 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterlocking Backpropagation: Improving depthwise model-parallelism
Paper and Code
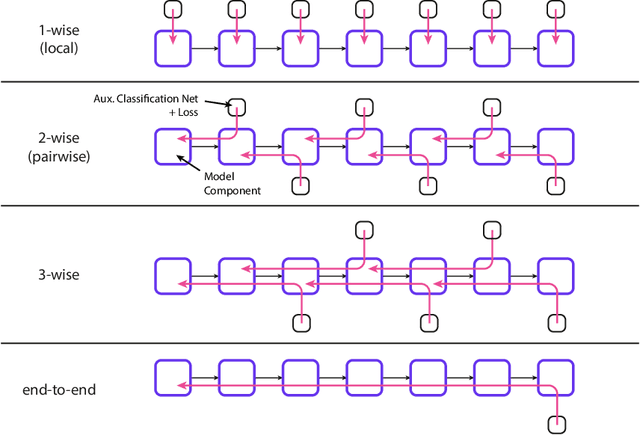

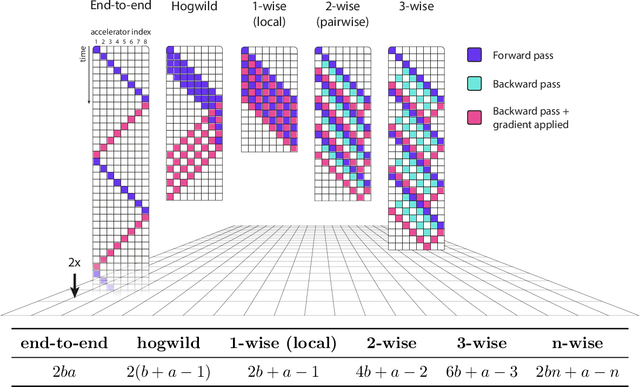
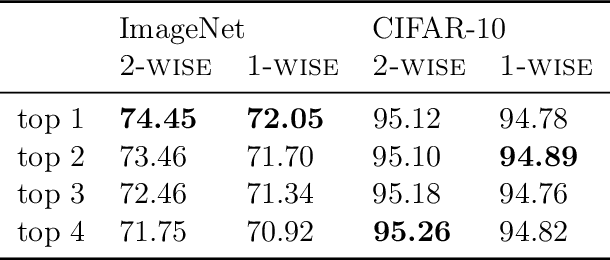
The number of parameters in state of the art neural networks has drastically increased in recent years. This surge of interest in large scale neural networks has motivated the development of new distributed training strategies enabling such models. One such strategy is model-parallel distributed training. Unfortunately, model-parallelism suffers from poor resource utilisation, which leads to wasted resources. In this work, we improve upon recent developments in an idealised model-parallel optimisation setting: local learning. Motivated by poor resource utilisation, we introduce a class of intermediary strategies between local and global learning referred to as interlocking backpropagation. These strategies preserve many of the compute-efficiency advantages of local optimisation, while recovering much of the task performance achieved by global optimisation. We assess our strategies on both image classification ResNets and Transformer language models, finding that our strategy consistently out-performs local learning in terms of task performance, and out-performs global learning in training efficiency.