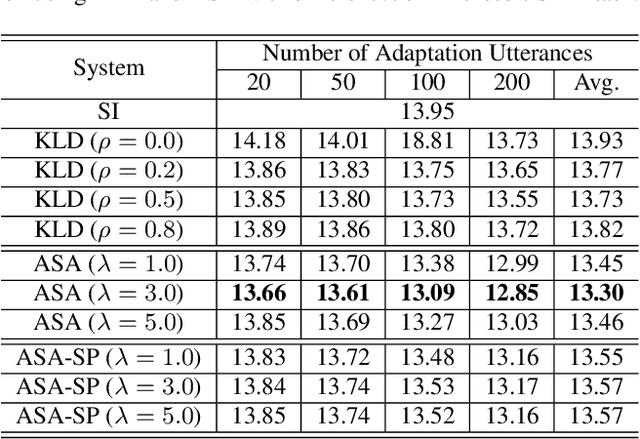
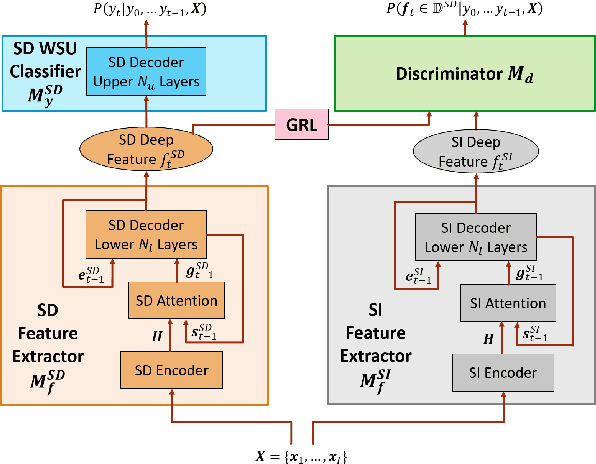
We propose a novel adversarial speaker adaptation (ASA) scheme, in which adversarial learning is applied to regularize the distribution of deep hidden features in a speaker-dependent (SD) deep neural network (DNN) acoustic model to be close to that of a fixed speaker-independent (SI) DNN acoustic model during adaptation. An additional discriminator network is introduced to distinguish the deep features generated by the SD model from those produced by the SI model. In ASA, with a fixed SI model as the reference, an SD model is jointly optimized with the discriminator network to minimize the senone classification loss, and simultaneously to mini-maximize the SI/SD discrimination loss on the adaptation data. With ASA, a senone-discriminative deep feature is learned in the SD model with a similar distribution to that of the SI model. With such a regularized and adapted deep feature, the SD model can perform improved automatic speech recognition on the target speaker's speech. Evaluated on the Microsoft short message dictation dataset, ASA achieves 14.4% and 7.9% relative word error rate improvements for supervised and unsupervised adaptation, respectively, over an SI model trained from 2600 hours data, with 200 adaptation utterances per speaker.
* 5 pages, 2 figures, ICASSP 2019