 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-time Earthquake Early Warning with Deep Learning: Application to the 2016 Central Apennines, Italy Earthquake Sequence
Jun 02, 2020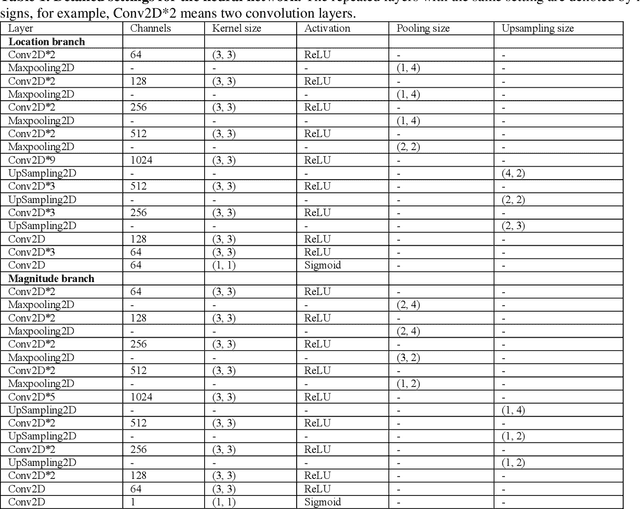
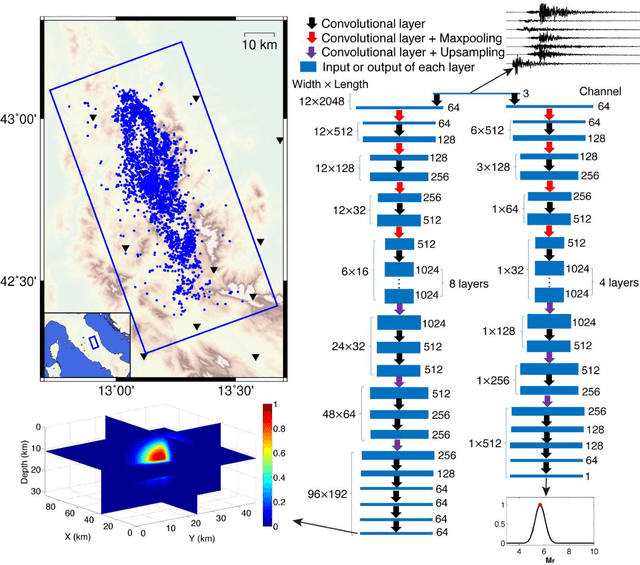
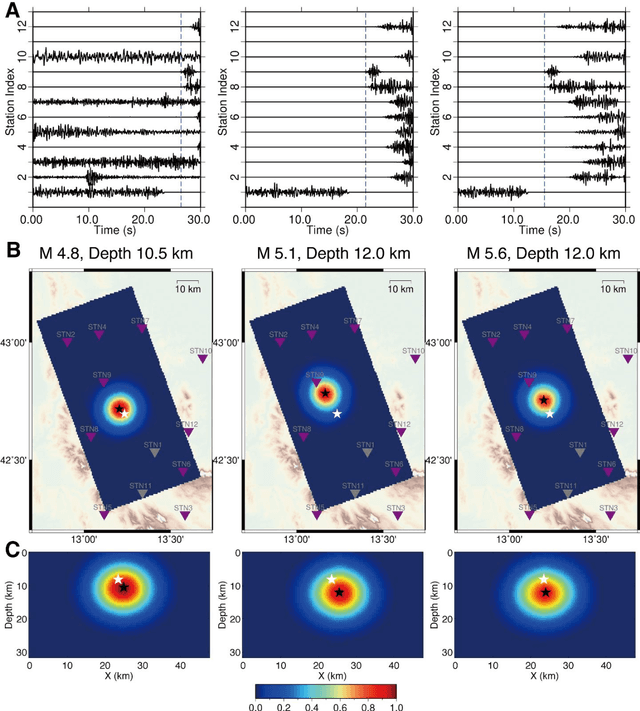
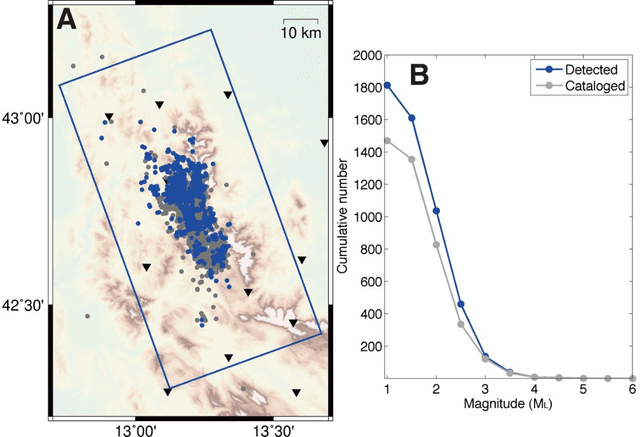
Earthquake early warning systems are required to report earthquake locations and magnitudes as quickly as possible before the damaging S wave arrival to mitigate seismic hazards. Deep learning techniques provide potential for extracting earthquake source information from full seismic waveforms instead of seismic phase picks. We developed a novel deep learning earthquake early warning system that utilizes fully convolutional networks to simultaneously detect earthquakes and estimate their source parameters from continuous seismic waveform streams. The system determines earthquake location and magnitude as soon as one station receives earthquake signals and evolutionarily improves the solutions by receiving continuous data. We apply the system to the 2016 Mw 6.0 earthquake in Central Apennines, Italy and its subsequent sequence. Earthquake locations and magnitudes can be reliably determined as early as four seconds after the earliest P phase, with mean error ranges of 6.8-3.7 km and 0.31-0.23, respectively.
Asymmetrical Vertical Federated Learning
Apr 30, 2020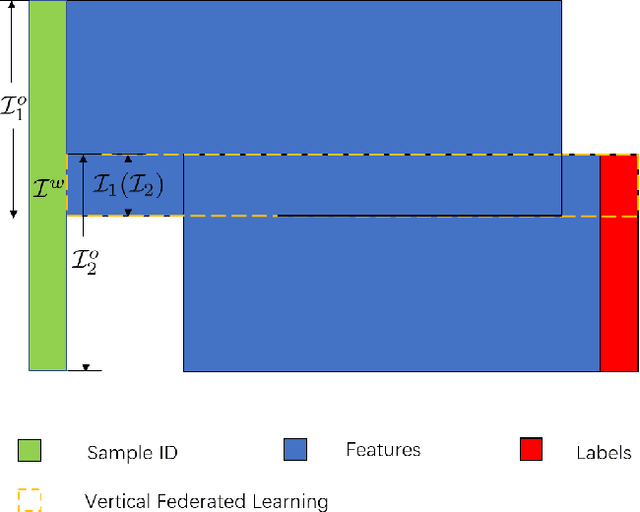


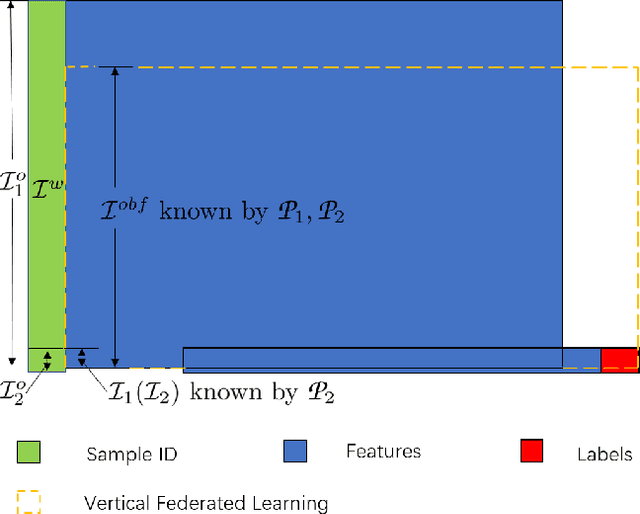
Federated learning is a distributed machine learning method that aims to preserve the privacy of sample features and labels. In a federated learning system, ID-based sample alignment approaches are usually applied with few efforts made on the protection of ID privacy. In real-life applications, however, the confidentiality of sample IDs, which are the strongest row identifiers, is also drawing much attention from many participants. To relax their privacy concerns about ID privacy, this paper formally proposes the notion of asymmetrical vertical federated learning and illustrates the way to protect sample IDs. The standard private set intersection protocol is adapted to achieve the asymmetrical ID alignment phase in an asymmetrical vertical federated learning system. Correspondingly, a Pohlig-Hellman realization of the adapted protocol is provided. This paper also presents a genuine with dummy approach to achieving asymmetrical federated model training. To illustrate its application, a federated logistic regression algorithm is provided as an example. Experiments are also made for validating the feasibility of this approach.
Differentially Private Linear Regression over Fully Decentralized Datasets
Apr 16, 2020This paper presents a differentially private algorithm for linear regression learning in a decentralized fashion. Under this algorithm, privacy budget is theoretically derived, in addition to that the solution error is shown to be bounded by $O(t)$ for $O(1/t)$ descent step size and $O(\exp(t^{1-e}))$ for $O(t^{-e})$ descent step size.
DCNAS: Densely Connected Neural Architecture Search for Semantic Image Segmentation
Mar 26, 2020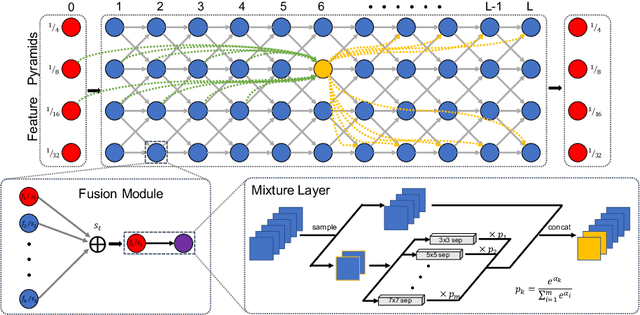
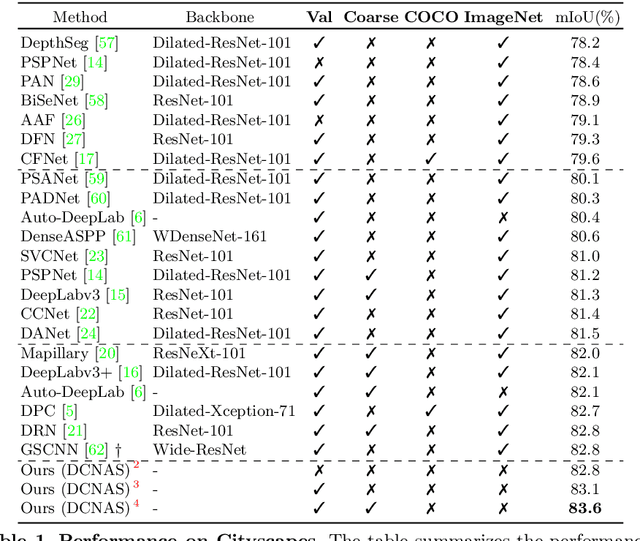
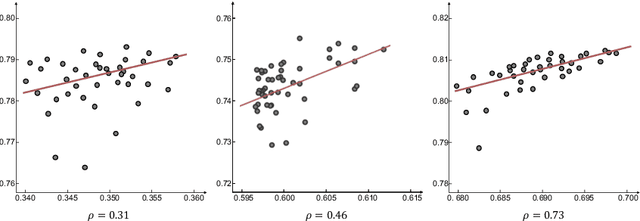
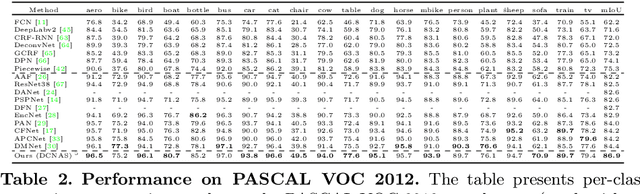
Neural Architecture Search (NAS) has shown great potentials in automatically designing scalable network architectures for dense image predictions. However, existing NAS algorithms usually compromise on restricted search space and search on proxy task to meet the achievable computational demands. To allow as wide as possible network architectures and avoid the gap between target and proxy dataset, we propose a Densely Connected NAS (DCNAS) framework, which directly searches the optimal network structures for the multi-scale representations of visual information, over a large-scale target dataset. Specifically, by connecting cells with each other using learnable weights, we introduce a densely connected search space to cover an abundance of mainstream network designs. Moreover, by combining both path-level and channel-level sampling strategies, we design a fusion module to reduce the memory consumption of ample search space. We demonstrate that the architecture obtained from our DCNAS algorithm achieves state-of-the-art performances on public semantic image segmentation benchmarks, including 83.6% on Cityscapes, and 86.9% on PASCAL VOC 2012 (track w/o additional data). We also retain leading performances when evaluating the architecture on the more challenging ADE20K and Pascal Context dataset.
Teddy: A System for Interactive Review Analysis
Jan 15, 2020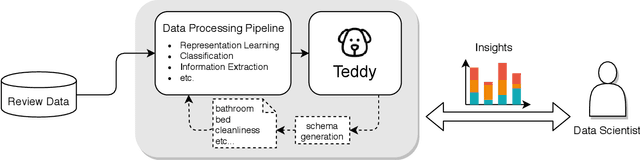

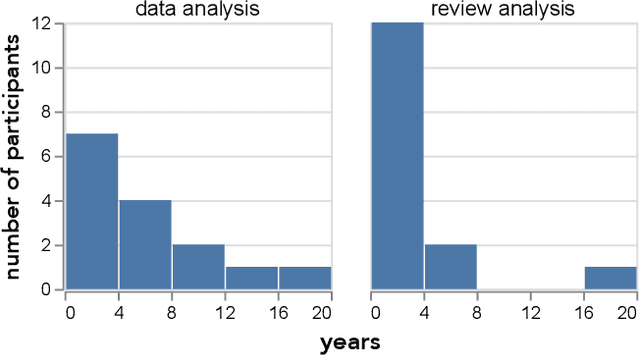
Reviews are integral to e-commerce services and products. They contain a wealth of information about the opinions and experiences of users, which can help better understand consumer decisions and improve user experience with products and services. Today, data scientists analyze reviews by developing rules and models to extract, aggregate, and understand information embedded in the review text. However, working with thousands of reviews, which are typically noisy incomplete text, can be daunting without proper tools. Here we first contribute results from an interview study that we conducted with fifteen data scientists who work with review text, providing insights into their practices and challenges. Results suggest data scientists need interactive systems for many review analysis tasks. In response we introduce Teddy, an interactive system that enables data scientists to quickly obtain insights from reviews and improve their extraction and modeling pipelines.
End-to-end Hand Mesh Recovery from a Monocular RGB Image
Mar 09, 2019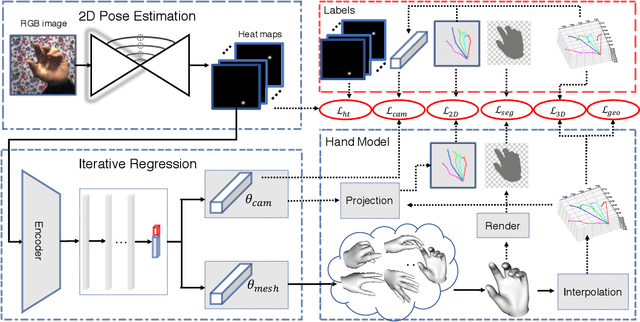
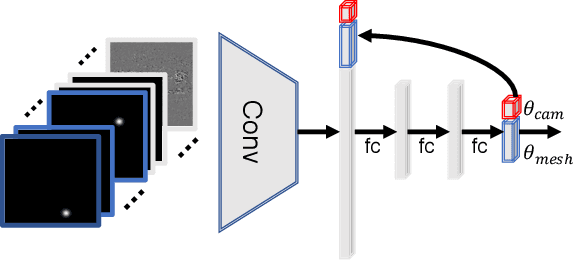
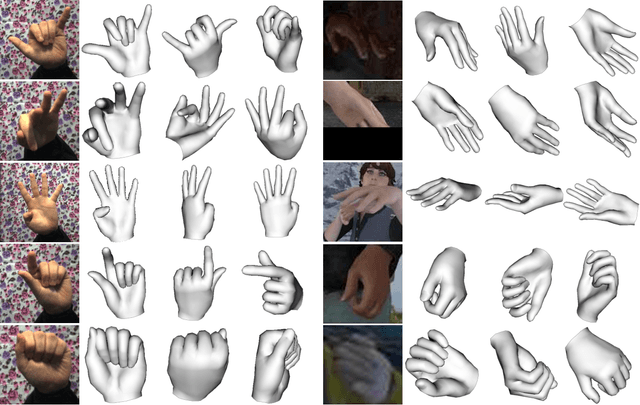

In this paper, we present a HAnd Mesh Recovery (HAMR) framework to tackle the problem of reconstructing the full 3D mesh of a human hand from a single RGB image. In contrast to existing research on 2D or 3D hand pose estimation from RGB or/and depth image data, HAMR can provide a more expressive and useful mesh representation for monocular hand image understanding. In particular, the mesh representation is achieved by parameterizing a generic 3D hand model with shape and relative 3D joint angles. By utilizing this mesh representation, we can easily compute the 3D joint locations via linear interpolations between the vertexes of the mesh, while obtain the 2D joint locations with a projection of the 3D joints.To this end, a differentiable re-projection loss can be defined in terms of the derived representations and the ground-truth labels, thus making our framework end-to-end trainable.Qualitative experiments show that our framework is capable of recovering appealing 3D hand mesh even in the presence of severe occlusions.Quantitatively, our approach also outperforms the state-of-the-art methods for both 2D and 3D hand pose estimation from a monocular RGB image on several benchmark datasets.