 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSketching without Worrying: Noise-Tolerant Sketch-Based Image Retrieval
Mar 28, 2022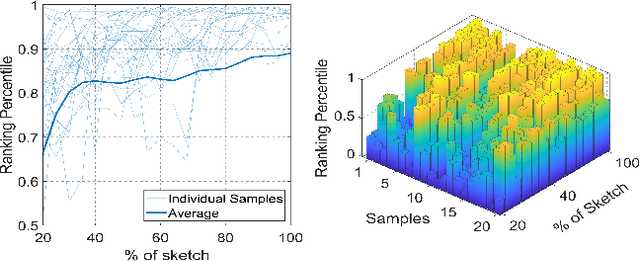
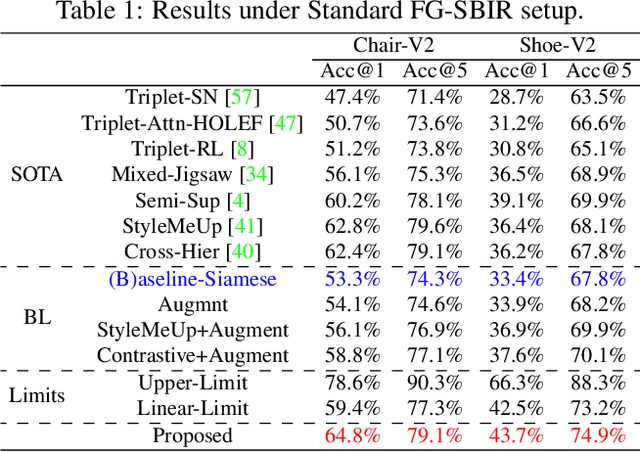
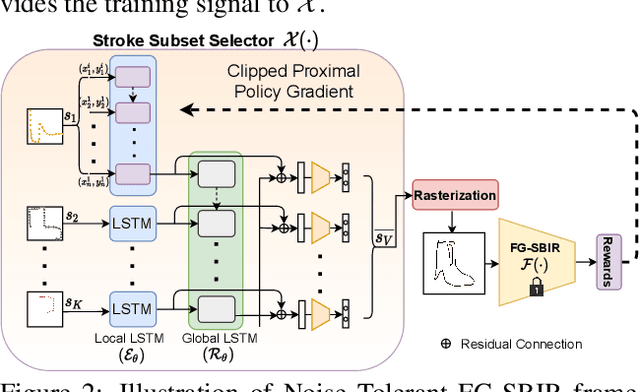
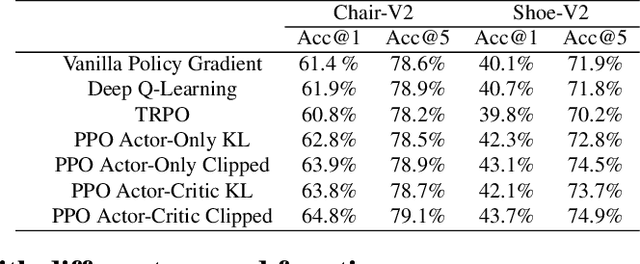
Sketching enables many exciting applications, notably, image retrieval. The fear-to-sketch problem (i.e., "I can't sketch") has however proven to be fatal for its widespread adoption. This paper tackles this "fear" head on, and for the first time, proposes an auxiliary module for existing retrieval models that predominantly lets the users sketch without having to worry. We first conducted a pilot study that revealed the secret lies in the existence of noisy strokes, but not so much of the "I can't sketch". We consequently design a stroke subset selector that {detects noisy strokes, leaving only those} which make a positive contribution towards successful retrieval. Our Reinforcement Learning based formulation quantifies the importance of each stroke present in a given subset, based on the extent to which that stroke contributes to retrieval. When combined with pre-trained retrieval models as a pre-processing module, we achieve a significant gain of 8%-10% over standard baselines and in turn report new state-of-the-art performance. Last but not least, we demonstrate the selector once trained, can also be used in a plug-and-play manner to empower various sketch applications in ways that were not previously possible.
Partially Does It: Towards Scene-Level FG-SBIR with Partial Input
Mar 28, 2022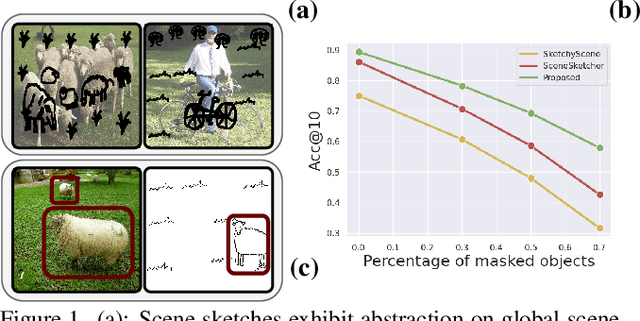
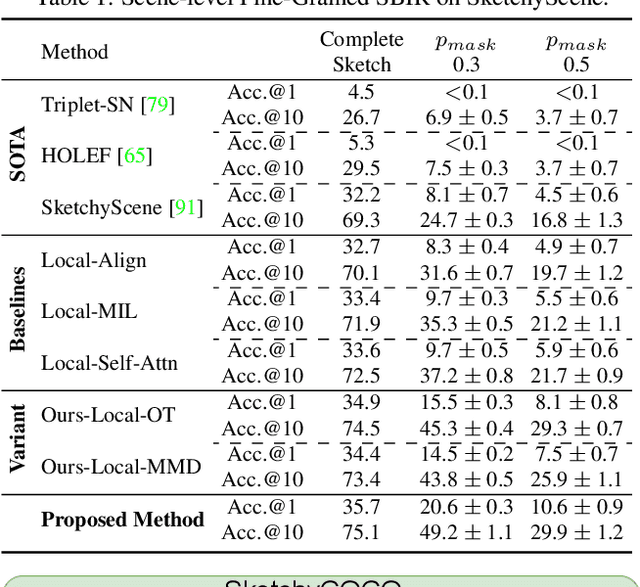
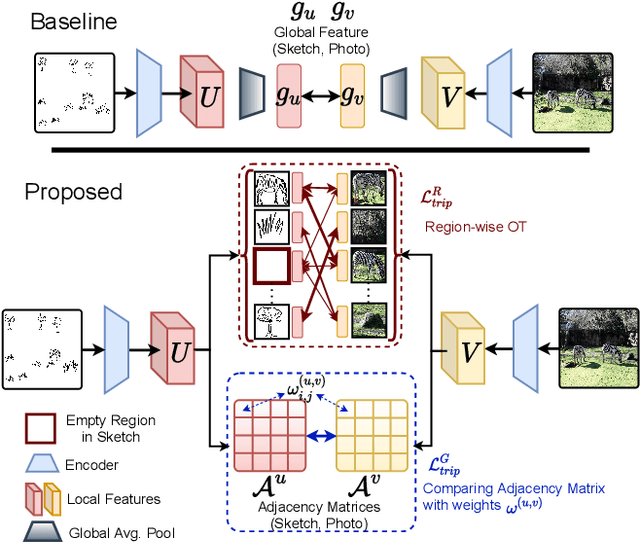
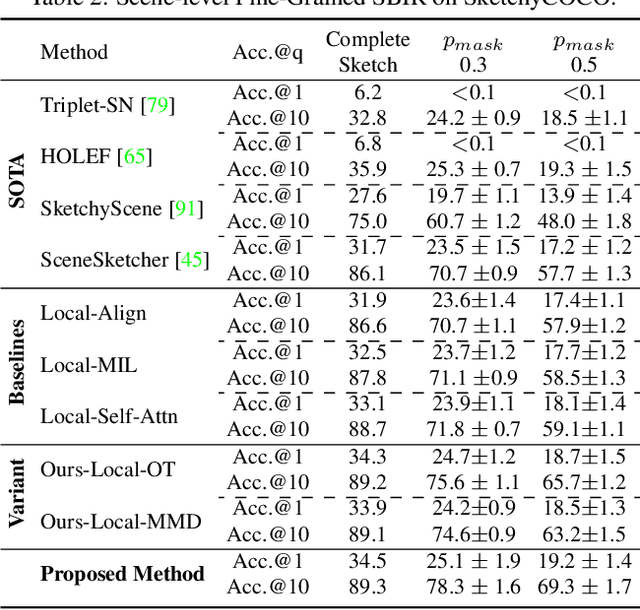
We scrutinise an important observation plaguing scene-level sketch research -- that a significant portion of scene sketches are "partial". A quick pilot study reveals: (i) a scene sketch does not necessarily contain all objects in the corresponding photo, due to the subjective holistic interpretation of scenes, (ii) there exists significant empty (white) regions as a result of object-level abstraction, and as a result, (iii) existing scene-level fine-grained sketch-based image retrieval methods collapse as scene sketches become more partial. To solve this "partial" problem, we advocate for a simple set-based approach using optimal transport (OT) to model cross-modal region associativity in a partially-aware fashion. Importantly, we improve upon OT to further account for holistic partialness by comparing intra-modal adjacency matrices. Our proposed method is not only robust to partial scene-sketches but also yields state-of-the-art performance on existing datasets.
Sketch3T: Test-Time Training for Zero-Shot SBIR
Mar 28, 2022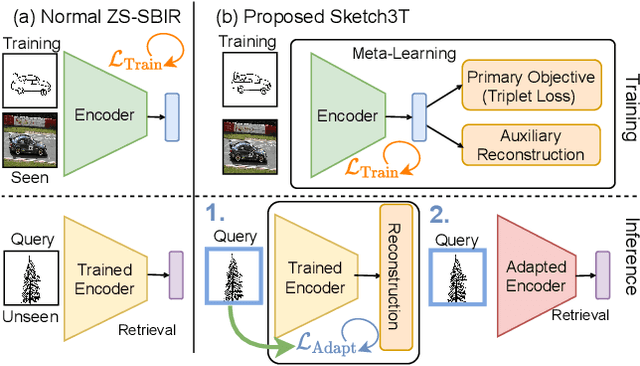
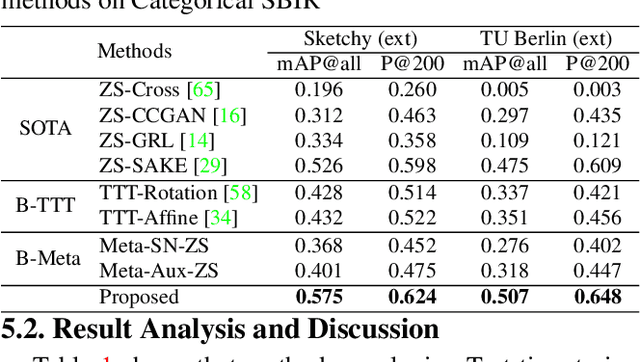
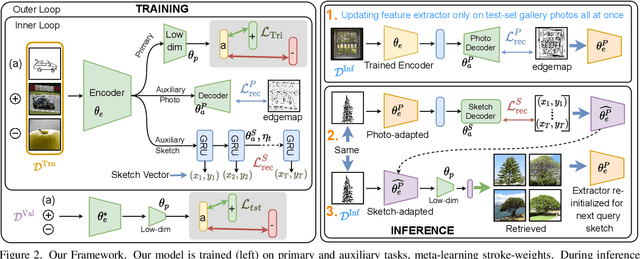
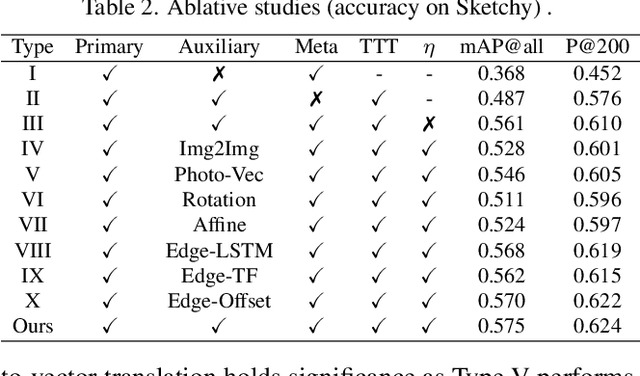
Zero-shot sketch-based image retrieval typically asks for a trained model to be applied as is to unseen categories. In this paper, we question to argue that this setup by definition is not compatible with the inherent abstract and subjective nature of sketches, i.e., the model might transfer well to new categories, but will not understand sketches existing in different test-time distribution as a result. We thus extend ZS-SBIR asking it to transfer to both categories and sketch distributions. Our key contribution is a test-time training paradigm that can adapt using just one sketch. Since there is no paired photo, we make use of a sketch raster-vector reconstruction module as a self-supervised auxiliary task. To maintain the fidelity of the trained cross-modal joint embedding during test-time update, we design a novel meta-learning based training paradigm to learn a separation between model updates incurred by this auxiliary task from those off the primary objective of discriminative learning. Extensive experiments show our model to outperform state of-the-arts, thanks to the proposed test-time adaption that not only transfers to new categories but also accommodates to new sketching styles.
FS-COCO: Towards Understanding of Freehand Sketches of Common Objects in Context
Mar 15, 2022

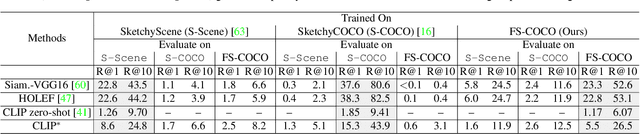
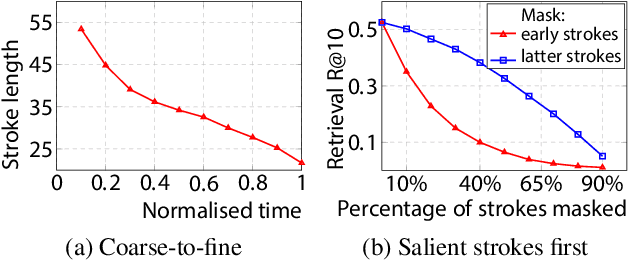
We advance sketch research to scenes with the first dataset of freehand scene sketches, FS-COCO. With practical applications in mind, we collect sketches that convey well scene content but can be sketched within a few minutes by a person with any sketching skills. Our dataset comprises 10,000 freehand scene vector sketches with per point space-time information by 100 non-expert individuals, offering both object- and scene-level abstraction. Each sketch is augmented with its text description. Using our dataset, we study for the first time the problem of the fine-grained image retrieval from freehand scene sketches and sketch captions. We draw insights on (i) Scene salience encoded in sketches with strokes temporal order; (ii) The retrieval performance accuracy from scene sketches against image captions; (iii) Complementarity of information in sketches and image captions, as well as the potential benefit of combining the two modalities. In addition, we propose new solutions enabled by our dataset (i) We adopt meta-learning to show how the retrieval model can be fine-tuned to a new user style given just a small set of sketches, (ii) We extend a popular vector sketch LSTM-based encoder to handle sketches with larger complexity than was supported by previous work. Namely, we propose a hierarchical sketch decoder, which we leverage at a sketch-specific "pretext" task. Our dataset enables for the first time research on freehand scene sketch understanding and its practical applications.
Dynamic Instance Domain Adaptation
Mar 09, 2022
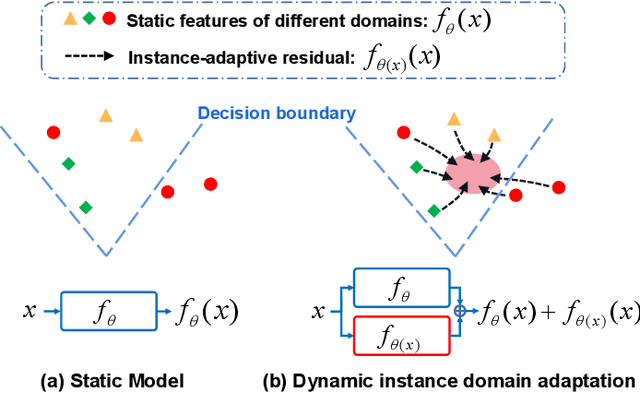
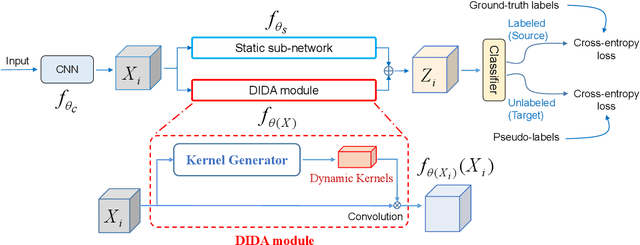
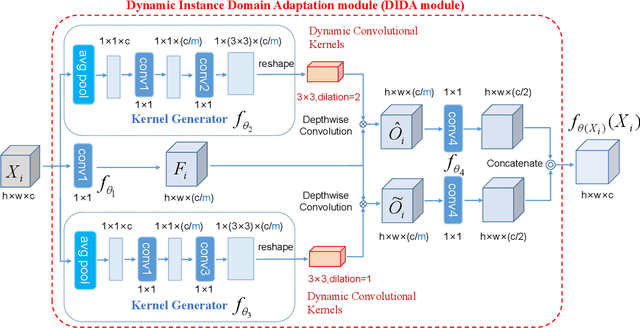
Most existing studies on unsupervised domain adaptation (UDA) assume that each domain's training samples come with domain labels (e.g., painting, photo). Samples from each domain are assumed to follow the same distribution and the domain labels are exploited to learn domain-invariant features via feature alignment. However, such an assumption often does not hold true -- there often exist numerous finer-grained domains (e.g., dozens of modern painting styles have been developed, each differing dramatically from those of the classic styles). Therefore, forcing feature distribution alignment across each artificially-defined and coarse-grained domain can be ineffective. In this paper, we address both single-source and multi-source UDA from a completely different perspective, which is to view each instance as a fine domain. Feature alignment across domains is thus redundant. Instead, we propose to perform dynamic instance domain adaptation (DIDA). Concretely, a dynamic neural network with adaptive convolutional kernels is developed to generate instance-adaptive residuals to adapt domain-agnostic deep features to each individual instance. This enables a shared classifier to be applied to both source and target domain data without relying on any domain annotation. Further, instead of imposing intricate feature alignment losses, we adopt a simple semi-supervised learning paradigm using only a cross-entropy loss for both labeled source and pseudo labeled target data. Our model, dubbed DIDA-Net, achieves state-of-the-art performance on several commonly used single-source and multi-source UDA datasets including Digits, Office-Home, DomainNet, Digit-Five, and PACS.
One Sketch for All: One-Shot Personalized Sketch Segmentation
Dec 20, 2021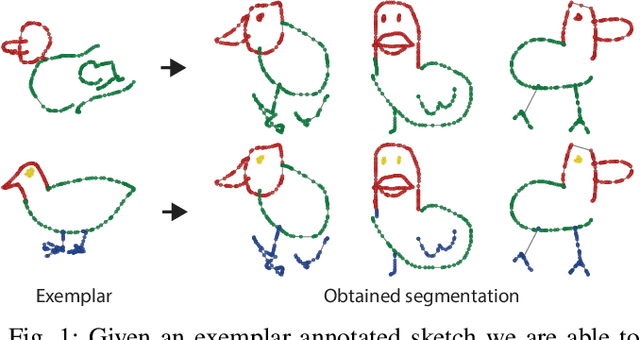
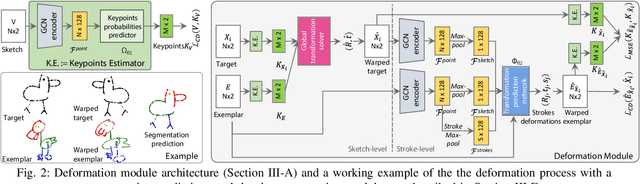
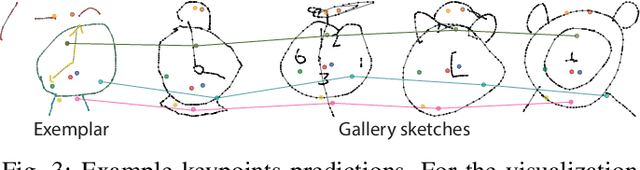

We present the first one-shot personalized sketch segmentation method. We aim to segment all sketches belonging to the same category provisioned with a single sketch with a given part annotation while (i) preserving the parts semantics embedded in the exemplar, and (ii) being robust to input style and abstraction. We refer to this scenario as personalized. With that, we importantly enable a much-desired personalization capability for downstream fine-grained sketch analysis tasks. To train a robust segmentation module, we deform the exemplar sketch to each of the available sketches of the same category. Our method generalizes to sketches not observed during training. Our central contribution is a sketch-specific hierarchical deformation network. Given a multi-level sketch-strokes encoding obtained via a graph convolutional network, our method estimates rigid-body transformation from the reference to the exemplar, on the upper level. Finer deformation from the exemplar to the globally warped reference sketch is further obtained through stroke-wise deformations, on the lower level. Both levels of deformation are guided by mean squared distances between the keypoints learned without supervision, ensuring that the stroke semantics are preserved. We evaluate our method against the state-of-the-art segmentation and perceptual grouping baselines re-purposed for the one-shot setting and against two few-shot 3D shape segmentation methods. We show that our method outperforms all the alternatives by more than 10% on average. Ablation studies further demonstrate that our method is robust to personalization: changes in input part semantics and style differences.
Hybrid Graph Neural Networks for Few-Shot Learning
Dec 13, 2021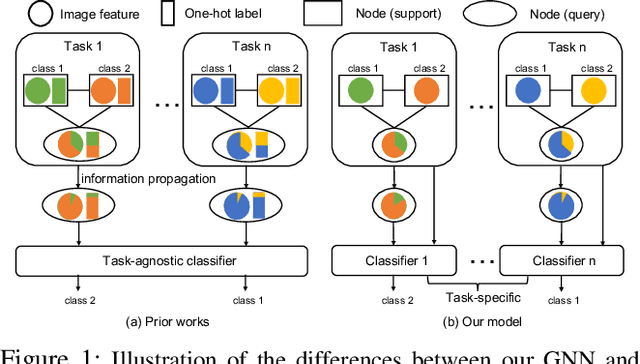
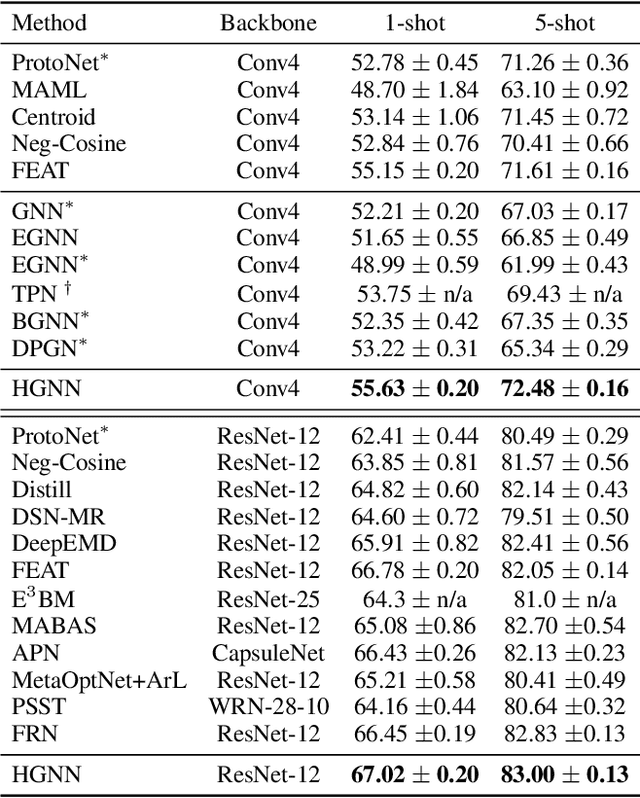
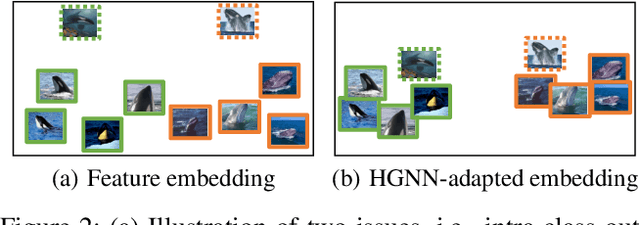
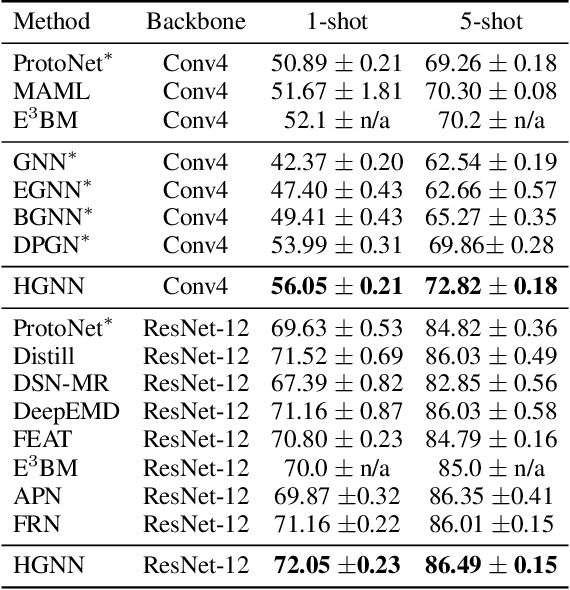
Graph neural networks (GNNs) have been used to tackle the few-shot learning (FSL) problem and shown great potentials under the transductive setting. However under the inductive setting, existing GNN based methods are less competitive. This is because they use an instance GNN as a label propagation/classification module, which is jointly meta-learned with a feature embedding network. This design is problematic because the classifier needs to adapt quickly to new tasks while the embedding does not. To overcome this problem, in this paper we propose a novel hybrid GNN (HGNN) model consisting of two GNNs, an instance GNN and a prototype GNN. Instead of label propagation, they act as feature embedding adaptation modules for quick adaptation of the meta-learned feature embedding to new tasks. Importantly they are designed to deal with a fundamental yet often neglected challenge in FSL, that is, with only a handful of shots per class, any few-shot classifier would be sensitive to badly sampled shots which are either outliers or can cause inter-class distribution overlapping. %Our two GNNs are designed to address these two types of poorly sampled few-shots respectively and their complementarity is exploited in the hybrid GNN model. Extensive experiments show that our HGNN obtains new state-of-the-art on three FSL benchmarks.
Clue Me In: Semi-Supervised FGVC with Out-of-Distribution Data
Dec 06, 2021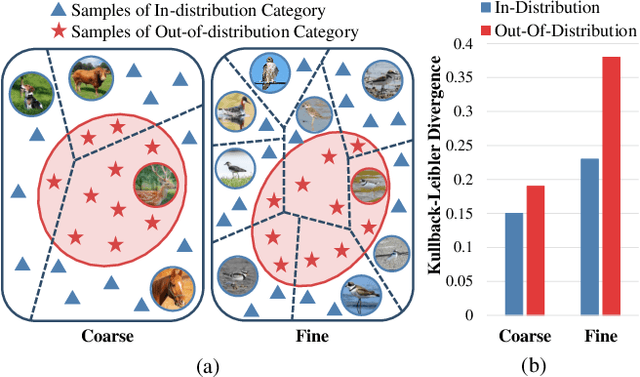
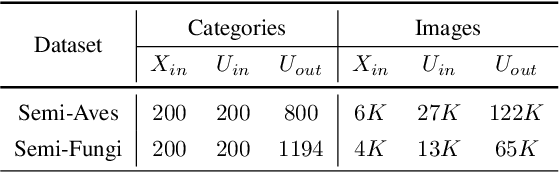
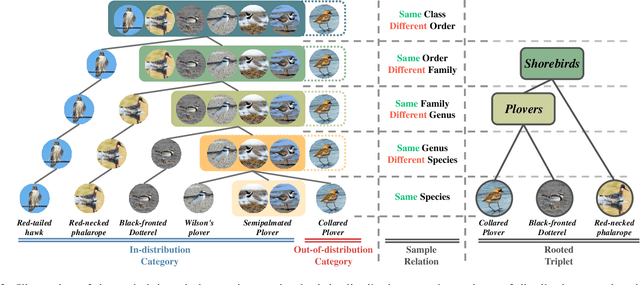
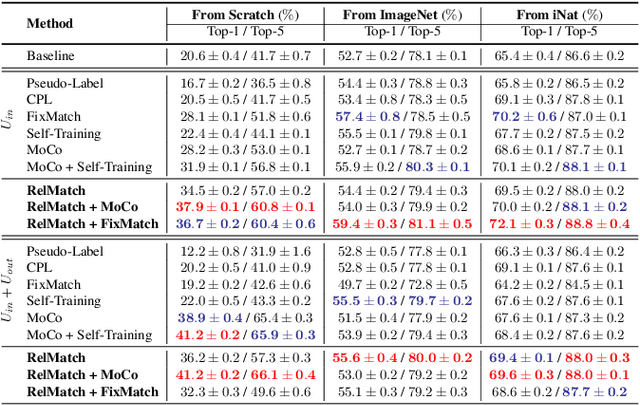
Despite great strides made on fine-grained visual classification (FGVC), current methods are still heavily reliant on fully-supervised paradigms where ample expert labels are called for. Semi-supervised learning (SSL) techniques, acquiring knowledge from unlabeled data, provide a considerable means forward and have shown great promise for coarse-grained problems. However, exiting SSL paradigms mostly assume in-distribution (i.e., category-aligned) unlabeled data, which hinders their effectiveness when re-proposed on FGVC. In this paper, we put forward a novel design specifically aimed at making out-of-distribution data work for semi-supervised FGVC, i.e., to "clue them in". We work off an important assumption that all fine-grained categories naturally follow a hierarchical structure (e.g., the phylogenetic tree of "Aves" that covers all bird species). It follows that, instead of operating on individual samples, we can instead predict sample relations within this tree structure as the optimization goal of SSL. Beyond this, we further introduced two strategies uniquely brought by these tree structures to achieve inter-sample consistency regularization and reliable pseudo-relation. Our experimental results reveal that (i) the proposed method yields good robustness against out-of-distribution data, and (ii) it can be equipped with prior arts, boosting their performance thus yielding state-of-the-art results. Code is available at https://github.com/PRIS-CV/RelMatch.
Making a Bird AI Expert Work for You and Me
Dec 06, 2021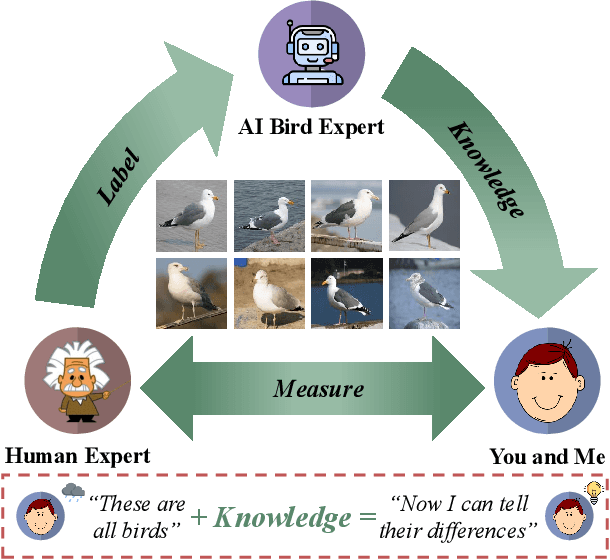



As powerful as fine-grained visual classification (FGVC) is, responding your query with a bird name of "Whip-poor-will" or "Mallard" probably does not make much sense. This however commonly accepted in the literature, underlines a fundamental question interfacing AI and human -- what constitutes transferable knowledge for human to learn from AI? This paper sets out to answer this very question using FGVC as a test bed. Specifically, we envisage a scenario where a trained FGVC model (the AI expert) functions as a knowledge provider in enabling average people (you and me) to become better domain experts ourselves, i.e. those capable in distinguishing between "Whip-poor-will" and "Mallard". Fig. 1 lays out our approach in answering this question. Assuming an AI expert trained using expert human labels, we ask (i) what is the best transferable knowledge we can extract from AI, and (ii) what is the most practical means to measure the gains in expertise given that knowledge? On the former, we propose to represent knowledge as highly discriminative visual regions that are expert-exclusive. For that, we devise a multi-stage learning framework, which starts with modelling visual attention of domain experts and novices before discriminatively distilling their differences to acquire the expert exclusive knowledge. For the latter, we simulate the evaluation process as book guide to best accommodate the learning practice of what is accustomed to humans. A comprehensive human study of 15,000 trials shows our method is able to consistently improve people of divergent bird expertise to recognise once unrecognisable birds. Interestingly, our approach also leads to improved conventional FGVC performance when the extracted knowledge defined is utilised as means to achieve discriminative localisation. Codes are available at: https://github.com/PRIS-CV/Making-a-Bird-AI-Expert-Work-for-You-and-Me
Fine-Grained Image Analysis with Deep Learning: A Survey
Nov 19, 2021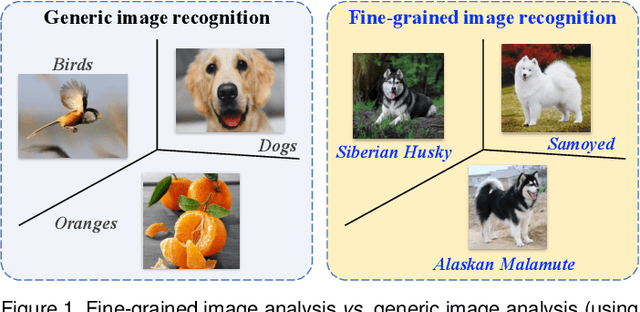
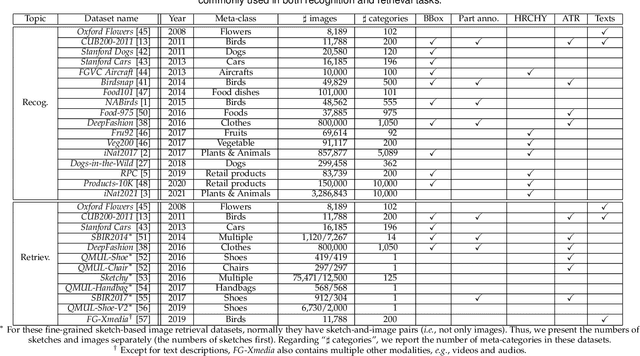
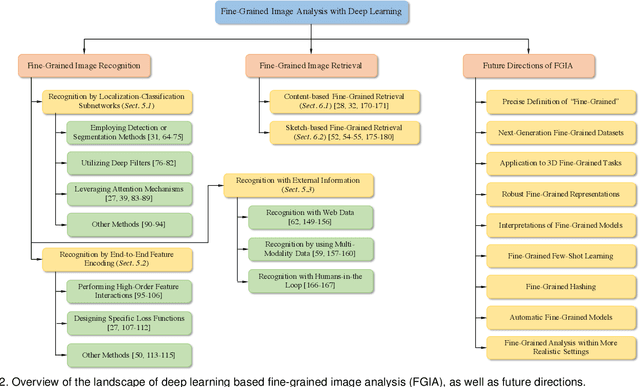
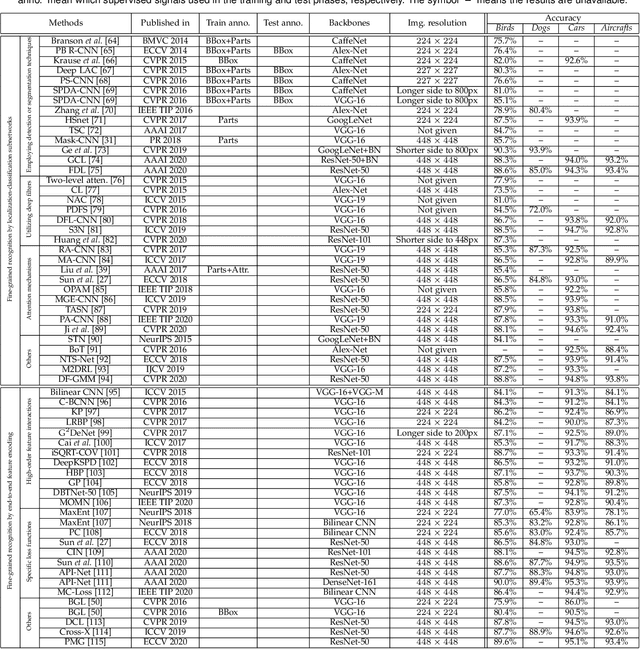
Fine-grained image analysis (FGIA) is a longstanding and fundamental problem in computer vision and pattern recognition, and underpins a diverse set of real-world applications. The task of FGIA targets analyzing visual objects from subordinate categories, e.g., species of birds or models of cars. The small inter-class and large intra-class variation inherent to fine-grained image analysis makes it a challenging problem. Capitalizing on advances in deep learning, in recent years we have witnessed remarkable progress in deep learning powered FGIA. In this paper we present a systematic survey of these advances, where we attempt to re-define and broaden the field of FGIA by consolidating two fundamental fine-grained research areas -- fine-grained image recognition and fine-grained image retrieval. In addition, we also review other key issues of FGIA, such as publicly available benchmark datasets and related domain-specific applications. We conclude by highlighting several research directions and open problems which need further exploration from the community.