 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkeleton-based Action Recognition through Contrasting Two-Stream Spatial-Temporal Networks
Jan 27, 2023



For pursuing accurate skeleton-based action recognition, most prior methods use the strategy of combining Graph Convolution Networks (GCNs) with attention-based methods in a serial way. However, they regard the human skeleton as a complete graph, resulting in less variations between different actions (e.g., the connection between the elbow and head in action ``clapping hands''). For this, we propose a novel Contrastive GCN-Transformer Network (ConGT) which fuses the spatial and temporal modules in a parallel way. The ConGT involves two parallel streams: Spatial-Temporal Graph Convolution stream (STG) and Spatial-Temporal Transformer stream (STT). The STG is designed to obtain action representations maintaining the natural topology structure of the human skeleton. The STT is devised to acquire action representations containing the global relationships among joints. Since the action representations produced from these two streams contain different characteristics, and each of them knows little information of the other, we introduce the contrastive learning paradigm to guide their output representations of the same sample to be as close as possible in a self-supervised manner. Through the contrastive learning, they can learn information from each other to enrich the action features by maximizing the mutual information between the two types of action representations. To further improve action recognition accuracy, we introduce the Cyclical Focal Loss (CFL) which can focus on confident training samples in early training epochs, with an increasing focus on hard samples during the middle epochs. We conduct experiments on three benchmark datasets, which demonstrate that our model achieves state-of-the-art performance in action recognition.
Deepfake Detection via Joint Unsupervised Reconstruction and Supervised Classification
Dec 11, 2022



Deep learning has enabled realistic face manipulation (i.e., deepfake), which poses significant concerns over the integrity of the media in circulation. Most existing deep learning techniques for deepfake detection can achieve promising performance in the intra-dataset evaluation setting (i.e., training and testing on the same dataset), but are unable to perform satisfactorily in the inter-dataset evaluation setting (i.e., training on one dataset and testing on another). Most of the previous methods use the backbone network to extract global features for making predictions and only employ binary supervision (i.e., indicating whether the training instances are fake or authentic) to train the network. Classification merely based on the learning of global features leads often leads to weak generalizability to unseen manipulation methods. In addition, the reconstruction task can improve the learned representations. In this paper, we introduce a novel approach for deepfake detection, which considers the reconstruction and classification tasks simultaneously to address these problems. This method shares the information learned by one task with the other, which focuses on a different aspect other existing works rarely consider and hence boosts the overall performance. In particular, we design a two-branch Convolutional AutoEncoder (CAE), in which the Convolutional Encoder used to compress the feature map into the latent representation is shared by both branches. Then the latent representation of the input data is fed to a simple classifier and the unsupervised reconstruction component simultaneously. Our network is trained end-to-end. Experiments demonstrate that our method achieves state-of-the-art performance on three commonly-used datasets, particularly in the cross-dataset evaluation setting.
Graph Classification via Discriminative Edge Feature Learning
Oct 05, 2022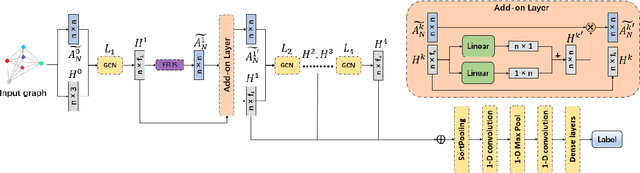
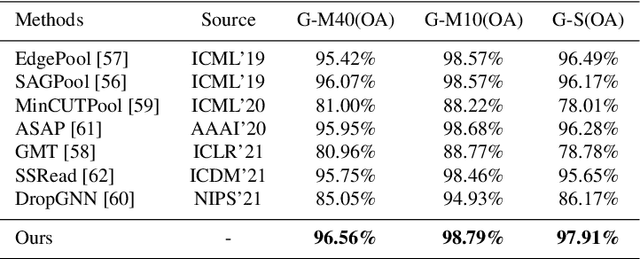
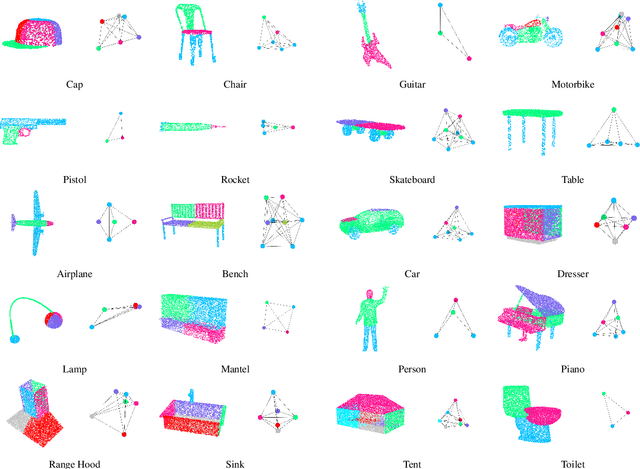
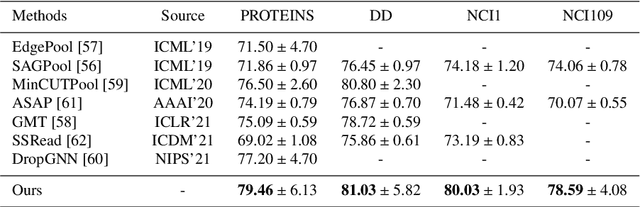
Spectral graph convolutional neural networks (GCNNs) have been producing encouraging results in graph classification tasks. However, most spectral GCNNs utilize fixed graphs when aggregating node features, while omitting edge feature learning and failing to get an optimal graph structure. Moreover, many existing graph datasets do not provide initialized edge features, further restraining the ability of learning edge features via spectral GCNNs. In this paper, we try to address this issue by designing an edge feature scheme and an add-on layer between every two stacked graph convolution layers in GCNN. Both are lightweight while effective in filling the gap between edge feature learning and performance enhancement of graph classification. The edge feature scheme makes edge features adapt to node representations at different graph convolution layers. The add-on layers help adjust the edge features to an optimal graph structure. To test the effectiveness of our method, we take Euclidean positions as initial node features and extract graphs with semantic information from point cloud objects. The node features of our extracted graphs are more scalable for edge feature learning than most existing graph datasets (in one-hot encoded label format). Three new graph datasets are constructed based on ModelNet40, ModelNet10 and ShapeNet Part datasets. Experimental results show that our method outperforms state-of-the-art graph classification methods on the new datasets by reaching 96.56% overall accuracy on Graph-ModelNet40, 98.79% on Graph-ModelNet10 and 97.91% on Graph-ShapeNet Part. The constructed graph datasets will be released to the community.
SPCNet: Stepwise Point Cloud Completion Network
Sep 05, 2022
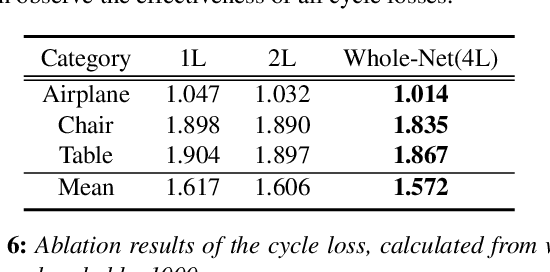
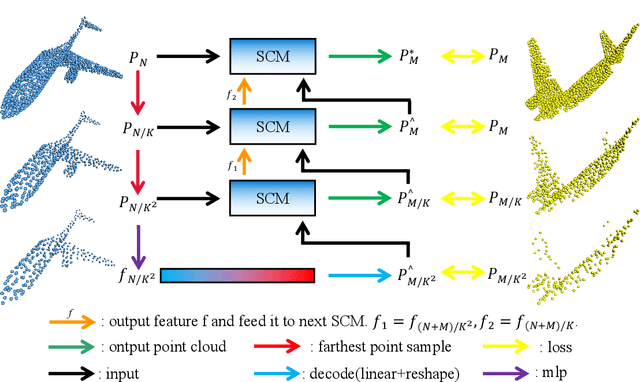
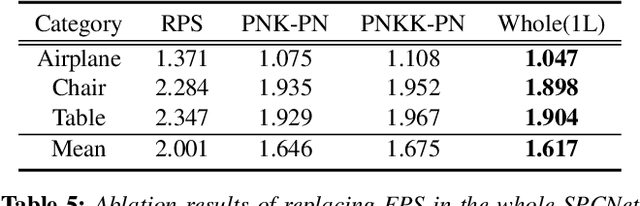
How will you repair a physical object with large missings? You may first recover its global yet coarse shape and stepwise increase its local details. We are motivated to imitate the above physical repair procedure to address the point cloud completion task. We propose a novel stepwise point cloud completion network (SPCNet) for various 3D models with large missings. SPCNet has a hierarchical bottom-to-up network architecture. It fulfills shape completion in an iterative manner, which 1) first infers the global feature of the coarse result; 2) then infers the local feature with the aid of global feature; and 3) finally infers the detailed result with the help of local feature and coarse result. Beyond the wisdom of simulating the physical repair, we newly design a cycle loss %based training strategy to enhance the generalization and robustness of SPCNet. Extensive experiments clearly show the superiority of our SPCNet over the state-of-the-art methods on 3D point clouds with large missings.
SO-Pose: SO-Equivariance Learning for 6D Object Pose Estimation
Aug 17, 2022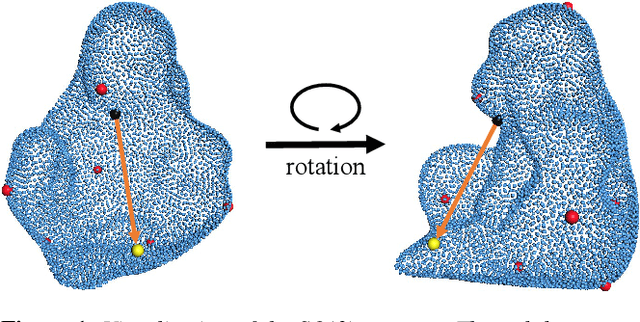
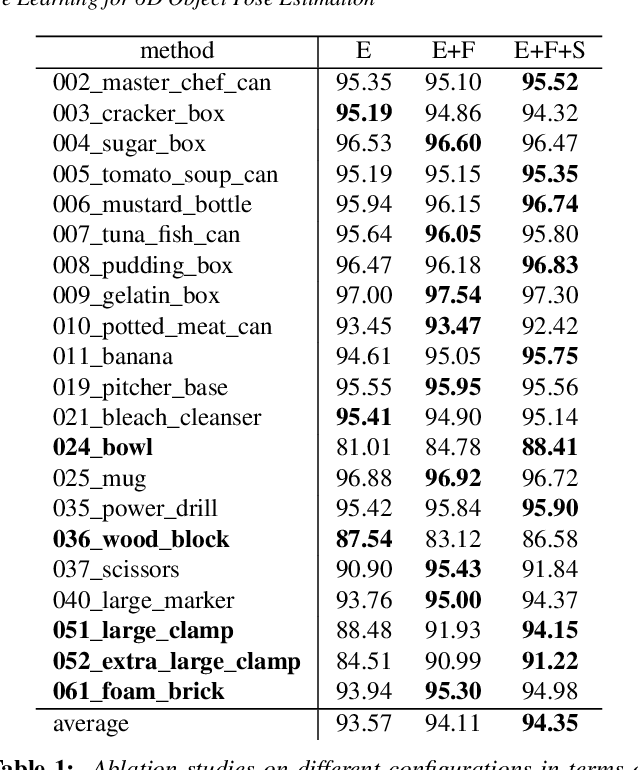

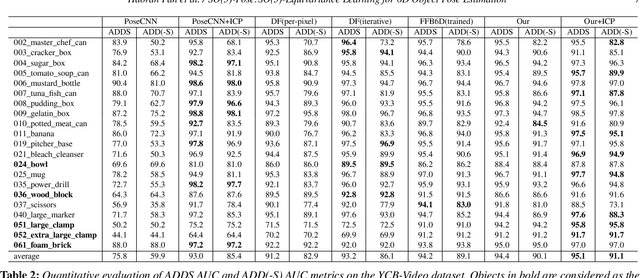
6D pose estimation of rigid objects from RGB-D images is crucial for object grasping and manipulation in robotics. Although RGB channels and the depth (D) channel are often complementary, providing respectively the appearance and geometry information, it is still non-trivial how to fully benefit from the two cross-modal data. From the simple yet new observation, when an object rotates, its semantic label is invariant to the pose while its keypoint offset direction is variant to the pose. To this end, we present SO(3)-Pose, a new representation learning network to explore SO(3)-equivariant and SO(3)-invariant features from the depth channel for pose estimation. The SO(3)-invariant features facilitate to learn more distinctive representations for segmenting objects with similar appearance from RGB channels. The SO(3)-equivariant features communicate with RGB features to deduce the (missed) geometry for detecting keypoints of an object with the reflective surface from the depth channel. Unlike most of existing pose estimation methods, our SO(3)-Pose not only implements the information communication between the RGB and depth channels, but also naturally absorbs the SO(3)-equivariance geometry knowledge from depth images, leading to better appearance and geometry representation learning. Comprehensive experiments show that our method achieves the state-of-the-art performance on three benchmarks.
Contrastive Learning for Joint Normal Estimation and Point Cloud Filtering
Aug 14, 2022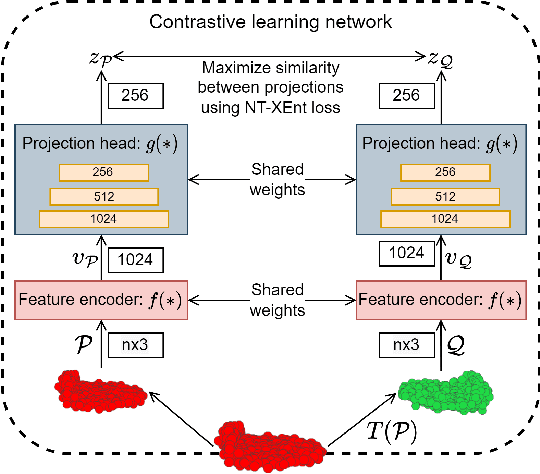
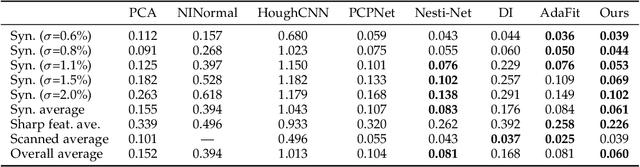
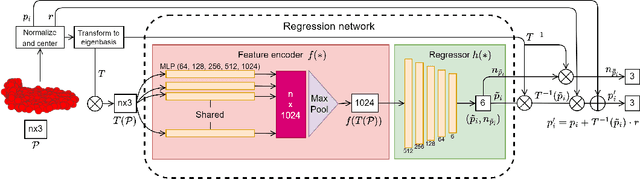
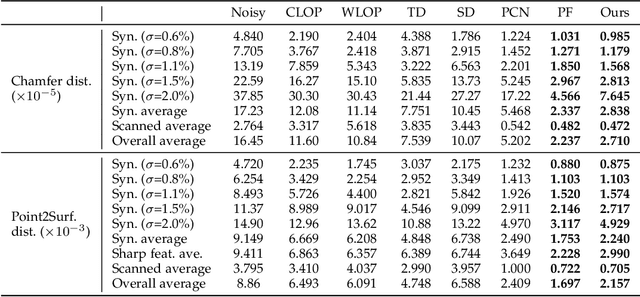
Point cloud filtering and normal estimation are two fundamental research problems in the 3D field. Existing methods usually perform normal estimation and filtering separately and often show sensitivity to noise and/or inability to preserve sharp geometric features such as corners and edges. In this paper, we propose a novel deep learning method to jointly estimate normals and filter point clouds. We first introduce a 3D patch based contrastive learning framework, with noise corruption as an augmentation, to train a feature encoder capable of generating faithful representations of point cloud patches while remaining robust to noise. These representations are consumed by a simple regression network and supervised by a novel joint loss, simultaneously estimating point normals and displacements that are used to filter the patch centers. Experimental results show that our method well supports the two tasks simultaneously and preserves sharp features and fine details. It generally outperforms state-of-the-art techniques on both tasks.
Masked Autoencoders in 3D Point Cloud Representation Learning
Jul 04, 2022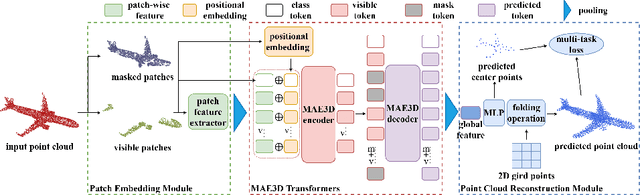



Transformer-based Self-supervised Representation Learning methods learn generic features from unlabeled datasets for providing useful network initialization parameters for downstream tasks. Recently, self-supervised learning based upon masking local surface patches for 3D point cloud data has been under-explored. In this paper, we propose masked Autoencoders in 3D point cloud representation learning (abbreviated as MAE3D), a novel autoencoding paradigm for self-supervised learning. We first split the input point cloud into patches and mask a portion of them, then use our Patch Embedding Module to extract the features of unmasked patches. Secondly, we employ patch-wise MAE3D Transformers to learn both local features of point cloud patches and high-level contextual relationships between patches and complete the latent representations of masked patches. We use our Point Cloud Reconstruction Module with multi-task loss to complete the incomplete point cloud as a result. We conduct self-supervised pre-training on ShapeNet55 with the point cloud completion pre-text task and fine-tune the pre-trained model on ModelNet40 and ScanObjectNN (PB\_T50\_RS, the hardest variant). Comprehensive experiments demonstrate that the local features extracted by our MAE3D from point cloud patches are beneficial for downstream classification tasks, soundly outperforming state-of-the-art methods ($93.4\%$ and $86.2\%$ classification accuracy, respectively).
CREAM: Weakly Supervised Object Localization via Class RE-Activation Mapping
May 27, 2022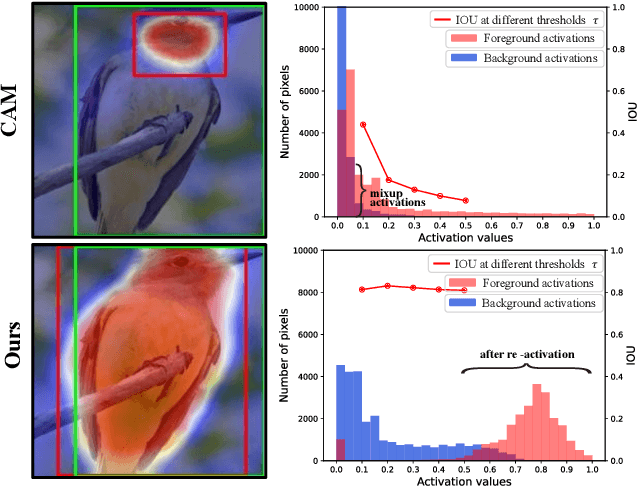
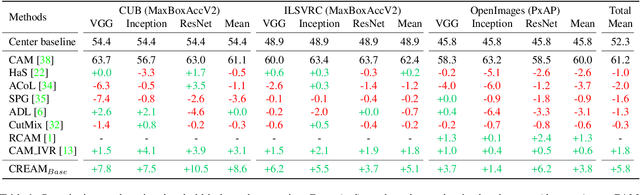
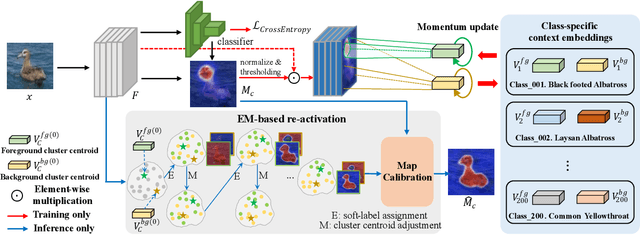
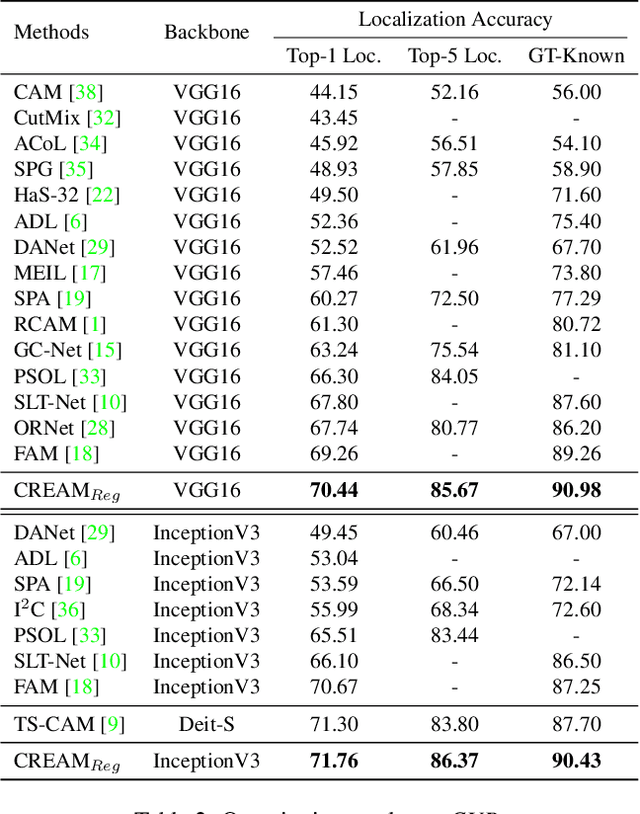
Weakly Supervised Object Localization (WSOL) aims to localize objects with image-level supervision. Existing works mainly rely on Class Activation Mapping (CAM) derived from a classification model. However, CAM-based methods usually focus on the most discriminative parts of an object (i.e., incomplete localization problem). In this paper, we empirically prove that this problem is associated with the mixup of the activation values between less discriminative foreground regions and the background. To address it, we propose Class RE-Activation Mapping (CREAM), a novel clustering-based approach to boost the activation values of the integral object regions. To this end, we introduce class-specific foreground and background context embeddings as cluster centroids. A CAM-guided momentum preservation strategy is developed to learn the context embeddings during training. At the inference stage, the re-activation mapping is formulated as a parameter estimation problem under Gaussian Mixture Model, which can be solved by deriving an unsupervised Expectation-Maximization based soft-clustering algorithm. By simply integrating CREAM into various WSOL approaches, our method significantly improves their performance. CREAM achieves the state-of-the-art performance on CUB, ILSVRC and OpenImages benchmark datasets. Code will be available at https://github.com/Jazzcharles/CREAM.
AI-based Carcinoma Detection and Classification Using Histopathological Images: A Systematic Review
Jan 18, 2022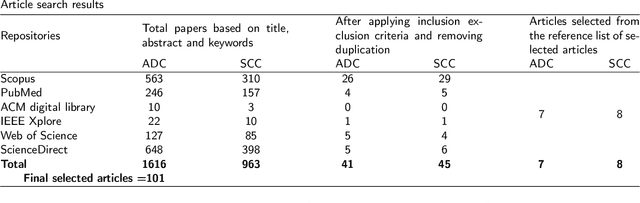
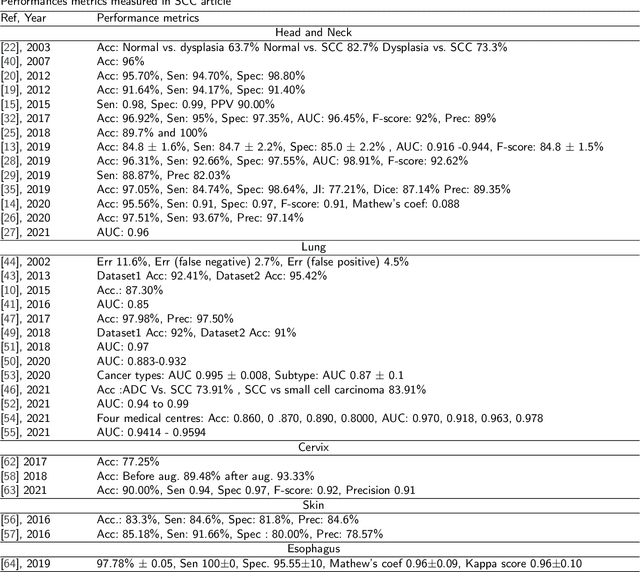

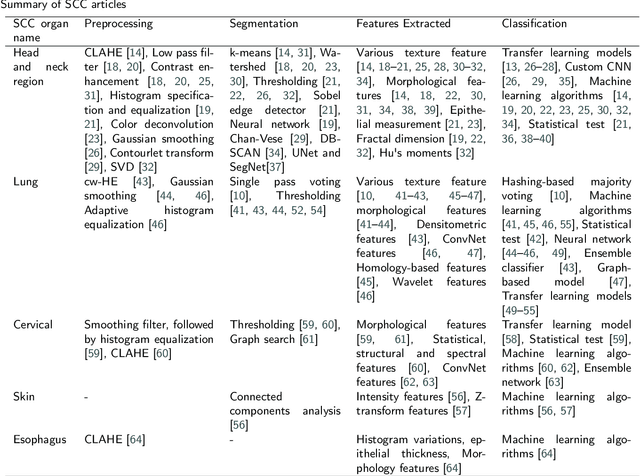
Histopathological image analysis is the gold standard to diagnose cancer. Carcinoma is a subtype of cancer that constitutes more than 80% of all cancer cases. Squamous cell carcinoma and adenocarcinoma are two major subtypes of carcinoma, diagnosed by microscopic study of biopsy slides. However, manual microscopic evaluation is a subjective and time-consuming process. Many researchers have reported methods to automate carcinoma detection and classification. The increasing use of artificial intelligence (AI) in the automation of carcinoma diagnosis also reveals a significant rise in the use of deep network models. In this systematic literature review, we present a comprehensive review of the state-of-the-art approaches reported in carcinoma diagnosis using histopathological images. Studies are selected from well-known databases with strict inclusion/exclusion criteria. We have categorized the articles and recapitulated their methods based on specific organs of carcinoma origin. Further, we have summarized pertinent literature on AI methods, highlighted critical challenges and limitations, and provided insights on future research direction in automated carcinoma diagnosis. Out of 101 articles selected, most of the studies experimented on private datasets with varied image sizes, obtaining accuracy between 63% and 100%. Overall, this review highlights the need for a generalized AI-based carcinoma diagnostic system. Additionally, it is desirable to have accountable approaches to extract microscopic features from images of multiple magnifications that should mimic pathologists' evaluations.
Towards Uniform Point Distribution in Feature-preserving Point Cloud Filtering
Jan 17, 2022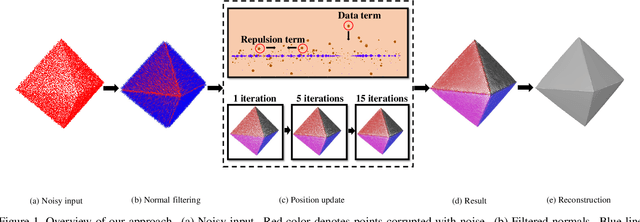
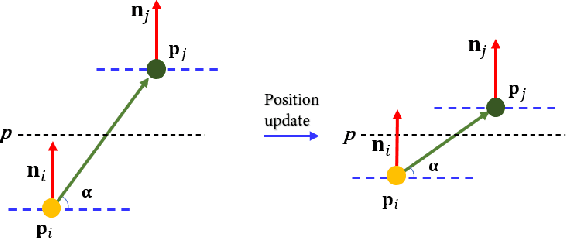
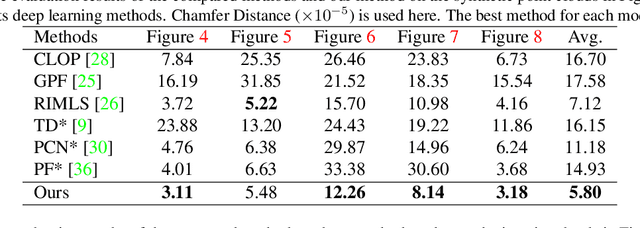
As a popular representation of 3D data, point cloud may contain noise and need to be filtered before use. Existing point cloud filtering methods either cannot preserve sharp features or result in uneven point distribution in the filtered output. To address this problem, this paper introduces a point cloud filtering method that considers both point distribution and feature preservation during filtering. The key idea is to incorporate a repulsion term with a data term in energy minimization. The repulsion term is responsible for the point distribution, while the data term is to approximate the noisy surfaces while preserving the geometric features. This method is capable of handling models with fine-scale features and sharp features. Extensive experiments show that our method yields better results with a more uniform point distribution ($5.8\times10^{-5}$ Chamfer Distance on average) in seconds.