 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgroTools: A Benchmark for Tool-Augmented Multimodal Agents in Agriculture
May 21, 2026Agricultural decision-making increasingly requires multimodal systems that can transform visual observations into reliable, executable actions. However, existing agricultural multimodal benchmarks mainly evaluate final-answer correctness and provide limited support for assessing whether models can use external tools to complete precision-sensitive workflows. In this paper, we introduce AgroTools, a benchmark for evaluating tool-augmented multimodal agents in agriculture. AgroTools contains 539 question-answer instances paired with 1,097 heterogeneous agricultural images, spanning five task families and an executable environment of 14 agricultural tools. Each query is annotated with structured tool-use traces, enabling a dual-view evaluation of both process-level execution quality and outcome-level task success. We benchmark 9 open-source and 4 closed-source multimodal large language models on AgroTools. Results show that current models remain far from reliable in agricultural tool-use settings, with clear bottlenecks in tool planning, argument generation, execution recovery, and final-answer synthesis. We hope AgroTools will support future research on multimodal agents for high-precision agricultural applications. The benchmark and evaluation are available at https://huggingface.co/datasets/AgroTools/AgroTools.
ConsistNav: Closing the Action Consistency Gap in Zero-Shot Object Navigation with Semantic Executive Control
May 11, 2026Zero-shot object navigation has advanced rapidly with open-vocabulary detectors, image--text models, and language-guided exploration. However, even after current methods detect a plausible target hypothesis, the agent may still oscillate between exploration and pursuit, or abandon the object near success. We identify this failure mode as an action consistency gap: semantic evidence is repeatedly reinterpreted at each step without persistent commitment across the episode. We introduce ConsistNav, a training-free zero-shot ObjectNav framework built around a semantic executive composed of three coordinated modules: Finite-State Executive Controller stages target pursuit through guarded semantic phases; Persistent Candidate Memory accumulates cross-frame target evidence into stable object hypotheses; and Stability-Aware Action Control suppresses rotational stagnation, ineffective pursuit, and unverified stopping. This design changes neither the detector nor the low-level planner; instead, it controls when semantic evidence should influence navigation and when it should be suppressed or revisited. We conduct extensive experiments on HM3D and MP3D, where ConsistNav achieves state-of-the-art results among compared zero-shot ObjectNav methods and improves SR by 11.4% and SPL by 7.9% over the controlled baseline on MP3D. Ablation studies and real-world deployment experiments further demonstrate the effectiveness and robustness of the proposed executive mechanism.
HM-Bench: A Comprehensive Benchmark for Multimodal Large Language Models in Hyperspectral Remote Sensing
Apr 10, 2026While multimodal large language models (MLLMs) have made significant strides in natural image understanding, their ability to perceive and reason over hyperspectral image (HSI) remains underexplored, which is a vital modality in remote sensing. The high dimensionality and intricate spectral-spatial properties of HSI pose unique challenges for models primarily trained on RGB data.To address this gap, we introduce Hyperspectral Multimodal Benchmark (HM-Bench), the first benchmark designed specifically to evaluate MLLMs in HSI understanding. We curate a large-scale dataset of 19,337 question-answer pairs across 13 task categories, ranging from basic perception to spectral reasoning. Given that existing MLLMs are not equipped to process raw hyperspectral cubes natively, we propose a dual-modality evaluation framework that transforms HSI data into two complementary representations: PCA-based composite images and structured textual reports. This approach facilitates a systematic comparison of different representation for model performance. Extensive evaluations on 18 representative MLLMs reveal significant difficulties in handling complex spatial-spectral reasoning tasks. Furthermore, our results demonstrate that visual inputs generally outperform textual inputs, highlighting the importance of grounding in spectral-spatial evidence for effective HSI understanding. Dataset and appendix can be accessed at https://github.com/HuoRiLi-Yu/HM-Bench.
A Comprehensive Review of Agricultural Parcel and Boundary Delineation from Remote Sensing Images: Recent Progress and Future Perspectives
Aug 20, 2025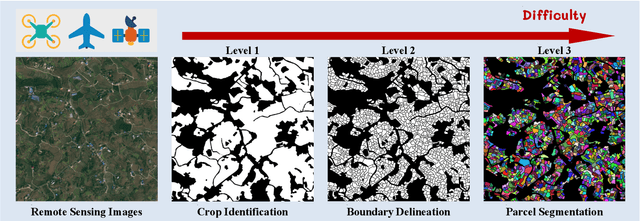
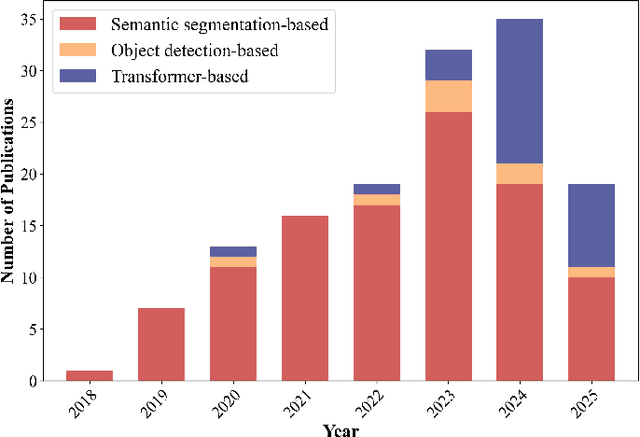
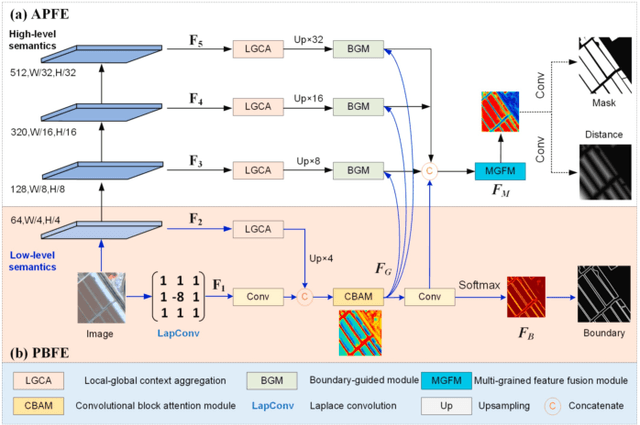
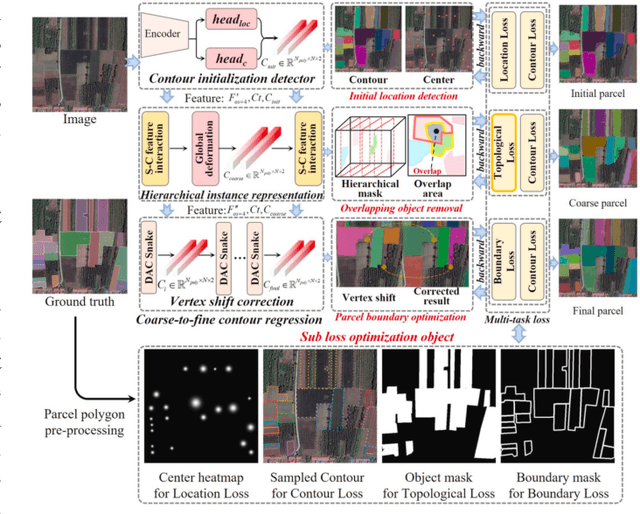
Powered by advances in multiple remote sensing sensors, the production of high spatial resolution images provides great potential to achieve cost-efficient and high-accuracy agricultural inventory and analysis in an automated way. Lots of studies that aim at providing an inventory of the level of each agricultural parcel have generated many methods for Agricultural Parcel and Boundary Delineation (APBD). This review covers APBD methods for detecting and delineating agricultural parcels and systematically reviews the past and present of APBD-related research applied to remote sensing images. With the goal to provide a clear knowledge map of existing APBD efforts, we conduct a comprehensive review of recent APBD papers to build a meta-data analysis, including the algorithm, the study site, the crop type, the sensor type, the evaluation method, etc. We categorize the methods into three classes: (1) traditional image processing methods (including pixel-based, edge-based and region-based); (2) traditional machine learning methods (such as random forest, decision tree); and (3) deep learning-based methods. With deep learning-oriented approaches contributing to a majority, we further discuss deep learning-based methods like semantic segmentation-based, object detection-based and Transformer-based methods. In addition, we discuss five APBD-related issues to further comprehend the APBD domain using remote sensing data, such as multi-sensor data in APBD task, comparisons between single-task learning and multi-task learning in the APBD domain, comparisons among different algorithms and different APBD tasks, etc. Finally, this review proposes some APBD-related applications and a few exciting prospects and potential hot topics in future APBD research. We hope this review help researchers who involved in APBD domain to keep track of its development and tendency.
Can Large Multimodal Models Understand Agricultural Scenes? Benchmarking with AgroMind
May 18, 2025Large Multimodal Models (LMMs) has demonstrated capabilities across various domains, but comprehensive benchmarks for agricultural remote sensing (RS) remain scarce. Existing benchmarks designed for agricultural RS scenarios exhibit notable limitations, primarily in terms of insufficient scene diversity in the dataset and oversimplified task design. To bridge this gap, we introduce AgroMind, a comprehensive agricultural remote sensing benchmark covering four task dimensions: spatial perception, object understanding, scene understanding, and scene reasoning, with a total of 13 task types, ranging from crop identification and health monitoring to environmental analysis. We curate a high-quality evaluation set by integrating eight public datasets and one private farmland plot dataset, containing 25,026 QA pairs and 15,556 images. The pipeline begins with multi-source data preprocessing, including collection, format standardization, and annotation refinement. We then generate a diverse set of agriculturally relevant questions through the systematic definition of tasks. Finally, we employ LMMs for inference, generating responses, and performing detailed examinations. We evaluated 18 open-source LMMs and 3 closed-source models on AgroMind. Experiments reveal significant performance gaps, particularly in spatial reasoning and fine-grained recognition, it is notable that human performance lags behind several leading LMMs. By establishing a standardized evaluation framework for agricultural RS, AgroMind reveals the limitations of LMMs in domain knowledge and highlights critical challenges for future work. Data and code can be accessed at https://rssysu.github.io/AgroMind/.
Evidential Graph Contrastive Alignment for Source-Free Blending-Target Domain Adaptation
Aug 14, 2024In this paper, we firstly tackle a more realistic Domain Adaptation (DA) setting: Source-Free Blending-Target Domain Adaptation (SF-BTDA), where we can not access to source domain data while facing mixed multiple target domains without any domain labels in prior. Compared to existing DA scenarios, SF-BTDA generally faces the co-existence of different label shifts in different targets, along with noisy target pseudo labels generated from the source model. In this paper, we propose a new method called Evidential Contrastive Alignment (ECA) to decouple the blending target domain and alleviate the effect from noisy target pseudo labels. First, to improve the quality of pseudo target labels, we propose a calibrated evidential learning module to iteratively improve both the accuracy and certainty of the resulting model and adaptively generate high-quality pseudo target labels. Second, we design a graph contrastive learning with the domain distance matrix and confidence-uncertainty criterion, to minimize the distribution gap of samples of a same class in the blended target domains, which alleviates the co-existence of different label shifts in blended targets. We conduct a new benchmark based on three standard DA datasets and ECA outperforms other methods with considerable gains and achieves comparable results compared with those that have domain labels or source data in prior.