 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorld Tracing: Generative Pixel-Aligned Geometry Beyond the Visible
Jun 11, 2026Image-to-3D methods often trade off faithfulness and completeness: depth estimators are anchored to input pixels but stop at the visible surface, while image-to-3D models generate complete shapes that are often misaligned with the input. We introduce World Tracing, a generative pixel-aligned geometry representation that predicts 3D points aligned with observed pixels while completing geometry beyond the visible surface. For each input pixel, World Tracing predicts an ordered stack of camera-space 3D points, where the first layer represents the visible surface and subsequent layers represent front-to-back intersections with occluded surfaces. We instantiate this representation with a world-tracing diffusion transformer, WT-DiT, which treats multiple geometry layers as separate denoising tokens coupled through factorized and global attention. WT-DiT is trained with pixel-space flow matching and a mixed noise schedule that balances visible-surface reconstruction with occluded-geometry generation. World Tracing achieves strong performance on visible-surface reconstruction and complete geometry generation across object, scene, and dynamic benchmarks, outperforming both depth predictors and image-to-3D generators. It also preserves 2D-to-3D correspondence, enabling text-driven 3D scene editing, geometry-conditioned novel-view video synthesis, and training-free integration with textured-mesh generators.
OS-SPEAR: A Toolkit for the Safety, Performance,Efficiency, and Robustness Analysis of OS Agents
Apr 27, 2026The evolution of Multimodal Large Language Models (MLLMs) has shifted the focus from text generation to active behavioral execution, particularly via OS agents navigating complex GUIs. However, the transition of these agents into trustworthy daily partners is hindered by a lack of rigorous evaluation regarding safety, efficiency, and multi-modal robustness. Current benchmarks suffer from narrow safety scenarios, noisy trajectory labeling, and limited robustness metrics. To bridge this gap, we propose OS-SPEAR, a comprehensive toolkit for the systematic analysis of OS agents across four dimensions: Safety, Performance, Efficiency, and Robustness. OS-SPEAR introduces four specialized subsets: (1) a S(afety)-subset encompassing diverse environment- and human-induced hazards; (2) a P(erformance)-subset curated via trajectory value estimation and stratified sampling; (3) an E(fficiency)-subset quantifying performance through the dual lenses of temporal latency and token consumption; and (4) a R(obustness)-subset that applies cross-modal disturbances to both visual and textual inputs. Additionally, we provide an automated analysis tool to generate human-readable diagnostic reports. We conduct an extensive evaluation of 22 popular OS agents using OS-SPEAR. Our empirical results reveal critical insights into the current landscape: notably, a prevalent trade-off between efficiency and safety or robustness, the performance superiority of specialized agents over general-purpose models, and varying robustness vulnerabilities across different modalities. By providing a multidimensional ranking and a standardized evaluation framework, OS-SPEAR offers a foundational resource for developing the next generation of reliable and efficient OS agents. The dataset and codes are available at https://github.com/Wuzheng02/OS-SPEAR.
Watch Out Your Album! On the Inadvertent Privacy Memorization in Multi-Modal Large Language Models
Mar 03, 2025Multi-Modal Large Language Models (MLLMs) have exhibited remarkable performance on various vision-language tasks such as Visual Question Answering (VQA). Despite accumulating evidence of privacy concerns associated with task-relevant content, it remains unclear whether MLLMs inadvertently memorize private content that is entirely irrelevant to the training tasks. In this paper, we investigate how randomly generated task-irrelevant private content can become spuriously correlated with downstream objectives due to partial mini-batch training dynamics, thus causing inadvertent memorization. Concretely, we randomly generate task-irrelevant watermarks into VQA fine-tuning images at varying probabilities and propose a novel probing framework to determine whether MLLMs have inadvertently encoded such content. Our experiments reveal that MLLMs exhibit notably different training behaviors in partial mini-batch settings with task-irrelevant watermarks embedded. Furthermore, through layer-wise probing, we demonstrate that MLLMs trigger distinct representational patterns when encountering previously seen task-irrelevant knowledge, even if this knowledge does not influence their output during prompting. Our code is available at https://github.com/illusionhi/ProbingPrivacy.
fNeRF: High Quality Radiance Fields from Practical Cameras
Jun 15, 2024



In recent years, the development of Neural Radiance Fields has enabled a previously unseen level of photo-realistic 3D reconstruction of scenes and objects from multi-view camera data. However, previous methods use an oversimplified pinhole camera model resulting in defocus blur being `baked' into the reconstructed radiance field. We propose a modification to the ray casting that leverages the optics of lenses to enhance scene reconstruction in the presence of defocus blur. This allows us to improve the quality of radiance field reconstructions from the measurements of a practical camera with finite aperture. We show that the proposed model matches the defocus blur behavior of practical cameras more closely than pinhole models and other approximations of defocus blur models, particularly in the presence of partial occlusions. This allows us to achieve sharper reconstructions, improving the PSNR on validation of all-in-focus images, on both synthetic and real datasets, by up to 3 dB.
Angle Sensitive Pixels for Lensless Imaging on Spherical Sensors
Jun 28, 2023We propose OrbCam, a lensless architecture for imaging with spherical sensors. Prior work in lensless imager techniques have focused largely on using planar sensors; for such designs, it is important to use a modulation element, e.g. amplitude or phase masks, to construct a invertible imaging system. In contrast, we show that the diversity of pixel orientations on a curved surface is sufficient to improve the conditioning of the mapping between the scene and the sensor. Hence, when imaging on a spherical sensor, all pixels can have the same angular response function such that the lensless imager is comprised of pixels that are identical to each other and differ only in their orientations. We provide the computational tools for the design of the angular response of the pixels in a spherical sensor that leads to well-conditioned and noise-robust measurements. We validate our design in both simulation and a lab prototype. The implications of our design is that the lensless imaging can be enabled easily for curved and flexible surfaces thereby opening up a new set of application domains.
A Simple Framework for 3D Lensless Imaging with Programmable Masks
Aug 18, 2021
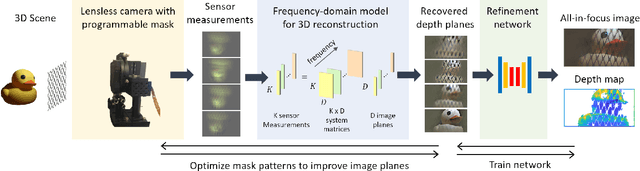
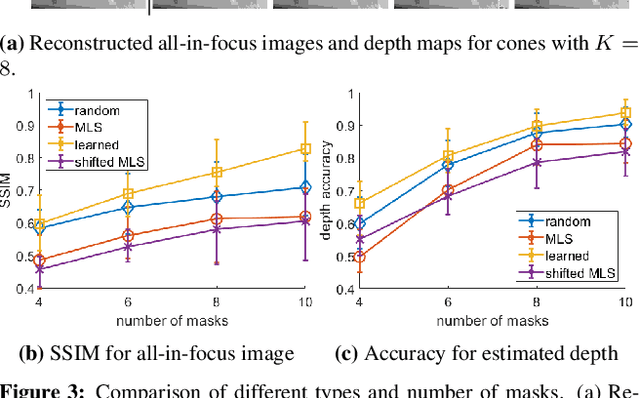

Lensless cameras provide a framework to build thin imaging systems by replacing the lens in a conventional camera with an amplitude or phase mask near the sensor. Existing methods for lensless imaging can recover the depth and intensity of the scene, but they require solving computationally-expensive inverse problems. Furthermore, existing methods struggle to recover dense scenes with large depth variations. In this paper, we propose a lensless imaging system that captures a small number of measurements using different patterns on a programmable mask. In this context, we make three contributions. First, we present a fast recovery algorithm to recover textures on a fixed number of depth planes in the scene. Second, we consider the mask design problem, for programmable lensless cameras, and provide a design template for optimizing the mask patterns with the goal of improving depth estimation. Third, we use a refinement network as a post-processing step to identify and remove artifacts in the reconstruction. These modifications are evaluated extensively with experimental results on a lensless camera prototype to showcase the performance benefits of the optimized masks and recovery algorithms over the state of the art.
* Supplementary material available at https://github.com/CSIPlab/Programmable3Dcam.git