 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio2Gestures: Generating Diverse Gestures from Speech Audio with Conditional Variational Autoencoders
Aug 15, 2021
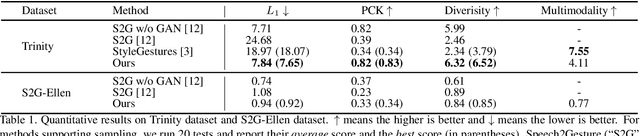
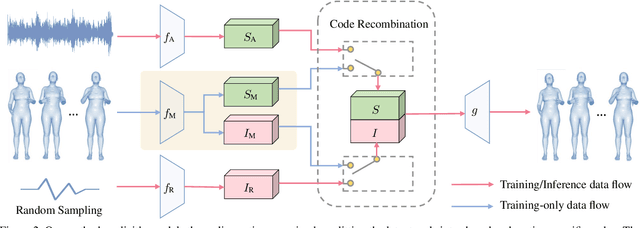

Generating conversational gestures from speech audio is challenging due to the inherent one-to-many mapping between audio and body motions. Conventional CNNs/RNNs assume one-to-one mapping, and thus tend to predict the average of all possible target motions, resulting in plain/boring motions during inference. In order to overcome this problem, we propose a novel conditional variational autoencoder (VAE) that explicitly models one-to-many audio-to-motion mapping by splitting the cross-modal latent code into shared code and motion-specific code. The shared code mainly models the strong correlation between audio and motion (such as the synchronized audio and motion beats), while the motion-specific code captures diverse motion information independent of the audio. However, splitting the latent code into two parts poses training difficulties for the VAE model. A mapping network facilitating random sampling along with other techniques including relaxed motion loss, bicycle constraint, and diversity loss are designed to better train the VAE. Experiments on both 3D and 2D motion datasets verify that our method generates more realistic and diverse motions than state-of-the-art methods, quantitatively and qualitatively. Finally, we demonstrate that our method can be readily used to generate motion sequences with user-specified motion clips on the timeline. Code and more results are at https://jingli513.github.io/audio2gestures.
Orthonormal Product Quantization Network for Scalable Face Image Retrieval
Jul 01, 2021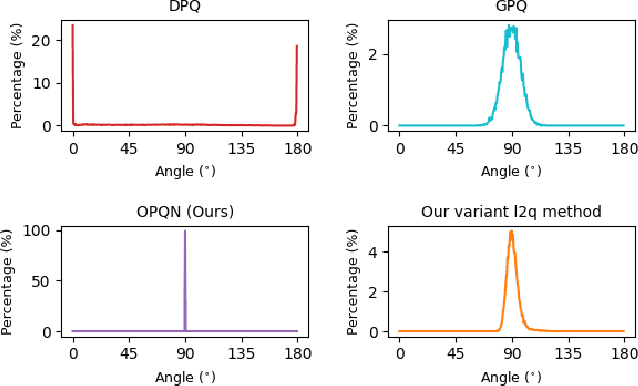
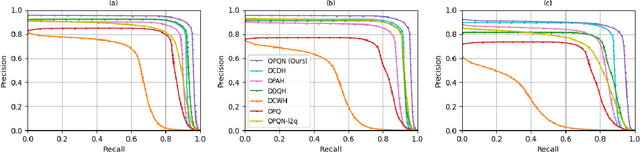
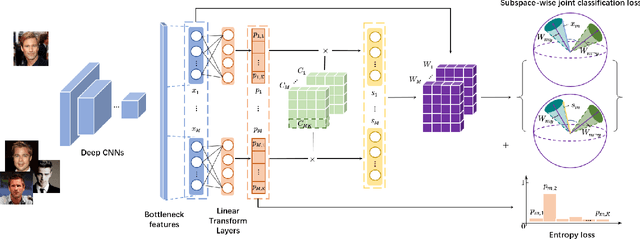
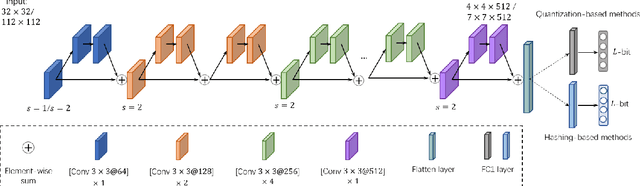
Recently, deep hashing with Hamming distance metric has drawn increasing attention for face image retrieval tasks. However, its counterpart deep quantization methods, which learn binary code representations with dictionary-related distance metrics, have seldom been explored for the task. This paper makes the first attempt to integrate product quantization into an end-to-end deep learning framework for face image retrieval. Unlike prior deep quantization methods where the codewords for quantization are learned from data, we propose a novel scheme using predefined orthonormal vectors as codewords, which aims to enhance the quantization informativeness and reduce the codewords' redundancy. To make the most of the discriminative information, we design a tailored loss function that maximizes the identity discriminability in each quantization subspace for both the quantized and the original features. Furthermore, an entropy-based regularization term is imposed to reduce the quantization error. We conduct experiments on three commonly-used datasets under the settings of both single-domain and cross-domain retrieval. It shows that the proposed method outperforms all the compared deep hashing/quantization methods under both settings with significant superiority. The proposed codewords scheme consistently improves both regular model performance and model generalization ability, verifying the importance of codewords' distribution for the quantization quality. Besides, our model's better generalization ability than deep hashing models indicates that it is more suitable for scalable face image retrieval tasks.
Animatable Neural Radiance Fields from Monocular RGB Video
Jun 25, 2021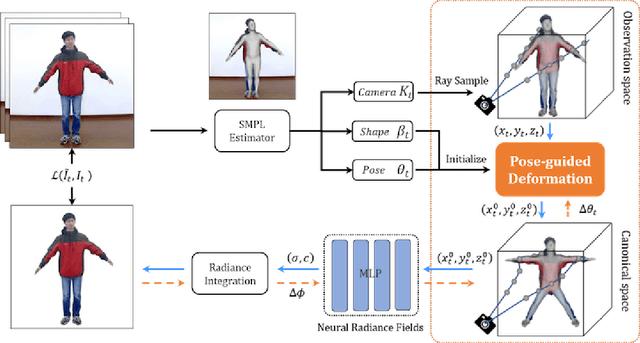
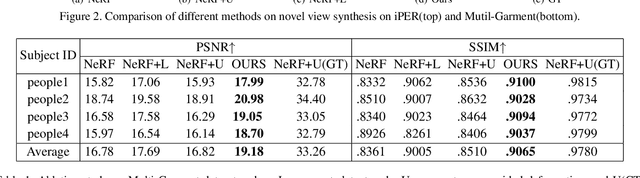


We present animatable neural radiance fields for detailed human avatar creation from monocular videos. Our approach extends neural radiance fields (NeRF) to the dynamic scenes with human movements via introducing explicit pose-guided deformation while learning the scene representation network. In particular, we estimate the human pose for each frame and learn a constant canonical space for the detailed human template, which enables natural shape deformation from the observation space to the canonical space under the explicit control of the pose parameters. To compensate for inaccurate pose estimation, we introduce the pose refinement strategy that updates the initial pose during the learning process, which not only helps to learn more accurate human reconstruction but also accelerates the convergence. In experiments we show that the proposed approach achieves 1) implicit human geometry and appearance reconstruction with high-quality details, 2) photo-realistic rendering of the human from arbitrary views, and 3) animation of the human with arbitrary poses.
Model-based 3D Hand Reconstruction via Self-Supervised Learning
Mar 22, 2021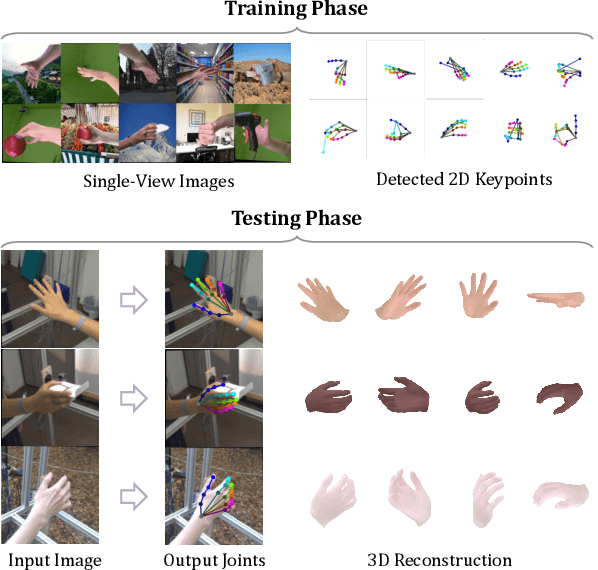
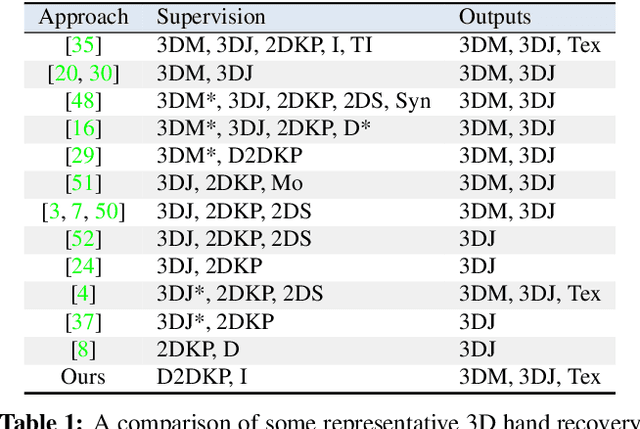
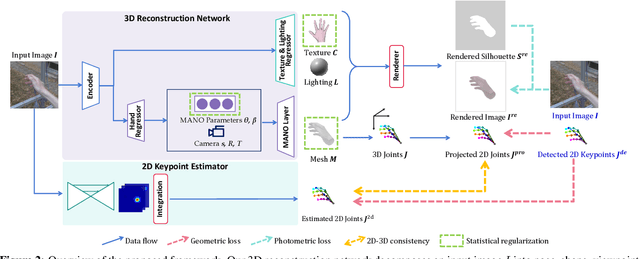
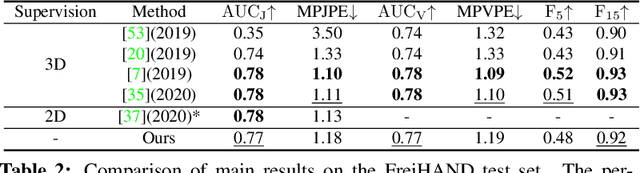
Reconstructing a 3D hand from a single-view RGB image is challenging due to various hand configurations and depth ambiguity. To reliably reconstruct a 3D hand from a monocular image, most state-of-the-art methods heavily rely on 3D annotations at the training stage, but obtaining 3D annotations is expensive. To alleviate reliance on labeled training data, we propose S2HAND, a self-supervised 3D hand reconstruction network that can jointly estimate pose, shape, texture, and the camera viewpoint. Specifically, we obtain geometric cues from the input image through easily accessible 2D detected keypoints. To learn an accurate hand reconstruction model from these noisy geometric cues, we utilize the consistency between 2D and 3D representations and propose a set of novel losses to rationalize outputs of the neural network. For the first time, we demonstrate the feasibility of training an accurate 3D hand reconstruction network without relying on manual annotations. Our experiments show that the proposed method achieves comparable performance with recent fully-supervised methods while using fewer supervision data.
High-Fidelity 3D Digital Human Creation from RGB-D Selfies
Oct 12, 2020
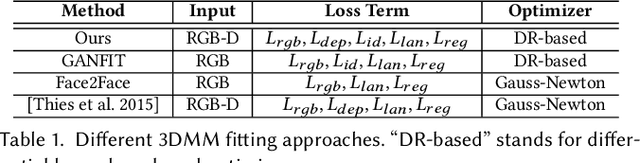
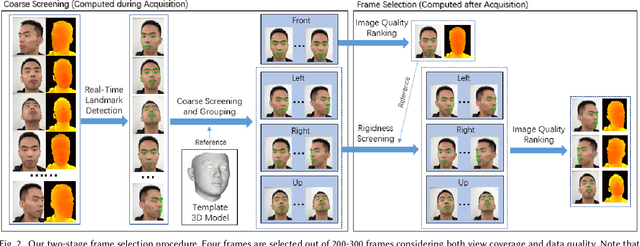

We present a fully automatic system that can produce high-fidelity, photo-realistic 3D digital human characters with a consumer RGB-D selfie camera. The system only needs the user to take a short selfie RGB-D video while rotating his/her head, and can produce a high quality reconstruction in less than 30 seconds. Our main contribution is a new facial geometry modeling and reflectance synthesis procedure that significantly improves the state-of-the-art. Specifically, given the input video a two-stage frame selection algorithm is first employed to select a few high-quality frames for reconstruction. A novel, differentiable renderer based 3D Morphable Model (3DMM) fitting method is then applied to recover facial geometries from multiview RGB-D data, which takes advantages of extensive data generation and perturbation. Our 3DMM has much larger expressive capacities than conventional 3DMM, allowing us to recover more accurate facial geometry using merely linear bases. For reflectance synthesis, we present a hybrid approach that combines parametric fitting and CNNs to synthesize high-resolution albedo/normal maps with realistic hair/pore/wrinkle details. Results show that our system can produce faithful 3D characters with extremely realistic details. Code and the constructed 3DMM is publicly available.
Semantic Hierarchy Preserving Deep Hashing for Large-scale Image Retrieval
Apr 12, 2019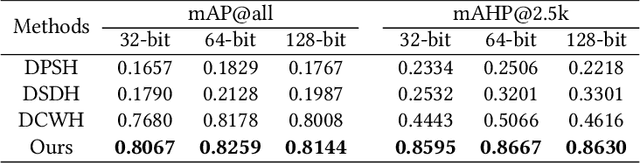

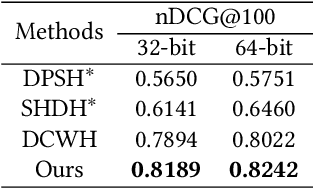
Convolutional neural networks have been widely used in content-based image retrieval. To better deal with large-scale data, the deep hashing model is proposed as an effective method, which maps an image to a binary code that can be used for hashing search. However, most existing deep hashing models only utilize fine-level semantic labels or convert them to similar/dissimilar labels for training. The natural semantic hierarchy structures are ignored in the training stage of the deep hashing model. In this paper, we present an effective algorithm to train a deep hashing model that can preserve a semantic hierarchy structure for large-scale image retrieval. Experiments on two datasets show that our method improves the fine-level retrieval performance. Meanwhile, our model achieves state-of-the-art results in terms of hierarchical retrieval.
Directional Statistics-based Deep Metric Learning for Image Classification and Retrieval
Mar 28, 2018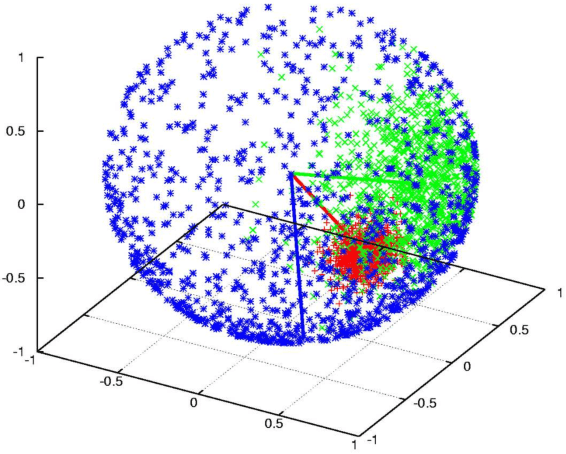


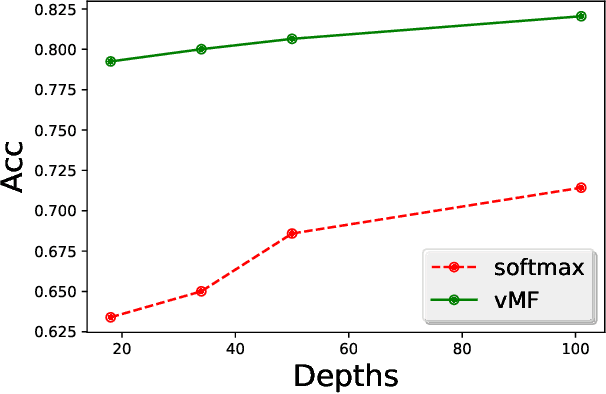
Deep distance metric learning (DDML), which is proposed to learn image similarity metrics in an end-to-end manner based on the convolution neural network, has achieved encouraging results in many computer vision tasks.$L2$-normalization in the embedding space has been used to improve the performance of several DDML methods. However, the commonly used Euclidean distance is no longer an accurate metric for $L2$-normalized embedding space, i.e., a hyper-sphere. Another challenge of current DDML methods is that their loss functions are usually based on rigid data formats, such as the triplet tuple. Thus, an extra process is needed to prepare data in specific formats. In addition, their losses are obtained from a limited number of samples, which leads to a lack of the global view of the embedding space. In this paper, we replace the Euclidean distance with the cosine similarity to better utilize the $L2$-normalization, which is able to attenuate the curse of dimensionality. More specifically, a novel loss function based on the von Mises-Fisher distribution is proposed to learn a compact hyper-spherical embedding space. Moreover, a new efficient learning algorithm is developed to better capture the global structure of the embedding space. Experiments for both classification and retrieval tasks on several standard datasets show that our method achieves state-of-the-art performance with a simpler training procedure. Furthermore, we demonstrate that, even with a small number of convolutional layers, our model can still obtain significantly better classification performance than the widely used softmax loss.
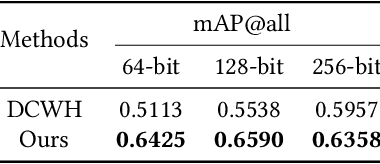
Deep Class-Wise Hashing: Semantics-Preserving Hashing via Class-wise Loss
Mar 12, 2018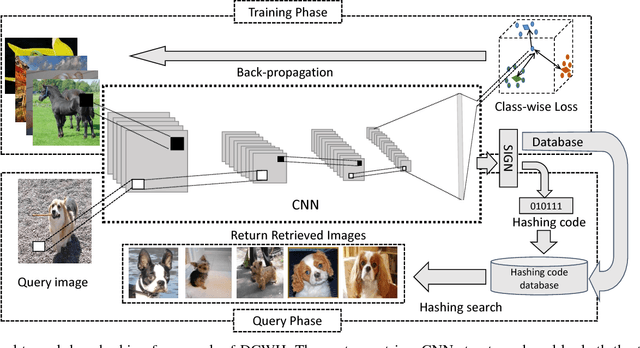


Deep supervised hashing has emerged as an influential solution to large-scale semantic image retrieval problems in computer vision. In the light of recent progress, convolutional neural network based hashing methods typically seek pair-wise or triplet labels to conduct the similarity preserving learning. However, complex semantic concepts of visual contents are hard to capture by similar/dissimilar labels, which limits the retrieval performance. Generally, pair-wise or triplet losses not only suffer from expensive training costs but also lack in extracting sufficient semantic information. In this regard, we propose a novel deep supervised hashing model to learn more compact class-level similarity preserving binary codes. Our deep learning based model is motivated by deep metric learning that directly takes semantic labels as supervised information in training and generates corresponding discriminant hashing code. Specifically, a novel cubic constraint loss function based on Gaussian distribution is proposed, which preserves semantic variations while penalizes the overlap part of different classes in the embedding space. To address the discrete optimization problem introduced by binary codes, a two-step optimization strategy is proposed to provide efficient training and avoid the problem of gradient vanishing. Extensive experiments on four large-scale benchmark databases show that our model can achieve the state-of-the-art retrieval performance. Moreover, when training samples are limited, our method surpasses other supervised deep hashing methods with non-negligible margins.