 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Tale of Two Linkings: Dynamically Gating between Schema Linking and Structural Linking for Text-to-SQL Parsing
Sep 30, 2020
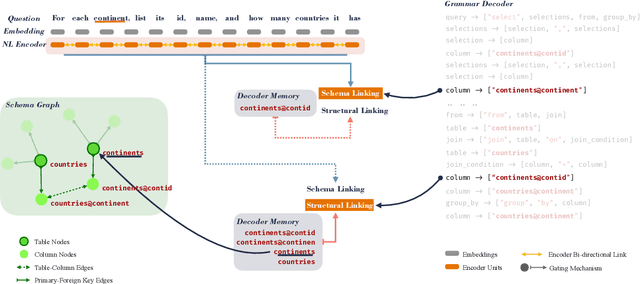
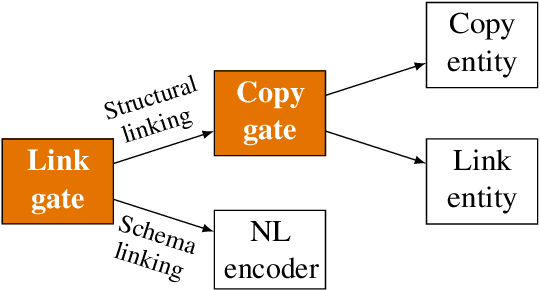

In Text-to-SQL semantic parsing, selecting the correct entities (tables and columns) to output is both crucial and challenging; the parser is required to connect the natural language (NL) question and the current SQL prediction with the structured world, i.e., the database. We formulate two linking processes to address this challenge: schema linking which links explicit NL mentions to the database and structural linking which links the entities in the output SQL with their structural relationships in the database schema. Intuitively, the effects of these two linking processes change based on the entity being generated, thus we propose to dynamically choose between them using a gating mechanism. Integrating the proposed method with two graph neural network based semantic parsers together with BERT representations demonstrates substantial gains in parsing accuracy on the challenging Spider dataset. Analyses show that our method helps to enhance the structure of the model output when generating complicated SQL queries and offers explainable predictions.
HittER: Hierarchical Transformers for Knowledge Graph Embeddings
Aug 28, 2020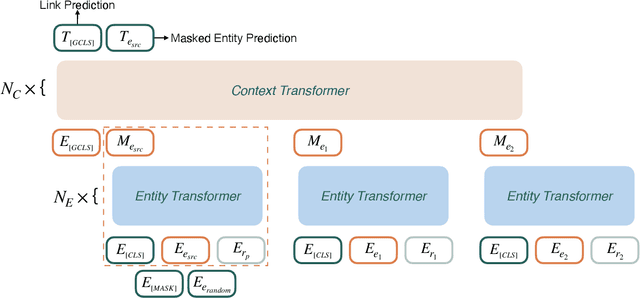
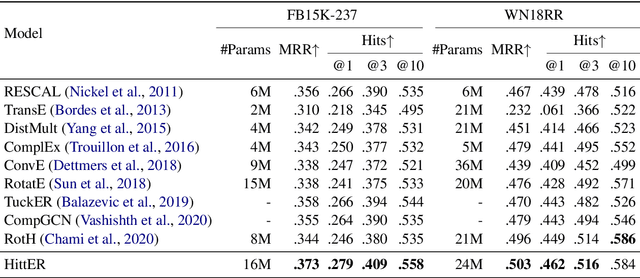
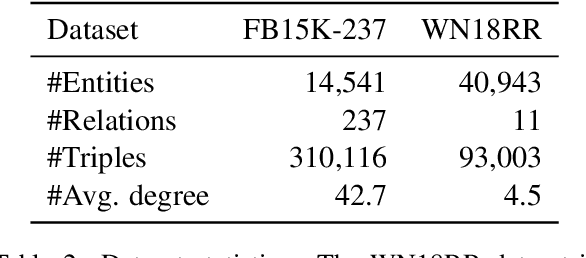

This paper examines the challenging problem of learning representations of entities and relations in a complex multi-relational knowledge graph. We propose HittER, a Hierarchical Transformer model to jointly learn Entity-relation composition and Relational contextualization based on a source entity's neighborhood. Our proposed model consists of two different Transformer blocks: the bottom block extracts features of each entity-relation pair in the local neighborhood of the source entity and the top block aggregates the relational information from the outputs of the bottom block. We further design a masked entity prediction task to balance information from the relational context and the source entity itself. Evaluated on the task of link prediction, our approach achieves new state-of-the-art results on two standard benchmark datasets FB15K-237 and WN18RR.
Pointwise Paraphrase Appraisal is Potentially Problematic
Jun 05, 2020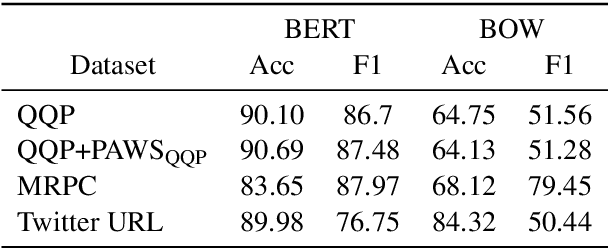
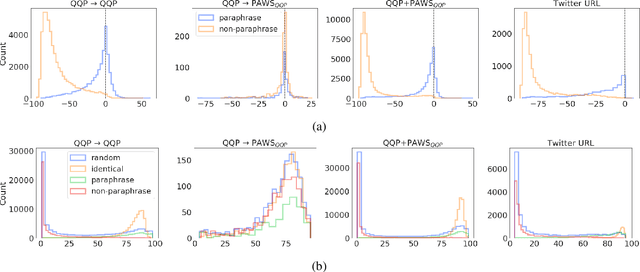
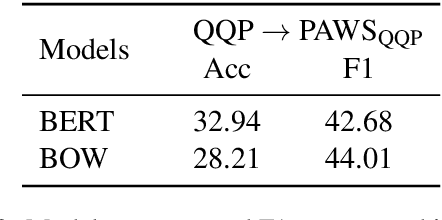
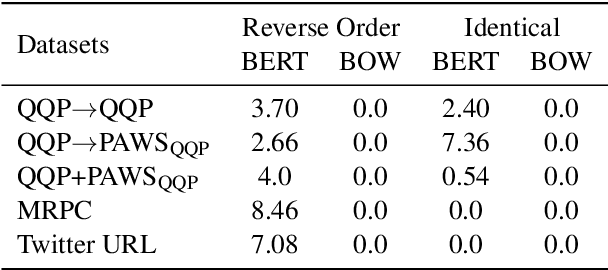
The prevailing approach for training and evaluating paraphrase identification models is constructed as a binary classification problem: the model is given a pair of sentences, and is judged by how accurately it classifies pairs as either paraphrases or non-paraphrases. This pointwise-based evaluation method does not match well the objective of most real world applications, so the goal of our work is to understand how models which perform well under pointwise evaluation may fail in practice and find better methods for evaluating paraphrase identification models. As a first step towards that goal, we show that although the standard way of fine-tuning BERT for paraphrase identification by pairing two sentences as one sequence results in a model with state-of-the-art performance, that model may perform poorly on simple tasks like identifying pairs with two identical sentences. Moreover, we show that these models may even predict a pair of randomly-selected sentences with higher paraphrase score than a pair of identical ones.
Reevaluating Adversarial Examples in Natural Language
Apr 25, 2020
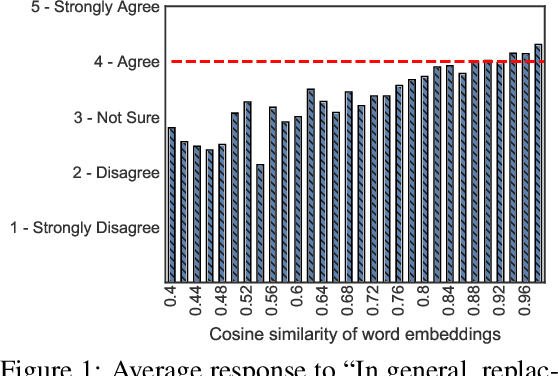
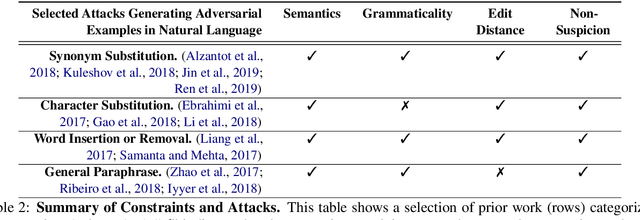
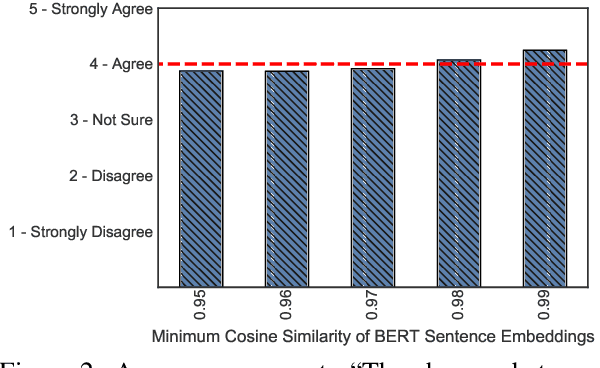
State-of-the-art attacks on NLP models have different definitions of what constitutes a successful attack. These differences make the attacks difficult to compare. We propose to standardize definitions of natural language adversarial examples based on a set of linguistic constraints: semantics, grammaticality, edit distance, and non-suspicion. We categorize previous attacks based on these constraints. For each constraint, we suggest options for human and automatic evaluation methods. We use these methods to evaluate two state-of-the-art synonym substitution attacks. We find that perturbations often do not preserve semantics, and 45\% introduce grammatical errors. Next, we conduct human studies to find a threshold for each evaluation method that aligns with human judgment. Human surveys reveal that to truly preserve semantics, we need to significantly increase the minimum cosine similarity between the embeddings of swapped words and sentence encodings of original and perturbed inputs. After tightening these constraints to agree with the judgment of our human annotators, the attacks produce valid, successful adversarial examples. But quality comes at a cost: attack success rate drops by over 70 percentage points. Finally, we introduce TextAttack, a library for adversarial attacks in NLP.
Generating Hierarchical Explanations on Text Classification via Feature Interaction Detection
Apr 04, 2020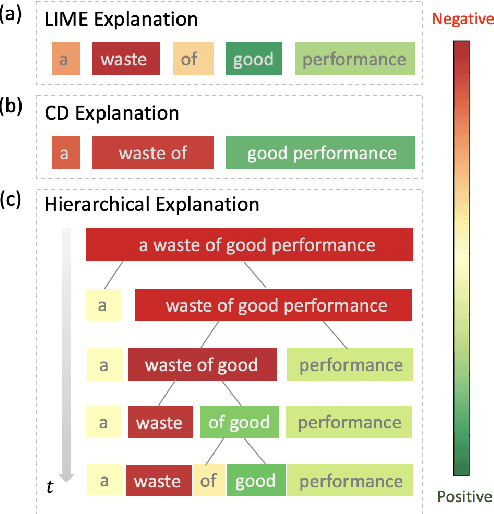
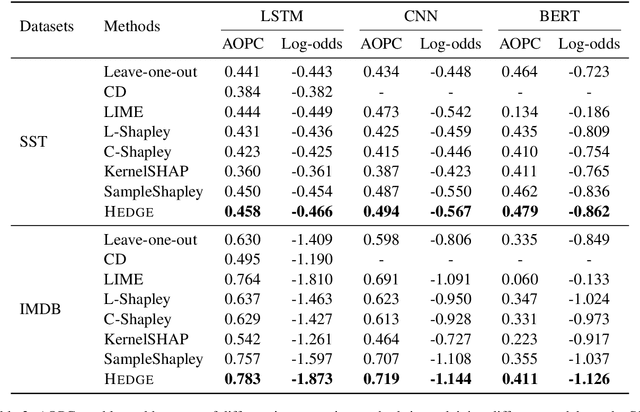
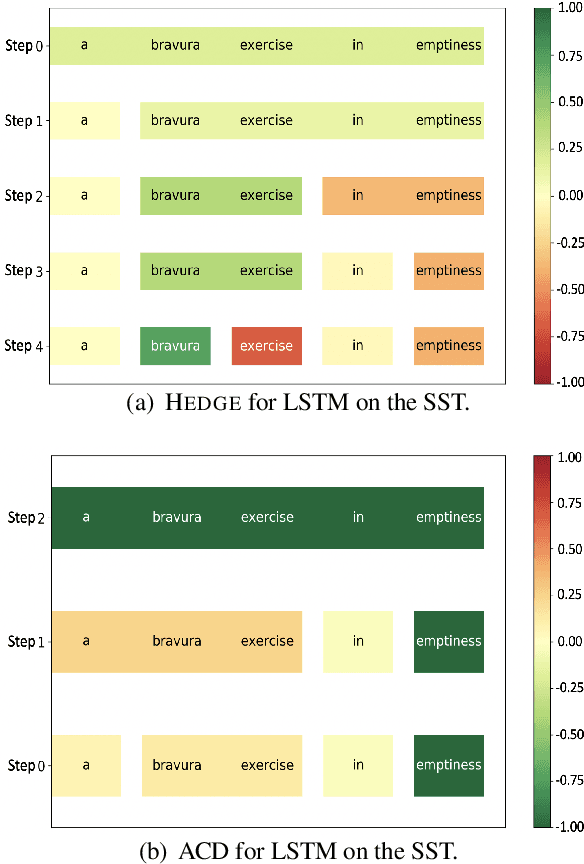
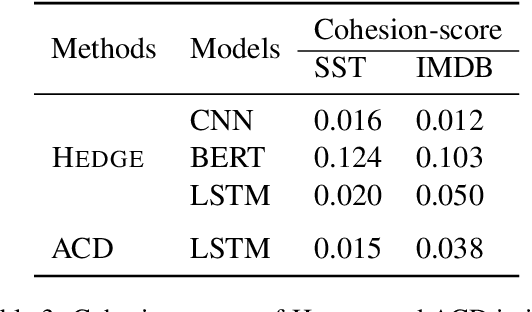
Generating explanations for neural networks has become crucial for their applications in real-world with respect to reliability and trustworthiness. In natural language processing, existing methods usually provide important features which are words or phrases selected from an input text as an explanation, but ignore the interactions between them. It poses challenges for humans to interpret an explanation and connect it to model prediction. In this work, we build hierarchical explanations by detecting feature interactions. Such explanations visualize how words and phrases are combined at different levels of the hierarchy, which can help users understand the decision-making of black-box models. The proposed method is evaluated with three neural text classifiers (LSTM, CNN, and BERT) on two benchmark datasets, via both automatic and human evaluations. Experiments show the effectiveness of the proposed method in providing explanations that are both faithful to models and interpretable to humans.
Improving the Explainability of Neural Sentiment Classifiers via Data Augmentation
Oct 09, 2019

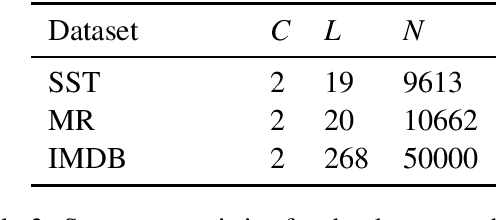
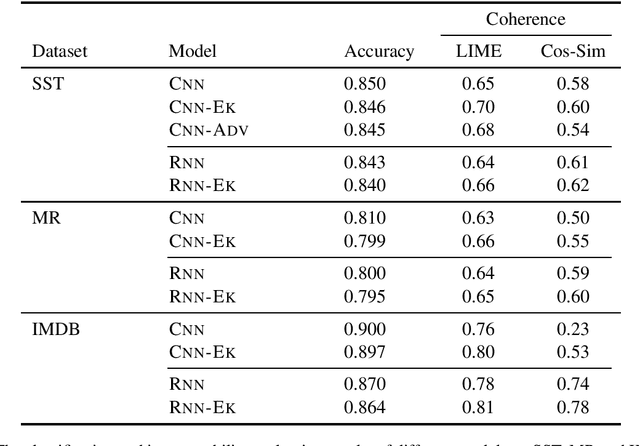
Sentiment analysis has been widely used by businesses for social media opinion mining, especially in the financial services industry, where customers' feedbacks are critical for companies. Recent progress of neural network models has achieved remarkable performance on sentiment classification, while the lack of classification interpretation may raise the trustworthy and many other issues in practice. In this work, we study the problem of improving the explainability of existing sentiment classifiers. We propose two data augmentation methods that create additional training examples to help improve model explainability: one method with a predefined sentiment word list as external knowledge and the other with adversarial examples. We test the proposed methods on both CNN and RNN classifiers with three benchmark sentiment datasets. The model explainability is assessed by both human evaluators and a simple automatic evaluation measurement. Experiments show the proposed data augmentation methods significantly improve the explainability of both neural classifiers.
An Empirical Comparison on Imitation Learning and Reinforcement Learning for Paraphrase Generation
Aug 28, 2019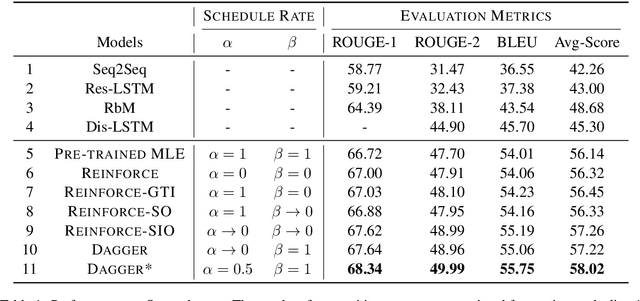
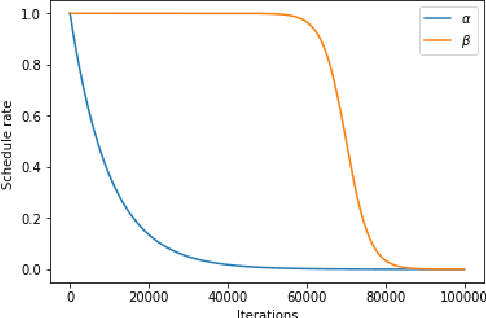
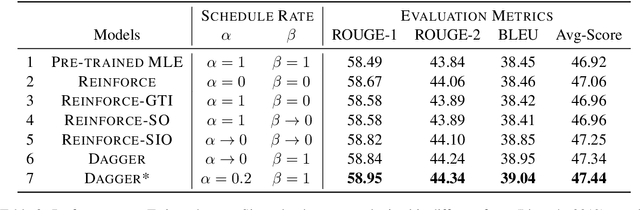
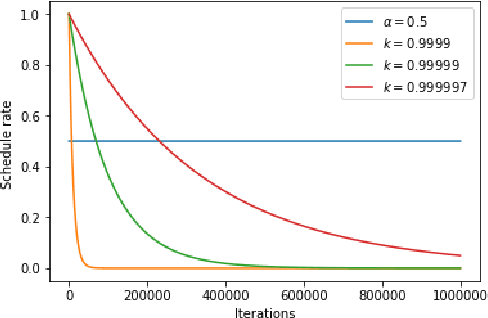
Generating paraphrases from given sentences involves decoding words step by step from a large vocabulary. To learn a decoder, supervised learning which maximizes the likelihood of tokens always suffers from the exposure bias. Although both reinforcement learning (RL) and imitation learning (IL) have been widely used to alleviate the bias, the lack of direct comparison leads to only a partial image on their benefits. In this work, we present an empirical study on how RL and IL can help boost the performance of generating paraphrases, with the pointer-generator as a base model. Experiments on the benchmark datasets show that (1) imitation learning is constantly better than reinforcement learning; and (2) the pointer-generator models with imitation learning outperform the state-of-the-art methods with a large margin.
Dynamic Entity Representations in Neural Language Models
Aug 02, 2017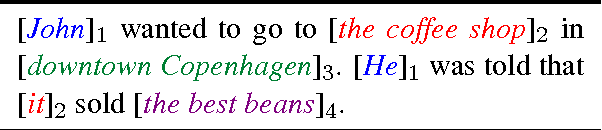

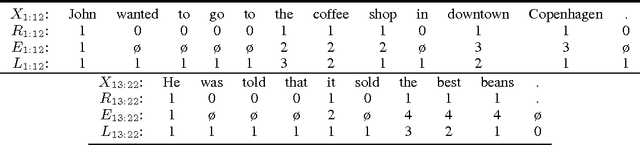

Understanding a long document requires tracking how entities are introduced and evolve over time. We present a new type of language model, EntityNLM, that can explicitly model entities, dynamically update their representations, and contextually generate their mentions. Our model is generative and flexible; it can model an arbitrary number of entities in context while generating each entity mention at an arbitrary length. In addition, it can be used for several different tasks such as language modeling, coreference resolution, and entity prediction. Experimental results with all these tasks demonstrate that our model consistently outperforms strong baselines and prior work.
Neural Discourse Structure for Text Categorization
May 06, 2017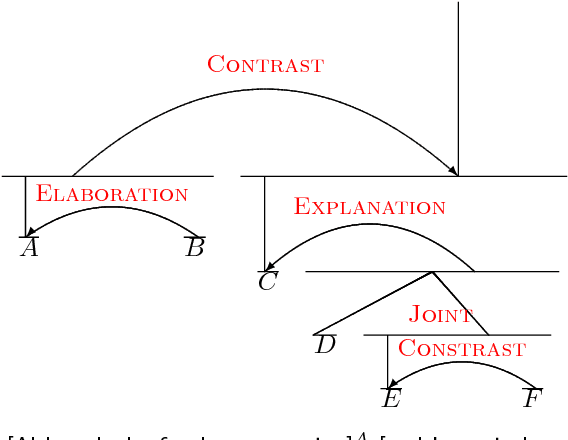
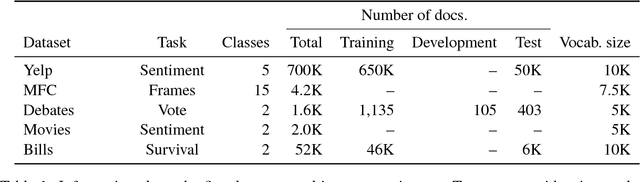
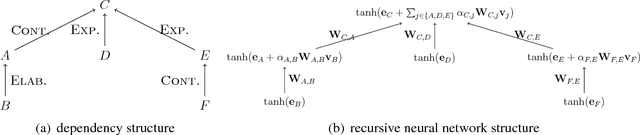
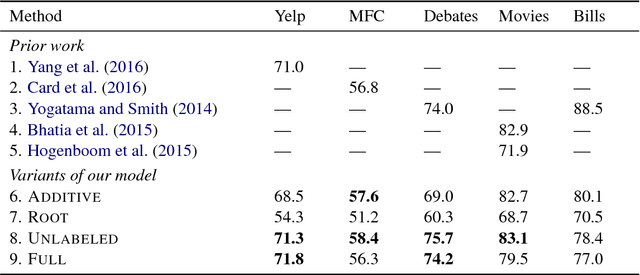
We show that discourse structure, as defined by Rhetorical Structure Theory and provided by an existing discourse parser, benefits text categorization. Our approach uses a recursive neural network and a newly proposed attention mechanism to compute a representation of the text that focuses on salient content, from the perspective of both RST and the task. Experiments consider variants of the approach and illustrate its strengths and weaknesses.
DyNet: The Dynamic Neural Network Toolkit
Jan 15, 2017
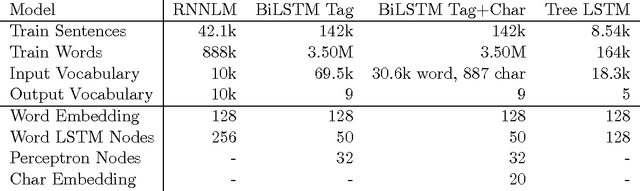

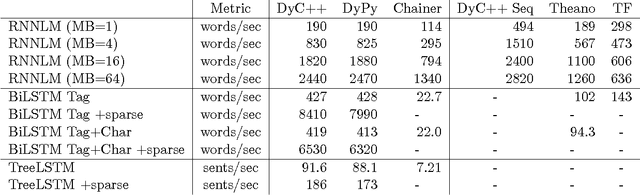
We describe DyNet, a toolkit for implementing neural network models based on dynamic declaration of network structure. In the static declaration strategy that is used in toolkits like Theano, CNTK, and TensorFlow, the user first defines a computation graph (a symbolic representation of the computation), and then examples are fed into an engine that executes this computation and computes its derivatives. In DyNet's dynamic declaration strategy, computation graph construction is mostly transparent, being implicitly constructed by executing procedural code that computes the network outputs, and the user is free to use different network structures for each input. Dynamic declaration thus facilitates the implementation of more complicated network architectures, and DyNet is specifically designed to allow users to implement their models in a way that is idiomatic in their preferred programming language (C++ or Python). One challenge with dynamic declaration is that because the symbolic computation graph is defined anew for every training example, its construction must have low overhead. To achieve this, DyNet has an optimized C++ backend and lightweight graph representation. Experiments show that DyNet's speeds are faster than or comparable with static declaration toolkits, and significantly faster than Chainer, another dynamic declaration toolkit. DyNet is released open-source under the Apache 2.0 license and available at http://github.com/clab/dynet.