 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAROM Air -- Vehicle Localization and Traffic Scene Reconstruction from Aerial Videos
May 31, 2023Road traffic scene reconstruction from videos has been desirable by road safety regulators, city planners, researchers, and autonomous driving technology developers. However, it is expensive and unnecessary to cover every mile of the road with cameras mounted on the road infrastructure. This paper presents a method that can process aerial videos to vehicle trajectory data so that a traffic scene can be automatically reconstructed and accurately re-simulated using computers. On average, the vehicle localization error is about 0.1 m to 0.3 m using a consumer-grade drone flying at 120 meters. This project also compiles a dataset of 50 reconstructed road traffic scenes from about 100 hours of aerial videos to enable various downstream traffic analysis applications and facilitate further road traffic related research. The dataset is available at https://github.com/duolu/CAROM.
Attributing Image Generative Models using Latent Fingerprints
Apr 17, 2023



Generative models have enabled the creation of contents that are indistinguishable from those taken from the nature. Open-source development of such models raised concerns about the risks in their misuse for malicious purposes. One potential risk mitigation strategy is to attribute generative models via fingerprinting. Current fingerprinting methods exhibit significant tradeoff between robust attribution accuracy and generation quality, and also lack designing principles to improve this tradeoff. This paper investigates the use of latent semantic dimensions as fingerprints, from where we can analyze the effects of design variables, including the choice of fingerprinting dimensions, strength, and capacity, on the accuracy-quality tradeoff. Compared with previous SOTA, our method requires minimum computation and is more applicable to large-scale models. We use StyleGAN2 and the latent diffusion model to demonstrate the efficacy of our method.
Mole Recruitment: Poisoning of Image Classifiers via Selective Batch Sampling
Mar 30, 2023



In this work, we present a data poisoning attack that confounds machine learning models without any manipulation of the image or label. This is achieved by simply leveraging the most confounding natural samples found within the training data itself, in a new form of a targeted attack coined "Mole Recruitment." We define moles as the training samples of a class that appear most similar to samples of another class, and show that simply restructuring training batches with an optimal number of moles can lead to significant degradation in the performance of the targeted class. We show the efficacy of this novel attack in an offline setting across several standard image classification datasets, and demonstrate the real-world viability of this attack in a continual learning (CL) setting. Our analysis reveals that state-of-the-art models are susceptible to Mole Recruitment, thereby exposing a previously undetected vulnerability of image classifiers.
Benchmarking Spatial Relationships in Text-to-Image Generation
Dec 20, 2022



Spatial understanding is a fundamental aspect of computer vision and integral for human-level reasoning about images, making it an important component for grounded language understanding. While recent large-scale text-to-image synthesis (T2I) models have shown unprecedented improvements in photorealism, it is unclear whether they have reliable spatial understanding capabilities. We investigate the ability of T2I models to generate correct spatial relationships among objects and present VISOR, an evaluation metric that captures how accurately the spatial relationship described in text is generated in the image. To benchmark existing models, we introduce a large-scale challenge dataset SR2D that contains sentences describing two objects and the spatial relationship between them. We construct and harness an automated evaluation pipeline that employs computer vision to recognize objects and their spatial relationships, and we employ it in a large-scale evaluation of T2I models. Our experiments reveal a surprising finding that, although recent state-of-the-art T2I models exhibit high image quality, they are severely limited in their ability to generate multiple objects or the specified spatial relations such as left/right/above/below. Our analyses demonstrate several biases and artifacts of T2I models such as the difficulty with generating multiple objects, a bias towards generating the first object mentioned, spatially inconsistent outputs for equivalent relationships, and a correlation between object co-occurrence and spatial understanding capabilities. We conduct a human study that shows the alignment between VISOR and human judgment about spatial understanding. We offer the SR2D dataset and the VISOR metric to the community in support of T2I spatial reasoning research.
Learning Action-Effect Dynamics from Pairs of Scene-graphs
Dec 07, 2022



'Actions' play a vital role in how humans interact with the world. Thus, autonomous agents that would assist us in everyday tasks also require the capability to perform 'Reasoning about Actions & Change' (RAC). Recently, there has been growing interest in the study of RAC with visual and linguistic inputs. Graphs are often used to represent semantic structure of the visual content (i.e. objects, their attributes and relationships among objects), commonly referred to as scene-graphs. In this work, we propose a novel method that leverages scene-graph representation of images to reason about the effects of actions described in natural language. We experiment with existing CLEVR_HYP (Sampat et. al, 2021) dataset and show that our proposed approach is effective in terms of performance, data efficiency, and generalization capability compared to existing models.
Learning Action-Effect Dynamics for Hypothetical Vision-Language Reasoning Task
Dec 07, 2022



'Actions' play a vital role in how humans interact with the world. Thus, autonomous agents that would assist us in everyday tasks also require the capability to perform 'Reasoning about Actions & Change' (RAC). This has been an important research direction in Artificial Intelligence (AI) in general, but the study of RAC with visual and linguistic inputs is relatively recent. The CLEVR_HYP (Sampat et. al., 2021) is one such testbed for hypothetical vision-language reasoning with actions as the key focus. In this work, we propose a novel learning strategy that can improve reasoning about the effects of actions. We implement an encoder-decoder architecture to learn the representation of actions as vectors. We combine the aforementioned encoder-decoder architecture with existing modality parsers and a scene graph question answering model to evaluate our proposed system on the CLEVR_HYP dataset. We conduct thorough experiments to demonstrate the effectiveness of our proposed approach and discuss its advantages over previous baselines in terms of performance, data efficiency, and generalization capability.
CRIPP-VQA: Counterfactual Reasoning about Implicit Physical Properties via Video Question Answering
Nov 07, 2022



Videos often capture objects, their visible properties, their motion, and the interactions between different objects. Objects also have physical properties such as mass, which the imaging pipeline is unable to directly capture. However, these properties can be estimated by utilizing cues from relative object motion and the dynamics introduced by collisions. In this paper, we introduce CRIPP-VQA, a new video question answering dataset for reasoning about the implicit physical properties of objects in a scene. CRIPP-VQA contains videos of objects in motion, annotated with questions that involve counterfactual reasoning about the effect of actions, questions about planning in order to reach a goal, and descriptive questions about visible properties of objects. The CRIPP-VQA test set enables evaluation under several out-of-distribution settings -- videos with objects with masses, coefficients of friction, and initial velocities that are not observed in the training distribution. Our experiments reveal a surprising and significant performance gap in terms of answering questions about implicit properties (the focus of this paper) and explicit properties of objects (the focus of prior work).
Reasoning about Actions over Visual and Linguistic Modalities: A Survey
Jul 15, 2022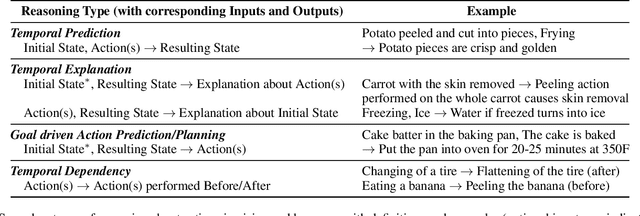


'Actions' play a vital role in how humans interact with the world and enable them to achieve desired goals. As a result, most common sense (CS) knowledge for humans revolves around actions. While 'Reasoning about Actions & Change' (RAC) has been widely studied in the Knowledge Representation community, it has recently piqued the interest of NLP and computer vision researchers. This paper surveys existing tasks, benchmark datasets, various techniques and models, and their respective performance concerning advancements in RAC in the vision and language domain. Towards the end, we summarize our key takeaways, discuss the present challenges facing this research area, and outline potential directions for future research.
Formalizing and Evaluating Requirements of Perception Systems for Automated Vehicles using Spatio-Temporal Perception Logic
Jun 29, 2022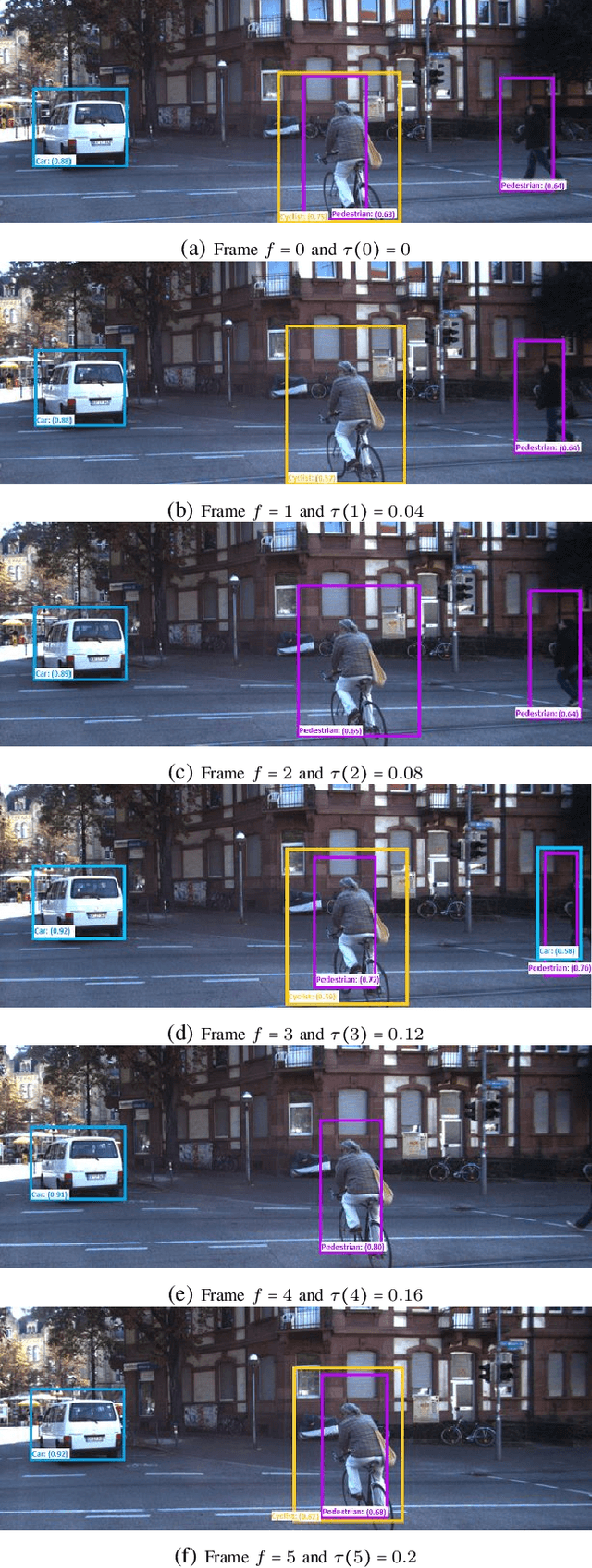


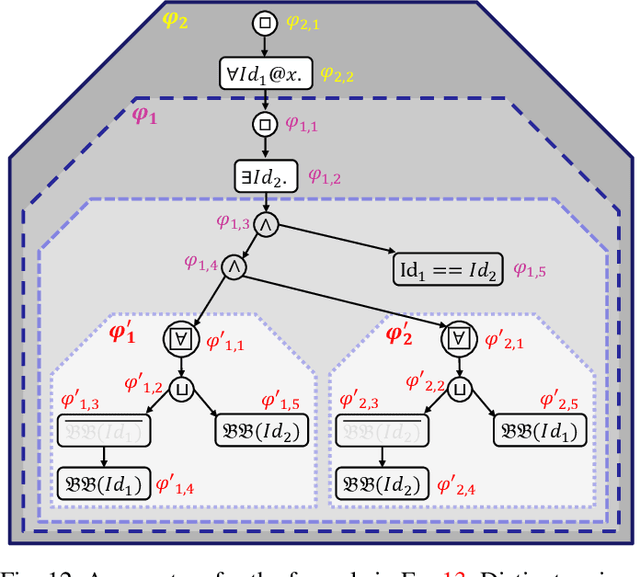
Automated vehicles (AV) heavily depend on robust perception systems. Current methods for evaluating vision systems focus mainly on frame-by-frame performance. Such evaluation methods appear to be inadequate in assessing the performance of a perception subsystem when used within an AV. In this paper, we present a logic -- referred to as Spatio-Temporal Perception Logic (STPL) -- which utilizes both spatial and temporal modalities. STPL enables reasoning over perception data using spatial and temporal relations. One major advantage of STPL is that it facilitates basic sanity checks on the real-time performance of the perception system, even without ground-truth data in some cases. We identify a fragment of STPL which is efficiently monitorable offline in polynomial time. Finally, we present a range of specifications for AV perception systems to highlight the types of requirements that can be expressed and analyzed through offline monitoring with STPL.
Improving Diversity with Adversarially Learned Transformations for Domain Generalization
Jun 15, 2022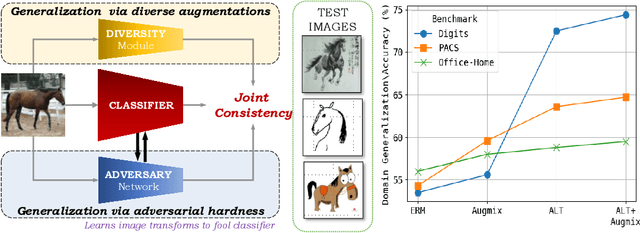
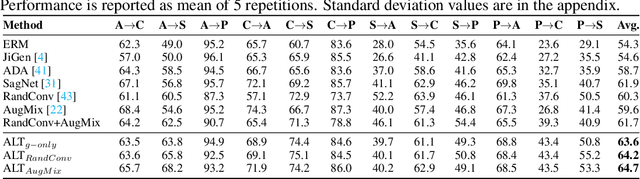
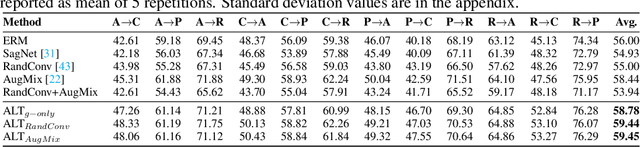
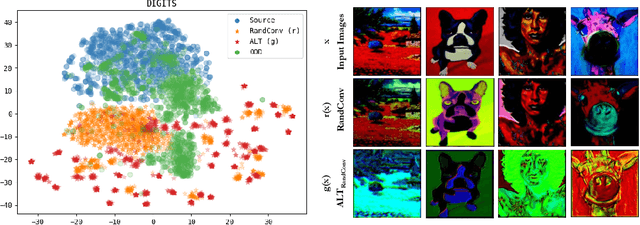
To be successful in single source domain generalization, maximizing diversity of synthesized domains has emerged as one of the most effective strategies. Many of the recent successes have come from methods that pre-specify the types of diversity that a model is exposed to during training, so that it can ultimately generalize well to new domains. However, na\"ive diversity based augmentations do not work effectively for domain generalization either because they cannot model large domain shift, or because the span of transforms that are pre-specified do not cover the types of shift commonly occurring in domain generalization. To address this issue, we present a novel framework that uses adversarially learned transformations (ALT) using a neural network to model plausible, yet hard image transformations that fool the classifier. This network is randomly initialized for each batch and trained for a fixed number of steps to maximize classification error. Further, we enforce consistency between the classifier's predictions on the clean and transformed images. With extensive empirical analysis, we find that this new form of adversarial transformations achieve both objectives of diversity and hardness simultaneously, outperforming all existing techniques on competitive benchmarks for single source domain generalization. We also show that ALT can naturally work with existing diversity modules to produce highly distinct, and large transformations of the source domain leading to state-of-the-art performance.