 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInternal Language Model Adaptation with Text-Only Data for End-to-End Speech Recognition
Oct 14, 2021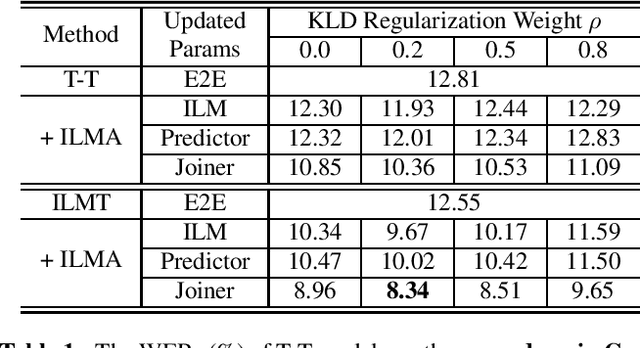
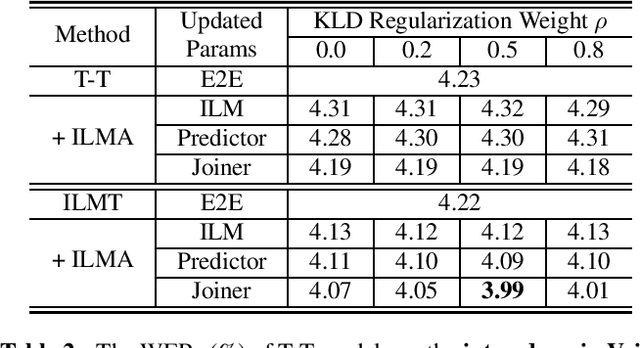
Text-only adaptation of an end-to-end (E2E) model remains a challenging task for automatic speech recognition (ASR). Language model (LM) fusion-based approaches require an additional external LM during inference, significantly increasing the computation cost. To overcome this, we propose an internal LM adaptation (ILMA) of the E2E model using text-only data. Trained with audio-transcript pairs, an E2E model implicitly learns an internal LM that characterizes the token sequence probability which is approximated by the E2E model output after zeroing out the encoder contribution. During ILMA, we fine-tune the internal LM, i.e., the E2E components excluding the encoder, to minimize a cross-entropy loss. To make ILMA effective, it is essential to train the E2E model with an internal LM loss besides the standard E2E loss. Furthermore, we propose to regularize ILMA by minimizing the Kullback-Leibler divergence between the output distributions of the adapted and unadapted internal LMs. ILMA is the most effective when we update only the last linear layer of the joint network. ILMA enables a fast text-only adaptation of the E2E model without increasing the run-time computational cost. Experimented with 30K-hour trained transformer transducer models, ILMA achieves up to 34.9% relative word error rate reduction from the unadapted baseline.
Transcribe-to-Diarize: Neural Speaker Diarization for Unlimited Number of Speakers using End-to-End Speaker-Attributed ASR
Oct 07, 2021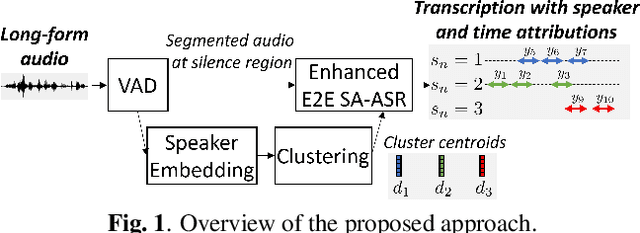
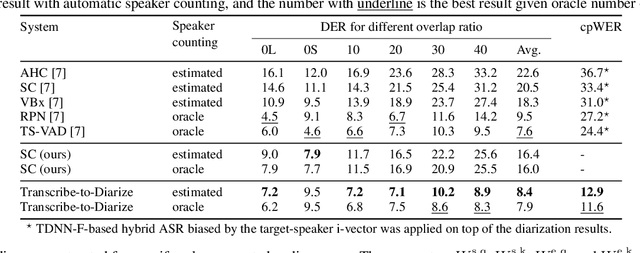
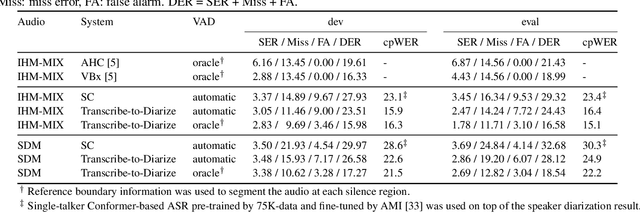
This paper presents Transcribe-to-Diarize, a new approach for neural speaker diarization that uses an end-to-end (E2E) speaker-attributed automatic speech recognition (SA-ASR). The E2E SA-ASR is a joint model that was recently proposed for speaker counting, multi-talker speech recognition, and speaker identification from monaural audio that contains overlapping speech. Although the E2E SA-ASR model originally does not estimate any time-related information, we show that the start and end times of each word can be estimated with sufficient accuracy from the internal state of the E2E SA-ASR by adding a small number of learnable parameters. Similar to the target-speaker voice activity detection (TS-VAD)-based diarization method, the E2E SA-ASR model is applied to estimate speech activity of each speaker while it has the advantages of (i) handling unlimited number of speakers, (ii) leveraging linguistic information for speaker diarization, and (iii) simultaneously generating speaker-attributed transcriptions. Experimental results on the LibriCSS and AMI corpora show that the proposed method achieves significantly better diarization error rate than various existing speaker diarization methods when the number of speakers is unknown, and achieves a comparable performance to TS-VAD when the number of speakers is given in advance. The proposed method simultaneously generates speaker-attributed transcription with state-of-the-art accuracy.
Continuous Streaming Multi-Talker ASR with Dual-path Transducers
Sep 17, 2021

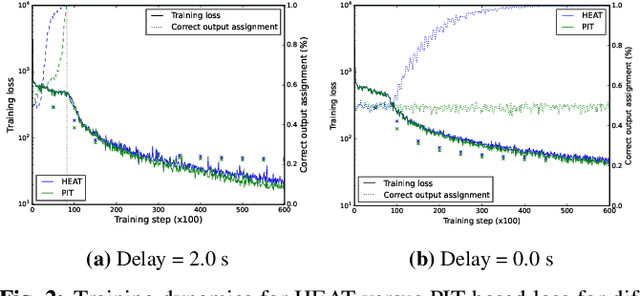
Streaming recognition of multi-talker conversations has so far been evaluated only for 2-speaker single-turn sessions. In this paper, we investigate it for multi-turn meetings containing multiple speakers using the Streaming Unmixing and Recognition Transducer (SURT) model, and show that naively extending the single-turn model to this harder setting incurs a performance penalty. As a solution, we propose the dual-path (DP) modeling strategy first used for time-domain speech separation. We experiment with LSTM and Transformer based DP models, and show that they improve word error rate (WER) performance while yielding faster convergence. We also explore training strategies such as chunk width randomization and curriculum learning for these models, and demonstrate their importance through ablation studies. Finally, we evaluate our models on the LibriCSS meeting data, where they perform competitively with offline separation-based methods.
A Comparative Study of Modular and Joint Approaches for Speaker-Attributed ASR on Monaural Long-Form Audio
Jul 06, 2021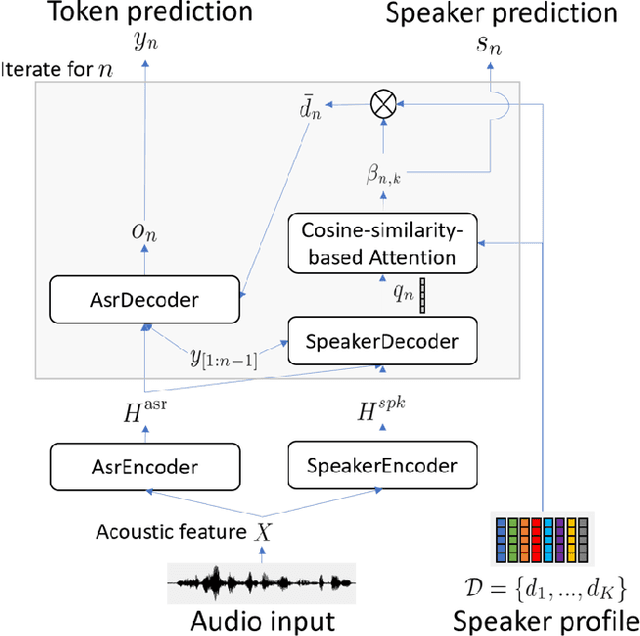
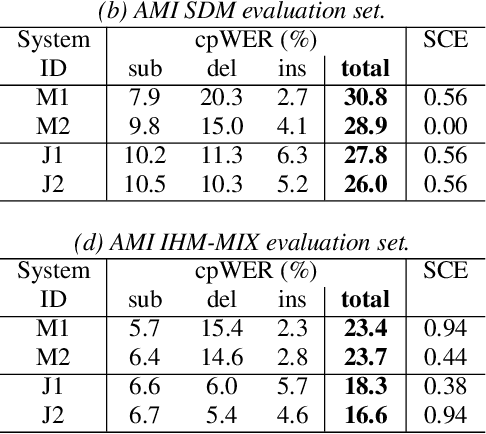
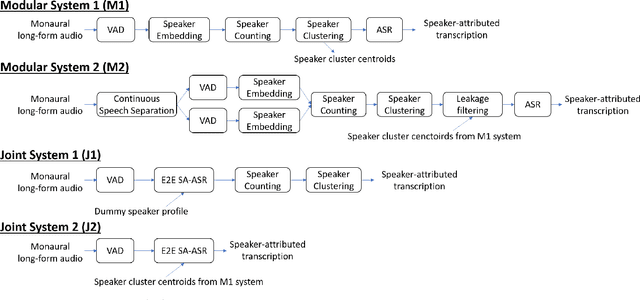
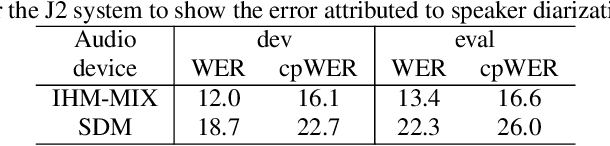
Speaker-attributed automatic speech recognition (SA-ASR) is a task to recognize "who spoke what" from multi-talker recordings. An SA-ASR system usually consists of multiple modules such as speech separation, speaker diarization and ASR. On the other hand, considering the joint optimization, an end-to-end (E2E) SA-ASR model has recently been proposed with promising results on simulation data. In this paper, we present our recent study on the comparison of such modular and joint approaches towards SA-ASR on real monaural recordings. We develop state-of-the-art SA-ASR systems for both modular and joint approaches by leveraging large-scale training data, including 75 thousand hours of ASR training data and the VoxCeleb corpus for speaker representation learning. We also propose a new pipeline that performs the E2E SA-ASR model after speaker clustering. Our evaluation on the AMI meeting corpus reveals that after fine-tuning with a small real data, the joint system performs 9.2--29.4% better in accuracy compared to the best modular system while the modular system performs better before such fine-tuning. We also conduct various error analyses to show the remaining issues for the monaural SA-ASR.
Dynamic Gradient Aggregation for Federated Domain Adaptation
Jun 14, 2021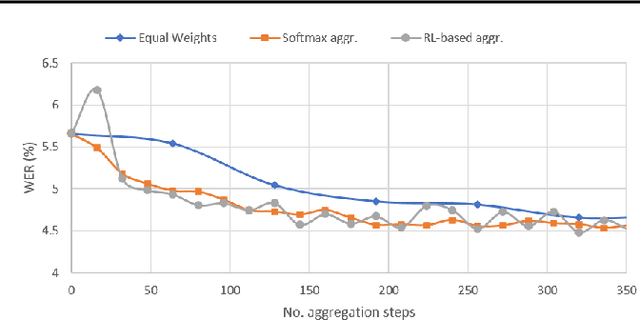
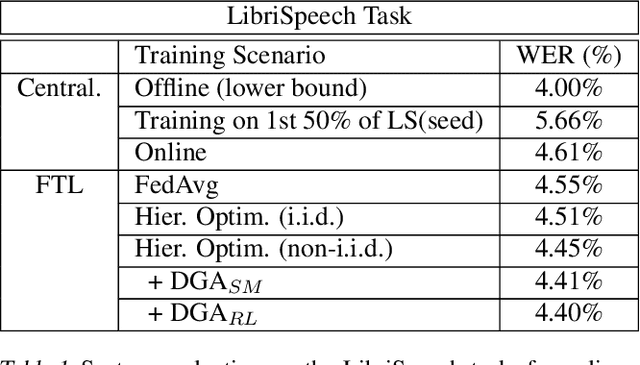
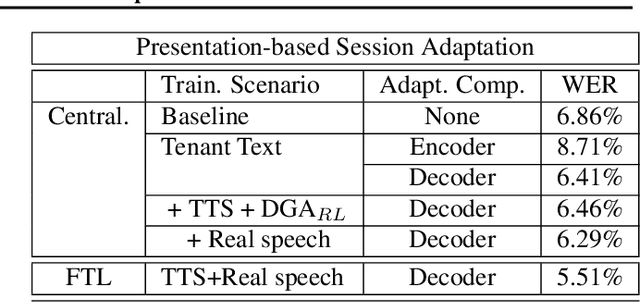
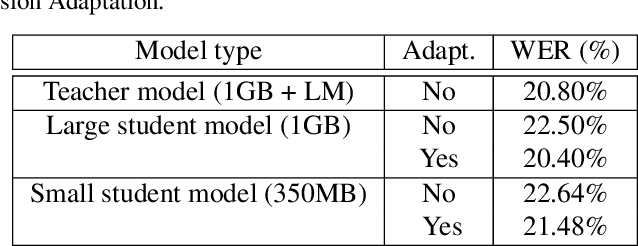
In this paper, a new learning algorithm for Federated Learning (FL) is introduced. The proposed scheme is based on a weighted gradient aggregation using two-step optimization to offer a flexible training pipeline. Herein, two different flavors of the aggregation method are presented, leading to an order of magnitude improvement in convergence speed compared to other distributed or FL training algorithms like BMUF and FedAvg. Further, the aggregation algorithm acts as a regularizer of the gradient quality. We investigate the effect of our FL algorithm in supervised and unsupervised Speech Recognition (SR) scenarios. The experimental validation is performed based on three tasks: first, the LibriSpeech task showing a speed-up of 7x and 6% word error rate reduction (WERR) compared to the baseline results. The second task is based on session adaptation providing 20% WERR over a powerful LAS model. Finally, our unsupervised pipeline is applied to the conversational SR task. The proposed FL system outperforms the baseline systems in both convergence speed and overall model performance.
Large-Scale Pre-Training of End-to-End Multi-Talker ASR for Meeting Transcription with Single Distant Microphone
Apr 12, 2021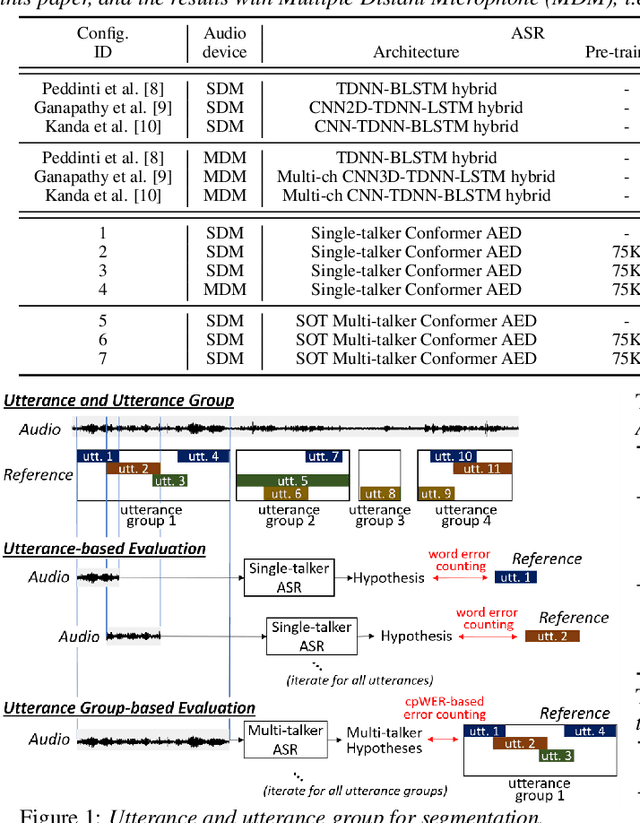


Transcribing meetings containing overlapped speech with only a single distant microphone (SDM) has been one of the most challenging problems for automatic speech recognition (ASR). While various approaches have been proposed, all previous studies on the monaural overlapped speech recognition problem were based on either simulation data or small-scale real data. In this paper, we extensively investigate a two-step approach where we first pre-train a serialized output training (SOT)-based multi-talker ASR by using large-scale simulation data and then fine-tune the model with a small amount of real meeting data. Experiments are conducted by utilizing 75 thousand (K) hours of our internal single-talker recording to simulate a total of 900K hours of multi-talker audio segments for supervised pre-training. With fine-tuning on the 70 hours of the AMI-SDM training data, our SOT ASR model achieves a word error rate (WER) of 21.2% for the AMI-SDM evaluation set while automatically counting speakers in each test segment. This result is not only significantly better than the previous state-of-the-art WER of 36.4% with oracle utterance boundary information but also better than a result by a similarly fine-tuned single-talker ASR model applied to beamformed audio.
End-to-End Speaker-Attributed ASR with Transformer
Apr 05, 2021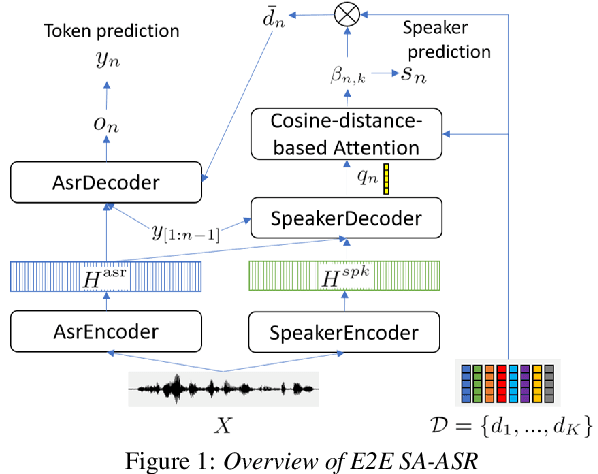
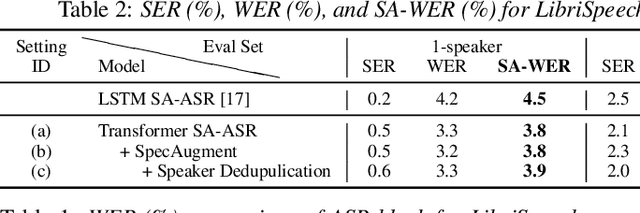
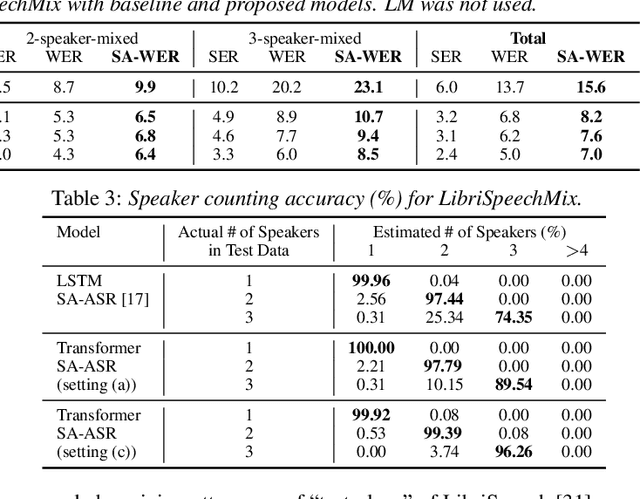
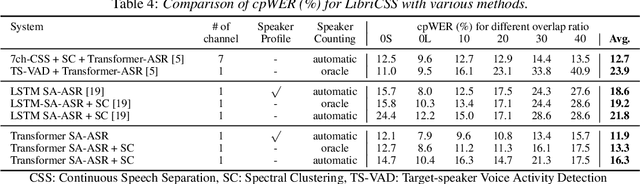
This paper presents our recent effort on end-to-end speaker-attributed automatic speech recognition, which jointly performs speaker counting, speech recognition and speaker identification for monaural multi-talker audio. Firstly, we thoroughly update the model architecture that was previously designed based on a long short-term memory (LSTM)-based attention encoder decoder by applying transformer architectures. Secondly, we propose a speaker deduplication mechanism to reduce speaker identification errors in highly overlapped regions. Experimental results on the LibriSpeechMix dataset shows that the transformer-based architecture is especially good at counting the speakers and that the proposed model reduces the speaker-attributed word error rate by 47% over the LSTM-based baseline. Furthermore, for the LibriCSS dataset, which consists of real recordings of overlapped speech, the proposed model achieves concatenated minimum-permutation word error rates of 11.9% and 16.3% with and without target speaker profiles, respectively, both of which are the state-of-the-art results for LibriCSS with the monaural setting.
Internal Language Model Training for Domain-Adaptive End-to-End Speech Recognition
Feb 02, 2021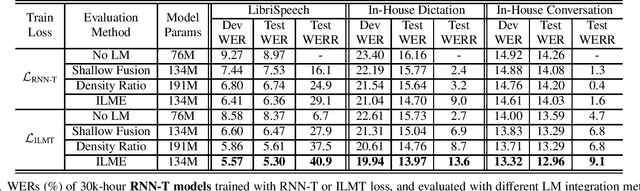
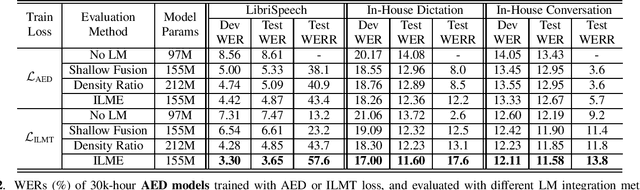
The efficacy of external language model (LM) integration with existing end-to-end (E2E) automatic speech recognition (ASR) systems can be improved significantly using the internal language model estimation (ILME) method. In this method, the internal LM score is subtracted from the score obtained by interpolating the E2E score with the external LM score, during inference. To improve the ILME-based inference, we propose an internal LM training (ILMT) method to minimize an additional internal LM loss by updating only the E2E model components that affect the internal LM estimation. ILMT encourages the E2E model to form a standalone LM inside its existing components, without sacrificing ASR accuracy. After ILMT, the more modular E2E model with matched training and inference criteria enables a more thorough elimination of the source-domain internal LM, and therefore leads to a more effective integration of the target-domain external LM. Experimented with 30K-hour trained recurrent neural network transducer and attention-based encoder-decoder models, ILMT with ILME-based inference achieves up to 31.5% and 11.4% relative word error rate reductions from standard E2E training with Shallow Fusion on out-of-domain LibriSpeech and in-domain Microsoft production test sets, respectively.
* 5 pages, ICASSP 2021
Hypothesis Stitcher for End-to-End Speaker-attributed ASR on Long-form Multi-talker Recordings
Jan 06, 2021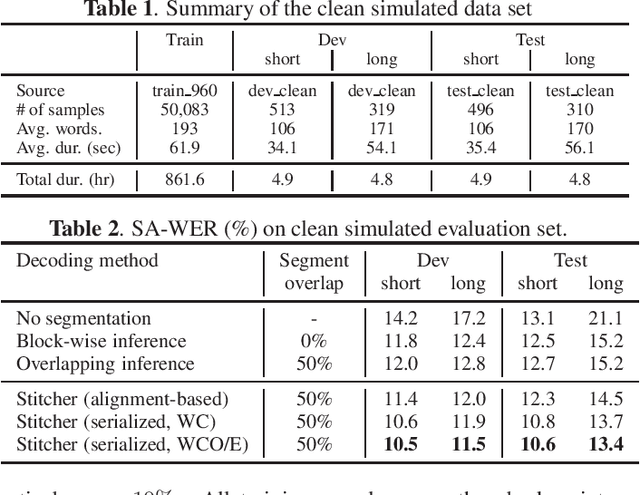
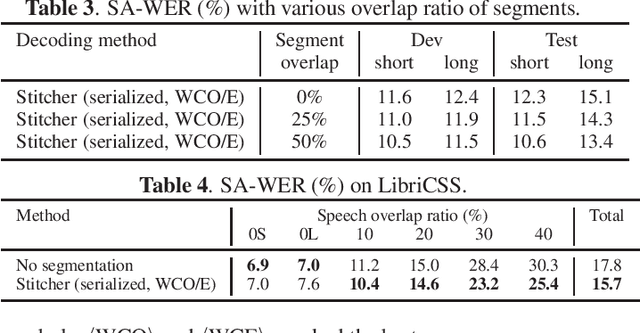
An end-to-end (E2E) speaker-attributed automatic speech recognition (SA-ASR) model was proposed recently to jointly perform speaker counting, speech recognition and speaker identification. The model achieved a low speaker-attributed word error rate (SA-WER) for monaural overlapped speech comprising an unknown number of speakers. However, the E2E modeling approach is susceptible to the mismatch between the training and testing conditions. It has yet to be investigated whether the E2E SA-ASR model works well for recordings that are much longer than samples seen during training. In this work, we first apply a known decoding technique that was developed to perform single-speaker ASR for long-form audio to our E2E SA-ASR task. Then, we propose a novel method using a sequence-to-sequence model, called hypothesis stitcher. The model takes multiple hypotheses obtained from short audio segments that are extracted from the original long-form input, and it then outputs a fused single hypothesis. We propose several architectural variations of the hypothesis stitcher model and compare them with the conventional decoding methods. Experiments using LibriSpeech and LibriCSS corpora show that the proposed method significantly improves SA-WER especially for long-form multi-talker recordings.
Minimum Bayes Risk Training for End-to-End Speaker-Attributed ASR
Nov 03, 2020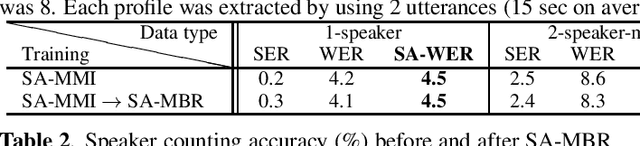
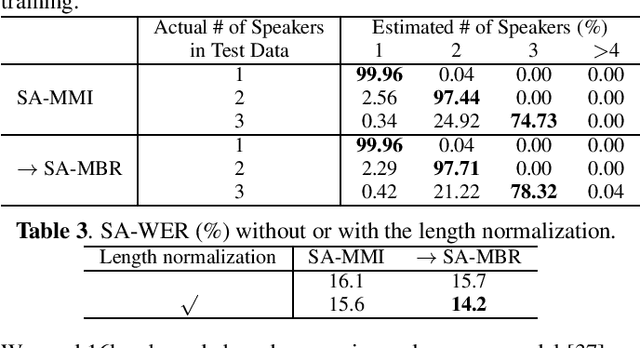
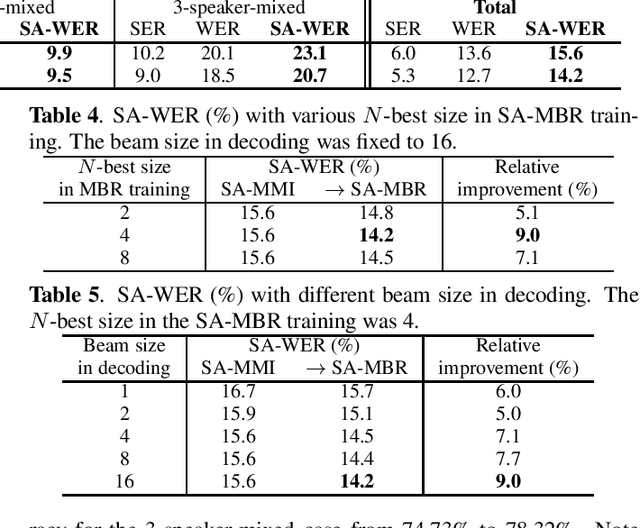
Recently, an end-to-end speaker-attributed automatic speech recognition (E2E SA-ASR) model was proposed as a joint model of speaker counting, speech recognition and speaker identification for monaural overlapped speech. In the previous study, the model parameters were trained based on the speaker-attributed maximum mutual information (SA-MMI) criterion, with which the joint posterior probability for multi-talker transcription and speaker identification are maximized over training data. Although SA-MMI training showed promising results for overlapped speech consisting of various numbers of speakers, the training criterion was not directly linked to the final evaluation metric, i.e., speaker-attributed word error rate (SA-WER). In this paper, we propose a speaker-attributed minimum Bayes risk (SA-MBR) training method where the parameters are trained to directly minimize the expected SA-WER over the training data. Experiments using the LibriSpeech corpus show that the proposed SA-MBR training reduces the SA-WER by 9.0 % relative compared with the SA-MMI-trained model.