 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Fraud Detection using Deep Boosting Decision Trees
Feb 12, 2023Fraud detection is to identify, monitor, and prevent potentially fraudulent activities from complex data. The recent development and success in AI, especially machine learning, provides a new data-driven way to deal with fraud. From a methodological point of view, machine learning based fraud detection can be divided into two categories, i.e., conventional methods (decision tree, boosting...) and deep learning, both of which have significant limitations in terms of the lack of representation learning ability for the former and interpretability for the latter. Furthermore, due to the rarity of detected fraud cases, the associated data is usually imbalanced, which seriously degrades the performance of classification algorithms. In this paper, we propose deep boosting decision trees (DBDT), a novel approach for fraud detection based on gradient boosting and neural networks. In order to combine the advantages of both conventional methods and deep learning, we first construct soft decision tree (SDT), a decision tree structured model with neural networks as its nodes, and then ensemble SDTs using the idea of gradient boosting. In this way we embed neural networks into gradient boosting to improve its representation learning capability and meanwhile maintain the interpretability. Furthermore, aiming at the rarity of detected fraud cases, in the model training phase we propose a compositional AUC maximization approach to deal with data imbalances at algorithm level. Extensive experiments on several real-life fraud detection datasets show that DBDT can significantly improve the performance and meanwhile maintain good interpretability. Our code is available at https://github.com/freshmanXB/DBDT.
Learning Neural Volumetric Field for Point Cloud Geometry Compression
Dec 11, 2022Due to the diverse sparsity, high dimensionality, and large temporal variation of dynamic point clouds, it remains a challenge to design an efficient point cloud compression method. We propose to code the geometry of a given point cloud by learning a neural volumetric field. Instead of representing the entire point cloud using a single overfit network, we divide the entire space into small cubes and represent each non-empty cube by a neural network and an input latent code. The network is shared among all the cubes in a single frame or multiple frames, to exploit the spatial and temporal redundancy. The neural field representation of the point cloud includes the network parameters and all the latent codes, which are generated by using back-propagation over the network parameters and its input. By considering the entropy of the network parameters and the latent codes as well as the distortion between the original and reconstructed cubes in the loss function, we derive a rate-distortion (R-D) optimal representation. Experimental results show that the proposed coding scheme achieves superior R-D performances compared to the octree-based G-PCC, especially when applied to multiple frames of a point cloud video. The code is available at https://github.com/huzi96/NVFPCC/.
Deterioration Prediction using Time-Series of Three Vital Signs and Current Clinical Features Amongst COVID-19 Patients
Oct 12, 2022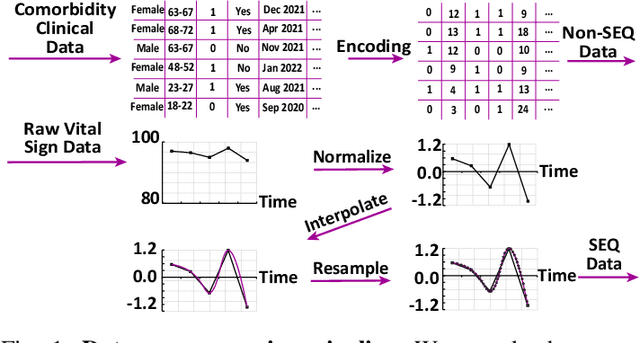
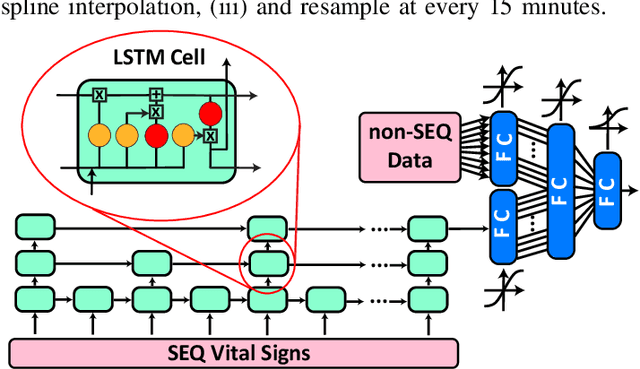
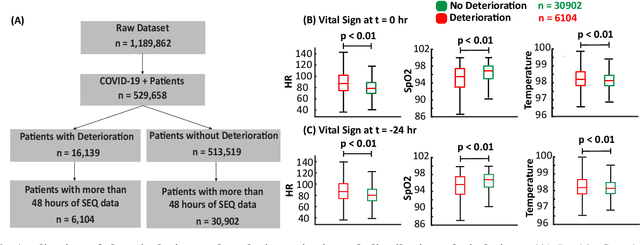
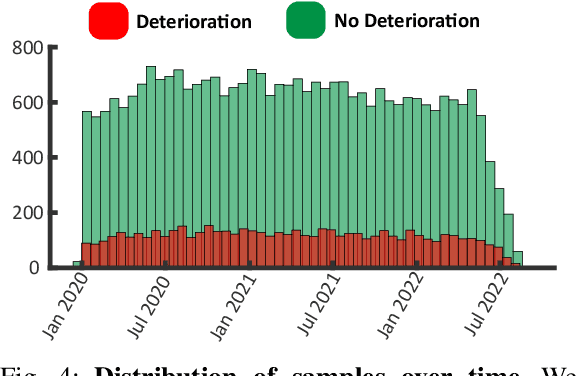
Unrecognized patient deterioration can lead to high morbidity and mortality. Most existing deterioration prediction models require a large number of clinical information, typically collected in hospital settings, such as medical images or comprehensive laboratory tests. This is infeasible for telehealth solutions and highlights a gap in deterioration prediction models that are based on minimal data, which can be recorded at a large scale in any clinic, nursing home, or even at the patient's home. In this study, we propose and develop a prognostic model that predicts if a patient will experience deterioration in the forthcoming 3-24 hours. The model sequentially processes routine triadic vital signs: (a) oxygen saturation, (b) heart rate, and (c) temperature. The model is also provided with basic patient information, including sex, age, vaccination status, vaccination date, and status of obesity, hypertension, or diabetes. We train and evaluate the model using data collected from 37,006 COVID-19 patients at NYU Langone Health in New York, USA. The model achieves an area under the receiver operating characteristic curve (AUROC) of 0.808-0.880 for 3-24 hour deterioration prediction. We also conduct occlusion experiments to evaluate the importance of each input feature, where the results reveal the significance of continuously monitoring the variations of the vital signs. Our results show the prospect of accurate deterioration forecast using a minimum feature set that can be relatively easily obtained using wearable devices and self-reported patient information.
Understanding the Impact of Image Quality and Distance of Objects to Object Detection Performance
Sep 17, 2022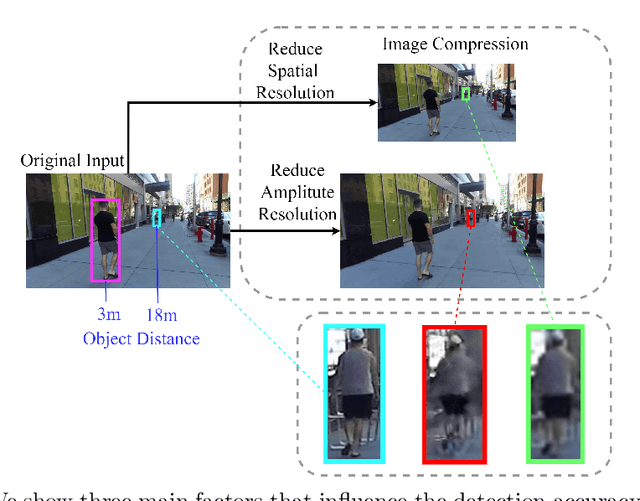
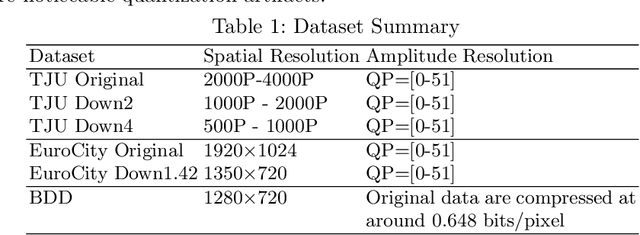
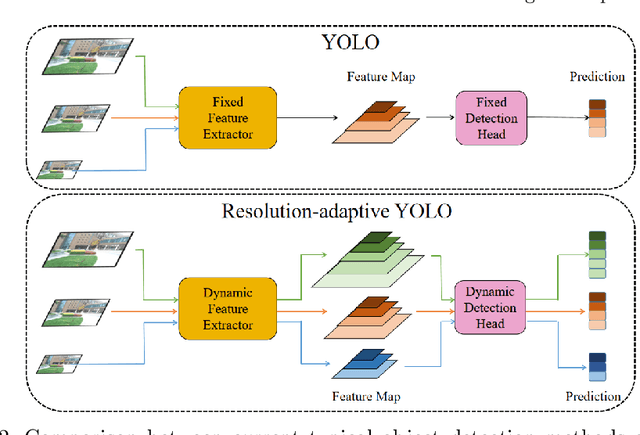

Deep learning has made great strides for object detection in images. The detection accuracy and computational cost of object detection depend on the spatial resolution of an image, which may be constrained by both the camera and storage considerations. Compression is often achieved by reducing either spatial or amplitude resolution or, at times, both, both of which have well-known effects on performance. Detection accuracy also depends on the distance of the object of interest from the camera. Our work examines the impact of spatial and amplitude resolution, as well as object distance, on object detection accuracy and computational cost. We develop a resolution-adaptive variant of YOLOv5 (RA-YOLO), which varies the number of scales in the feature pyramid and detection head based on the spatial resolution of the input image. To train and evaluate this new method, we created a dataset of images with diverse spatial and amplitude resolutions by combining images from the TJU and Eurocity datasets and generating different resolutions by applying spatial resizing and compression. We first show that RA-YOLO achieves a good trade-off between detection accuracy and inference time over a large range of spatial resolutions. We then evaluate the impact of spatial and amplitude resolutions on object detection accuracy using the proposed RA-YOLO model. We demonstrate that the optimal spatial resolution that leads to the highest detection accuracy depends on the 'tolerated' image size. We further assess the impact of the distance of an object to the camera on the detection accuracy and show that higher spatial resolution enables a greater detection range. These results provide important guidelines for choosing the image spatial resolution and compression settings predicated on available bandwidth, storage, desired inference time, and/or desired detection range, in practical applications.
Learning to Predict on Octree for Scalable Point Cloud Geometry Coding
Sep 06, 2022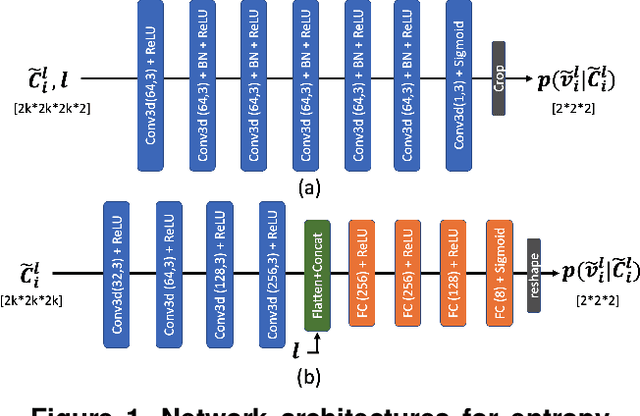
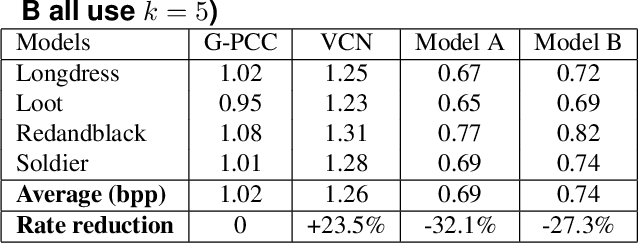
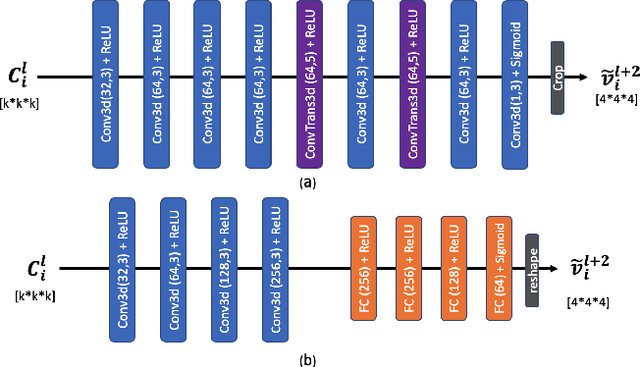
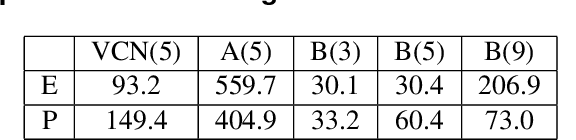
Octree-based point cloud representation and compression have been adopted by the MPEG G-PCC standard. However, it only uses handcrafted methods to predict the probability that a leaf node is non-empty, which is then used for entropy coding. We propose a novel approach for predicting such probabilities for geometry coding, which applies a denoising neural network to a "noisy" context cube that includes both neighboring decoded voxels as well as uncoded voxels. We further propose a convolution-based model to upsample the decoded point cloud at a coarse resolution on the decoder side. Integration of the two approaches significantly improves the rate-distortion performance for geometry coding compared to the original G-PCC standard and other baseline methods for dense point clouds. The proposed octree-based entropy coding approach is naturally scalable, which is desirable for dynamic rate adaptation in point cloud streaming systems.
Improved Image Classification with Token Fusion
Aug 19, 2022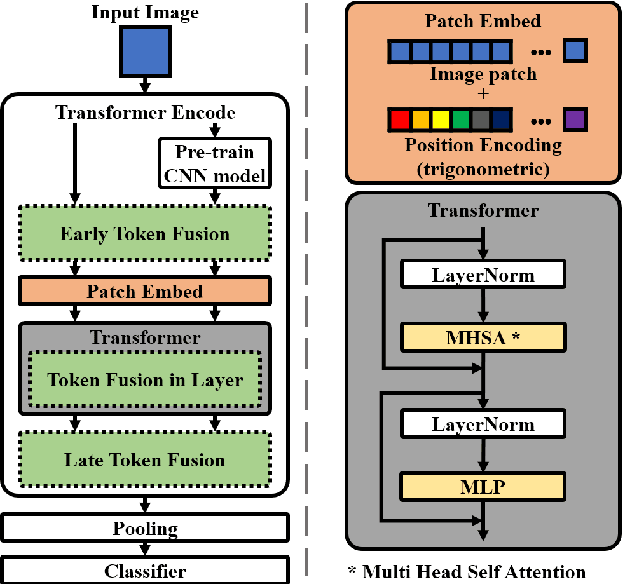
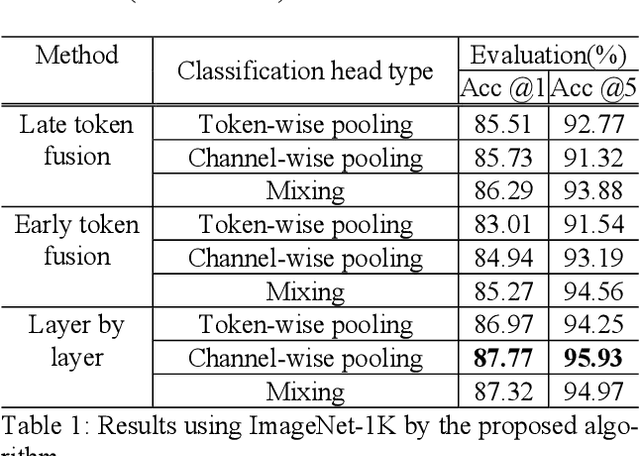
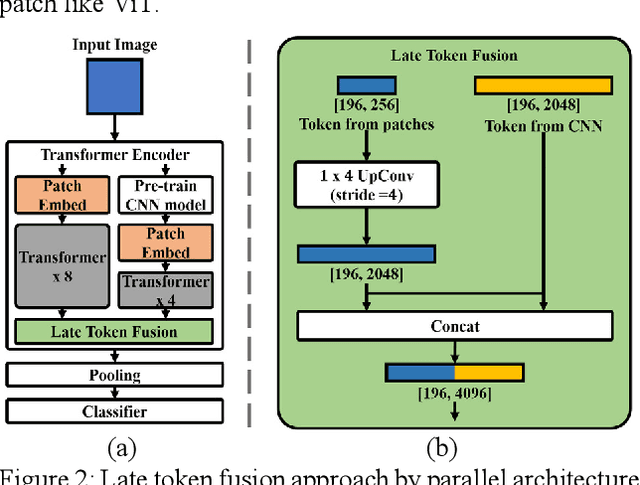
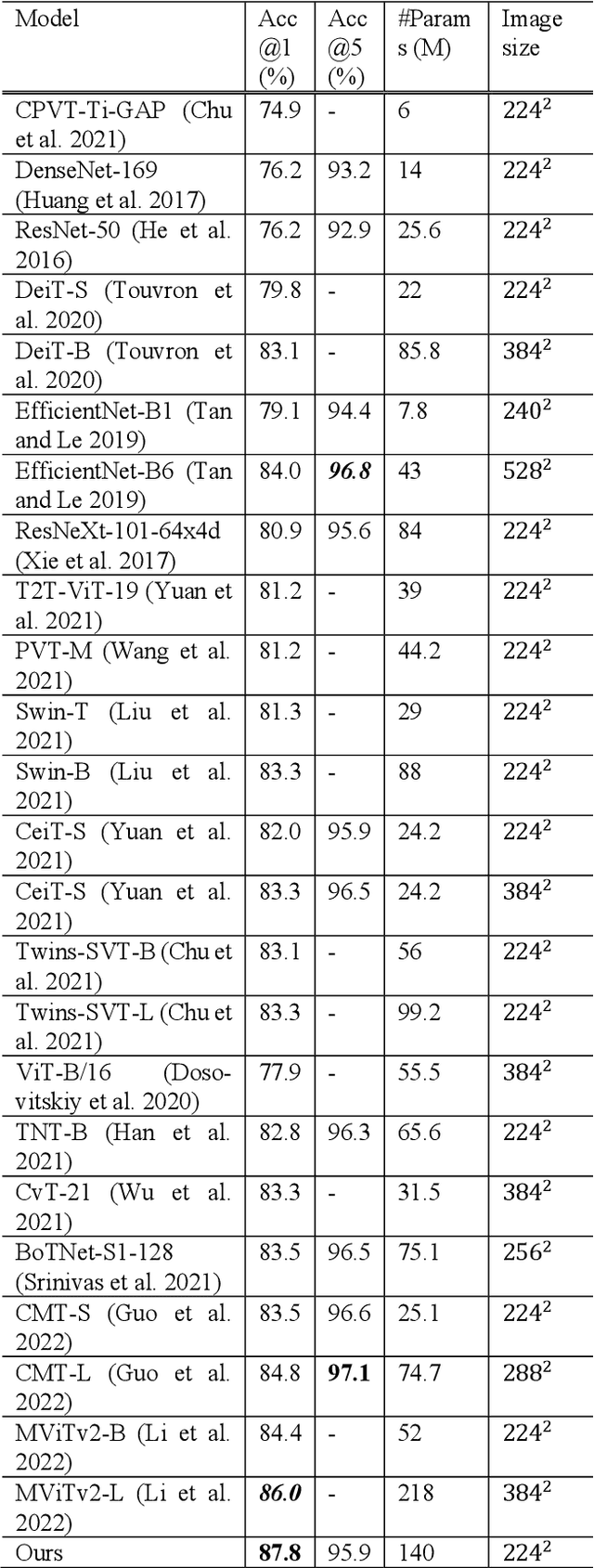
In this paper, we propose a method using the fusion of CNN and transformer structure to improve image classification performance. In the case of CNN, information about a local area on an image can be extracted well, but there is a limit to the extraction of global information. On the other hand, the transformer has an advantage in relatively global extraction, but has a disadvantage in that it requires a lot of memory for local feature value extraction. In the case of an image, it is converted into a feature map through CNN, and each feature map's pixel is considered a token. At the same time, the image is divided into patch areas and then fused with the transformer method that views them as tokens. For the fusion of tokens with two different characteristics, we propose three methods: (1) late token fusion with parallel structure, (2) early token fusion, (3) token fusion in a layer by layer. In an experiment using ImageNet 1k, the proposed method shows the best classification performance.
Detect and Approach: Close-Range Navigation Support for People with Blindness and Low Vision
Aug 17, 2022

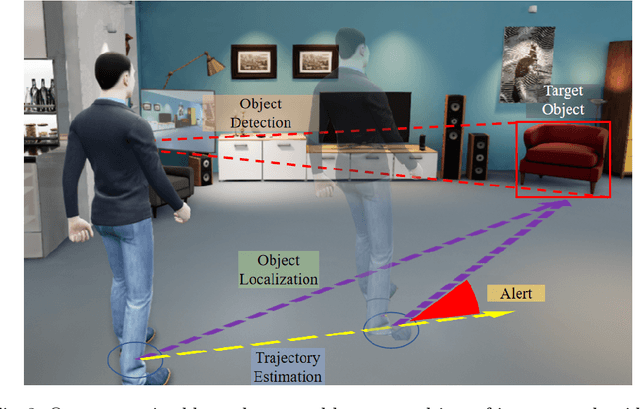
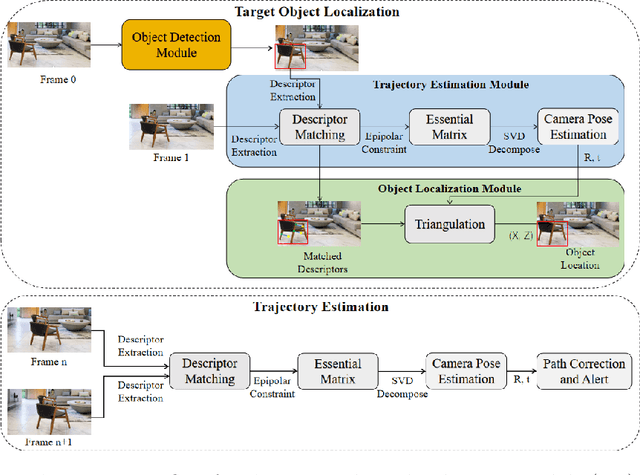
People with blindness and low vision (pBLV) experience significant challenges when locating final destinations or targeting specific objects in unfamiliar environments. Furthermore, besides initially locating and orienting oneself to a target object, approaching the final target from one's present position is often frustrating and challenging, especially when one drifts away from the initial planned path to avoid obstacles. In this paper, we develop a novel wearable navigation solution to provide real-time guidance for a user to approach a target object of interest efficiently and effectively in unfamiliar environments. Our system contains two key visual computing functions: initial target object localization in 3D and continuous estimation of the user's trajectory, both based on the 2D video captured by a low-cost monocular camera mounted on in front of the chest of the user. These functions enable the system to suggest an initial navigation path, continuously update the path as the user moves, and offer timely recommendation about the correction of the user's path. Our experiments demonstrate that our system is able to operate with an error of less than 0.5 meter both outdoor and indoor. The system is entirely vision-based and does not need other sensors for navigation, and the computation can be run with the Jetson processor in the wearable system to facilitate real-time navigation assistance.
Gabor is Enough: Interpretable Deep Denoising with a Gabor Synthesis Dictionary Prior
Apr 23, 2022
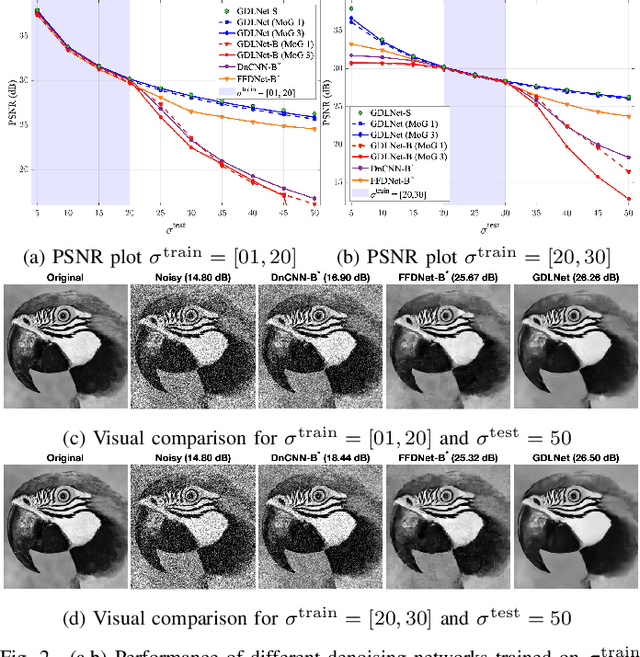

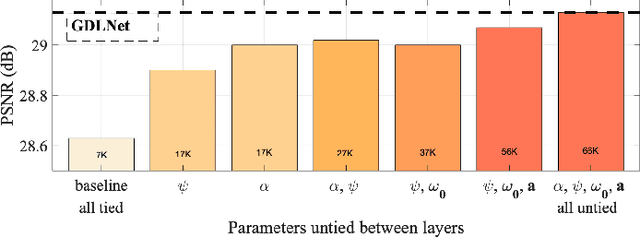
Image processing neural networks, natural and artificial, have a long history with orientation-selectivity, often described mathematically as Gabor filters. Gabor-like filters have been observed in the early layers of CNN classifiers and even throughout low-level image processing networks. In this work, we take this observation to the extreme and explicitly constrain the filters of a natural-image denoising CNN to be learned 2D real Gabor filters. Surprisingly, we find that the proposed network (GDLNet) can achieve near state-of-the-art denoising performance amongst popular fully convolutional neural networks, with only a fraction of the learned parameters. We further verify that this parameterization maintains the noise-level generalization (training vs. inference mismatch) characteristics of the base network, and investigate the contribution of individual Gabor filter parameters to the performance of the denoiser. We present positive findings for the interpretation of dictionary learning networks as performing accelerated sparse-coding via the importance of untied learned scale parameters between network layers. Our network's success suggests that representations used by low-level image processing CNNs can be as simple and interpretable as Gabor filterbanks.
Feature Compression for Rate Constrained Object Detection on the Edge
Apr 15, 2022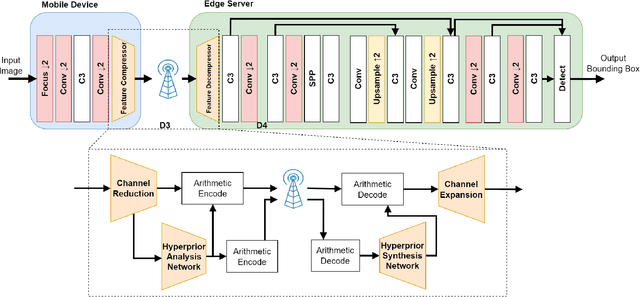

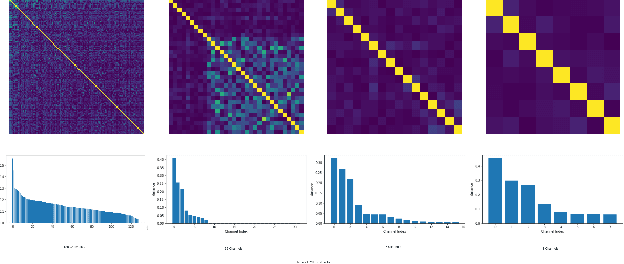
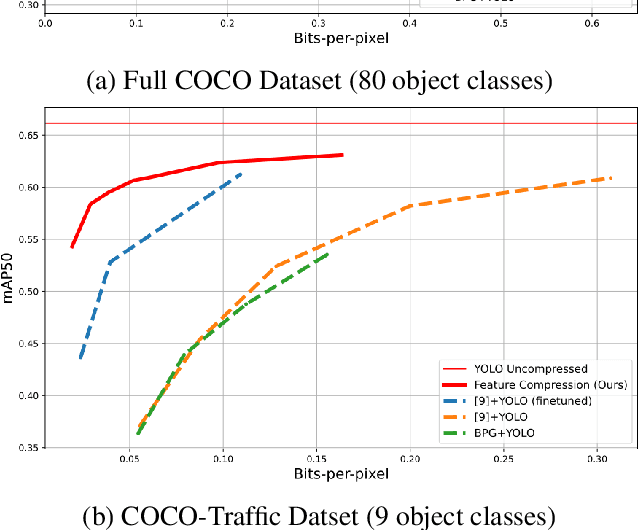
Recent advances in computer vision has led to a growth of interest in deploying visual analytics model on mobile devices. However, most mobile devices have limited computing power, which prohibits them from running large scale visual analytics neural networks. An emerging approach to solve this problem is to offload the computation of these neural networks to computing resources at an edge server. Efficient computation offloading requires optimizing the trade-off between multiple objectives including compressed data rate, analytics performance, and computation speed. In this work, we consider a "split computation" system to offload a part of the computation of the YOLO object detection model. We propose a learnable feature compression approach to compress the intermediate YOLO features with light-weight computation. We train the feature compression and decompression module together with the YOLO model to optimize the object detection accuracy under a rate constraint. Compared to baseline methods that apply either standard image compression or learned image compression at the mobile and perform image decompression and YOLO at the edge, the proposed system achieves higher detection accuracy at the low to medium rate range. Furthermore, the proposed system requires substantially lower computation time on the mobile device with CPU only.
FS6D: Few-Shot 6D Pose Estimation of Novel Objects
Mar 28, 2022

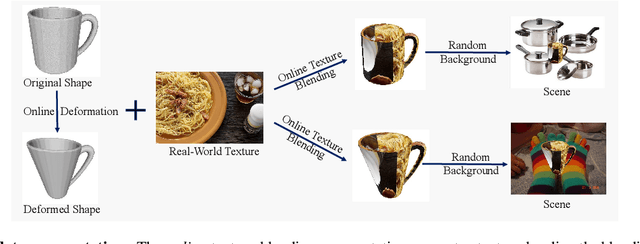
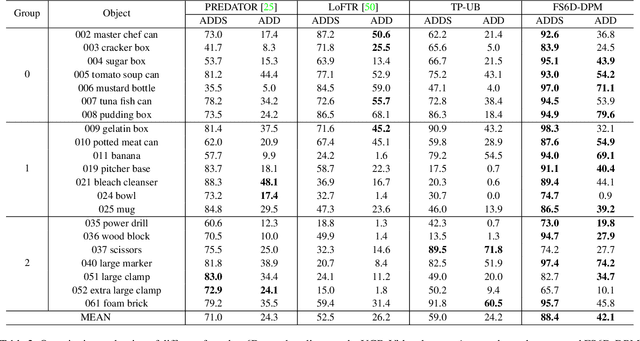
6D object pose estimation networks are limited in their capability to scale to large numbers of object instances due to the close-set assumption and their reliance on high-fidelity object CAD models. In this work, we study a new open set problem; the few-shot 6D object poses estimation: estimating the 6D pose of an unknown object by a few support views without extra training. To tackle the problem, we point out the importance of fully exploring the appearance and geometric relationship between the given support views and query scene patches and propose a dense prototypes matching framework by extracting and matching dense RGBD prototypes with transformers. Moreover, we show that the priors from diverse appearances and shapes are crucial to the generalization capability under the problem setting and thus propose a large-scale RGBD photorealistic dataset (ShapeNet6D) for network pre-training. A simple and effective online texture blending approach is also introduced to eliminate the domain gap from the synthesis dataset, which enriches appearance diversity at a low cost. Finally, we discuss possible solutions to this problem and establish benchmarks on popular datasets to facilitate future research. The project page is at \url{https://fs6d.github.io/}.