 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving black-box optimization in VAE latent space using decoder uncertainty
Jun 30, 2021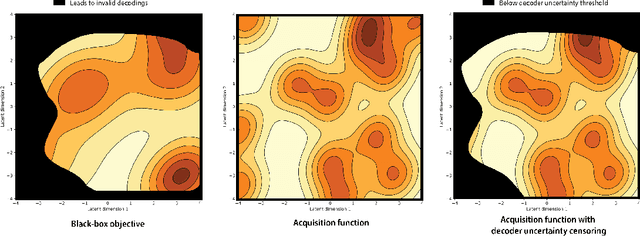
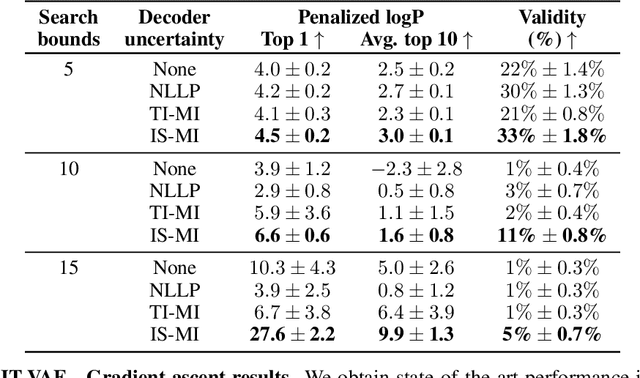


Optimization in the latent space of variational autoencoders is a promising approach to generate high-dimensional discrete objects that maximize an expensive black-box property (e.g., drug-likeness in molecular generation, function approximation with arithmetic expressions). However, existing methods lack robustness as they may decide to explore areas of the latent space for which no data was available during training and where the decoder can be unreliable, leading to the generation of unrealistic or invalid objects. We propose to leverage the epistemic uncertainty of the decoder to guide the optimization process. This is not trivial though, as a naive estimation of uncertainty in the high-dimensional and structured settings we consider would result in high estimator variance. To solve this problem, we introduce an importance sampling-based estimator that provides more robust estimates of epistemic uncertainty. Our uncertainty-guided optimization approach does not require modifications of the model architecture nor the training process. It produces samples with a better trade-off between black-box objective and validity of the generated samples, sometimes improving both simultaneously. We illustrate these advantages across several experimental settings in digit generation, arithmetic expression approximation and molecule generation for drug design.
A Practical & Unified Notation for Information-Theoretic Quantities in ML
Jun 22, 2021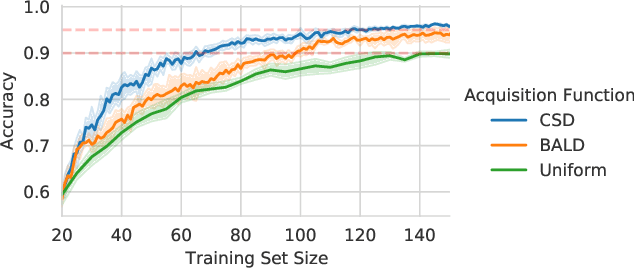

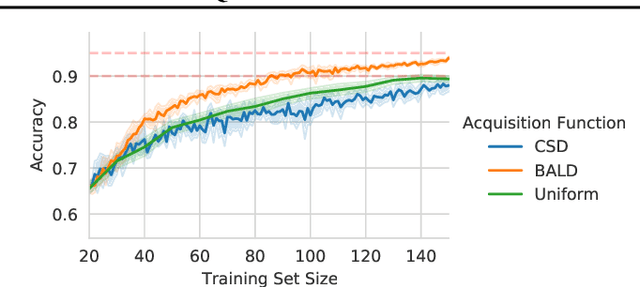
Information theory is of importance to machine learning, but the notation for information-theoretic quantities is sometimes opaque. The right notation can convey valuable intuitions and concisely express new ideas. We propose such a notation for machine learning users and expand it to include information-theoretic quantities between events (outcomes) and random variables. We apply this notation to a popular information-theoretic acquisition function in Bayesian active learning which selects the most informative (unlabelled) samples to be labelled by an expert. We demonstrate the value of our notation when extending the acquisition function to the core-set problem, which consists of selecting the most informative samples \emph{given} the labels.
A Simple Baseline for Batch Active Learning with Stochastic Acquisition Functions
Jun 22, 2021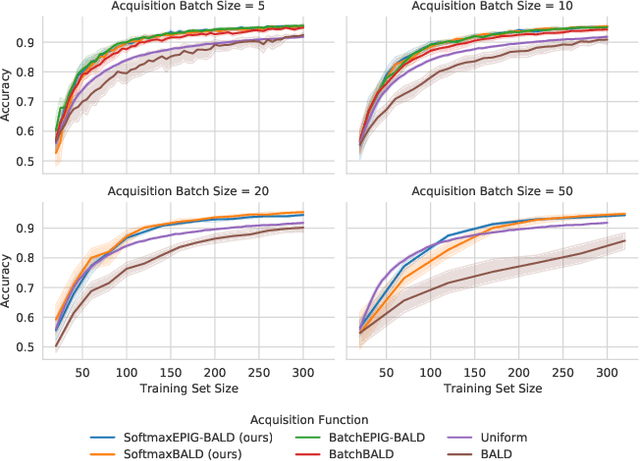
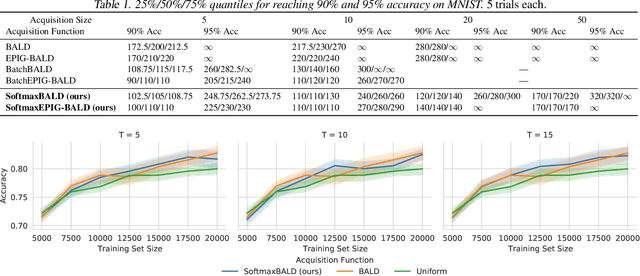
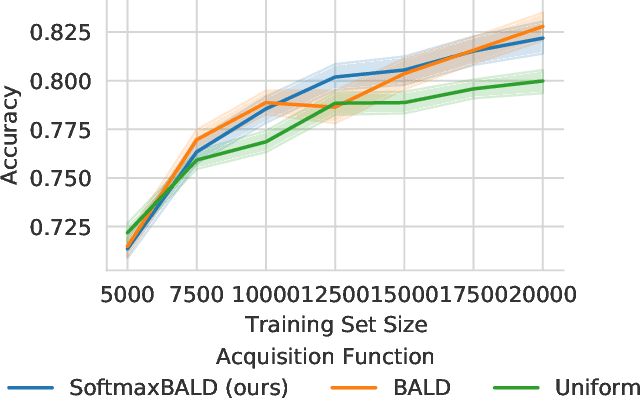
In active learning, new labels are commonly acquired in batches. However, common acquisition functions are only meant for one-sample acquisition rounds at a time, and when their scores are used naively for batch acquisition, they result in batches lacking diversity, which deteriorates performance. On the other hand, state-of-the-art batch acquisition functions are costly to compute. In this paper, we present a novel class of stochastic acquisition functions that extend one-sample acquisition functions to the batch setting by observing how one-sample acquisition scores change as additional samples are acquired and modelling this difference for additional batch samples. We simply acquire new samples by sampling from the pool set using a Gibbs distribution based on the acquisition scores. Our acquisition functions are both vastly cheaper to compute and out-perform other batch acquisition functions.
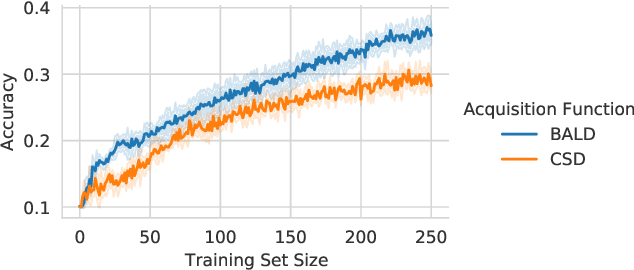
Active Learning under Pool Set Distribution Shift and Noisy Data
Jun 22, 2021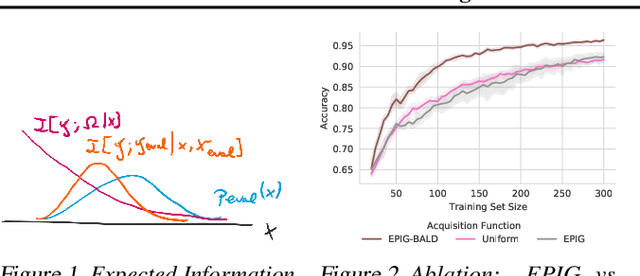
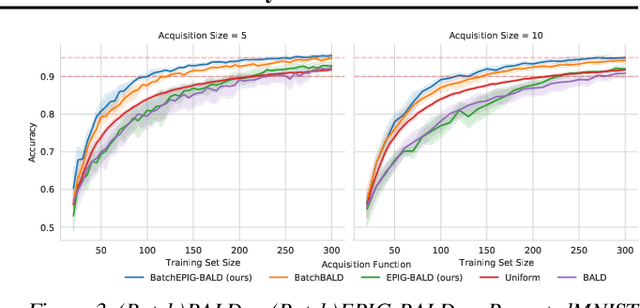
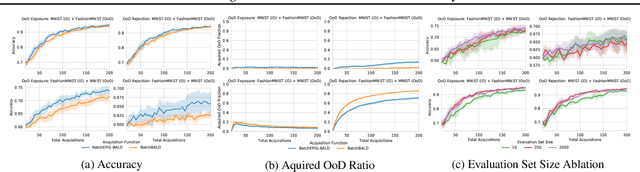
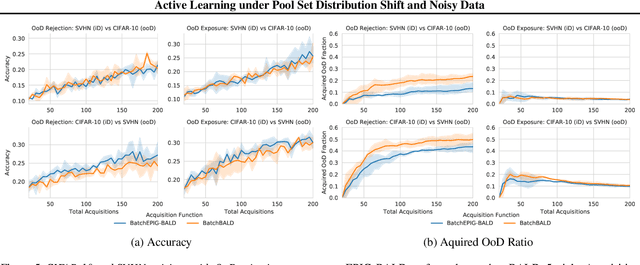
Active Learning is essential for more label-efficient deep learning. Bayesian Active Learning has focused on BALD, which reduces model parameter uncertainty. However, we show that BALD gets stuck on out-of-distribution or junk data that is not relevant for the task. We examine a novel *Expected Predictive Information Gain (EPIG)* to deal with distribution shifts of the pool set. EPIG reduces the uncertainty of *predictions* on an unlabelled *evaluation set* sampled from the test data distribution whose distribution might be different to the pool set distribution. Based on this, our new EPIG-BALD acquisition function for Bayesian Neural Networks selects samples to improve the performance on the test data distribution instead of selecting samples that reduce model uncertainty everywhere, including for out-of-distribution regions with low density in the test data distribution. Our method outperforms state-of-the-art Bayesian active learning methods on high-dimensional datasets and avoids out-of-distribution junk data in cases where current state-of-the-art methods fail.
Can convolutional ResNets approximately preserve input distances? A frequency analysis perspective
Jun 17, 2021

ResNets constrained to be bi-Lipschitz, that is, approximately distance preserving, have been a crucial component of recently proposed techniques for deterministic uncertainty quantification in neural models. We show that theoretical justifications for recent regularisation schemes trying to enforce such a constraint suffer from a crucial flaw -- the theoretical link between the regularisation scheme used and bi-Lipschitzness is only valid under conditions which do not hold in practice, rendering existing theory of limited use, despite the strong empirical performance of these models. We provide a theoretical explanation for the effectiveness of these regularisation schemes using a frequency analysis perspective, showing that under mild conditions these schemes will enforce a lower Lipschitz bound on the low-frequency projection of images. We then provide empirical evidence supporting our theoretical claims, and perform further experiments which demonstrate that our broader conclusions appear to hold when some of the mathematical assumptions of our proof are relaxed, corresponding to the setup used in prior work. In addition, we present a simple constructive algorithm to search for counter examples to the distance preservation condition, and discuss possible implications of our theory for future model design.
KL Guided Domain Adaptation
Jun 14, 2021
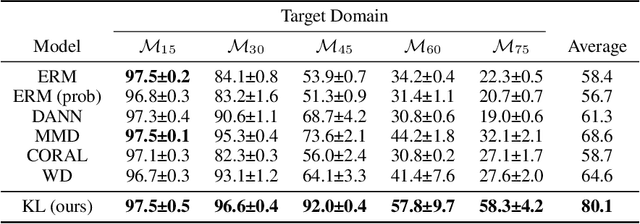

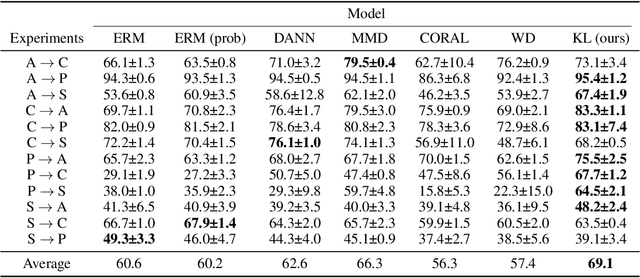
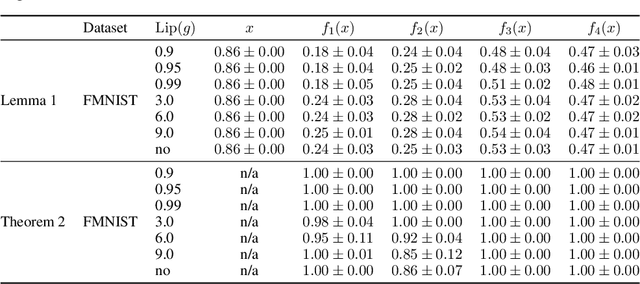
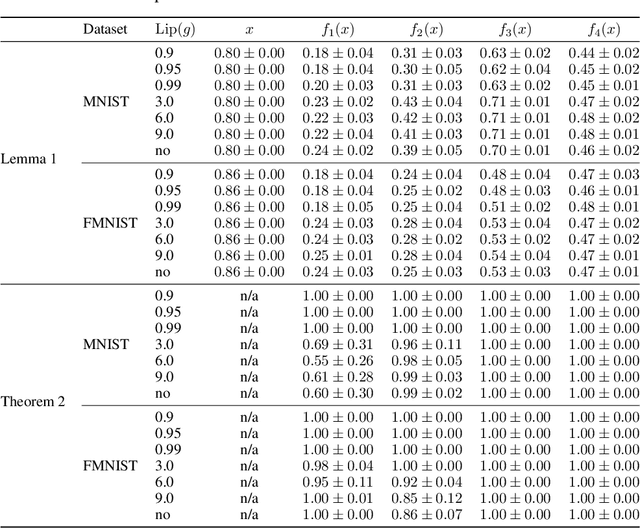
Domain adaptation is an important problem and often needed for real-world applications. In this problem, instead of i.i.d. datapoints, we assume that the source (training) data and the target (testing) data have different distributions. With that setting, the empirical risk minimization training procedure often does not perform well, since it does not account for the change in the distribution. A common approach in the domain adaptation literature is to learn a representation of the input that has the same distributions over the source and the target domain. However, these approaches often require additional networks and/or optimizing an adversarial (minimax) objective, which can be very expensive or unstable in practice. To tackle this problem, we first derive a generalization bound for the target loss based on the training loss and the reverse Kullback-Leibler (KL) divergence between the source and the target representation distributions. Based on this bound, we derive an algorithm that minimizes the KL term to obtain a better generalization to the target domain. We show that with a probabilistic representation network, the KL term can be estimated efficiently via minibatch samples without any additional network or a minimax objective. This leads to a theoretically sound alignment method which is also very efficient and stable in practice. Experimental results also suggest that our method outperforms other representation-alignment approaches.
Uncertainty Baselines: Benchmarks for Uncertainty & Robustness in Deep Learning
Jun 07, 2021
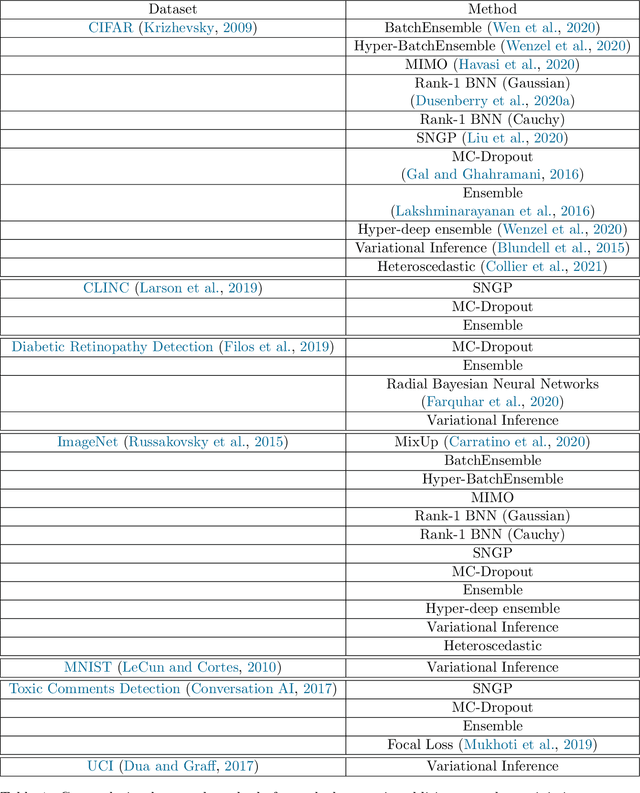
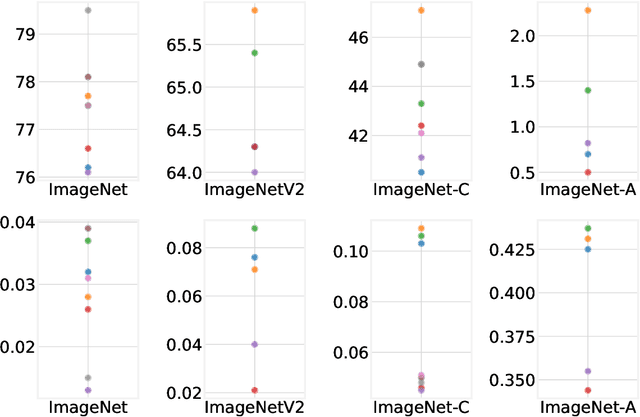
High-quality estimates of uncertainty and robustness are crucial for numerous real-world applications, especially for deep learning which underlies many deployed ML systems. The ability to compare techniques for improving these estimates is therefore very important for research and practice alike. Yet, competitive comparisons of methods are often lacking due to a range of reasons, including: compute availability for extensive tuning, incorporation of sufficiently many baselines, and concrete documentation for reproducibility. In this paper we introduce Uncertainty Baselines: high-quality implementations of standard and state-of-the-art deep learning methods on a variety of tasks. As of this writing, the collection spans 19 methods across 9 tasks, each with at least 5 metrics. Each baseline is a self-contained experiment pipeline with easily reusable and extendable components. Our goal is to provide immediate starting points for experimentation with new methods or applications. Additionally we provide model checkpoints, experiment outputs as Python notebooks, and leaderboards for comparing results. Code available at https://github.com/google/uncertainty-baselines.
Self-Attention Between Datapoints: Going Beyond Individual Input-Output Pairs in Deep Learning
Jun 04, 2021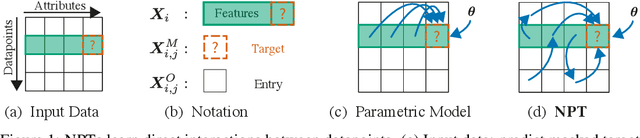
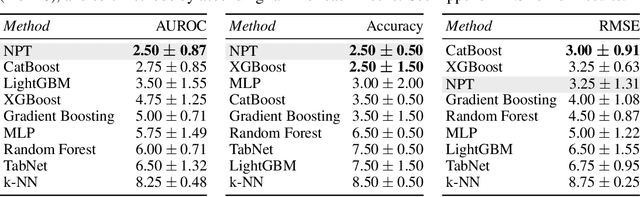
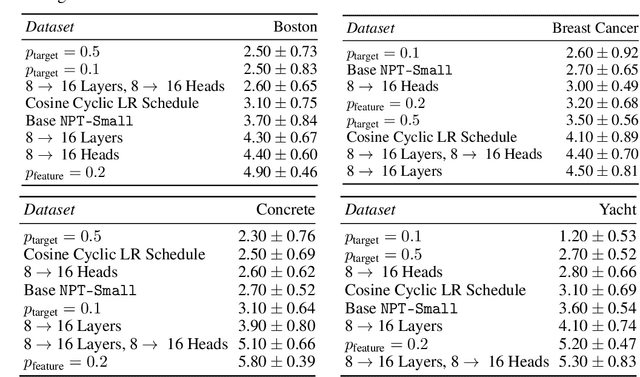
We challenge a common assumption underlying most supervised deep learning: that a model makes a prediction depending only on its parameters and the features of a single input. To this end, we introduce a general-purpose deep learning architecture that takes as input the entire dataset instead of processing one datapoint at a time. Our approach uses self-attention to reason about relationships between datapoints explicitly, which can be seen as realizing non-parametric models using parametric attention mechanisms. However, unlike conventional non-parametric models, we let the model learn end-to-end from the data how to make use of other datapoints for prediction. Empirically, our models solve cross-datapoint lookup and complex reasoning tasks unsolvable by traditional deep learning models. We show highly competitive results on tabular data, early results on CIFAR-10, and give insight into how the model makes use of the interactions between points.
Physically-Consistent Generative Adversarial Networks for Coastal Flood Visualization
May 05, 2021
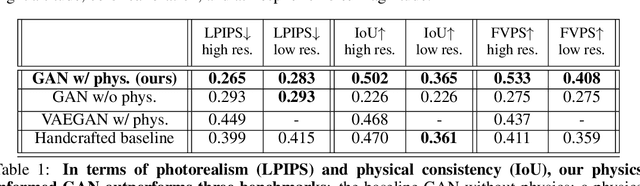
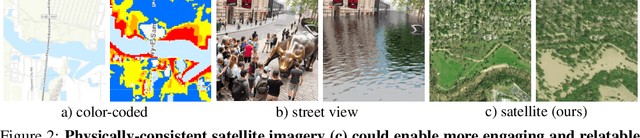
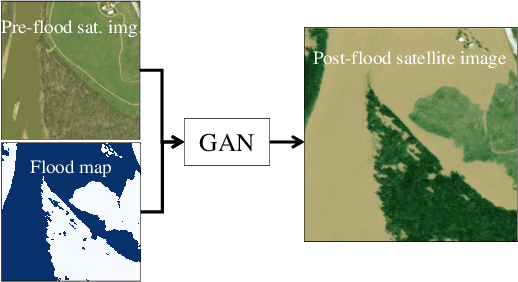
As climate change increases the intensity of natural disasters, society needs better tools for adaptation. Floods, for example, are the most frequent natural disaster, and better tools for flood risk communication could increase the support for flood-resilient infrastructure development. Our work aims to enable more visual communication of large-scale climate impacts via visualizing the output of coastal flood models as satellite imagery. We propose the first deep learning pipeline to ensure physical-consistency in synthetic visual satellite imagery. We advanced a state-of-the-art GAN called pix2pixHD, such that it produces imagery that is physically-consistent with the output of an expert-validated storm surge model (NOAA SLOSH). By evaluating the imagery relative to physics-based flood maps, we find that our proposed framework outperforms baseline models in both physical-consistency and photorealism. We envision our work to be the first step towards a global visualization of how climate change shapes our landscape. Continuing on this path, we show that the proposed pipeline generalizes to visualize arctic sea ice melt. We also publish a dataset of over 25k labelled image-pairs to study image-to-image translation in Earth observation.
Outcome-Driven Reinforcement Learning via Variational Inference
Apr 20, 2021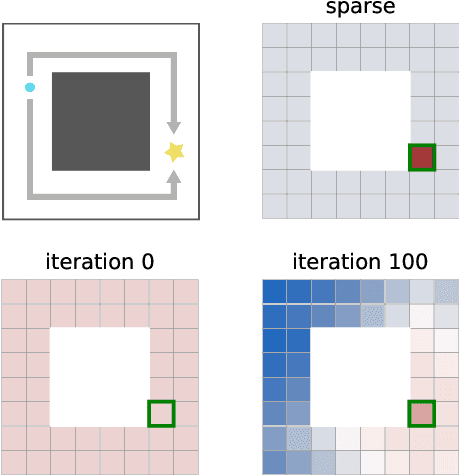
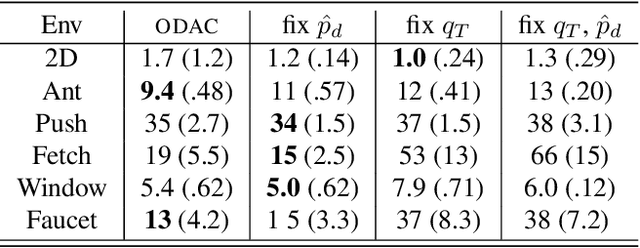
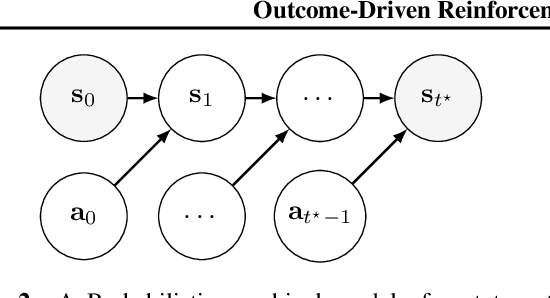
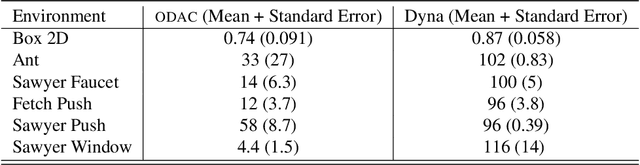
While reinforcement learning algorithms provide automated acquisition of optimal policies, practical application of such methods requires a number of design decisions, such as manually designing reward functions that not only define the task, but also provide sufficient shaping to accomplish it. In this paper, we discuss a new perspective on reinforcement learning, recasting it as the problem of inferring actions that achieve desired outcomes, rather than a problem of maximizing rewards. To solve the resulting outcome-directed inference problem, we establish a novel variational inference formulation that allows us to derive a well-shaped reward function which can be learned directly from environment interactions. From the corresponding variational objective, we also derive a new probabilistic Bellman backup operator reminiscent of the standard Bellman backup operator and use it to develop an off-policy algorithm to solve goal-directed tasks. We empirically demonstrate that this method eliminates the need to design reward functions and leads to effective goal-directed behaviors.