 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHM-Bench: A Comprehensive Benchmark for Multimodal Large Language Models in Hyperspectral Remote Sensing
Apr 10, 2026While multimodal large language models (MLLMs) have made significant strides in natural image understanding, their ability to perceive and reason over hyperspectral image (HSI) remains underexplored, which is a vital modality in remote sensing. The high dimensionality and intricate spectral-spatial properties of HSI pose unique challenges for models primarily trained on RGB data.To address this gap, we introduce Hyperspectral Multimodal Benchmark (HM-Bench), the first benchmark designed specifically to evaluate MLLMs in HSI understanding. We curate a large-scale dataset of 19,337 question-answer pairs across 13 task categories, ranging from basic perception to spectral reasoning. Given that existing MLLMs are not equipped to process raw hyperspectral cubes natively, we propose a dual-modality evaluation framework that transforms HSI data into two complementary representations: PCA-based composite images and structured textual reports. This approach facilitates a systematic comparison of different representation for model performance. Extensive evaluations on 18 representative MLLMs reveal significant difficulties in handling complex spatial-spectral reasoning tasks. Furthermore, our results demonstrate that visual inputs generally outperform textual inputs, highlighting the importance of grounding in spectral-spatial evidence for effective HSI understanding. Dataset and appendix can be accessed at https://github.com/HuoRiLi-Yu/HM-Bench.
Estimating unknown parameters in differential equations with a reinforcement learning based PSO method
Nov 13, 2024



Differential equations offer a foundational yet powerful framework for modeling interactions within complex dynamic systems and are widely applied across numerous scientific fields. One common challenge in this area is estimating the unknown parameters of these dynamic relationships. However, traditional numerical optimization methods rely on the selection of initial parameter values, making them prone to local optima. Meanwhile, deep learning and Bayesian methods require training models on specific differential equations, resulting in poor versatility. This paper reformulates the parameter estimation problem of differential equations as an optimization problem by introducing the concept of particles from the particle swarm optimization algorithm. Building on reinforcement learning-based particle swarm optimization (RLLPSO), this paper proposes a novel method, DERLPSO, for estimating unknown parameters of differential equations. We compared its performance on three typical ordinary differential equations with the state-of-the-art methods, including the RLLPSO algorithm, traditional numerical methods, deep learning approaches, and Bayesian methods. The experimental results demonstrate that our DERLPSO consistently outperforms other methods in terms of performance, achieving an average Mean Square Error of 1.13e-05, which reduces the error by approximately 4 orders of magnitude compared to other methods. Apart from ordinary differential equations, our DERLPSO also show great promise for estimating unknown parameters of partial differential equations. The DERLPSO method proposed in this paper has high accuracy, is independent of initial parameter values, and possesses strong versatility and stability. This work provides new insights into unknown parameter estimation for differential equations.
Why Perturbing Symbolic Music is Necessary: Fitting the Distribution of Never-used Notes through a Joint Probabilistic Diffusion Model
Aug 04, 2024Existing music generation models are mostly language-based, neglecting the frequency continuity property of notes, resulting in inadequate fitting of rare or never-used notes and thus reducing the diversity of generated samples. We argue that the distribution of notes can be modeled by translational invariance and periodicity, especially using diffusion models to generalize notes by injecting frequency-domain Gaussian noise. However, due to the low-density nature of music symbols, estimating the distribution of notes latent in the high-density solution space poses significant challenges. To address this problem, we introduce the Music-Diff architecture, which fits a joint distribution of notes and accompanying semantic information to generate symbolic music conditionally. We first enhance the fragmentation module for extracting semantics by using event-based notations and the structural similarity index, thereby preventing boundary blurring. As a prerequisite for multivariate perturbation, we introduce a joint pre-training method to construct the progressions between notes and musical semantics while avoiding direct modeling of low-density notes. Finally, we recover the perturbed notes by a multi-branch denoiser that fits multiple noise objectives via Pareto optimization. Our experiments suggest that in contrast to language models, joint probability diffusion models perturbing at both note and semantic levels can provide more sample diversity and compositional regularity. The case study highlights the rhythmic advantages of our model over language- and DDPMs-based models by analyzing the hierarchical structure expressed in the self-similarity metrics.
More Perspectives Mean Better: Underwater Target Recognition and Localization with Multimodal Data via Symbiotic Transformer and Multiview Regression
May 22, 2023



Underwater acoustic target recognition (UATR) and localization (UATL) play important roles in marine exploration. The highly noisy acoustic signal and time-frequency interference among various sources pose big challenges to this task. To tackle these issues, we propose a multimodal approach to extract and fuse audio-visual-textual information to recognize and localize underwater targets through the designed Symbiotic Transformer (Symb-Trans) and Multi-View Regression (MVR) method. The multimodal data were first preprocessed by a custom-designed HetNorm module to normalize the multi-source data in a common feature space. The Symb-Trans module embeds audiovisual features by co-training the preprocessed multimodal features through parallel branches and a content encoder with cross-attention. The audiovisual features are then used for underwater target recognition. Meanwhile, the text embedding combined with the audiovisual features is fed to an MVR module to predict the localization of the underwater targets through multi-view clustering and multiple regression. Since no off-the-shell multimodal dataset is available for UATR and UATL, we combined multiple public datasets, consisting of acoustic, and/or visual, and/or textural data, to obtain audio-visual-textual triplets for model training and validation. Experiments show that our model outperforms comparative methods in 91.7% (11 out of 12 metrics) and 100% (4 metrics) of the quantitative metrics for the recognition and localization tasks, respectively. In a case study, we demonstrate the advantages of multi-view models in establishing sample discriminability through visualization methods. For UATL, the proposed MVR method produces the relation graphs, which allow predictions based on records of underwater targets with similar conditions.
The Power of Reuse: A Multi-Scale Transformer Model for Structural Dynamic Segmentation in Symbolic Music Generation
May 17, 2022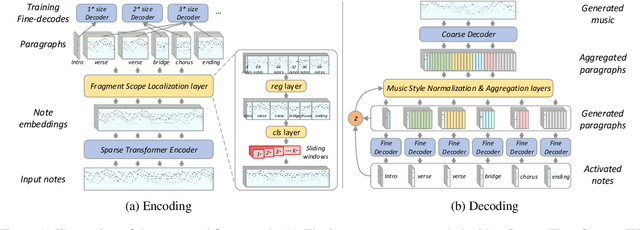
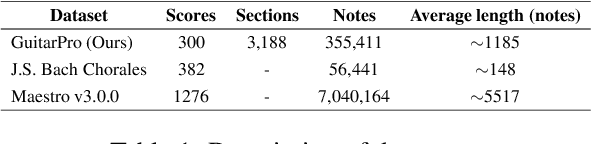
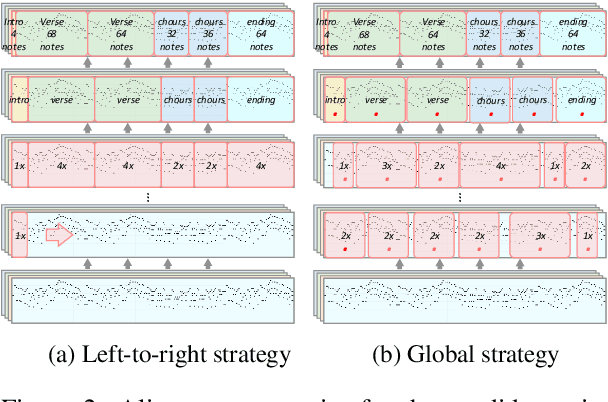
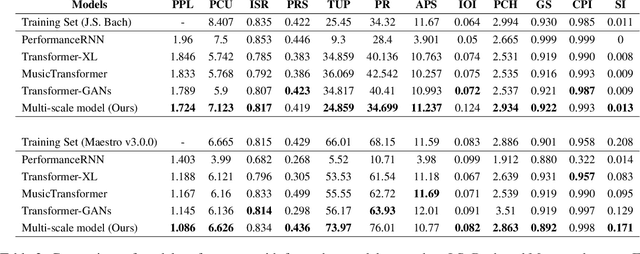
Symbolic Music Generation relies on the contextual representation capabilities of the generative model, where the most prevalent approach is the Transformer-based model. Not only that, the learning of long-term context is also related to the dynamic segmentation of musical structures, i.e. intro, verse and chorus, which is currently overlooked by the research community. In this paper, we propose a multi-scale Transformer, which uses coarse-decoder and fine-decoders to model the contexts at the global and section-level, respectively. Concretely, we designed a Fragment Scope Localization layer to syncopate the music into sections, which were later used to pre-train fine-decoders. After that, we designed a Music Style Normalization layer to transfer the style information from the original sections to the generated sections to achieve consistency in music style. The generated sections are combined in the aggregation layer and fine-tuned by the coarse decoder. Our model is evaluated on two open MIDI datasets, and experiments show that our model outperforms the best contemporary symbolic music generative models. More excitingly, visual evaluation shows that our model is superior in melody reuse, resulting in more realistic music.
Review of Machine-Learning Methods for RNA Secondary Structure Prediction
Sep 01, 2020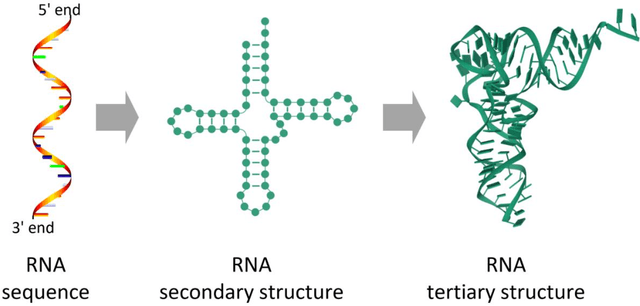
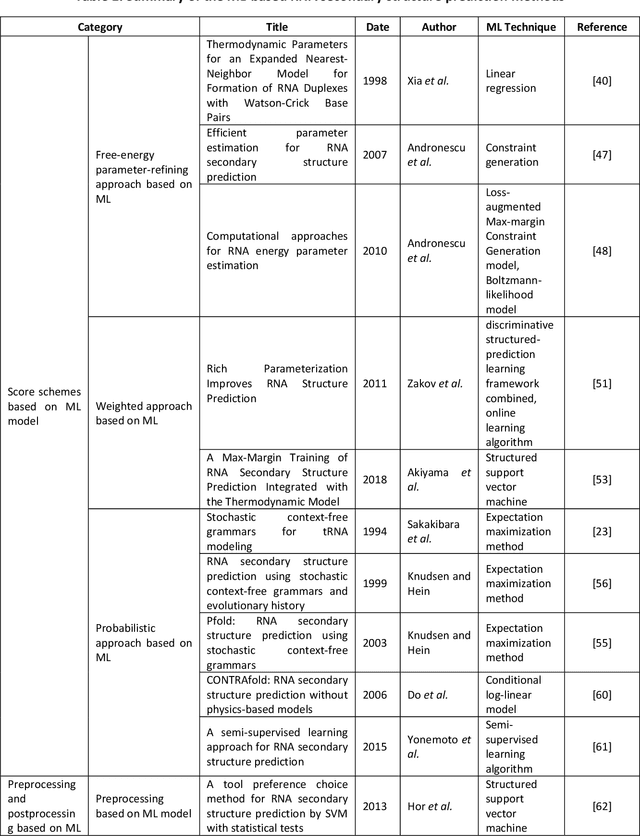
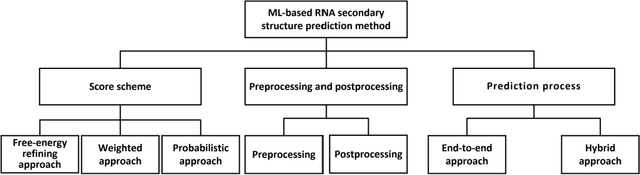
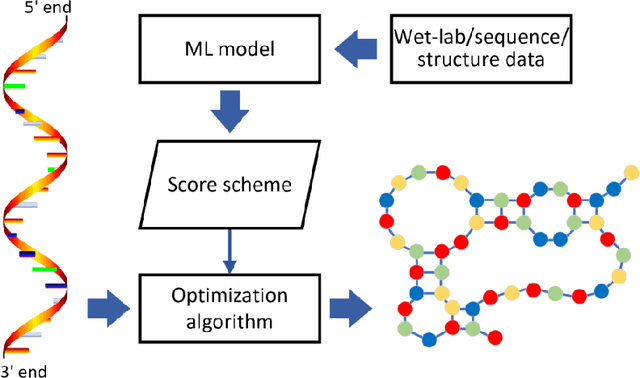
Secondary structure plays an important role in determining the function of non-coding RNAs. Hence, identifying RNA secondary structures is of great value to research. Computational prediction is a mainstream approach for predicting RNA secondary structure. Unfortunately, even though new methods have been proposed over the past 40 years, the performance of computational prediction methods has stagnated in the last decade. Recently, with the increasing availability of RNA structure data, new methods based on machine-learning technologies, especially deep learning, have alleviated the issue. In this review, we provide a comprehensive overview of RNA secondary structure prediction methods based on machine-learning technologies and a tabularized summary of the most important methods in this field. The current pending issues in the field of RNA secondary structure prediction and future trends are also discussed.