 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSC3OD: Sparsely Supervised Collaborative 3D Object Detection from LiDAR Point Clouds
Jul 03, 2023



Collaborative 3D object detection, with its improved interaction advantage among multiple agents, has been widely explored in autonomous driving. However, existing collaborative 3D object detectors in a fully supervised paradigm heavily rely on large-scale annotated 3D bounding boxes, which is labor-intensive and time-consuming. To tackle this issue, we propose a sparsely supervised collaborative 3D object detection framework SSC3OD, which only requires each agent to randomly label one object in the scene. Specifically, this model consists of two novel components, i.e., the pillar-based masked autoencoder (Pillar-MAE) and the instance mining module. The Pillar-MAE module aims to reason over high-level semantics in a self-supervised manner, and the instance mining module generates high-quality pseudo labels for collaborative detectors online. By introducing these simple yet effective mechanisms, the proposed SSC3OD can alleviate the adverse impacts of incomplete annotations. We generate sparse labels based on collaborative perception datasets to evaluate our method. Extensive experiments on three large-scale datasets reveal that our proposed SSC3OD can effectively improve the performance of sparsely supervised collaborative 3D object detectors.
The Cascaded Forward Algorithm for Neural Network Training
Mar 24, 2023



Backpropagation algorithm has been widely used as a mainstream learning procedure for neural networks in the past decade, and has played a significant role in the development of deep learning. However, there exist some limitations associated with this algorithm, such as getting stuck in local minima and experiencing vanishing/exploding gradients, which have led to questions about its biological plausibility. To address these limitations, alternative algorithms to backpropagation have been preliminarily explored, with the Forward-Forward (FF) algorithm being one of the most well-known. In this paper we propose a new learning framework for neural networks, namely Cascaded Forward (CaFo) algorithm, which does not rely on BP optimization as that in FF. Unlike FF, our framework directly outputs label distributions at each cascaded block, which does not require generation of additional negative samples and thus leads to a more efficient process at both training and testing. Moreover, in our framework each block can be trained independently, so it can be easily deployed into parallel acceleration systems. The proposed method is evaluated on four public image classification benchmarks, and the experimental results illustrate significant improvement in prediction accuracy in comparison with the baseline.
Collaborative Perception in Autonomous Driving: Methods, Datasets and Challenges
Jan 16, 2023



Collaborative perception is essential to address occlusion and sensor failure issues in autonomous driving. In recent years, deep learning on collaborative perception has become even thriving, with numerous methods have been proposed. Although some works have reviewed and analyzed the basic architecture and key components in this field, there is still a lack of reviews on systematical collaboration modules in perception networks and large-scale collaborative perception datasets. The primary goal of this work is to address the abovementioned issues and provide a comprehensive review of recent achievements in this field. First, we introduce fundamental technologies and collaboration schemes. Following that, we provide an overview of practical collaborative perception methods and systematically summarize the collaboration modules in networks to improve collaboration efficiency and performance while also ensuring collaboration robustness and safety. Then, we present large-scale public datasets and summarize quantitative results on these benchmarks. Finally, we discuss the remaining challenges and promising future research directions.
LightFR: Lightweight Federated Recommendation with Privacy-preserving Matrix Factorization
Jun 23, 2022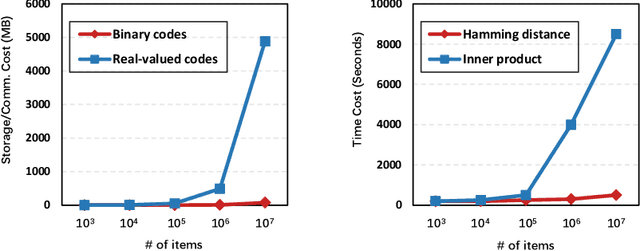


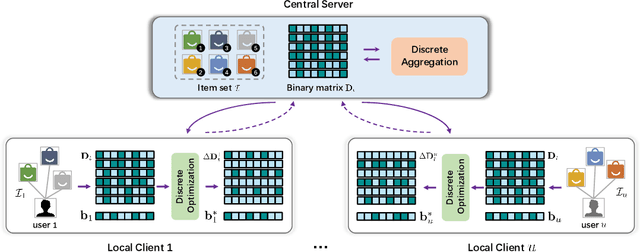
Federated recommender system (FRS), which enables many local devices to train a shared model jointly without transmitting local raw data, has become a prevalent recommendation paradigm with privacy-preserving advantages. However, previous work on FRS performs similarity search via inner product in continuous embedding space, which causes an efficiency bottleneck when the scale of items is extremely large. We argue that such a scheme in federated settings ignores the limited capacities in resource-constrained user devices (i.e., storage space, computational overhead, and communication bandwidth), and makes it harder to be deployed in large-scale recommender systems. Besides, it has been shown that the transmission of local gradients in real-valued form between server and clients may leak users' private information. To this end, we propose a lightweight federated recommendation framework with privacy-preserving matrix factorization, LightFR, that is able to generate high-quality binary codes by exploiting learning to hash techniques under federated settings, and thus enjoys both fast online inference and economic memory consumption. Moreover, we devise an efficient federated discrete optimization algorithm to collaboratively train model parameters between the server and clients, which can effectively prevent real-valued gradient attacks from malicious parties. Through extensive experiments on four real-world datasets, we show that our LightFR model outperforms several state-of-the-art FRS methods in terms of recommendation accuracy, inference efficiency and data privacy.
Boundary Corrected Multi-scale Fusion Network for Real-time Semantic Segmentation
Mar 01, 2022

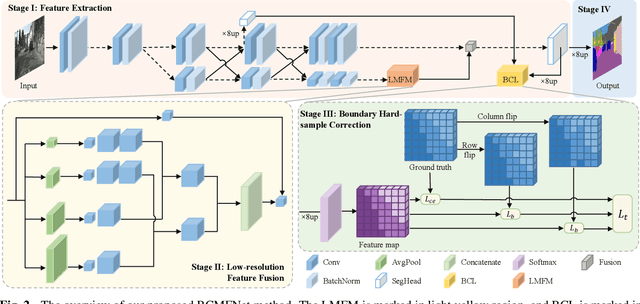
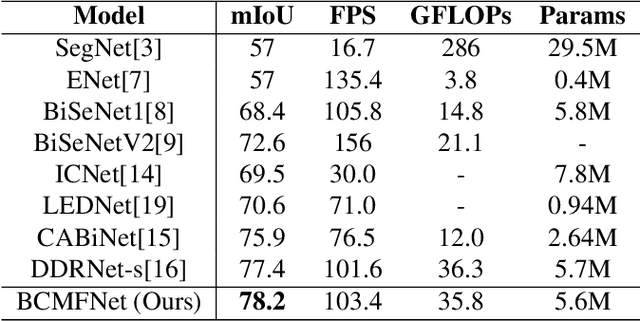
Image semantic segmentation aims at the pixel-level classification of images, which has requirements for both accuracy and speed in practical application. Existing semantic segmentation methods mainly rely on the high-resolution input to achieve high accuracy and do not meet the requirements of inference time. Although some methods focus on high-speed scene parsing with lightweight architectures, they can not fully mine semantic features under low computation with relatively low performance. To realize the real-time and high-precision segmentation, we propose a new method named Boundary Corrected Multi-scale Fusion Network, which uses the designed Low-resolution Multi-scale Fusion Module to extract semantic information. Moreover, to deal with boundary errors caused by low-resolution feature map fusion, we further design an additional Boundary Corrected Loss to constrain overly smooth features. Extensive experiments show that our method achieves a state-of-the-art balance of accuracy and speed for the real-time semantic segmentation.
LighTN: Light-weight Transformer Network for Performance-overhead Tradeoff in Point Cloud Downsampling
Feb 13, 2022Compared with traditional task-irrelevant downsampling methods, task-oriented neural networks have shown improved performance in point cloud downsampling range. Recently, Transformer family of networks has shown a more powerful learning capacity in visual tasks. However, Transformer-based architectures potentially consume too many resources which are usually worthless for low overhead task networks in downsampling range. This paper proposes a novel light-weight Transformer network (LighTN) for task-oriented point cloud downsampling, as an end-to-end and plug-and-play solution. In LighTN, a single-head self-correlation module is presented to extract refined global contextual features, where three projection matrices are simultaneously eliminated to save resource overhead, and the output of symmetric matrix satisfies the permutation invariant. Then, we design a novel downsampling loss function to guide LighTN focuses on critical point cloud regions with more uniform distribution and prominent points coverage. Furthermore, We introduce a feed-forward network scaling mechanism to enhance the learnable capacity of LighTN according to the expand-reduce strategy. The result of extensive experiments on classification and registration tasks demonstrates LighTN can achieve state-of-the-art performance with limited resource overhead.
Deep Probabilistic Graph Matching
Jan 05, 2022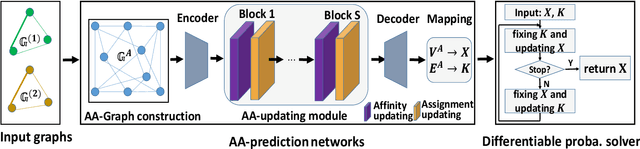
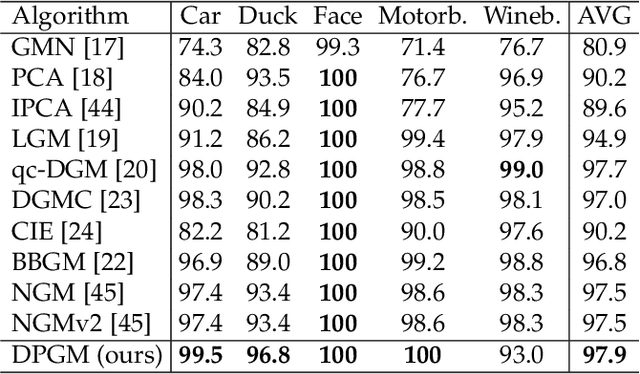
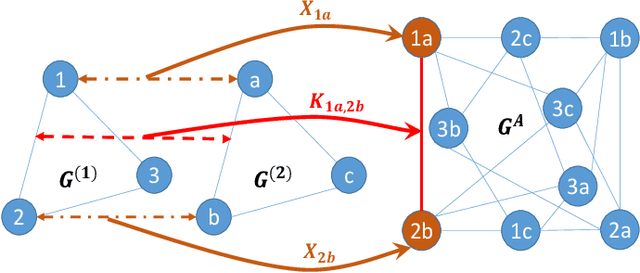
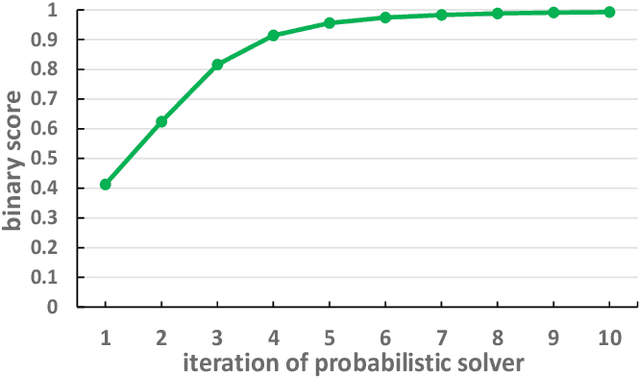
Most previous learning-based graph matching algorithms solve the \textit{quadratic assignment problem} (QAP) by dropping one or more of the matching constraints and adopting a relaxed assignment solver to obtain sub-optimal correspondences. Such relaxation may actually weaken the original graph matching problem, and in turn hurt the matching performance. In this paper we propose a deep learning-based graph matching framework that works for the original QAP without compromising on the matching constraints. In particular, we design an affinity-assignment prediction network to jointly learn the pairwise affinity and estimate the node assignments, and we then develop a differentiable solver inspired by the probabilistic perspective of the pairwise affinities. Aiming to obtain better matching results, the probabilistic solver refines the estimated assignments in an iterative manner to impose both discrete and one-to-one matching constraints. The proposed method is evaluated on three popularly tested benchmarks (Pascal VOC, Willow Object and SPair-71k), and it outperforms all previous state-of-the-arts on all benchmarks.
GLAN: A Graph-based Linear Assignment Network
Jan 05, 2022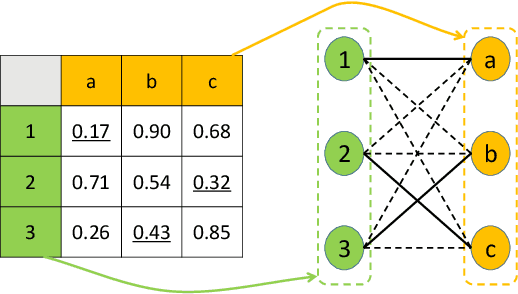
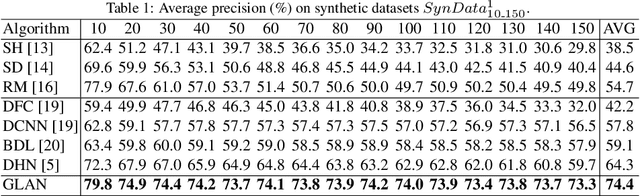
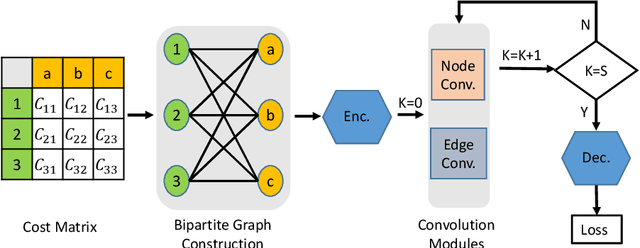

Differentiable solvers for the linear assignment problem (LAP) have attracted much research attention in recent years, which are usually embedded into learning frameworks as components. However, previous algorithms, with or without learning strategies, usually suffer from the degradation of the optimality with the increment of the problem size. In this paper, we propose a learnable linear assignment solver based on deep graph networks. Specifically, we first transform the cost matrix to a bipartite graph and convert the assignment task to the problem of selecting reliable edges from the constructed graph. Subsequently, a deep graph network is developed to aggregate and update the features of nodes and edges. Finally, the network predicts a label for each edge that indicates the assignment relationship. The experimental results on a synthetic dataset reveal that our method outperforms state-of-the-art baselines and achieves consistently high accuracy with the increment of the problem size. Furthermore, we also embed the proposed solver, in comparison with state-of-the-art baseline solvers, into a popular multi-object tracking (MOT) framework to train the tracker in an end-to-end manner. The experimental results on MOT benchmarks illustrate that the proposed LAP solver improves the tracker by the largest margin.
Camera-aware Style Separation and Contrastive Learning for Unsupervised Person Re-identification
Dec 19, 2021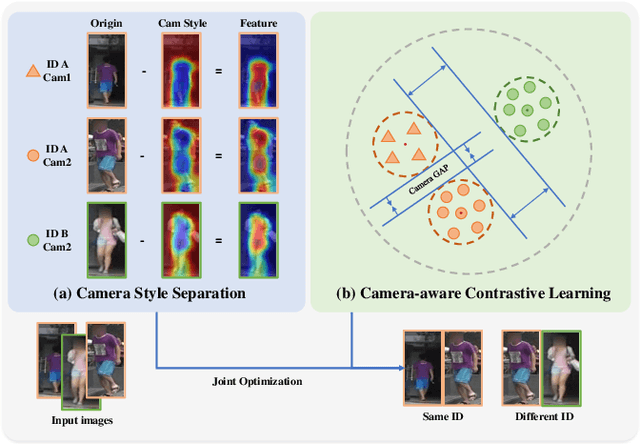
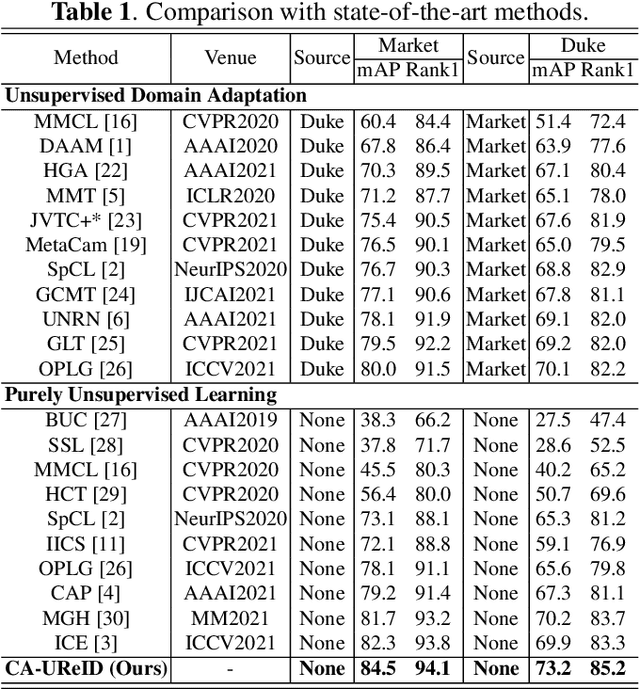
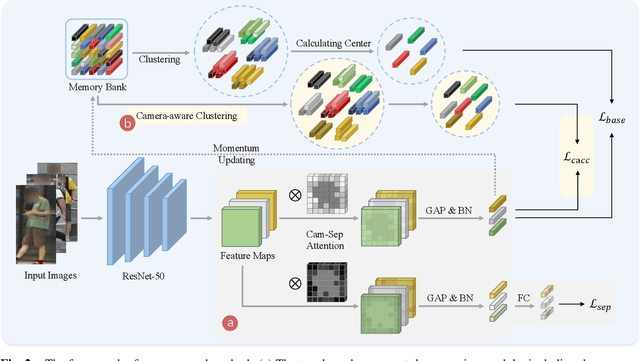
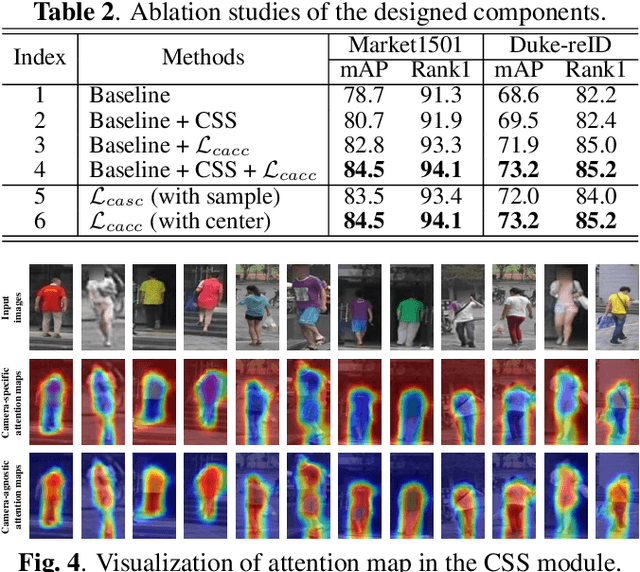
Unsupervised person re-identification (ReID) is a challenging task without data annotation to guide discriminative learning. Existing methods attempt to solve this problem by clustering extracted embeddings to generate pseudo labels. However, most methods ignore the intra-class gap caused by camera style variance, and some methods are relatively complex and indirect although they try to solve the negative impact of the camera style on feature distribution. To solve this problem, we propose a camera-aware style separation and contrastive learning method (CA-UReID), which directly separates camera styles in the feature space with the designed camera-aware attention module. It can explicitly divide the learnable feature into camera-specific and camera-agnostic parts, reducing the influence of different cameras. Moreover, to further narrow the gap across cameras, we design a camera-aware contrastive center loss to learn more discriminative embedding for each identity. Extensive experiments demonstrate the superiority of our method over the state-of-the-art methods on the unsupervised person ReID task.
Clicking Matters:Towards Interactive Human Parsing
Nov 11, 2021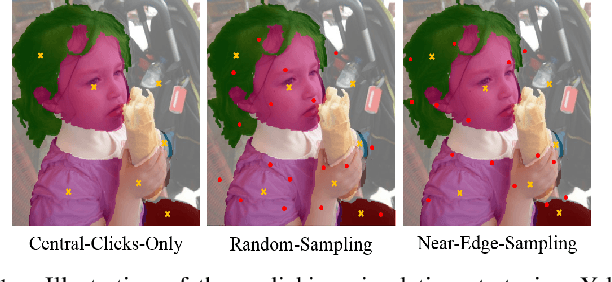
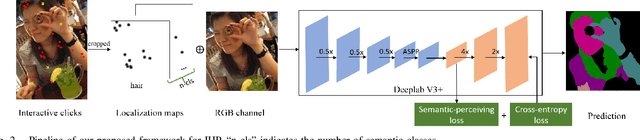
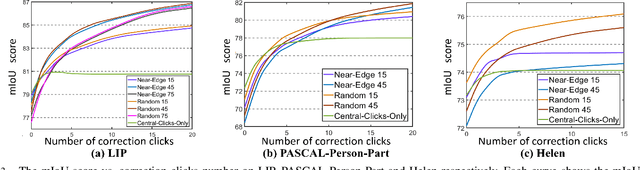
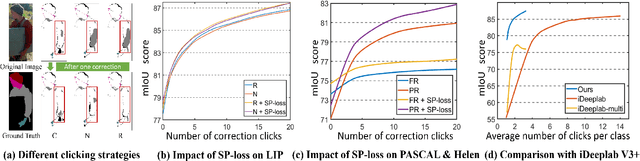
In this work, we focus on Interactive Human Parsing (IHP), which aims to segment a human image into multiple human body parts with guidance from users' interactions. This new task inherits the class-aware property of human parsing, which cannot be well solved by traditional interactive image segmentation approaches that are generally class-agnostic. To tackle this new task, we first exploit user clicks to identify different human parts in the given image. These clicks are subsequently transformed into semantic-aware localization maps, which are concatenated with the RGB image to form the input of the segmentation network and generate the initial parsing result. To enable the network to better perceive user's purpose during the correction process, we investigate several principal ways for the refinement, and reveal that random-sampling-based click augmentation is the best way for promoting the correction effectiveness. Furthermore, we also propose a semantic-perceiving loss (SP-loss) to augment the training, which can effectively exploit the semantic relationships of clicks for better optimization. To the best knowledge, this work is the first attempt to tackle the human parsing task under the interactive setting. Our IHP solution achieves 85\% mIoU on the benchmark LIP, 80\% mIoU on PASCAL-Person-Part and CIHP, 75\% mIoU on Helen with only 1.95, 3.02, 2.84 and 1.09 clicks per class respectively. These results demonstrate that we can simply acquire high-quality human parsing masks with only a few human effort. We hope this work can motivate more researchers to develop data-efficient solutions to IHP in the future.