 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning-based Sketches for Frequency Estimation in Data Streams without Ground Truth
Dec 04, 2024Estimating the frequency of items on the high-volume, fast data stream has been extensively studied in many areas, such as database and network measurement. Traditional sketch algorithms only allow to give very rough estimates with limited memory cost, whereas some learning-augmented algorithms have been proposed recently, their offline framework requires actual frequencies that are challenging to access in general for training, and speed is too slow for real-time processing, despite the still coarse-grained accuracy. To this end, we propose a more practical learning-based estimation framework namely UCL-sketch, by following the line of equation-based sketch to estimate per-key frequencies. In a nutshell, there are two key techniques: online training via equivalent learning without ground truth, and highly scalable architecture with logical estimation buckets. We implemented experiments on both real-world and synthetic datasets. The results demonstrate that our method greatly outperforms existing state-of-the-art sketches regarding per-key accuracy and distribution, while preserving resource efficiency. Our code is attached in the supplementary material, and will be made publicly available at https://github.com/Y-debug-sys/UCL-sketch.
Diffusion Models Meet Network Management: Improving Traffic Matrix Analysis with Diffusion-based Approach
Nov 29, 2024



Due to network operation and maintenance relying heavily on network traffic monitoring, traffic matrix analysis has been one of the most crucial issues for network management related tasks. However, it is challenging to reliably obtain the precise measurement in computer networks because of the high measurement cost, and the unavoidable transmission loss. Although some methods proposed in recent years allowed estimating network traffic from partial flow-level or link-level measurements, they often perform poorly for traffic matrix estimation nowadays. Despite strong assumptions like low-rank structure and the prior distribution, existing techniques are usually task-specific and tend to be significantly worse as modern network communication is extremely complicated and dynamic. To address the dilemma, this paper proposed a diffusion-based traffic matrix analysis framework named Diffusion-TM, which leverages problem-agnostic diffusion to notably elevate the estimation performance in both traffic distribution and accuracy. The novel framework not only takes advantage of the powerful generative ability of diffusion models to produce realistic network traffic, but also leverages the denoising process to unbiasedly estimate all end-to-end traffic in a plug-and-play manner under theoretical guarantee. Moreover, taking into account that compiling an intact traffic dataset is usually infeasible, we also propose a two-stage training scheme to make our framework be insensitive to missing values in the dataset. With extensive experiments with real-world datasets, we illustrate the effectiveness of Diffusion-TM on several tasks. Moreover, the results also demonstrate that our method can obtain promising results even with $5\%$ known values left in the datasets.
Traffic Matrix Estimation based on Denoising Diffusion Probabilistic Model
Oct 21, 2024



The traffic matrix estimation (TME) problem has been widely researched for decades of years. Recent progresses in deep generative models offer new opportunities to tackle TME problems in a more advanced way. In this paper, we leverage the powerful ability of denoising diffusion probabilistic models (DDPMs) on distribution learning, and for the first time adopt DDPM to address the TME problem. To ensure a good performance of DDPM on learning the distributions of TMs, we design a preprocessing module to reduce the dimensions of TMs while keeping the data variety of each OD flow. To improve the estimation accuracy, we parameterize the noise factors in DDPM and transform the TME problem into a gradient-descent optimization problem. Finally, we compared our method with the state-of-the-art TME methods using two real-world TM datasets, the experimental results strongly demonstrate the superiority of our method on both TM synthesis and TM estimation.
Cell-ontology guided transcriptome foundation model
Aug 22, 2024



Transcriptome foundation models TFMs hold great promises of deciphering the transcriptomic language that dictate diverse cell functions by self-supervised learning on large-scale single-cell gene expression data, and ultimately unraveling the complex mechanisms of human diseases. However, current TFMs treat cells as independent samples and ignore the taxonomic relationships between cell types, which are available in cell ontology graphs. We argue that effectively leveraging this ontology information during the TFM pre-training can improve learning biologically meaningful gene co-expression patterns while preserving TFM as a general purpose foundation model for downstream zero-shot and fine-tuning tasks. To this end, we present \textbf{s}ingle \textbf{c}ell, \textbf{Cell}-\textbf{o}ntology guided TFM scCello. We introduce cell-type coherence loss and ontology alignment loss, which are minimized along with the masked gene expression prediction loss during the pre-training. The novel loss component guide scCello to learn the cell-type-specific representation and the structural relation between cell types from the cell ontology graph, respectively. We pre-trained scCello on 22 million cells from CellxGene database leveraging their cell-type labels mapped to the cell ontology graph from Open Biological and Biomedical Ontology Foundry. Our TFM demonstrates competitive generalization and transferability performance over the existing TFMs on biologically important tasks including identifying novel cell types of unseen cells, prediction of cell-type-specific marker genes, and cancer drug responses.
Diffusion-TS: Interpretable Diffusion for General Time Series Generation
Mar 14, 2024Denoising diffusion probabilistic models (DDPMs) are becoming the leading paradigm for generative models. It has recently shown breakthroughs in audio synthesis, time series imputation and forecasting. In this paper, we propose Diffusion-TS, a novel diffusion-based framework that generates multivariate time series samples of high quality by using an encoder-decoder transformer with disentangled temporal representations, in which the decomposition technique guides Diffusion-TS to capture the semantic meaning of time series while transformers mine detailed sequential information from the noisy model input. Different from existing diffusion-based approaches, we train the model to directly reconstruct the sample instead of the noise in each diffusion step, combining a Fourier-based loss term. Diffusion-TS is expected to generate time series satisfying both interpretablity and realness. In addition, it is shown that the proposed Diffusion-TS can be easily extended to conditional generation tasks, such as forecasting and imputation, without any model changes. This also motivates us to further explore the performance of Diffusion-TS under irregular settings. Finally, through qualitative and quantitative experiments, results show that Diffusion-TS achieves the state-of-the-art results on various realistic analyses of time series.
Towards Foundation Models for Knowledge Graph Reasoning
Oct 06, 2023



Foundation models in language and vision have the ability to run inference on any textual and visual inputs thanks to the transferable representations such as a vocabulary of tokens in language. Knowledge graphs (KGs) have different entity and relation vocabularies that generally do not overlap. The key challenge of designing foundation models on KGs is to learn such transferable representations that enable inference on any graph with arbitrary entity and relation vocabularies. In this work, we make a step towards such foundation models and present ULTRA, an approach for learning universal and transferable graph representations. ULTRA builds relational representations as a function conditioned on their interactions. Such a conditioning strategy allows a pre-trained ULTRA model to inductively generalize to any unseen KG with any relation vocabulary and to be fine-tuned on any graph. Conducting link prediction experiments on 57 different KGs, we find that the zero-shot inductive inference performance of a single pre-trained ULTRA model on unseen graphs of various sizes is often on par or better than strong baselines trained on specific graphs. Fine-tuning further boosts the performance.
ProtST: Multi-Modality Learning of Protein Sequences and Biomedical Texts
Jan 28, 2023



Current protein language models (PLMs) learn protein representations mainly based on their sequences, thereby well capturing co-evolutionary information, but they are unable to explicitly acquire protein functions, which is the end goal of protein representation learning. Fortunately, for many proteins, their textual property descriptions are available, where their various functions are also described. Motivated by this fact, we first build the ProtDescribe dataset to augment protein sequences with text descriptions of their functions and other important properties. Based on this dataset, we propose the ProtST framework to enhance Protein Sequence pre-training and understanding by biomedical Texts. During pre-training, we design three types of tasks, i.e., unimodal mask prediction, multimodal representation alignment and multimodal mask prediction, to enhance a PLM with protein property information with different granularities and, at the same time, preserve the PLM's original representation power. On downstream tasks, ProtST enables both supervised learning and zero-shot prediction. We verify the superiority of ProtST-induced PLMs over previous ones on diverse representation learning benchmarks. Under the zero-shot setting, we show the effectiveness of ProtST on zero-shot protein classification, and ProtST also enables functional protein retrieval from a large-scale database without any function annotation.
Package Theft Detection from Smart Home Security Cameras
May 24, 2022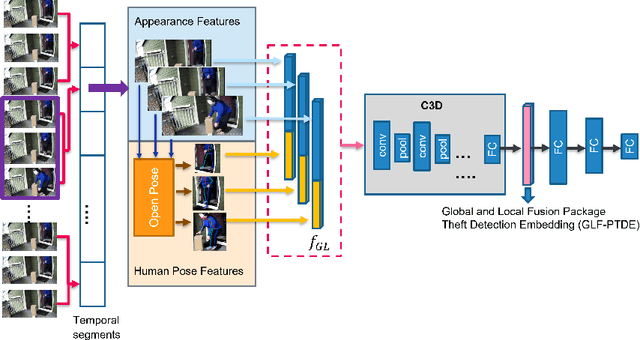

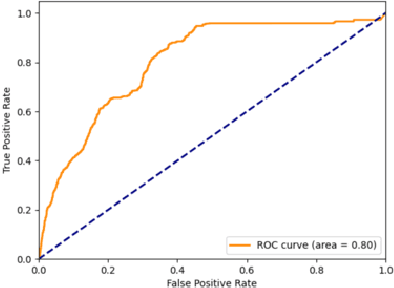

Package theft detection has been a challenging task mainly due to lack of training data and a wide variety of package theft cases in reality. In this paper, we propose a new Global and Local Fusion Package Theft Detection Embedding (GLF-PTDE) framework to generate package theft scores for each segment within a video to fulfill the real-world requirements on package theft detection. Moreover, we construct a novel Package Theft Detection dataset to facilitate the research on this task. Our method achieves 80% AUC performance on the newly proposed dataset, showing the effectiveness of the proposed GLF-PTDE framework and its robustness in different real scenes for package theft detection.
TorchDrug: A Powerful and Flexible Machine Learning Platform for Drug Discovery
Feb 16, 2022

Machine learning has huge potential to revolutionize the field of drug discovery and is attracting increasing attention in recent years. However, lacking domain knowledge (e.g., which tasks to work on), standard benchmarks and data preprocessing pipelines are the main obstacles for machine learning researchers to work in this domain. To facilitate the progress of machine learning for drug discovery, we develop TorchDrug, a powerful and flexible machine learning platform for drug discovery built on top of PyTorch. TorchDrug benchmarks a variety of important tasks in drug discovery, including molecular property prediction, pretrained molecular representations, de novo molecular design and optimization, retrosynthsis prediction, and biomedical knowledge graph reasoning. State-of-the-art techniques based on geometric deep learning (or graph machine learning), deep generative models, reinforcement learning and knowledge graph reasoning are implemented for these tasks. TorchDrug features a hierarchical interface that facilitates customization from both novices and experts in this domain. Tutorials, benchmark results and documentation are available at https://torchdrug.ai. Code is released under Apache License 2.0.