 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncentivizing Truthfulness and Collaborative Fairness in Bayesian Learning
May 12, 2026Collaborative machine learning involves training high-quality models using datasets from a number of sources. To incentivize sources to share data, existing data valuation methods fairly reward each source based on its data submitted as is. However, as these methods do not verify nor incentivize data truthfulness, the sources can manipulate their data (e.g., by submitting duplicated or noisy data) to artificially increase their valuations and rewards or prevent others from benefiting. This paper presents the first mechanism that provably ensures (F) collaborative fairness and incentivizes (T) truthfulness at equilibrium for Bayesian models. Our mechanism combines semivalues (e.g., Shapley value), which ensure fairness, and a truthful data valuation function (DVF) based on a validation set that is unknown to the sources. As semivalues are influenced by others' data, we introduce an additional condition to prove that a source can maximize its expected data values in coalitions and semivalues by submitting a dataset that captures its true knowledge. Additionally, we discuss the implications and suitable relaxations of (F) and (T) when the mediator has a limited budget for rewards or lacks a validation set. Our theoretical findings are validated on synthetic and real-world datasets.
Is Data Shapley Not Better than Random in Data Selection? Ask NASH
May 11, 2026Data selection studies the problem of identifying high-quality subsets of training data. While some existing works have considered selecting the subset of data with top-$m$ Data Shapley or other semivalues as they account for the interaction among every subset of data, other works argue that Data Shapley can sometimes perform ineffectively in practice and select subsets that are no better than random. This raises the questions: (I) Are there certain "Shapley-informative" settings where Data Shapley consistently works well? (II) Can we strategically utilize these settings to select high-quality subsets consistently and efficiently? In this paper, we propose a novel data selection framework, NASH (Non-linear Aggregation of SHapley-informative components), which (I) decomposes the target utility function (e.g., validation accuracy) into simpler, Shapley-informative component functions, and selects data by optimizing an objective that (II) aggregates these components non-linearly. We demonstrate that NASH substantially boosts the effectiveness of Shapley/semivalue-based data selection with minimal additional runtime cost.
DeRDaVa: Deletion-Robust Data Valuation for Machine Learning
Dec 18, 2023



Data valuation is concerned with determining a fair valuation of data from data sources to compensate them or to identify training examples that are the most or least useful for predictions. With the rising interest in personal data ownership and data protection regulations, model owners will likely have to fulfil more data deletion requests. This raises issues that have not been addressed by existing works: Are the data valuation scores still fair with deletions? Must the scores be expensively recomputed? The answer is no. To avoid recomputations, we propose using our data valuation framework DeRDaVa upfront for valuing each data source's contribution to preserving robust model performance after anticipated data deletions. DeRDaVa can be efficiently approximated and will assign higher values to data that are more useful or less likely to be deleted. We further generalize DeRDaVa to Risk-DeRDaVa to cater to risk-averse/seeking model owners who are concerned with the worst/best-cases model utility. We also empirically demonstrate the practicality of our solutions.
Real-time Earthquake Early Warning with Deep Learning: Application to the 2016 Central Apennines, Italy Earthquake Sequence
Jun 02, 2020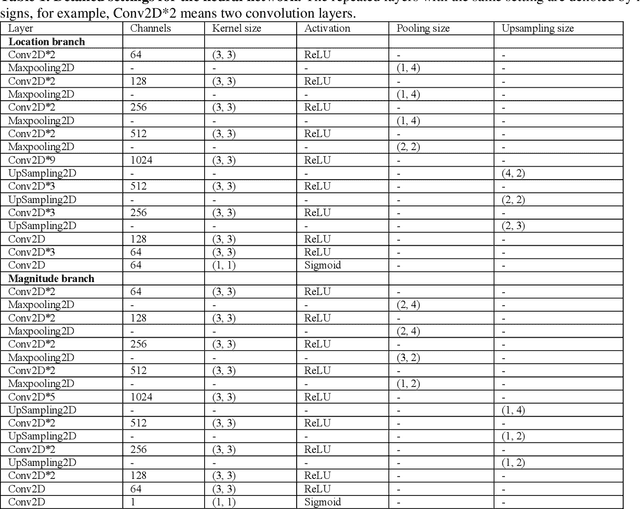
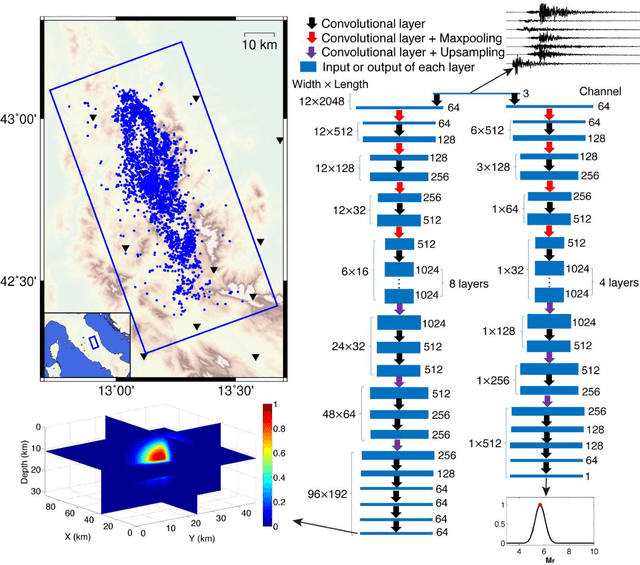
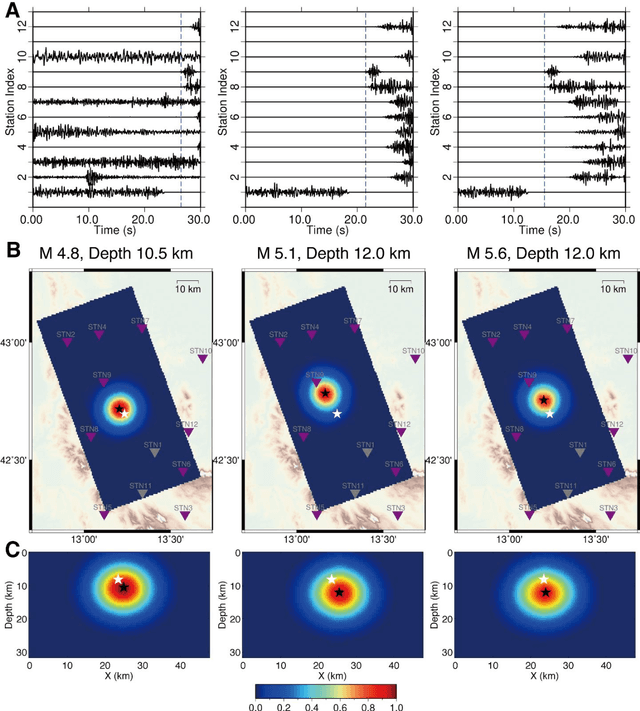
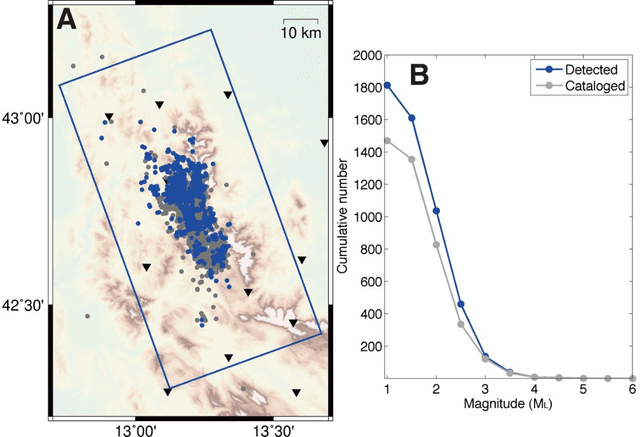
Earthquake early warning systems are required to report earthquake locations and magnitudes as quickly as possible before the damaging S wave arrival to mitigate seismic hazards. Deep learning techniques provide potential for extracting earthquake source information from full seismic waveforms instead of seismic phase picks. We developed a novel deep learning earthquake early warning system that utilizes fully convolutional networks to simultaneously detect earthquakes and estimate their source parameters from continuous seismic waveform streams. The system determines earthquake location and magnitude as soon as one station receives earthquake signals and evolutionarily improves the solutions by receiving continuous data. We apply the system to the 2016 Mw 6.0 earthquake in Central Apennines, Italy and its subsequent sequence. Earthquake locations and magnitudes can be reliably determined as early as four seconds after the earliest P phase, with mean error ranges of 6.8-3.7 km and 0.31-0.23, respectively.