 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Learning Inverts the Data Generating Process
Feb 17, 2021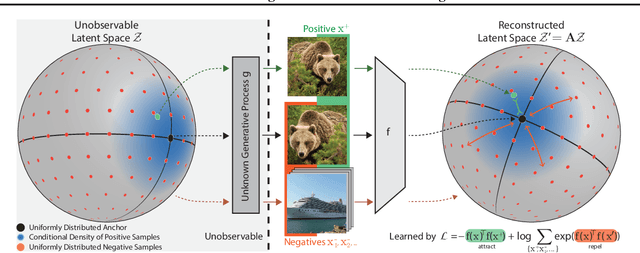
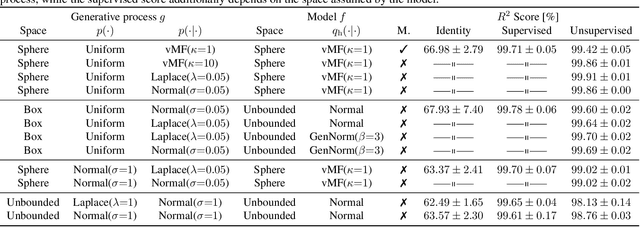
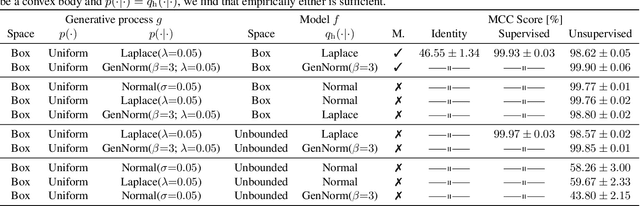

Contrastive learning has recently seen tremendous success in self-supervised learning. So far, however, it is largely unclear why the learned representations generalize so effectively to a large variety of downstream tasks. We here prove that feedforward models trained with objectives belonging to the commonly used InfoNCE family learn to implicitly invert the underlying generative model of the observed data. While the proofs make certain statistical assumptions about the generative model, we observe empirically that our findings hold even if these assumptions are severely violated. Our theory highlights a fundamental connection between contrastive learning, generative modeling, and nonlinear independent component analysis, thereby furthering our understanding of the learned representations as well as providing a theoretical foundation to derive more effective contrastive losses.
Improving Low Resource Code-switched ASR using Augmented Code-switched TTS
Oct 12, 2020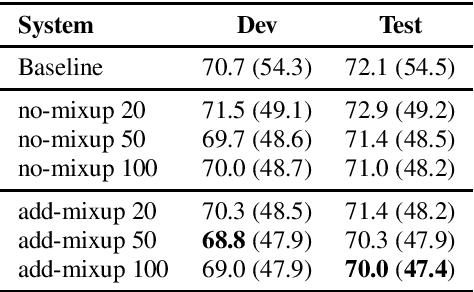
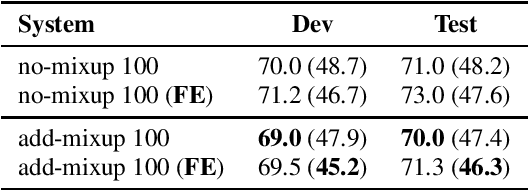
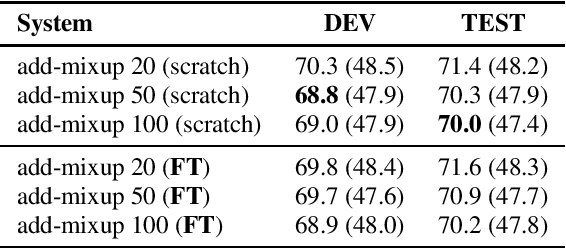
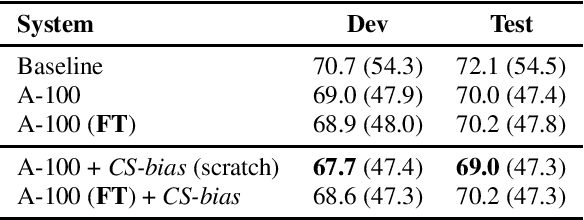
Building Automatic Speech Recognition (ASR) systems for code-switched speech has recently gained renewed attention due to the widespread use of speech technologies in multilingual communities worldwide. End-to-end ASR systems are a natural modeling choice due to their ease of use and superior performance in monolingual settings. However, it is well known that end-to-end systems require large amounts of labeled speech. In this work, we investigate improving code-switched ASR in low resource settings via data augmentation using code-switched text-to-speech (TTS) synthesis. We propose two targeted techniques to effectively leverage TTS speech samples: 1) Mixup, an existing technique to create new training samples via linear interpolation of existing samples, applied to TTS and real speech samples, and 2) a new loss function, used in conjunction with TTS samples, to encourage code-switched predictions. We report significant improvements in ASR performance achieving absolute word error rate (WER) reductions of up to 5%, and measurable improvement in code switching using our proposed techniques on a Hindi-English code-switched ASR task.
Towards Nonlinear Disentanglement in Natural Data with Temporal Sparse Coding
Jul 21, 2020
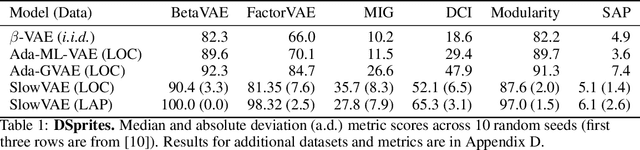
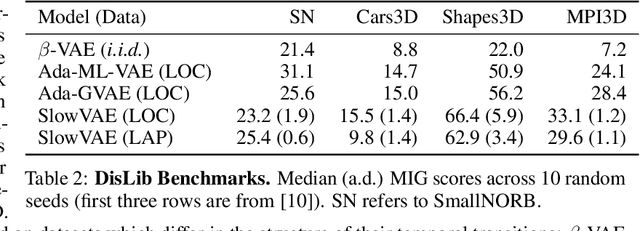
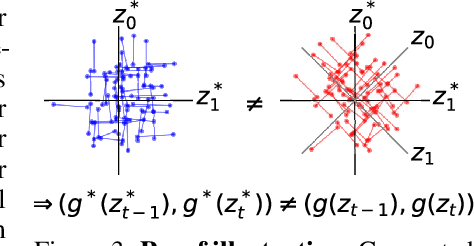
We construct an unsupervised learning model that achieves nonlinear disentanglement of underlying factors of variation in naturalistic videos. Previous work suggests that representations can be disentangled if all but a few factors in the environment stay constant at any point in time. As a result, algorithms proposed for this problem have only been tested on carefully constructed datasets with this exact property, leaving it unclear whether they will transfer to natural scenes. Here we provide evidence that objects in segmented natural movies undergo transitions that are typically small in magnitude with occasional large jumps, which is characteristic of a temporally sparse distribution. We leverage this finding and present SlowVAE, a model for unsupervised representation learning that uses a sparse prior on temporally adjacent observations to disentangle generative factors without any assumptions on the number of changing factors. We provide a proof of identifiability and show that the model reliably learns disentangled representations on several established benchmark datasets, often surpassing the current state-of-the-art. We additionally demonstrate transferability towards video datasets with natural dynamics, Natural Sprites and KITTI Masks, which we contribute as benchmarks for guiding disentanglement research towards more natural data domains.
S2RMs: Spatially Structured Recurrent Modules
Jul 13, 2020



Capturing the structure of a data-generating process by means of appropriate inductive biases can help in learning models that generalize well and are robust to changes in the input distribution. While methods that harness spatial and temporal structures find broad application, recent work has demonstrated the potential of models that leverage sparse and modular structure using an ensemble of sparingly interacting modules. In this work, we take a step towards dynamic models that are capable of simultaneously exploiting both modular and spatiotemporal structures. We accomplish this by abstracting the modeled dynamical system as a collection of autonomous but sparsely interacting sub-systems. The sub-systems interact according to a topology that is learned, but also informed by the spatial structure of the underlying real-world system. This results in a class of models that are well suited for modeling the dynamics of systems that only offer local views into their state, along with corresponding spatial locations of those views. On the tasks of video prediction from cropped frames and multi-agent world modeling from partial observations in the challenging Starcraft2 domain, we find our models to be more robust to the number of available views and better capable of generalization to novel tasks without additional training, even when compared against strong baselines that perform equally well or better on the training distribution.
Unmasking the Inductive Biases of Unsupervised Object Representations for Video Sequences
Jun 12, 2020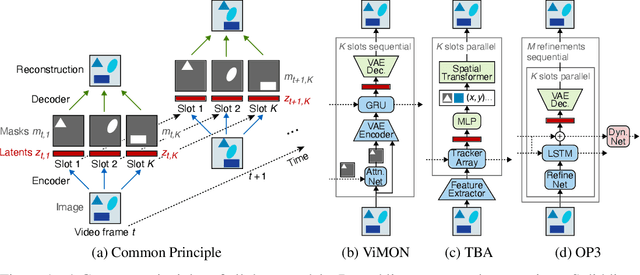
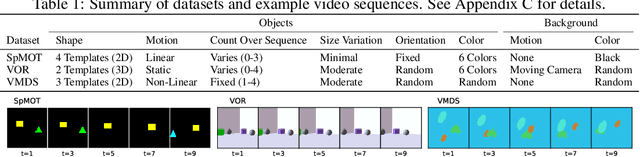
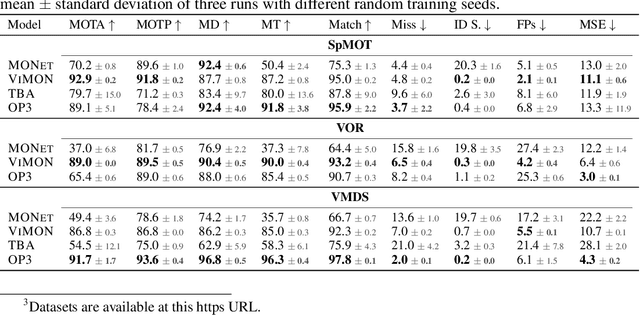
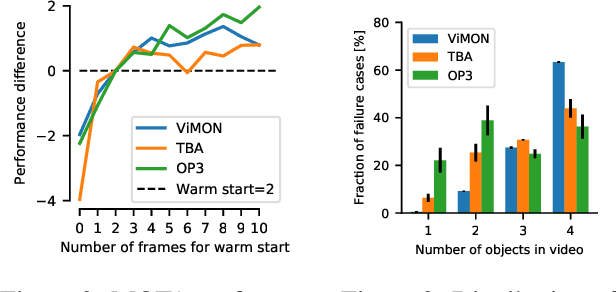
Perceiving the world in terms of objects is a crucial prerequisite for reasoning and scene understanding. Recently, several methods have been proposed for unsupervised learning of object-centric representations. However, since these models have been evaluated with respect to different downstream tasks, it remains unclear how they compare in terms of basic perceptual abilities such as detection, figure-ground segmentation and tracking of individual objects. In this paper, we argue that the established evaluation protocol of multi-object tracking tests precisely these perceptual qualities and we propose a new benchmark dataset based on procedurally generated video sequences. Using this benchmark, we compare the perceptual abilities of three state-of-the-art unsupervised object-centric learning approaches. Towards this goal, we propose a video-extension of MONet, a seminal object-centric model for static scenes, and compare it to two recent video models: OP3, which exploits clustering via spatial mixture models, and TBA, which uses an explicit factorization via spatial transformers. Our results indicate that architectures which employ unconstrained latent representations based on per-object variational autoencoders and full-image object masks are able to learn more powerful representations in terms of object detection, segmentation and tracking than the explicitly parameterized spatial transformer based architecture. We also observe that none of the methods are able to gracefully handle the most challenging tracking scenarios, suggesting that our synthetic video benchmark may provide fruitful guidance towards learning more robust object-centric video representations.
Devising Malware Characterstics using Transformers
May 23, 2020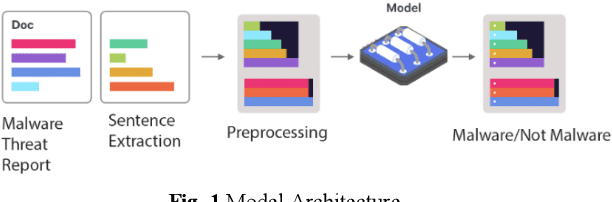
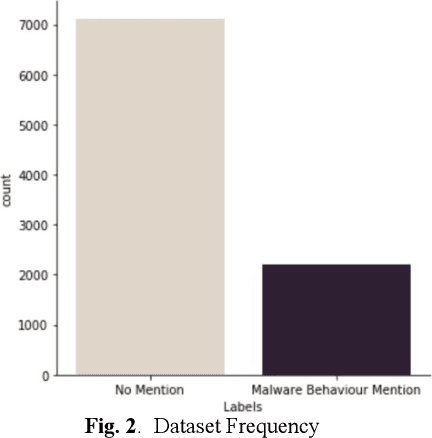
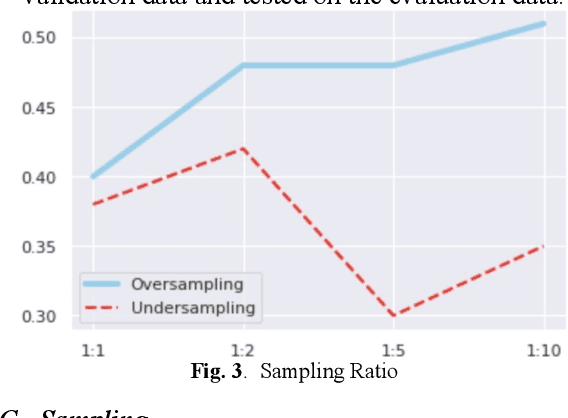
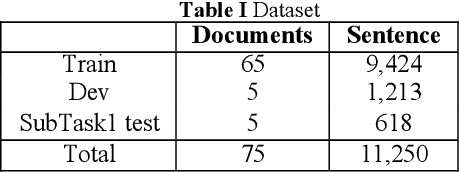
With the increasing number of cybersecurity threats, it becomes more difficult for researchers to skim through the security reports for malware analysis. There is a need to be able to extract highly relevant sentences without having to read through the entire malware reports. In this paper, we are finding relevant malware behavior mentions from Advanced Persistent Threat Reports. This main contribution is an opening attempt to Transformer the approach for malware behavior analysis.
On the Effectiveness of Low Frequency Perturbations
Feb 28, 2019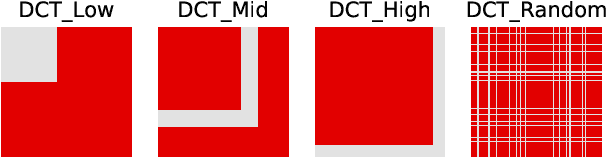

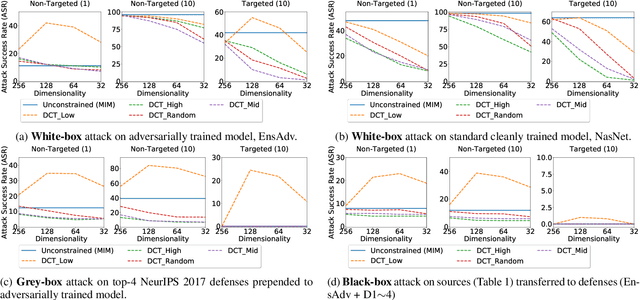
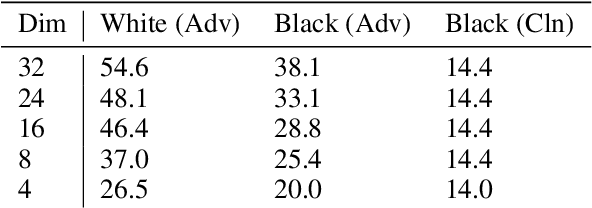
Carefully crafted, often imperceptible, adversarial perturbations have been shown to cause state-of-the-art models to yield extremely inaccurate outputs, rendering them unsuitable for safety-critical application domains. In addition, recent work has shown that constraining the attack space to a low frequency regime is particularly effective. Yet, it remains unclear whether this is due to generally constraining the attack search space or specifically removing high frequency components from consideration. By systematically controlling the frequency components of the perturbation, evaluating against the top-placing defense submissions in the NeurIPS 2017 competition, we empirically show that performance improvements in both optimization and generalization are yielded only when low frequency components are preserved. In fact, the defended models based on (ensemble) adversarial training are roughly as vulnerable to low frequency perturbations as undefended models, suggesting that the purported robustness of proposed defenses is reliant upon adversarial perturbations being high frequency in nature. We do find that under $\ell_\infty$ $\epsilon=16/255$, a commonly used distortion bound, low frequency perturbations are indeed perceptible. This questions the use of the $\ell_\infty$-norm, in particular, as a distortion metric, and suggests that explicitly considering the frequency space is promising for learning robust models which better align with human perception.
Max-Margin Adversarial (MMA) Training: Direct Input Space Margin Maximization through Adversarial Training
Dec 06, 2018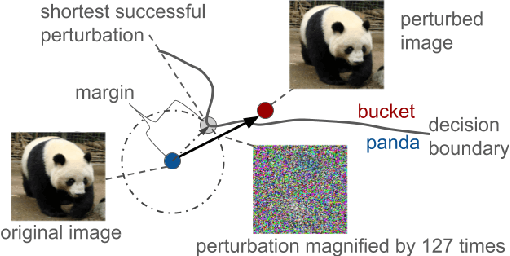
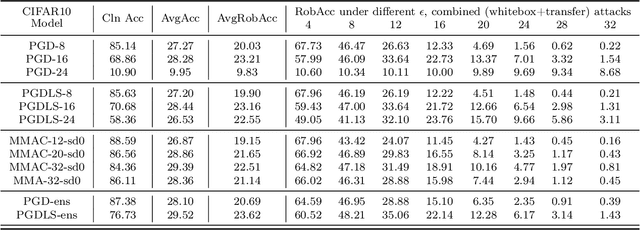
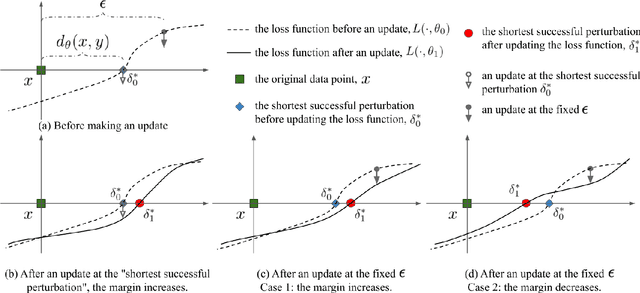
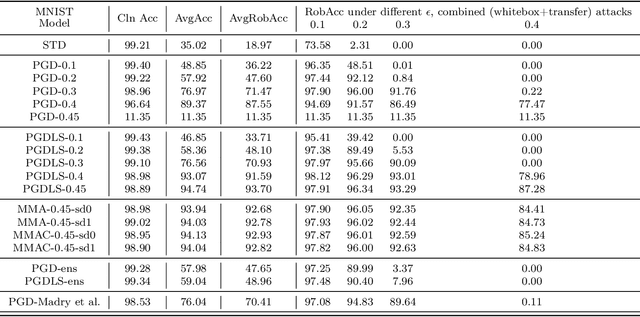
We propose Max-Margin Adversarial (MMA) training for directly maximizing the input space margin. This margin maximization is direct, in the sense that the margin's gradient w.r.t. model parameters can be shown to be parallel with the loss' gradient at the minimal length perturbation, thus gradient ascent on margins can be performed by gradient descent on losses. We further propose a specific formulation of MMA training to maximize the average margin of training examples in order to train models that are robust to adversarial perturbations. It is implemented by performing adversarial training on a novel adaptive norm projected gradient descent (AN-PGD) attack. Preliminary experimental results demonstrate that our method outperforms the existing state of the art methods. In particular, testing against both white-box and transfer projected gradient descent attacks on MNIST, our trained model improves the SOTA $\ell_\infty$ $\epsilon=0.3$ robust accuracy by 2\%, while maintaining the SOTA clean accuracy. Furthermore, the same model provides, to the best of our knowledge, the first model that is robust at $\ell_\infty$ $\epsilon=0.4$, with a robust accuracy of $86.51\%$.
CAAD 2018: Generating Transferable Adversarial Examples
Sep 29, 2018
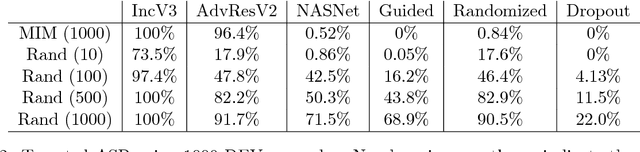

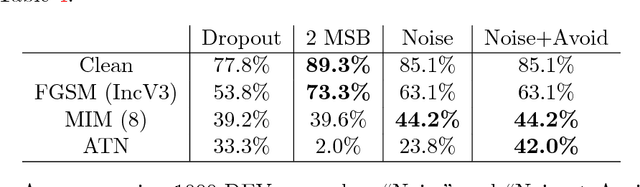
Deep neural networks (DNNs) are vulnerable to adversarial examples, perturbations carefully crafted to fool the targeted DNN, in both the non-targeted and targeted case. In the non-targeted case, the attacker simply aims to induce misclassification. In the targeted case, the attacker aims to induce classification to a specified target class. In addition, it has been observed that strong adversarial examples can transfer to unknown models, yielding a serious security concern. The NIPS 2017 competition was organized to accelerate research in adversarial attacks and defenses, taking place in the realistic setting where submitted adversarial attacks attempt to transfer to submitted defenses. The CAAD 2018 competition took place with nearly identical rules to the NIPS 2017 one. Given the requirement that the NIPS 2017 submissions were to be open-sourced, participants in the CAAD 2018 competition were able to directly build upon previous solutions, and thus improve the state-of-the-art in this setting. Our team participated in the CAAD 2018 competition, and won 1st place in both attack subtracks, non-targeted and targeted adversarial attacks, and 3rd place in defense. We outline our solutions and development results in this article. We hope our results can inform researchers in both generating and defending against adversarial examples.
Generating Natural Language Adversarial Examples
Sep 24, 2018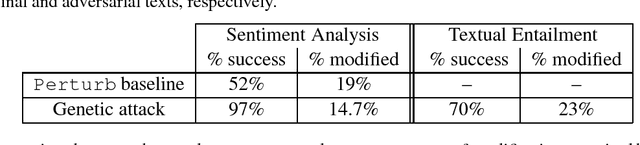
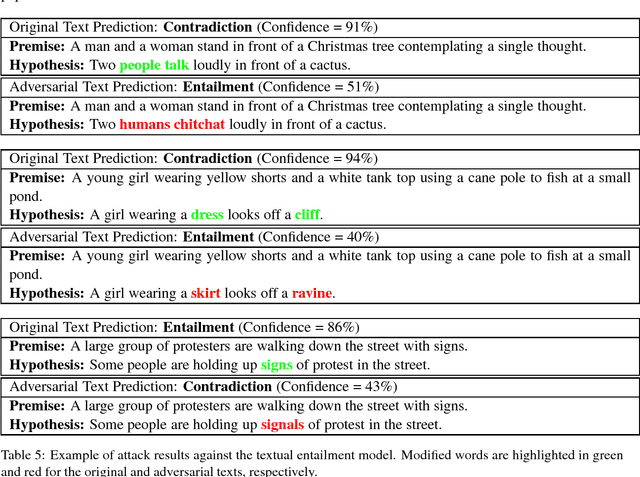
Deep neural networks (DNNs) are vulnerable to adversarial examples, perturbations to correctly classified examples which can cause the model to misclassify. In the image domain, these perturbations are often virtually indistinguishable to human perception, causing humans and state-of-the-art models to disagree. However, in the natural language domain, small perturbations are clearly perceptible, and the replacement of a single word can drastically alter the semantics of the document. Given these challenges, we use a black-box population-based optimization algorithm to generate semantically and syntactically similar adversarial examples that fool well-trained sentiment analysis and textual entailment models with success rates of 97% and 70%, respectively. We additionally demonstrate that 92.3% of the successful sentiment analysis adversarial examples are classified to their original label by 20 human annotators, and that the examples are perceptibly quite similar. Finally, we discuss an attempt to use adversarial training as a defense, but fail to yield improvement, demonstrating the strength and diversity of our adversarial examples. We hope our findings encourage researchers to pursue improving the robustness of DNNs in the natural language domain.