 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChemEval: A Comprehensive Multi-Level Chemical Evaluation for Large Language Models
Sep 21, 2024



There is a growing interest in the role that LLMs play in chemistry which lead to an increased focus on the development of LLMs benchmarks tailored to chemical domains to assess the performance of LLMs across a spectrum of chemical tasks varying in type and complexity. However, existing benchmarks in this domain fail to adequately meet the specific requirements of chemical research professionals. To this end, we propose \textbf{\textit{ChemEval}}, which provides a comprehensive assessment of the capabilities of LLMs across a wide range of chemical domain tasks. Specifically, ChemEval identified 4 crucial progressive levels in chemistry, assessing 12 dimensions of LLMs across 42 distinct chemical tasks which are informed by open-source data and the data meticulously crafted by chemical experts, ensuring that the tasks have practical value and can effectively evaluate the capabilities of LLMs. In the experiment, we evaluate 12 mainstream LLMs on ChemEval under zero-shot and few-shot learning contexts, which included carefully selected demonstration examples and carefully designed prompts. The results show that while general LLMs like GPT-4 and Claude-3.5 excel in literature understanding and instruction following, they fall short in tasks demanding advanced chemical knowledge. Conversely, specialized LLMs exhibit enhanced chemical competencies, albeit with reduced literary comprehension. This suggests that LLMs have significant potential for enhancement when tackling sophisticated tasks in the field of chemistry. We believe our work will facilitate the exploration of their potential to drive progress in chemistry. Our benchmark and analysis will be available at {\color{blue} \url{https://github.com/USTC-StarTeam/ChemEval}}.
SX-Stitch: An Efficient VMS-UNet Based Framework for Intraoperative Scoliosis X-Ray Image Stitching
Sep 09, 2024



In scoliosis surgery, the limited field of view of the C-arm X-ray machine restricts the surgeons' holistic analysis of spinal structures .This paper presents an end-to-end efficient and robust intraoperative X-ray image stitching method for scoliosis surgery,named SX-Stitch. The method is divided into two stages:segmentation and stitching. In the segmentation stage, We propose a medical image segmentation model named Vision Mamba of Spine-UNet (VMS-UNet), which utilizes the state space Mamba to capture long-distance contextual information while maintaining linear computational complexity, and incorporates the SimAM attention mechanism, significantly improving the segmentation performance.In the stitching stage, we simplify the alignment process between images to the minimization of a registration energy function. The total energy function is then optimized to order unordered images, and a hybrid energy function is introduced to optimize the best seam, effectively eliminating parallax artifacts. On the clinical dataset, Sx-Stitch demonstrates superiority over SOTA schemes both qualitatively and quantitatively.
Community-Centric Graph Unlearning
Aug 19, 2024
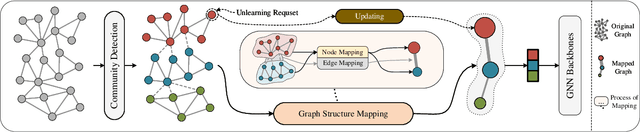
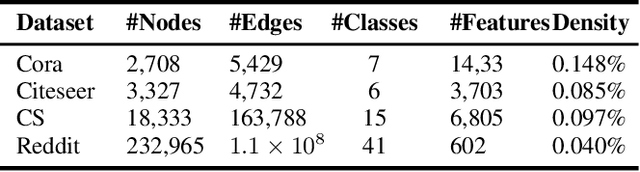
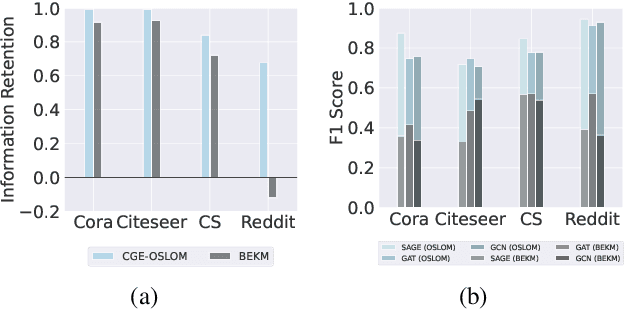
Graph unlearning technology has become increasingly important since the advent of the `right to be forgotten' and the growing concerns about the privacy and security of artificial intelligence. Graph unlearning aims to quickly eliminate the effects of specific data on graph neural networks (GNNs). However, most existing deterministic graph unlearning frameworks follow a balanced partition-submodel training-aggregation paradigm, resulting in a lack of structural information between subgraph neighborhoods and redundant unlearning parameter calculations. To address this issue, we propose a novel Graph Structure Mapping Unlearning paradigm (GSMU) and a novel method based on it named Community-centric Graph Eraser (CGE). CGE maps community subgraphs to nodes, thereby enabling the reconstruction of a node-level unlearning operation within a reduced mapped graph. CGE makes the exponential reduction of both the amount of training data and the number of unlearning parameters. Extensive experiments conducted on five real-world datasets and three widely used GNN backbones have verified the high performance and efficiency of our CGE method, highlighting its potential in the field of graph unlearning.
Optimal Sketching for Residual Error Estimation for Matrix and Vector Norms
Aug 16, 2024
We study the problem of residual error estimation for matrix and vector norms using a linear sketch. Such estimates can be used, for example, to quickly assess how useful a more expensive low-rank approximation computation will be. The matrix case concerns the Frobenius norm and the task is to approximate the $k$-residual $\|A - A_k\|_F$ of the input matrix $A$ within a $(1+\epsilon)$-factor, where $A_k$ is the optimal rank-$k$ approximation. We provide a tight bound of $\Theta(k^2/\epsilon^4)$ on the size of bilinear sketches, which have the form of a matrix product $SAT$. This improves the previous $O(k^2/\epsilon^6)$ upper bound in (Andoni et al. SODA 2013) and gives the first non-trivial lower bound, to the best of our knowledge. In our algorithm, our sketching matrices $S$ and $T$ can both be sparse matrices, allowing for a very fast update time. We demonstrate that this gives a substantial advantage empirically, for roughly the same sketch size and accuracy as in previous work. For the vector case, we consider the $\ell_p$-norm for $p>2$, where the task is to approximate the $k$-residual $\|x - x_k\|_p$ up to a constant factor, where $x_k$ is the optimal $k$-sparse approximation to $x$. Such vector norms are frequently studied in the data stream literature and are useful for finding frequent items or so-called heavy hitters. We establish an upper bound of $O(k^{2/p}n^{1-2/p}\operatorname{poly}(\log n))$ for constant $\epsilon$ on the dimension of a linear sketch for this problem. Our algorithm can be extended to the $\ell_p$ sparse recovery problem with the same sketching dimension, which seems to be the first such bound for $p > 2$. We also show an $\Omega(k^{2/p}n^{1-2/p})$ lower bound for the sparse recovery problem, which is tight up to a $\mathrm{poly}(\log n)$ factor.
Fairness and Bias Mitigation in Computer Vision: A Survey
Aug 05, 2024



Computer vision systems have witnessed rapid progress over the past two decades due to multiple advances in the field. As these systems are increasingly being deployed in high-stakes real-world applications, there is a dire need to ensure that they do not propagate or amplify any discriminatory tendencies in historical or human-curated data or inadvertently learn biases from spurious correlations. This paper presents a comprehensive survey on fairness that summarizes and sheds light on ongoing trends and successes in the context of computer vision. The topics we discuss include 1) The origin and technical definitions of fairness drawn from the wider fair machine learning literature and adjacent disciplines. 2) Work that sought to discover and analyze biases in computer vision systems. 3) A summary of methods proposed to mitigate bias in computer vision systems in recent years. 4) A comprehensive summary of resources and datasets produced by researchers to measure, analyze, and mitigate bias and enhance fairness. 5) Discussion of the field's success, continuing trends in the context of multimodal foundation and generative models, and gaps that still need to be addressed. The presented characterization should help researchers understand the importance of identifying and mitigating bias in computer vision and the state of the field and identify potential directions for future research.
Topology Optimization of Random Memristors for Input-Aware Dynamic SNN
Jul 26, 2024



There is unprecedented development in machine learning, exemplified by recent large language models and world simulators, which are artificial neural networks running on digital computers. However, they still cannot parallel human brains in terms of energy efficiency and the streamlined adaptability to inputs of different difficulties, due to differences in signal representation, optimization, run-time reconfigurability, and hardware architecture. To address these fundamental challenges, we introduce pruning optimization for input-aware dynamic memristive spiking neural network (PRIME). Signal representation-wise, PRIME employs leaky integrate-and-fire neurons to emulate the brain's inherent spiking mechanism. Drawing inspiration from the brain's structural plasticity, PRIME optimizes the topology of a random memristive spiking neural network without expensive memristor conductance fine-tuning. For runtime reconfigurability, inspired by the brain's dynamic adjustment of computational depth, PRIME employs an input-aware dynamic early stop policy to minimize latency during inference, thereby boosting energy efficiency without compromising performance. Architecture-wise, PRIME leverages memristive in-memory computing, mirroring the brain and mitigating the von Neumann bottleneck. We validated our system using a 40 nm 256 Kb memristor-based in-memory computing macro on neuromorphic image classification and image inpainting. Our results demonstrate the classification accuracy and Inception Score are comparable to the software baseline, while achieving maximal 62.50-fold improvements in energy efficiency, and maximal 77.0% computational load savings. The system also exhibits robustness against stochastic synaptic noise of analogue memristors. Our software-hardware co-designed model paves the way to future brain-inspired neuromorphic computing with brain-like energy efficiency and adaptivity.
U-learning for Prediction Inference via Combinatory Multi-Subsampling: With Applications to LASSO and Neural Networks
Jul 22, 2024



Epigenetic aging clocks play a pivotal role in estimating an individual's biological age through the examination of DNA methylation patterns at numerous CpG (Cytosine-phosphate-Guanine) sites within their genome. However, making valid inferences on predicted epigenetic ages, or more broadly, on predictions derived from high-dimensional inputs, presents challenges. We introduce a novel U-learning approach via combinatory multi-subsampling for making ensemble predictions and constructing confidence intervals for predictions of continuous outcomes when traditional asymptotic methods are not applicable. More specifically, our approach conceptualizes the ensemble estimators within the framework of generalized U-statistics and invokes the H\'ajek projection for deriving the variances of predictions and constructing confidence intervals with valid conditional coverage probabilities. We apply our approach to two commonly used predictive algorithms, Lasso and deep neural networks (DNNs), and illustrate the validity of inferences with extensive numerical studies. We have applied these methods to predict the DNA methylation age (DNAmAge) of patients with various health conditions, aiming to accurately characterize the aging process and potentially guide anti-aging interventions.
UNICAD: A Unified Approach for Attack Detection, Noise Reduction and Novel Class Identification
Jun 24, 2024



As the use of Deep Neural Networks (DNNs) becomes pervasive, their vulnerability to adversarial attacks and limitations in handling unseen classes poses significant challenges. The state-of-the-art offers discrete solutions aimed to tackle individual issues covering specific adversarial attack scenarios, classification or evolving learning. However, real-world systems need to be able to detect and recover from a wide range of adversarial attacks without sacrificing classification accuracy and to flexibly act in {\bf unseen} scenarios. In this paper, UNICAD, is proposed as a novel framework that integrates a variety of techniques to provide an adaptive solution. For the targeted image classification, UNICAD achieves accurate image classification, detects unseen classes, and recovers from adversarial attacks using Prototype and Similarity-based DNNs with denoising autoencoders. Our experiments performed on the CIFAR-10 dataset highlight UNICAD's effectiveness in adversarial mitigation and unseen class classification, outperforming traditional models.
Federated Adversarial Learning for Robust Autonomous Landing Runway Detection
Jun 22, 2024



As the development of deep learning techniques in autonomous landing systems continues to grow, one of the major challenges is trust and security in the face of possible adversarial attacks. In this paper, we propose a federated adversarial learning-based framework to detect landing runways using paired data comprising of clean local data and its adversarial version. Firstly, the local model is pre-trained on a large-scale lane detection dataset. Then, instead of exploiting large instance-adaptive models, we resort to a parameter-efficient fine-tuning method known as scale and shift deep features (SSF), upon the pre-trained model. Secondly, in each SSF layer, distributions of clean local data and its adversarial version are disentangled for accurate statistics estimation. To the best of our knowledge, this marks the first instance of federated learning work that address the adversarial sample problem in landing runway detection. Our experimental evaluations over both synthesis and real images of Landing Approach Runway Detection (LARD) dataset consistently demonstrate good performance of the proposed federated adversarial learning and robust to adversarial attacks.
* ICANN2024
PUDD: Towards Robust Multi-modal Prototype-based Deepfake Detection
Jun 22, 2024



Deepfake techniques generate highly realistic data, making it challenging for humans to discern between actual and artificially generated images. Recent advancements in deep learning-based deepfake detection methods, particularly with diffusion models, have shown remarkable progress. However, there is a growing demand for real-world applications to detect unseen individuals, deepfake techniques, and scenarios. To address this limitation, we propose a Prototype-based Unified Framework for Deepfake Detection (PUDD). PUDD offers a detection system based on similarity, comparing input data against known prototypes for video classification and identifying potential deepfakes or previously unseen classes by analyzing drops in similarity. Our extensive experiments reveal three key findings: (1) PUDD achieves an accuracy of 95.1% on Celeb-DF, outperforming state-of-the-art deepfake detection methods; (2) PUDD leverages image classification as the upstream task during training, demonstrating promising performance in both image classification and deepfake detection tasks during inference; (3) PUDD requires only 2.7 seconds for retraining on new data and emits 10$^{5}$ times less carbon compared to the state-of-the-art model, making it significantly more environmentally friendly.
* CVPR2024