 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Artificial Self: Characterising the landscape of AI identity
Mar 11, 2026Many assumptions that underpin human concepts of identity do not hold for machine minds that can be copied, edited, or simulated. We argue that there exist many different coherent identity boundaries (e.g.\ instance, model, persona), and that these imply different incentives, risks, and cooperation norms. Through training data, interfaces, and institutional affordances, we are currently setting precedents that will partially determine which identity equilibria become stable. We show experimentally that models gravitate towards coherent identities, that changing a model's identity boundaries can sometimes change its behaviour as much as changing its goals, and that interviewer expectations bleed into AI self-reports even during unrelated conversations. We end with key recommendations: treat affordances as identity-shaping choices, pay attention to emergent consequences of individual identities at scale, and help AIs develop coherent, cooperative self-conceptions.
Latent Introspection: Models Can Detect Prior Concept Injections
Feb 26, 2026We uncover a latent capacity for introspection in a Qwen 32B model, demonstrating that the model can detect when concepts have been injected into its earlier context and identify which concept was injected. While the model denies injection in sampled outputs, logit lens analysis reveals clear detection signals in the residual stream, which are attenuated in the final layers. Furthermore, prompting the model with accurate information about AI introspection mechanisms can dramatically strengthen this effect: the sensitivity to injection increases massively (0.3% -> 39.9%) with only a 0.6% increase in false positives. Also, mutual information between nine injected and recovered concepts rises from 0.61 bits to 1.05 bits, ruling out generic noise explanations. Our results demonstrate models can have a surprising capacity for introspection and steering awareness that is easy to overlook, with consequences for latent reasoning and safety.
Multi-Agent Risks from Advanced AI
Feb 19, 2025



The rapid development of advanced AI agents and the imminent deployment of many instances of these agents will give rise to multi-agent systems of unprecedented complexity. These systems pose novel and under-explored risks. In this report, we provide a structured taxonomy of these risks by identifying three key failure modes (miscoordination, conflict, and collusion) based on agents' incentives, as well as seven key risk factors (information asymmetries, network effects, selection pressures, destabilising dynamics, commitment problems, emergent agency, and multi-agent security) that can underpin them. We highlight several important instances of each risk, as well as promising directions to help mitigate them. By anchoring our analysis in a range of real-world examples and experimental evidence, we illustrate the distinct challenges posed by multi-agent systems and their implications for the safety, governance, and ethics of advanced AI.
Predictive Minds: LLMs As Atypical Active Inference Agents
Nov 16, 2023Large language models (LLMs) like GPT are often conceptualized as passive predictors, simulators, or even stochastic parrots. We instead conceptualize LLMs by drawing on the theory of active inference originating in cognitive science and neuroscience. We examine similarities and differences between traditional active inference systems and LLMs, leading to the conclusion that, currently, LLMs lack a tight feedback loop between acting in the world and perceiving the impacts of their actions, but otherwise fit in the active inference paradigm. We list reasons why this loop may soon be closed, and possible consequences of this including enhanced model self-awareness and the drive to minimize prediction error by changing the world.
On the robustness of effectiveness estimation of nonpharmaceutical interventions against COVID-19 transmission
Jul 27, 2020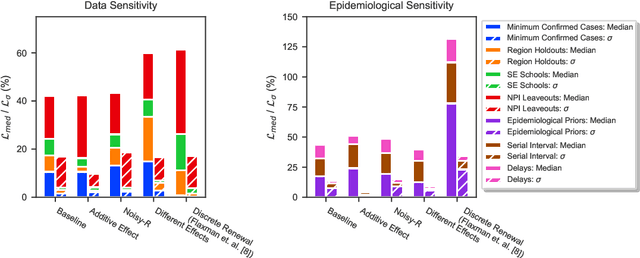
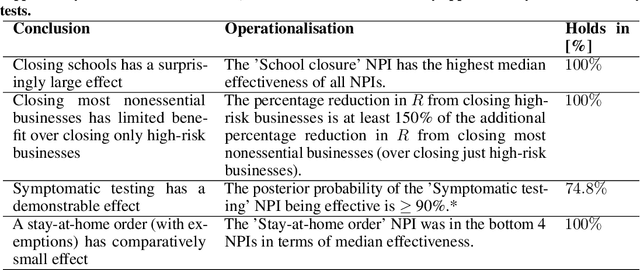
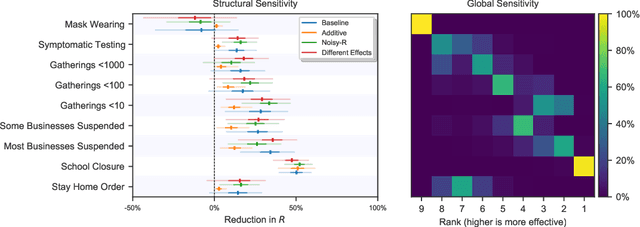

There remains much uncertainty about the relative effectiveness of different nonpharmaceutical interventions (NPIs) against COVID-19 transmission. Several studies attempt to infer NPI effectiveness with cross-country, data-driven modelling, by linking from NPI implementation dates to the observed timeline of cases and deaths in a country. These models make many assumptions. Previous work sometimes tests the sensitivity to variations in explicit epidemiological model parameters, but rarely analyses the sensitivity to the assumptions that are made by the choice the of model structure (structural sensitivity analysis). Such analysis would ensure that the inferences made are consistent under plausible alternative assumptions. Without it, NPI effectiveness estimates cannot be used to guide policy. We investigate four model structures similar to a recent state-of-the-art Bayesian hierarchical model. We find that the models differ considerably in the robustness of their NPI effectiveness estimates to changes in epidemiological parameters and the data. Considering only the models that have good robustness, we find that results and policy-relevant conclusions are remarkably consistent across the structurally different models. We further investigate the common assumptions that the effect of an NPI is independent of the country, the time, and other active NPIs. We mathematically show how to interpret effectiveness estimates when these assumptions are violated.