 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeP2Seg: Pointly-supervised Segmentation via Mutual Distillation
Jan 18, 2024Point-level Supervised Instance Segmentation (PSIS) aims to enhance the applicability and scalability of instance segmentation by utilizing low-cost yet instance-informative annotations. Existing PSIS methods usually rely on positional information to distinguish objects, but predicting precise boundaries remains challenging due to the lack of contour annotations. Nevertheless, weakly supervised semantic segmentation methods are proficient in utilizing intra-class feature consistency to capture the boundary contours of the same semantic regions. In this paper, we design a Mutual Distillation Module (MDM) to leverage the complementary strengths of both instance position and semantic information and achieve accurate instance-level object perception. The MDM consists of Semantic to Instance (S2I) and Instance to Semantic (I2S). S2I is guided by the precise boundaries of semantic regions to learn the association between annotated points and instance contours. I2S leverages discriminative relationships between instances to facilitate the differentiation of various objects within the semantic map. Extensive experiments substantiate the efficacy of MDM in fostering the synergy between instance and semantic information, consequently improving the quality of instance-level object representations. Our method achieves 55.7 mAP$_{50}$ and 17.6 mAP on the PASCAL VOC and MS COCO datasets, significantly outperforming recent PSIS methods and several box-supervised instance segmentation competitors.
Semantic-aware SAM for Point-Prompted Instance Segmentation
Dec 26, 2023



Single-point annotation in visual tasks, with the goal of minimizing labelling costs, is becoming increasingly prominent in research. Recently, visual foundation models, such as Segment Anything (SAM), have gained widespread usage due to their robust zero-shot capabilities and exceptional annotation performance. However, SAM's class-agnostic output and high confidence in local segmentation introduce 'semantic ambiguity', posing a challenge for precise category-specific segmentation. In this paper, we introduce a cost-effective category-specific segmenter using SAM. To tackle this challenge, we have devised a Semantic-Aware Instance Segmentation Network (SAPNet) that integrates Multiple Instance Learning (MIL) with matching capability and SAM with point prompts. SAPNet strategically selects the most representative mask proposals generated by SAM to supervise segmentation, with a specific focus on object category information. Moreover, we introduce the Point Distance Guidance and Box Mining Strategy to mitigate inherent challenges: 'group' and 'local' issues in weakly supervised segmentation. These strategies serve to further enhance the overall segmentation performance. The experimental results on Pascal VOC and COCO demonstrate the promising performance of our proposed SAPNet, emphasizing its semantic matching capabilities and its potential to advance point-prompted instance segmentation. The code will be made publicly available.
Boosting Segment Anything Model Towards Open-Vocabulary Learning
Dec 06, 2023



The recent Segment Anything Model (SAM) has emerged as a new paradigmatic vision foundation model, showcasing potent zero-shot generalization and flexible prompting. Despite SAM finding applications and adaptations in various domains, its primary limitation lies in the inability to grasp object semantics. In this paper, we present Sambor to seamlessly integrate SAM with the open-vocabulary object detector in an end-to-end framework. While retaining all the remarkable capabilities inherent to SAM, we enhance it with the capacity to detect arbitrary objects based on human inputs like category names or reference expressions. To accomplish this, we introduce a novel SideFormer module that extracts SAM features to facilitate zero-shot object localization and inject comprehensive semantic information for open-vocabulary recognition. In addition, we devise an open-set region proposal network (Open-set RPN), enabling the detector to acquire the open-set proposals generated by SAM. Sambor demonstrates superior zero-shot performance across benchmarks, including COCO and LVIS, proving highly competitive against previous SoTA methods. We aspire for this work to serve as a meaningful endeavor in endowing SAM to recognize diverse object categories and advancing open-vocabulary learning with the support of vision foundation models.
P2RBox: A Single Point is All You Need for Oriented Object Detection
Nov 22, 2023



Oriented object detection, a specialized subfield in computer vision, finds applications across diverse scenarios, excelling particularly when dealing with objects of arbitrary orientations. Conversely, point annotation, which treats objects as single points, offers a cost-effective alternative to rotated and horizontal bounding boxes but sacrifices performance due to the loss of size and orientation information. In this study, we introduce the P2RBox network, which leverages point annotations and a mask generator to create mask proposals, followed by filtration through our Inspector Module and Constrainer Module. This process selects high-quality masks, which are subsequently converted into rotated box annotations for training a fully supervised detector. Specifically, we've thoughtfully crafted an Inspector Module rooted in multi-instance learning principles to evaluate the semantic score of masks. We've also proposed a more robust mask quality assessment in conjunction with the Constrainer Module. Furthermore, we've introduced a Symmetry Axis Estimation (SAE) Module inspired by the spectral theorem for symmetric matrices to transform the top-performing mask proposal into rotated bounding boxes. P2RBox performs well with three fully supervised rotated object detectors: RetinaNet, Rotated FCOS, and Oriented R-CNN. By combining with Oriented R-CNN, P2RBox achieves 62.26% on DOTA-v1.0 test dataset. As far as we know, this is the first attempt at training an oriented object detector with point supervision.
Spatial Self-Distillation for Object Detection with Inaccurate Bounding Boxes
Aug 15, 2023



Object detection via inaccurate bounding boxes supervision has boosted a broad interest due to the expensive high-quality annotation data or the occasional inevitability of low annotation quality (\eg tiny objects). The previous works usually utilize multiple instance learning (MIL), which highly depends on category information, to select and refine a low-quality box. Those methods suffer from object drift, group prediction and part domination problems without exploring spatial information. In this paper, we heuristically propose a \textbf{Spatial Self-Distillation based Object Detector (SSD-Det)} to mine spatial information to refine the inaccurate box in a self-distillation fashion. SSD-Det utilizes a Spatial Position Self-Distillation \textbf{(SPSD)} module to exploit spatial information and an interactive structure to combine spatial information and category information, thus constructing a high-quality proposal bag. To further improve the selection procedure, a Spatial Identity Self-Distillation \textbf{(SISD)} module is introduced in SSD-Det to obtain spatial confidence to help select the best proposals. Experiments on MS-COCO and VOC datasets with noisy box annotation verify our method's effectiveness and achieve state-of-the-art performance. The code is available at https://github.com/ucas-vg/PointTinyBenchmark/tree/SSD-Det.
Causal Coupled Mechanisms: A Control Method with Cooperation and Competition for Complex System
Sep 15, 2022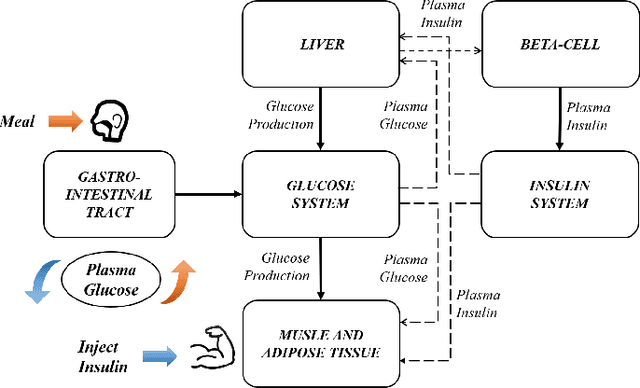

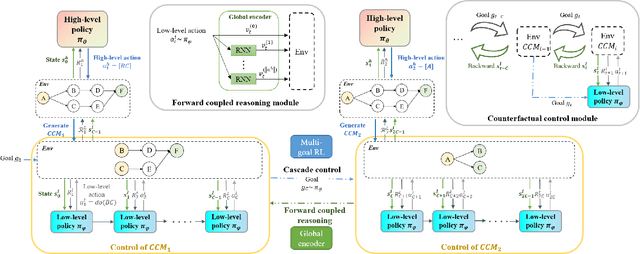
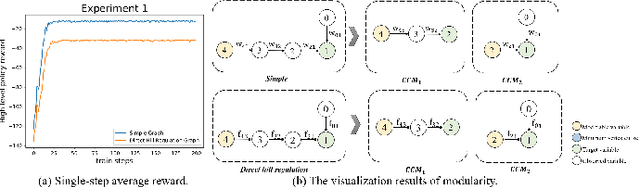
Complex systems are ubiquitous in the real world and tend to have complicated and poorly understood dynamics. For their control issues, the challenge is to guarantee accuracy, robustness, and generalization in such bloated and troubled environments. Fortunately, a complex system can be divided into multiple modular structures that human cognition appears to exploit. Inspired by this cognition, a novel control method, Causal Coupled Mechanisms (CCMs), is proposed that explores the cooperation in division and competition in combination. Our method employs the theory of hierarchical reinforcement learning (HRL), in which 1) the high-level policy with competitive awareness divides the whole complex system into multiple functional mechanisms, and 2) the low-level policy finishes the control task of each mechanism. Specifically for cooperation, a cascade control module helps the series operation of CCMs, and a forward coupled reasoning module is used to recover the coupling information lost in the division process. On both synthetic systems and a real-world biological regulatory system, the CCM method achieves robust and state-of-the-art control results even with unpredictable random noise. Moreover, generalization results show that reusing prepared specialized CCMs helps to perform well in environments with different confounders and dynamics.
Point-to-Box Network for Accurate Object Detection via Single Point Supervision
Jul 14, 2022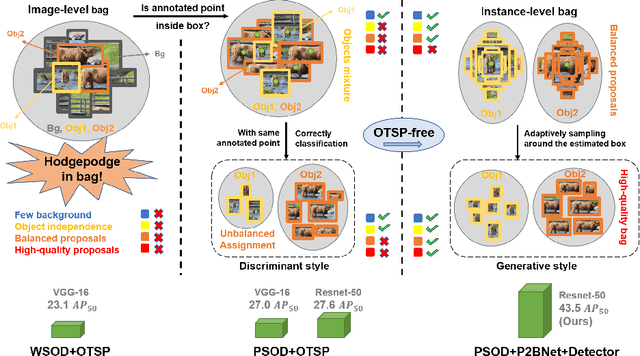
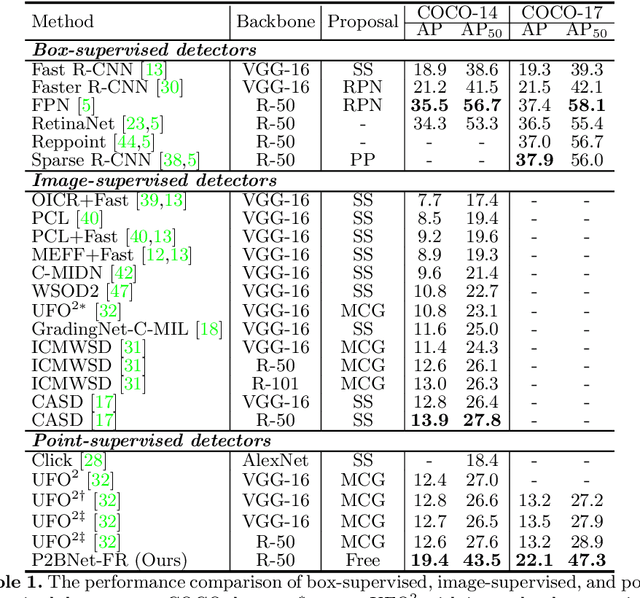
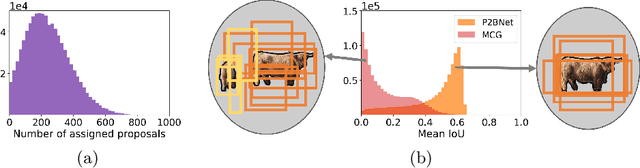
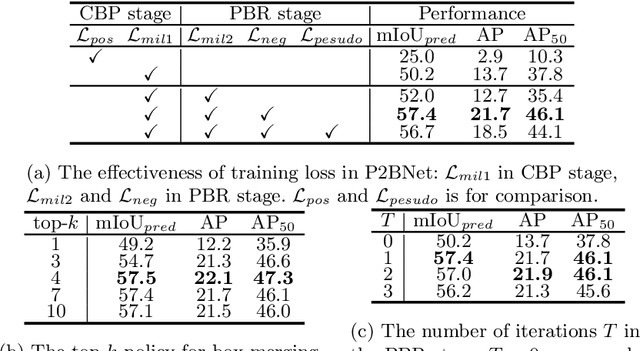
Object detection using single point supervision has received increasing attention over the years. In this paper, we attribute such a large performance gap to the failure of generating high-quality proposal bags which are crucial for multiple instance learning (MIL). To address this problem, we introduce a lightweight alternative to the off-the-shelf proposal (OTSP) method and thereby create the Point-to-Box Network (P2BNet), which can construct an inter-objects balanced proposal bag by generating proposals in an anchor-like way. By fully investigating the accurate position information, P2BNet further constructs an instance-level bag, avoiding the mixture of multiple objects. Finally, a coarse-to-fine policy in a cascade fashion is utilized to improve the IoU between proposals and ground-truth (GT). Benefiting from these strategies, P2BNet is able to produce high-quality instance-level bags for object detection. P2BNet improves the mean average precision (AP) by more than 50% relative to the previous best PSOD method on the MS COCO dataset. It also demonstrates the great potential to bridge the performance gap between point supervised and bounding-box supervised detectors. The code will be released at github.com/ucas-vg/P2BNet.
Object Localization under Single Coarse Point Supervision
Mar 17, 2022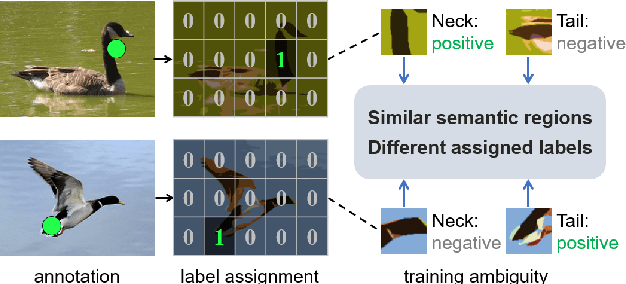
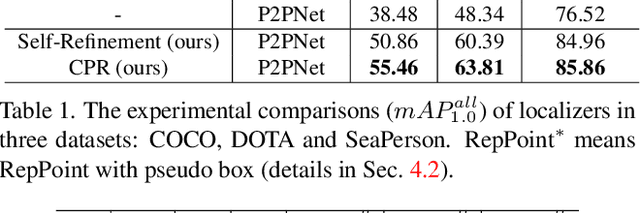

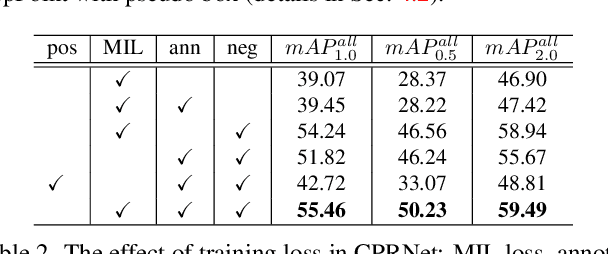
Point-based object localization (POL), which pursues high-performance object sensing under low-cost data annotation, has attracted increased attention. However, the point annotation mode inevitably introduces semantic variance for the inconsistency of annotated points. Existing POL methods heavily reply on accurate key-point annotations which are difficult to define. In this study, we propose a POL method using coarse point annotations, relaxing the supervision signals from accurate key points to freely spotted points. To this end, we propose a coarse point refinement (CPR) approach, which to our best knowledge is the first attempt to alleviate semantic variance from the perspective of algorithm. CPR constructs point bags, selects semantic-correlated points, and produces semantic center points through multiple instance learning (MIL). In this way, CPR defines a weakly supervised evolution procedure, which ensures training high-performance object localizer under coarse point supervision. Experimental results on COCO, DOTA and our proposed SeaPerson dataset validate the effectiveness of the CPR approach. The dataset and code will be available at https://github.com/ucas-vg/PointTinyBenchmark/.
P2P-Loc: Point to Point Tiny Person Localization
Jan 05, 2022

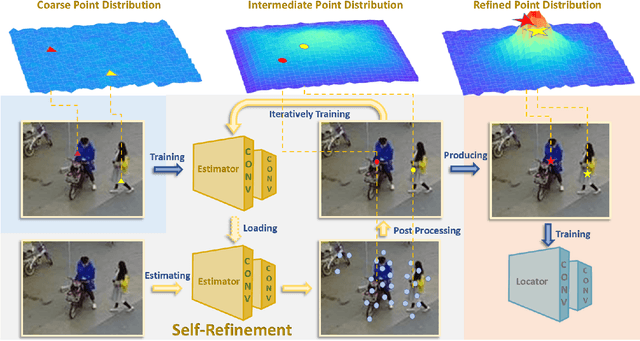

Bounding-box annotation form has been the most frequently used method for visual object localization tasks. However, bounding-box annotation relies on a large amount of precisely annotating bounding boxes, and it is expensive and laborious. It is impossible to be employed in practical scenarios and even redundant for some applications (such as tiny person localization) that the size would not matter. Therefore, we propose a novel point-based framework for the person localization task by annotating each person as a coarse point (CoarsePoint) instead of an accurate bounding box that can be any point within the object extent. Then, the network predicts the person's location as a 2D coordinate in the image. Although this greatly simplifies the data annotation pipeline, the CoarsePoint annotation inevitably decreases label reliability (label uncertainty) and causes network confusion during training. As a result, we propose a point self-refinement approach that iteratively updates point annotations in a self-paced way. The proposed refinement system alleviates the label uncertainty and progressively improves localization performance. Experimental results show that our approach has achieved comparable object localization performance while saving up to 80$\%$ of annotation cost.
Group Sampling for Unsupervised Person Re-identification
Jul 07, 2021
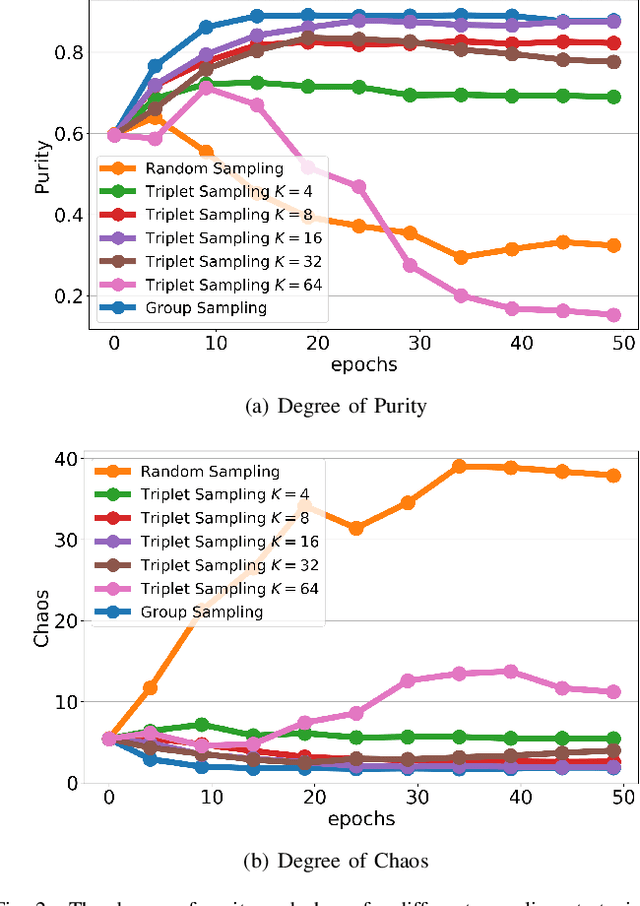
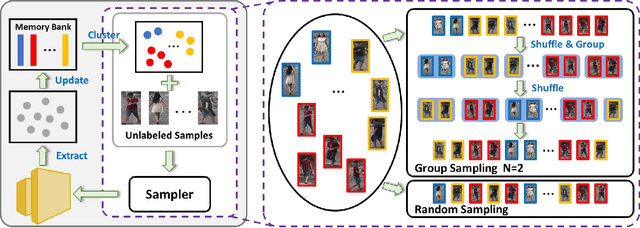
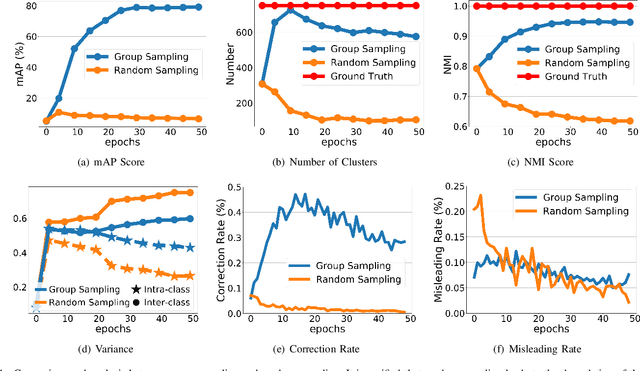
Unsupervised person re-identification (re-ID) remains a challenging task, where the classifier and feature representation could be easily misled by the noisy pseudo labels towards deteriorated over-fitting. In this paper, we propose a simple yet effective approach, termed Group Sampling, to alleviate the negative impact of noisy pseudo labels within unsupervised person re-ID models. The idea behind Group Sampling is that it can gather a group of samples from the same class in the same mini-batch, such that the model is trained upon group normalized samples while alleviating the effect of a single sample. Group sampling updates the pipeline of pseudo label generation by guaranteeing the samples to be better divided into the correct classes. Group Sampling regularizes classifier training and representation learning, leading to the statistical stability of feature representation in a progressive fashion. Qualitative and quantitative experiments on Market-1501, DukeMTMC-reID, and MSMT17 show that Grouping Sampling improves the state-of-the-arts by up to 2.2%~6.1%. Code is available at https://github.com/wavinflaghxm/GroupSampling.