 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgroTools: A Benchmark for Tool-Augmented Multimodal Agents in Agriculture
May 21, 2026Agricultural decision-making increasingly requires multimodal systems that can transform visual observations into reliable, executable actions. However, existing agricultural multimodal benchmarks mainly evaluate final-answer correctness and provide limited support for assessing whether models can use external tools to complete precision-sensitive workflows. In this paper, we introduce AgroTools, a benchmark for evaluating tool-augmented multimodal agents in agriculture. AgroTools contains 539 question-answer instances paired with 1,097 heterogeneous agricultural images, spanning five task families and an executable environment of 14 agricultural tools. Each query is annotated with structured tool-use traces, enabling a dual-view evaluation of both process-level execution quality and outcome-level task success. We benchmark 9 open-source and 4 closed-source multimodal large language models on AgroTools. Results show that current models remain far from reliable in agricultural tool-use settings, with clear bottlenecks in tool planning, argument generation, execution recovery, and final-answer synthesis. We hope AgroTools will support future research on multimodal agents for high-precision agricultural applications. The benchmark and evaluation are available at https://huggingface.co/datasets/AgroTools/AgroTools.
AgroVG: A Large-Scale Multi-Source Benchmark for Agricultural Visual Grounding
May 21, 2026Visual grounding, the task of localizing objects described by natural-language expressions, is a foundational capability for agricultural AI systems, enabling applications such as selective weeding, disease monitoring, and targeted harvesting. Reliable evaluation of agricultural visual grounding remains challenging because agricultural targets are often small, repetitive, occluded, or irregularly shaped, and instructions may refer to one, many, or no objects in an image. Evaluating this capability therefore requires jointly testing localization accuracy, target-set completeness, and existence-aware abstention. To address these challenges, we introduce \textbf{AgroVG}, a multi-source benchmark that formulates agricultural grounding as generalized set prediction: given an image and a referring expression, a model must return all matching target instances or abstain when no target is present. AgroVG contains 10{,}071 annotation-grounded image-query pairs from ten source datasets across six target families: crop/weed, fruit, wheat head, pest, plant disease, and tree canopy. It supports bounding-box grounding (T1) across all six families and instance-mask grounding (T2) on sources with reliable instance-level pixel annotations, with queries covering single-target, multi-target, and target-absent regimes. AgroVG further provides task-specific protocols for box-set matching and query-level mask coverage. Zero-shot evaluation of 26 model configurations spanning closed-source MLLMs, open-source VLMs, and specialized grounding systems reveals persistent gaps: the best multi-target Set-$F_1$ reaches only 0.35, and the best positive-query mask success rate at IoU@0.75 remains below 0.17. Data and code are available at https://anonymous.4open.science/r/AgroVG-5172/ .
GTPBD-MM: A Global Terraced Parcel and Boundary Dataset with Multi-Modality
Apr 14, 2026Agricultural parcel extraction plays an important role in remote sensing-based agricultural monitoring, supporting parcel surveying, precision management, and ecological assessment. However, existing public benchmarks mainly focus on regular and relatively flat farmland scenes. In contrast, terraced parcels in mountainous regions exhibit stepped terrain, pronounced elevation variation, irregular boundaries, and strong cross-regional heterogeneity, making parcel extraction a more challenging problem that jointly requires visual recognition, semantic discrimination, and terrain-aware geometric understanding. Although recent studies have advanced visual parcel benchmarks and image-text farmland understanding, a unified benchmark for complex terraced parcel extraction under aligned image-text-DEM settings remains absent. To fill this gap, we present GTPBD-MM, the first multimodal benchmark for global terraced parcel extraction. Built upon GTPBD, GTPBD-MM integrates high-resolution optical imagery, structured text descriptions, and DEM data, and supports systematic evaluation under Image-only, Image+Text, and Image+Text+DEM settings. We further propose Elevation and Text guided Terraced parcel network (ETTerra), a multimodal baseline for terraced parcel delineation. Extensive experiments demonstrate that textual semantics and terrain geometry provide complementary cues beyond visual appearance alone, yielding more accurate, coherent, and structurally consistent delineation results in complex terraced scenes.
HM-Bench: A Comprehensive Benchmark for Multimodal Large Language Models in Hyperspectral Remote Sensing
Apr 10, 2026While multimodal large language models (MLLMs) have made significant strides in natural image understanding, their ability to perceive and reason over hyperspectral image (HSI) remains underexplored, which is a vital modality in remote sensing. The high dimensionality and intricate spectral-spatial properties of HSI pose unique challenges for models primarily trained on RGB data.To address this gap, we introduce Hyperspectral Multimodal Benchmark (HM-Bench), the first benchmark designed specifically to evaluate MLLMs in HSI understanding. We curate a large-scale dataset of 19,337 question-answer pairs across 13 task categories, ranging from basic perception to spectral reasoning. Given that existing MLLMs are not equipped to process raw hyperspectral cubes natively, we propose a dual-modality evaluation framework that transforms HSI data into two complementary representations: PCA-based composite images and structured textual reports. This approach facilitates a systematic comparison of different representation for model performance. Extensive evaluations on 18 representative MLLMs reveal significant difficulties in handling complex spatial-spectral reasoning tasks. Furthermore, our results demonstrate that visual inputs generally outperform textual inputs, highlighting the importance of grounding in spectral-spatial evidence for effective HSI understanding. Dataset and appendix can be accessed at https://github.com/HuoRiLi-Yu/HM-Bench.
Parameter-Efficient Modality-Balanced Symmetric Fusion for Multimodal Remote Sensing Semantic Segmentation
Mar 18, 2026Multimodal remote sensing semantic segmentation enhances scene interpretation by exploiting complementary physical cues from heterogeneous data. Although pretrained Vision Foundation Models (VFMs) provide strong general-purpose representations, adapting them to multimodal tasks often incurs substantial computational overhead and is prone to modality imbalance, where the contribution of auxiliary modalities is suppressed during optimization. To address these challenges, we propose MoBaNet, a parameter-efficient and modality-balanced symmetric fusion framework. Built upon a largely frozen VFM backbone, MoBaNet adopts a symmetric dual-stream architecture to preserve generalizable representations while minimizing the number of trainable parameters. Specifically, we design a Cross-modal Prompt-Injected Adapter (CPIA) to enable deep semantic interaction by generating shared prompts and injecting them into bottleneck adapters under the frozen backbone. To obtain compact and discriminative multimodal representations for decoding, we further introduce a Difference-Guided Gated Fusion Module (DGFM), which adaptively fuses paired stage features by explicitly leveraging cross-modal discrepancy to guide feature selection. Furthermore, we propose a Modality-Conditional Random Masking (MCRM) strategy to mitigate modality imbalance by masking one modality only during training and imposing hard-pixel auxiliary supervision on modality-specific branches. Extensive experiments on the ISPRS Vaihingen and Potsdam benchmarks demonstrate that MoBaNet achieves state-of-the-art performance with significantly fewer trainable parameters than full fine-tuning, validating its effectiveness for robust and balanced multimodal fusion. The source code in this work is available at https://github.com/sauryeo/MoBaNet.
AgroNVILA: Perception-Reasoning Decoupling for Multi-view Agricultural Multimodal Large Language Models
Mar 15, 2026Agricultural multimodal reasoning requires robust spatial understanding across varying scales, from ground-level close-ups to top-down UAV and satellite imagery. Existing Multi-modal Large Language Models (MLLMs) suffer from a significant "terrestrial-centric" bias, causing scale confusion and logic drift during complex agricultural planning. To address this, we introduce the first large-scale AgroOmni (288K), a multi-view training corpus designed to capture diverse spatial topologies and scales in modern precision agriculture. Built on this dataset, we propose AgroNVILA, an MLLM that utilizes a novel Perception-Reasoning Decoupling (PRD) architecture. On the perception side, we incorporate a View-Conditioned Meta-Net (VCMN), which injects macroscopic spatial context into visual tokens, resolving scale ambiguities with minimal computational overhead. On the reasoning side, Agriculture-aware Relative Policy Optimization (ARPO) leverages reinforcement learning to align the model's decision-making with expert agricultural logic, preventing statistical shortcuts. Extensive experiments demonstrate that AgroNVILA outperforms state-of-the-art MLLMs, achieving significant improvements (+15.18%) in multi-altitude agricultural reasoning, reflecting its robust capability for holistic agricultural spatial planning.
A Comprehensive Review of Agricultural Parcel and Boundary Delineation from Remote Sensing Images: Recent Progress and Future Perspectives
Aug 20, 2025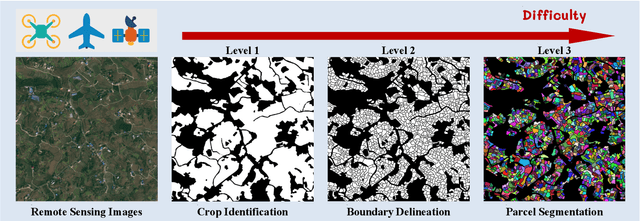
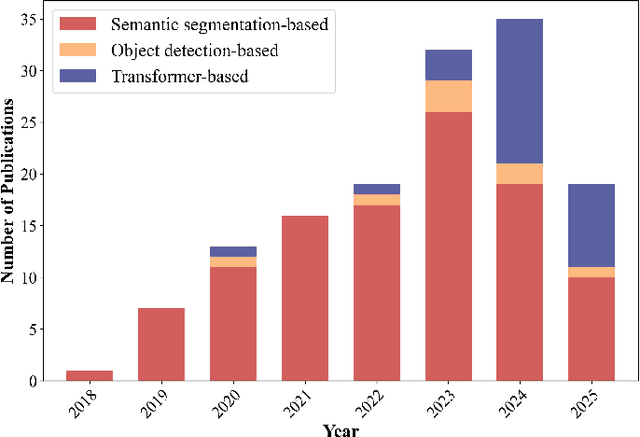
Powered by advances in multiple remote sensing sensors, the production of high spatial resolution images provides great potential to achieve cost-efficient and high-accuracy agricultural inventory and analysis in an automated way. Lots of studies that aim at providing an inventory of the level of each agricultural parcel have generated many methods for Agricultural Parcel and Boundary Delineation (APBD). This review covers APBD methods for detecting and delineating agricultural parcels and systematically reviews the past and present of APBD-related research applied to remote sensing images. With the goal to provide a clear knowledge map of existing APBD efforts, we conduct a comprehensive review of recent APBD papers to build a meta-data analysis, including the algorithm, the study site, the crop type, the sensor type, the evaluation method, etc. We categorize the methods into three classes: (1) traditional image processing methods (including pixel-based, edge-based and region-based); (2) traditional machine learning methods (such as random forest, decision tree); and (3) deep learning-based methods. With deep learning-oriented approaches contributing to a majority, we further discuss deep learning-based methods like semantic segmentation-based, object detection-based and Transformer-based methods. In addition, we discuss five APBD-related issues to further comprehend the APBD domain using remote sensing data, such as multi-sensor data in APBD task, comparisons between single-task learning and multi-task learning in the APBD domain, comparisons among different algorithms and different APBD tasks, etc. Finally, this review proposes some APBD-related applications and a few exciting prospects and potential hot topics in future APBD research. We hope this review help researchers who involved in APBD domain to keep track of its development and tendency.
Can Large Multimodal Models Understand Agricultural Scenes? Benchmarking with AgroMind
May 18, 2025Large Multimodal Models (LMMs) has demonstrated capabilities across various domains, but comprehensive benchmarks for agricultural remote sensing (RS) remain scarce. Existing benchmarks designed for agricultural RS scenarios exhibit notable limitations, primarily in terms of insufficient scene diversity in the dataset and oversimplified task design. To bridge this gap, we introduce AgroMind, a comprehensive agricultural remote sensing benchmark covering four task dimensions: spatial perception, object understanding, scene understanding, and scene reasoning, with a total of 13 task types, ranging from crop identification and health monitoring to environmental analysis. We curate a high-quality evaluation set by integrating eight public datasets and one private farmland plot dataset, containing 25,026 QA pairs and 15,556 images. The pipeline begins with multi-source data preprocessing, including collection, format standardization, and annotation refinement. We then generate a diverse set of agriculturally relevant questions through the systematic definition of tasks. Finally, we employ LMMs for inference, generating responses, and performing detailed examinations. We evaluated 18 open-source LMMs and 3 closed-source models on AgroMind. Experiments reveal significant performance gaps, particularly in spatial reasoning and fine-grained recognition, it is notable that human performance lags behind several leading LMMs. By establishing a standardized evaluation framework for agricultural RS, AgroMind reveals the limitations of LMMs in domain knowledge and highlights critical challenges for future work. Data and code can be accessed at https://rssysu.github.io/AgroMind/.
Low Saturation Confidence Distribution-based Test-Time Adaptation for Cross-Domain Remote Sensing Image Classification
Aug 29, 2024Although the Unsupervised Domain Adaptation (UDA) method has improved the effect of remote sensing image classification tasks, most of them are still limited by access to the source domain (SD) data. Designs such as Source-free Domain Adaptation (SFDA) solve the challenge of a lack of SD data, however, they still rely on a large amount of target domain data and thus cannot achieve fast adaptations, which seriously hinders their further application in broader scenarios. The real-world applications of cross-domain remote sensing image classification require a balance of speed and accuracy at the same time. Therefore, we propose a novel and comprehensive test time adaptation (TTA) method -- Low Saturation Confidence Distribution Test Time Adaptation (LSCD-TTA), which is the first attempt to solve such scenarios through the idea of TTA. LSCD-TTA specifically considers the distribution characteristics of remote sensing images, including three main parts that concentrate on different optimization directions: First, low saturation distribution (LSD) considers the dominance of low-confidence samples during the later TTA stage. Second, weak-category cross-entropy (WCCE) increases the weight of categories that are more difficult to classify with less prior knowledge. Finally, diverse categories confidence (DIV) comprehensively considers the category diversity to alleviate the deviation of the sample distribution. By weighting the abovementioned three modules, the model can widely, quickly and accurately adapt to the target domain without much prior target distributions, repeated data access, and manual annotation. We evaluate LSCD-TTA on three remote-sensing image datasets. The experimental results show that LSCD-TTA achieves a significant gain of 4.96%-10.51% with Resnet-50 and 5.33%-12.49% with Resnet-101 in average accuracy compared to other state-of-the-art DA and TTA methods.
Layered Image Vectorization via Semantic Simplification
Jun 08, 2024



This work presents a novel progressive image vectorization technique aimed at generating layered vectors that represent the original image from coarse to fine detail levels. Our approach introduces semantic simplification, which combines Score Distillation Sampling and semantic segmentation to iteratively simplify the input image. Subsequently, our method optimizes the vector layers for each of the progressively simplified images. Our method provides robust optimization, which avoids local minima and enables adjustable detail levels in the final output. The layered, compact vector representation enhances usability for further editing and modification. Comparative analysis with conventional vectorization methods demonstrates our technique's superiority in producing vectors with high visual fidelity, and more importantly, maintaining vector compactness and manageability. The project homepage is https://szuviz.github.io/layered_vectorization/.