 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Convolutional Encoder Model for Neural Machine Translation
Jul 25, 2017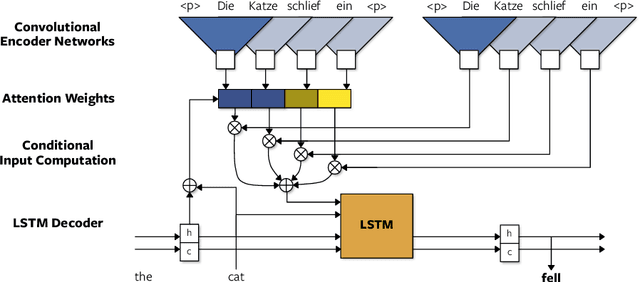
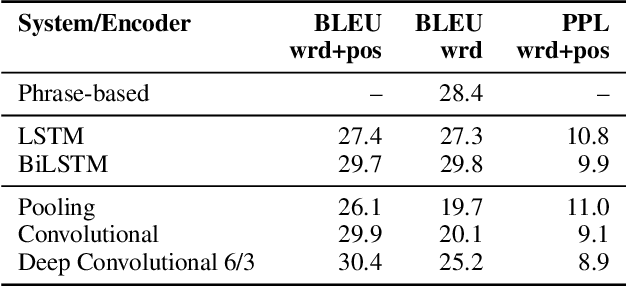
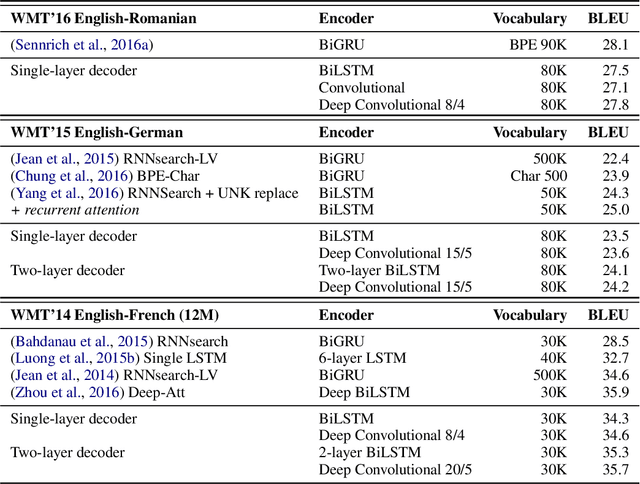
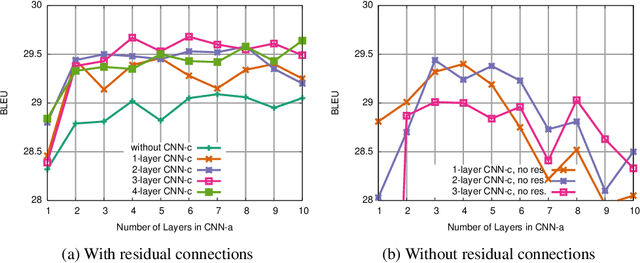
The prevalent approach to neural machine translation relies on bi-directional LSTMs to encode the source sentence. In this paper we present a faster and simpler architecture based on a succession of convolutional layers. This allows to encode the entire source sentence simultaneously compared to recurrent networks for which computation is constrained by temporal dependencies. On WMT'16 English-Romanian translation we achieve competitive accuracy to the state-of-the-art and we outperform several recently published results on the WMT'15 English-German task. Our models obtain almost the same accuracy as a very deep LSTM setup on WMT'14 English-French translation. Our convolutional encoder speeds up CPU decoding by more than two times at the same or higher accuracy as a strong bi-directional LSTM baseline.
Deal or No Deal? End-to-End Learning for Negotiation Dialogues
Jun 16, 2017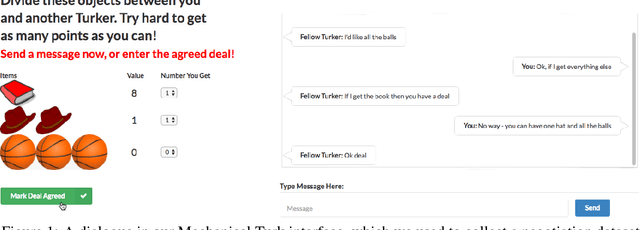
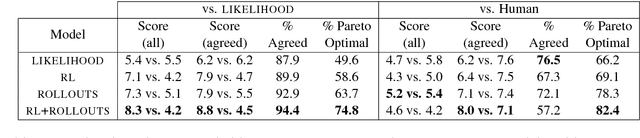
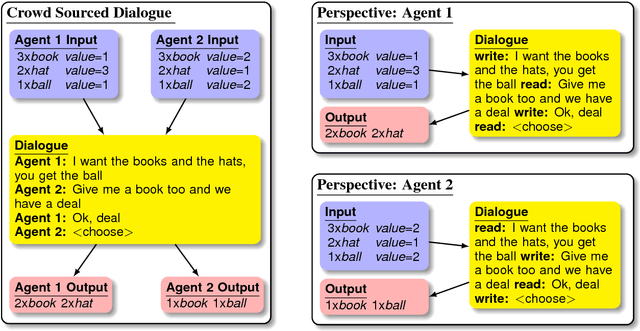
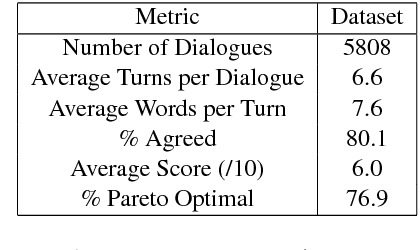
Much of human dialogue occurs in semi-cooperative settings, where agents with different goals attempt to agree on common decisions. Negotiations require complex communication and reasoning skills, but success is easy to measure, making this an interesting task for AI. We gather a large dataset of human-human negotiations on a multi-issue bargaining task, where agents who cannot observe each other's reward functions must reach an agreement (or a deal) via natural language dialogue. For the first time, we show it is possible to train end-to-end models for negotiation, which must learn both linguistic and reasoning skills with no annotated dialogue states. We also introduce dialogue rollouts, in which the model plans ahead by simulating possible complete continuations of the conversation, and find that this technique dramatically improves performance. Our code and dataset are publicly available (https://github.com/facebookresearch/end-to-end-negotiator).
Theano: A Python framework for fast computation of mathematical expressions
May 09, 2016



Theano is a Python library that allows to define, optimize, and evaluate mathematical expressions involving multi-dimensional arrays efficiently. Since its introduction, it has been one of the most used CPU and GPU mathematical compilers - especially in the machine learning community - and has shown steady performance improvements. Theano is being actively and continuously developed since 2008, multiple frameworks have been built on top of it and it has been used to produce many state-of-the-art machine learning models. The present article is structured as follows. Section I provides an overview of the Theano software and its community. Section II presents the principal features of Theano and how to use them, and compares them with other similar projects. Section III focuses on recently-introduced functionalities and improvements. Section IV compares the performance of Theano against Torch7 and TensorFlow on several machine learning models. Section V discusses current limitations of Theano and potential ways of improving it.
Predicting distributions with Linearizing Belief Networks
May 02, 2016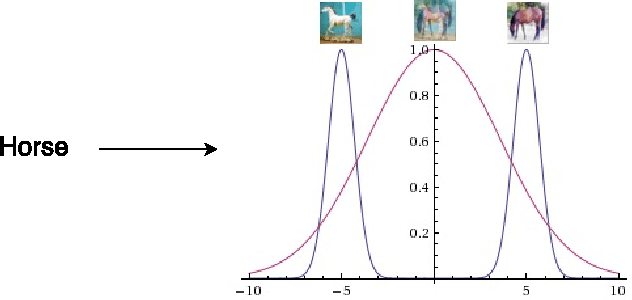

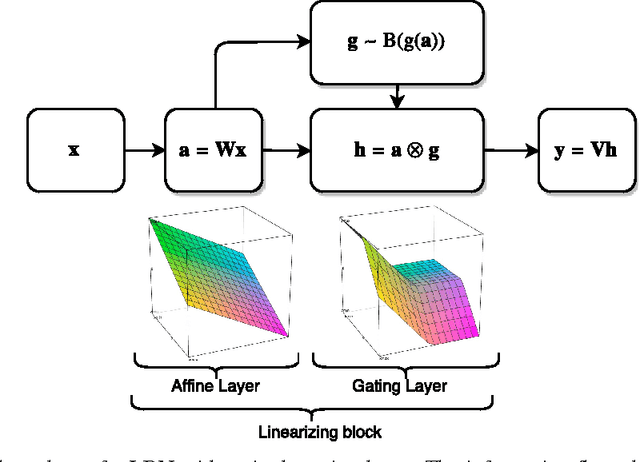
Conditional belief networks introduce stochastic binary variables in neural networks. Contrary to a classical neural network, a belief network can predict more than the expected value of the output $Y$ given the input $X$. It can predict a distribution of outputs $Y$ which is useful when an input can admit multiple outputs whose average is not necessarily a valid answer. Such networks are particularly relevant to inverse problems such as image prediction for denoising, or text to speech. However, traditional sigmoid belief networks are hard to train and are not suited to continuous problems. This work introduces a new family of networks called linearizing belief nets or LBNs. A LBN decomposes into a deep linear network where each linear unit can be turned on or off by non-deterministic binary latent units. It is a universal approximator of real-valued conditional distributions and can be trained using gradient descent. Moreover, the linear pathways efficiently propagate continuous information and they act as multiplicative skip-connections that help optimization by removing gradient diffusion. This yields a model which trains efficiently and improves the state-of-the-art on image denoising and facial expression generation with the Toronto faces dataset.
Equilibrated adaptive learning rates for non-convex optimization
Aug 29, 2015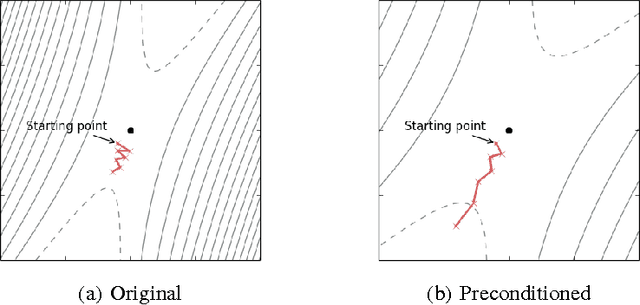
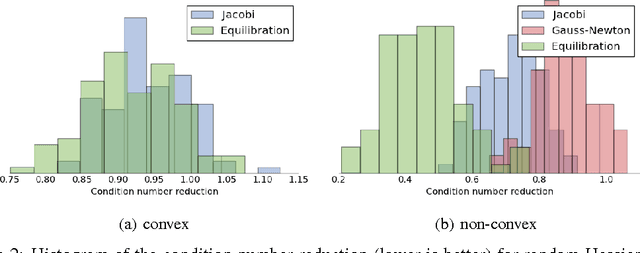
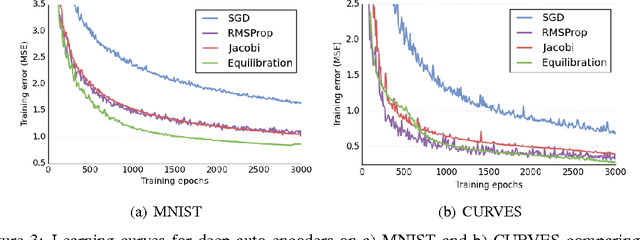
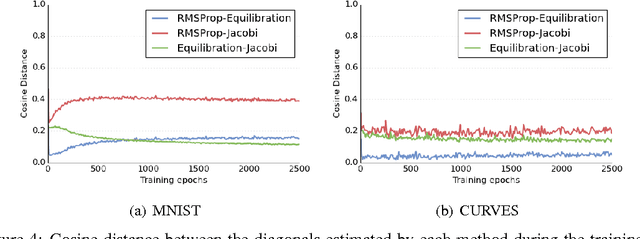
Parameter-specific adaptive learning rate methods are computationally efficient ways to reduce the ill-conditioning problems encountered when training large deep networks. Following recent work that strongly suggests that most of the critical points encountered when training such networks are saddle points, we find how considering the presence of negative eigenvalues of the Hessian could help us design better suited adaptive learning rate schemes. We show that the popular Jacobi preconditioner has undesirable behavior in the presence of both positive and negative curvature, and present theoretical and empirical evidence that the so-called equilibration preconditioner is comparatively better suited to non-convex problems. We introduce a novel adaptive learning rate scheme, called ESGD, based on the equilibration preconditioner. Our experiments show that ESGD performs as well or better than RMSProp in terms of convergence speed, always clearly improving over plain stochastic gradient descent.
On the saddle point problem for non-convex optimization
May 28, 2014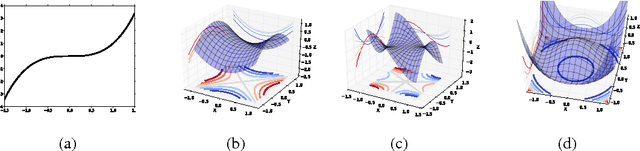

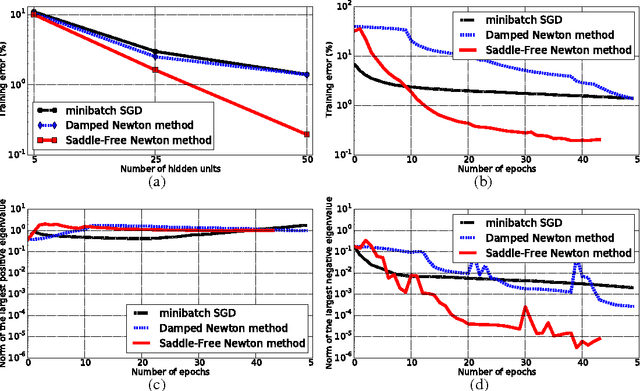
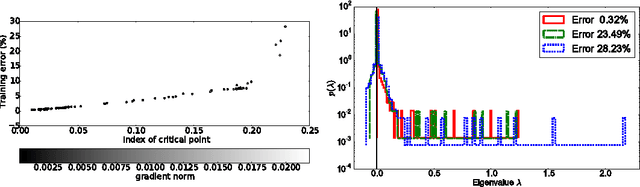
A central challenge to many fields of science and engineering involves minimizing non-convex error functions over continuous, high dimensional spaces. Gradient descent or quasi-Newton methods are almost ubiquitously used to perform such minimizations, and it is often thought that a main source of difficulty for the ability of these local methods to find the global minimum is the proliferation of local minima with much higher error than the global minimum. Here we argue, based on results from statistical physics, random matrix theory, and neural network theory, that a deeper and more profound difficulty originates from the proliferation of saddle points, not local minima, especially in high dimensional problems of practical interest. Such saddle points are surrounded by high error plateaus that can dramatically slow down learning, and give the illusory impression of the existence of a local minimum. Motivated by these arguments, we propose a new algorithm, the saddle-free Newton method, that can rapidly escape high dimensional saddle points, unlike gradient descent and quasi-Newton methods. We apply this algorithm to deep neural network training, and provide preliminary numerical evidence for its superior performance.
Zero-Shot Learning for Semantic Utterance Classification
Mar 07, 2014

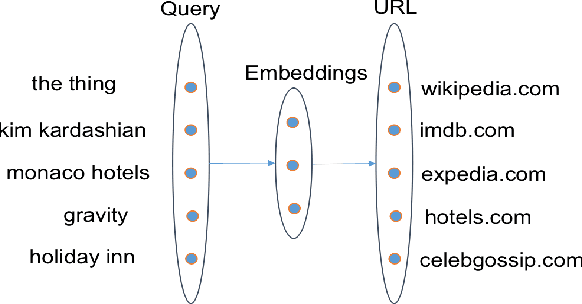
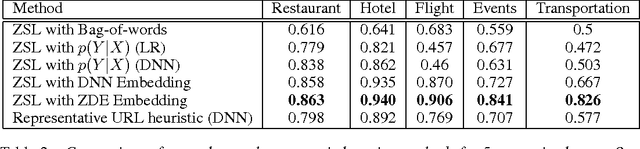
We propose a novel zero-shot learning method for semantic utterance classification (SUC). It learns a classifier $f: X \to Y$ for problems where none of the semantic categories $Y$ are present in the training set. The framework uncovers the link between categories and utterances using a semantic space. We show that this semantic space can be learned by deep neural networks trained on large amounts of search engine query log data. More precisely, we propose a novel method that can learn discriminative semantic features without supervision. It uses the zero-shot learning framework to guide the learning of the semantic features. We demonstrate the effectiveness of the zero-shot semantic learning algorithm on the SUC dataset collected by (Tur, 2012). Furthermore, we achieve state-of-the-art results by combining the semantic features with a supervised method.
Big Neural Networks Waste Capacity
Mar 14, 2013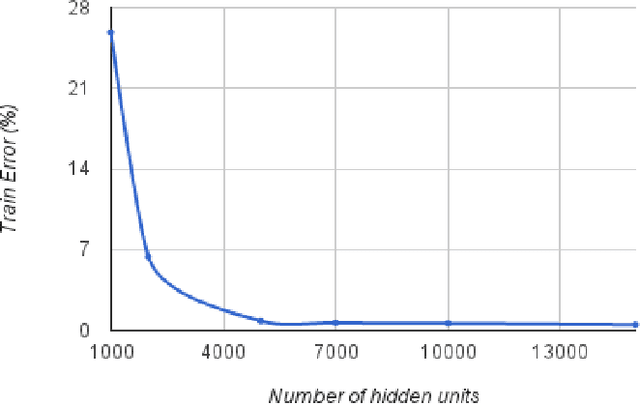
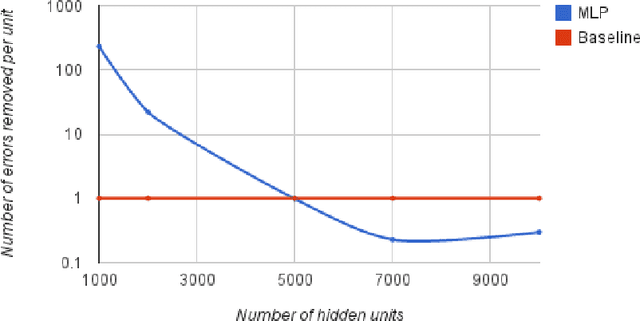
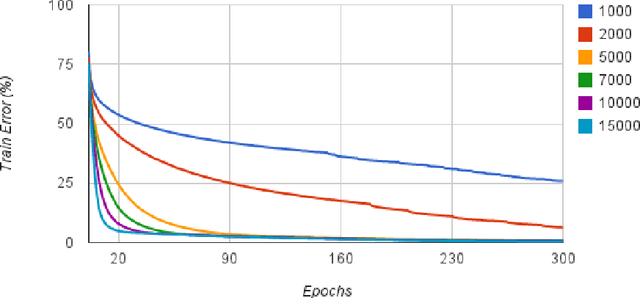
This article exposes the failure of some big neural networks to leverage added capacity to reduce underfitting. Past research suggest diminishing returns when increasing the size of neural networks. Our experiments on ImageNet LSVRC-2010 show that this may be due to the fact there are highly diminishing returns for capacity in terms of training error, leading to underfitting. This suggests that the optimization method - first order gradient descent - fails at this regime. Directly attacking this problem, either through the optimization method or the choices of parametrization, may allow to improve the generalization error on large datasets, for which a large capacity is required.