 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSearching for Two-Stream Models in Multivariate Space for Video Recognition
Aug 30, 2021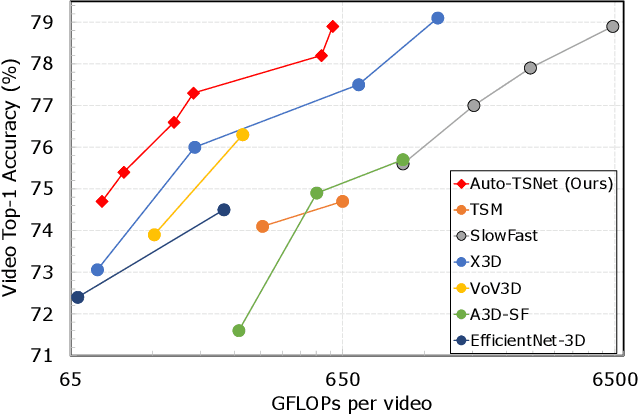
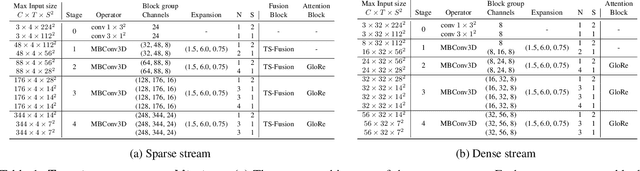
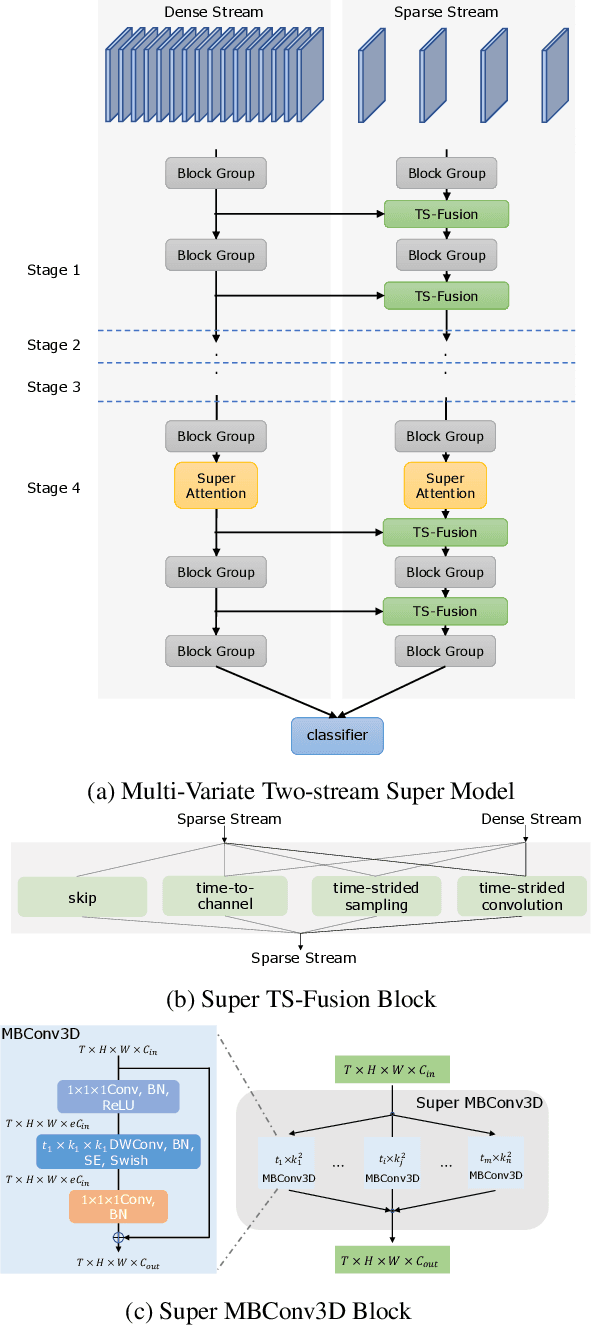

Conventional video models rely on a single stream to capture the complex spatial-temporal features. Recent work on two-stream video models, such as SlowFast network and AssembleNet, prescribe separate streams to learn complementary features, and achieve stronger performance. However, manually designing both streams as well as the in-between fusion blocks is a daunting task, requiring to explore a tremendously large design space. Such manual exploration is time-consuming and often ends up with sub-optimal architectures when computational resources are limited and the exploration is insufficient. In this work, we present a pragmatic neural architecture search approach, which is able to search for two-stream video models in giant spaces efficiently. We design a multivariate search space, including 6 search variables to capture a wide variety of choices in designing two-stream models. Furthermore, we propose a progressive search procedure, by searching for the architecture of individual streams, fusion blocks, and attention blocks one after the other. We demonstrate two-stream models with significantly better performance can be automatically discovered in our design space. Our searched two-stream models, namely Auto-TSNet, consistently outperform other models on standard benchmarks. On Kinetics, compared with the SlowFast model, our Auto-TSNet-L model reduces FLOPS by nearly 11 times while achieving the same accuracy 78.9%. On Something-Something-V2, Auto-TSNet-M improves the accuracy by at least 2% over other methods which use less than 50 GFLOPS per video.
Understanding and Accelerating Neural Architecture Search with Training-Free and Theory-Grounded Metrics
Aug 26, 2021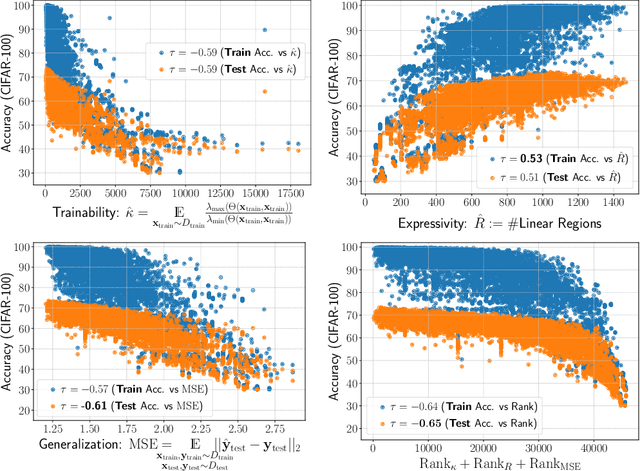

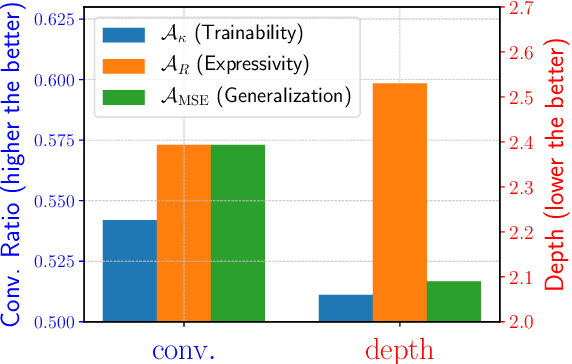
This work targets designing a principled and unified training-free framework for Neural Architecture Search (NAS), with high performance, low cost, and in-depth interpretation. NAS has been explosively studied to automate the discovery of top-performer neural networks, but suffers from heavy resource consumption and often incurs search bias due to truncated training or approximations. Recent NAS works start to explore indicators that can predict a network's performance without training. However, they either leveraged limited properties of deep networks, or the benefits of their training-free indicators are not applied to more extensive search methods. By rigorous correlation analysis, we present a unified framework to understand and accelerate NAS, by disentangling "TEG" characteristics of searched networks - Trainability, Expressivity, Generalization - all assessed in a training-free manner. The TEG indicators could be scaled up and integrated with various NAS search methods, including both supernet and single-path approaches. Extensive studies validate the effective and efficient guidance from our TEG-NAS framework, leading to both improved search accuracy and over 2.3x reduction in search time cost. Moreover, we visualize search trajectories on three landscapes of "TEG" characteristics, observing that while a good local minimum is easier to find on NAS-Bench-201 given its simple topology, balancing "TEG" characteristics is much harder on the DARTS search space due to its complex landscape geometry. Our code is available at https://github.com/VITA-Group/TEGNAS.
SAFIN: Arbitrary Style Transfer With Self-Attentive Factorized Instance Normalization
May 20, 2021


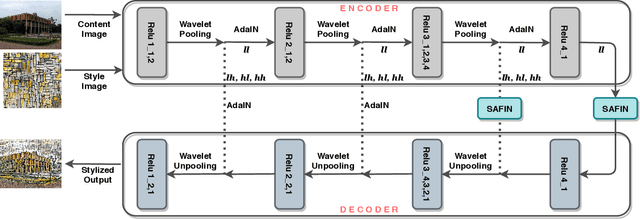
Artistic style transfer aims to transfer the style characteristics of one image onto another image while retaining its content. Existing approaches commonly leverage various normalization techniques, although these face limitations in adequately transferring diverse textures to different spatial locations. Self-Attention-based approaches have tackled this issue with partial success but suffer from unwanted artifacts. Motivated by these observations, this paper aims to combine the best of both worlds: self-attention and normalization. That yields a new plug-and-play module that we name Self-Attentive Factorized Instance Normalization (SAFIN). SAFIN is essentially a spatially adaptive normalization module whose parameters are inferred through attention on the content and style image. We demonstrate that plugging SAFIN into the base network of another state-of-the-art method results in enhanced stylization. We also develop a novel base network composed of Wavelet Transform for multi-scale style transfer, which when combined with SAFIN, produces visually appealing results with lesser unwanted textures.
Neural Architecture Search on ImageNet in Four GPU Hours: A Theoretically Inspired Perspective
Mar 16, 2021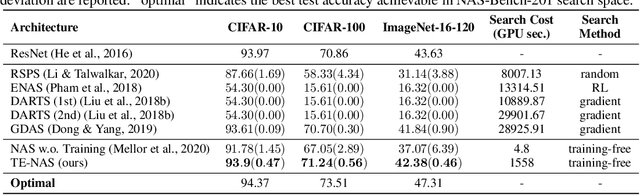
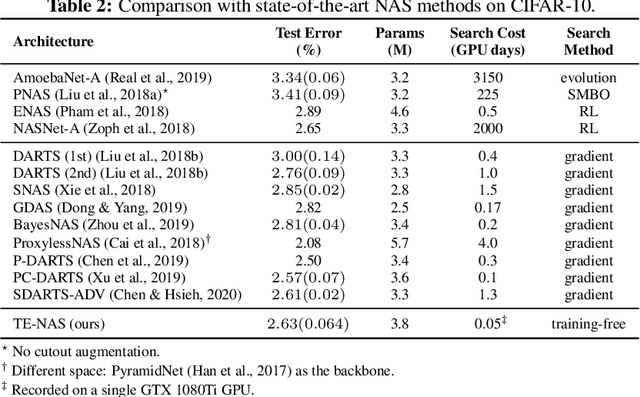
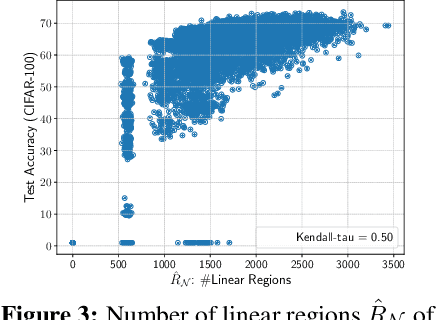
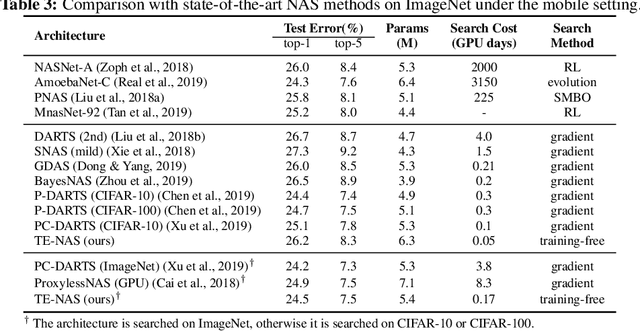
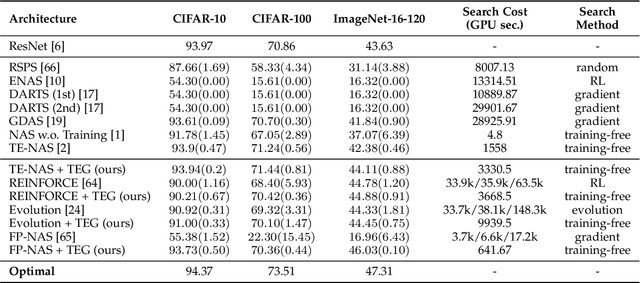
Neural Architecture Search (NAS) has been explosively studied to automate the discovery of top-performer neural networks. Current works require heavy training of supernet or intensive architecture evaluations, thus suffering from heavy resource consumption and often incurring search bias due to truncated training or approximations. Can we select the best neural architectures without involving any training and eliminate a drastic portion of the search cost? We provide an affirmative answer, by proposing a novel framework called training-free neural architecture search (TE-NAS). TE-NAS ranks architectures by analyzing the spectrum of the neural tangent kernel (NTK) and the number of linear regions in the input space. Both are motivated by recent theory advances in deep networks and can be computed without any training and any label. We show that: (1) these two measurements imply the trainability and expressivity of a neural network; (2) they strongly correlate with the network's test accuracy. Further on, we design a pruning-based NAS mechanism to achieve a more flexible and superior trade-off between the trainability and expressivity during the search. In NAS-Bench-201 and DARTS search spaces, TE-NAS completes high-quality search but only costs 0.5 and 4 GPU hours with one 1080Ti on CIFAR-10 and ImageNet, respectively. We hope our work inspires more attempts in bridging the theoretical findings of deep networks and practical impacts in real NAS applications. Code is available at: https://github.com/VITA-Group/TENAS.
Sandwich Batch Normalization
Feb 22, 2021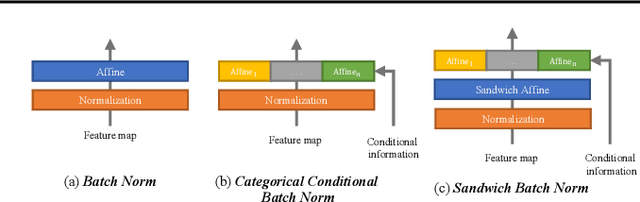

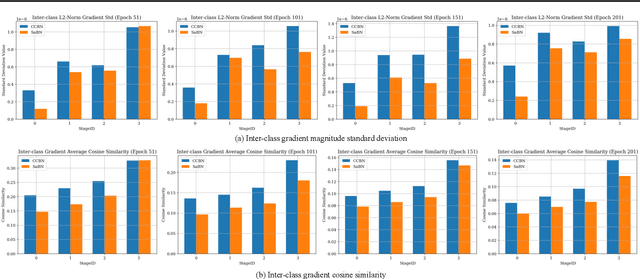

We present Sandwich Batch Normalization (SaBN), an embarrassingly easy improvement of Batch Normalization (BN) with only a few lines of code changes. SaBN is motivated by addressing the inherent feature distribution heterogeneity that one can be identified in many tasks, which can arise from data heterogeneity (multiple input domains) or model heterogeneity (dynamic architectures, model conditioning, etc.). Our SaBN factorizes the BN affine layer into one shared sandwich affine layer, cascaded by several parallel independent affine layers. Concrete analysis reveals that, during optimization, SaBN promotes balanced gradient norms while still preserving diverse gradient directions: a property that many application tasks seem to favor. We demonstrate the prevailing effectiveness of SaBN as a drop-in replacement in four tasks: $\textbf{conditional image generation}$, $\textbf{neural architecture search}$ (NAS), $\textbf{adversarial training}$, and $\textbf{arbitrary style transfer}$. Leveraging SaBN immediately achieves better Inception Score and FID on CIFAR-10 and ImageNet conditional image generation with three state-of-the-art GANs; boosts the performance of a state-of-the-art weight-sharing NAS algorithm significantly on NAS-Bench-201; substantially improves the robust and standard accuracies for adversarial defense; and produces superior arbitrary stylized results. We also provide visualizations and analysis to help understand why SaBN works. Codes are available at https://github.com/VITA-Group/Sandwich-Batch-Normalization.
AutoPose: Searching Multi-Scale Branch Aggregation for Pose Estimation
Aug 16, 2020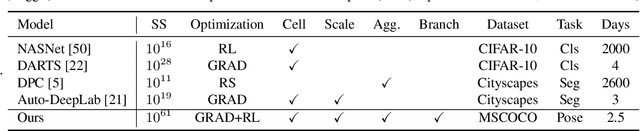
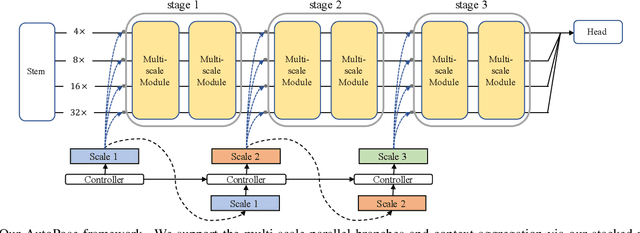
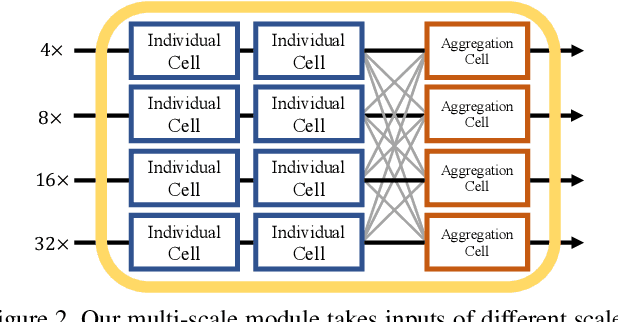
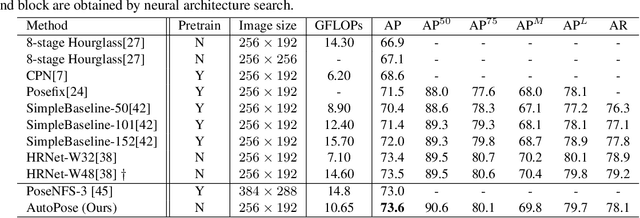
We present AutoPose, a novel neural architecture search(NAS) framework that is capable of automatically discovering multiple parallel branches of cross-scale connections towards accurate and high-resolution 2D human pose estimation. Recently, high-performance hand-crafted convolutional networks for pose estimation show growing demands on multi-scale fusion and high-resolution representations. However, current NAS works exhibit limited flexibility on scale searching, they dominantly adopt simplified search spaces of single-branch architectures. Such simplification limits the fusion of information at different scales and fails to maintain high-resolution representations. The presentedAutoPose framework is able to search for multi-branch scales and network depth, in addition to the cell-level microstructure. Motivated by the search space, a novel bi-level optimization method is presented, where the network-level architecture is searched via reinforcement learning, and the cell-level search is conducted by the gradient-based method. Within 2.5 GPU days, AutoPose is able to find very competitive architectures on the MS COCO dataset, that are also transferable to the MPII dataset. Our code is available at https://github.com/VITA-Group/AutoPose.
NADS: Neural Architecture Distribution Search for Uncertainty Awareness
Jun 11, 2020
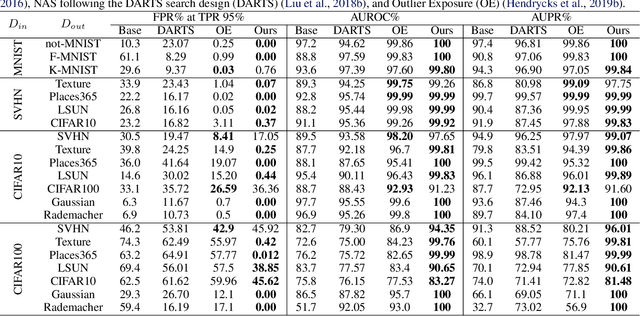
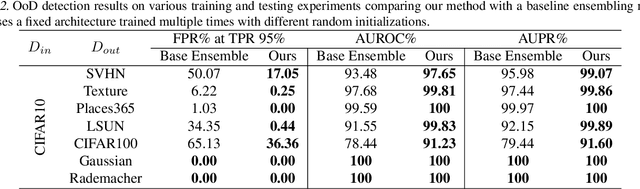
Machine learning (ML) systems often encounter Out-of-Distribution (OoD) errors when dealing with testing data coming from a distribution different from training data. It becomes important for ML systems in critical applications to accurately quantify its predictive uncertainty and screen out these anomalous inputs. However, existing OoD detection approaches are prone to errors and even sometimes assign higher likelihoods to OoD samples. Unlike standard learning tasks, there is currently no well established guiding principle for designing OoD detection architectures that can accurately quantify uncertainty. To address these problems, we first seek to identify guiding principles for designing uncertainty-aware architectures, by proposing Neural Architecture Distribution Search (NADS). NADS searches for a distribution of architectures that perform well on a given task, allowing us to identify common building blocks among all uncertainty-aware architectures. With this formulation, we are able to optimize a stochastic OoD detection objective and construct an ensemble of models to perform OoD detection. We perform multiple OoD detection experiments and observe that our NADS performs favorably, with up to 57% improvement in accuracy compared to state-of-the-art methods among 15 different testing configurations.
AutoSpeech: Neural Architecture Search for Speaker Recognition
May 07, 2020
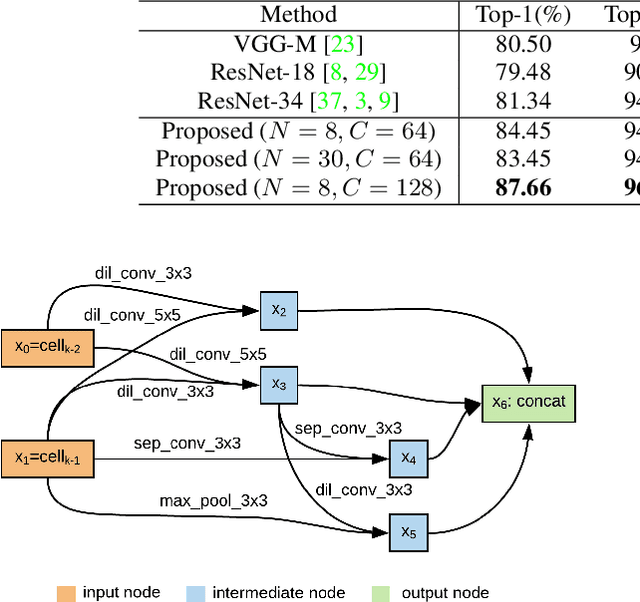
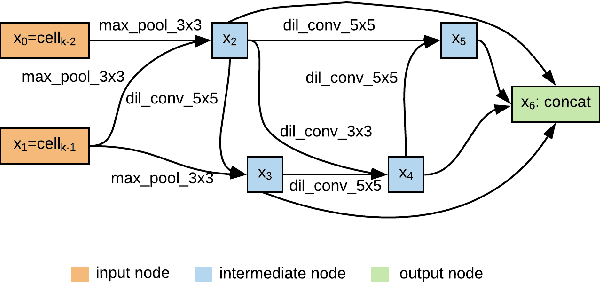
Speaker recognition systems based on Convolutional Neural Networks (CNNs) are often built with off-the-shelf backbones such as VGG-Net or ResNet. However, these backbones were originally proposed for image classification, and therefore may not be naturally fit for speaker recognition. Due to the prohibitive complexity of manually exploring the design space, we propose the first neural architecture search approach approach for the speaker recognition tasks, named as AutoSpeech. Our algorithm first identifies the optimal operation combination in a neural cell and then derives a CNN model by stacking the neural cell for multiple times. The final speaker recognition model can be obtained by training the derived CNN model through the standard scheme. To evaluate the proposed approach, we conduct experiments on both speaker identification and speaker verification tasks using the VoxCeleb1 dataset. Results demonstrate that the derived CNN architectures from the proposed approach significantly outperform current speaker recognition systems based on VGG-M, ResNet-18, and ResNet-34 back-bones, while enjoying lower model complexity.
FasterSeg: Searching for Faster Real-time Semantic Segmentation
Jan 16, 2020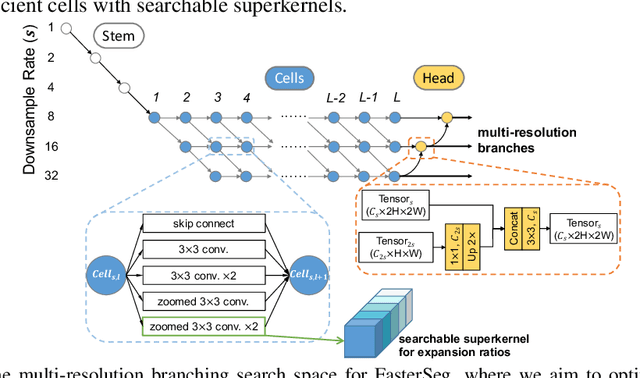
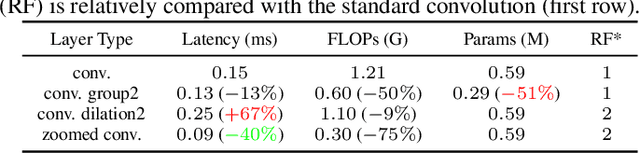
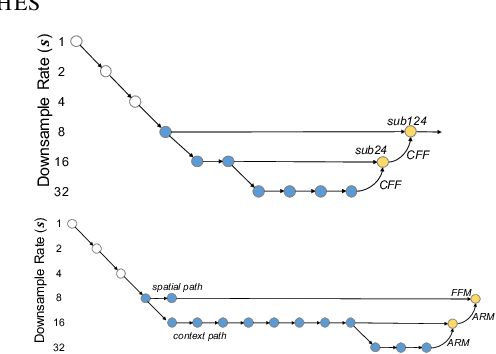
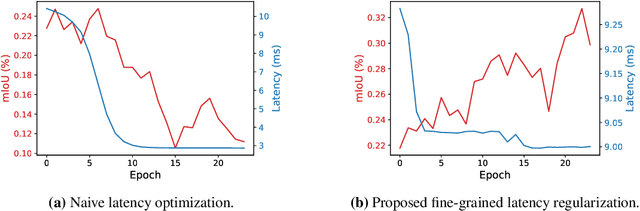
We present FasterSeg, an automatically designed semantic segmentation network with not only state-of-the-art performance but also faster speed than current methods. Utilizing neural architecture search (NAS), FasterSeg is discovered from a novel and broader search space integrating multi-resolution branches, that has been recently found to be vital in manually designed segmentation models. To better calibrate the balance between the goals of high accuracy and low latency, we propose a decoupled and fine-grained latency regularization, that effectively overcomes our observed phenomenons that the searched networks are prone to "collapsing" to low-latency yet poor-accuracy models. Moreover, we seamlessly extend FasterSeg to a new collaborative search (co-searching) framework, simultaneously searching for a teacher and a student network in the same single run. The teacher-student distillation further boosts the student model's accuracy. Experiments on popular segmentation benchmarks demonstrate the competency of FasterSeg. For example, FasterSeg can run over 30% faster than the closest manually designed competitor on Cityscapes, while maintaining comparable accuracy.
AutoGAN: Neural Architecture Search for Generative Adversarial Networks
Aug 11, 2019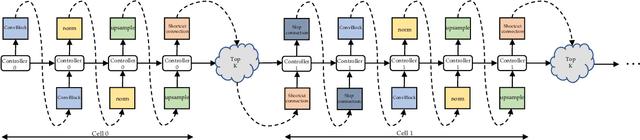
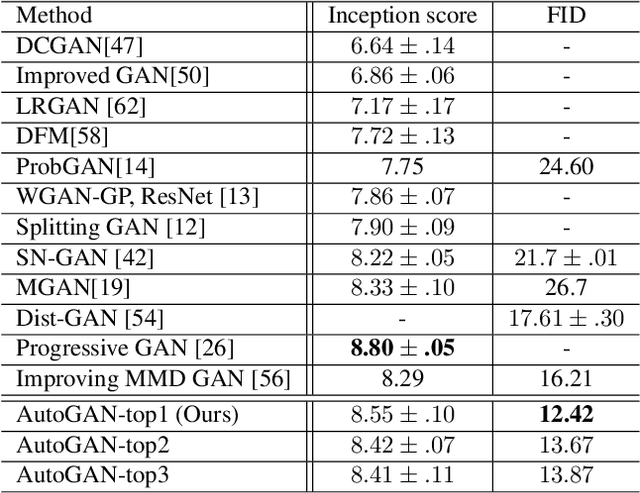
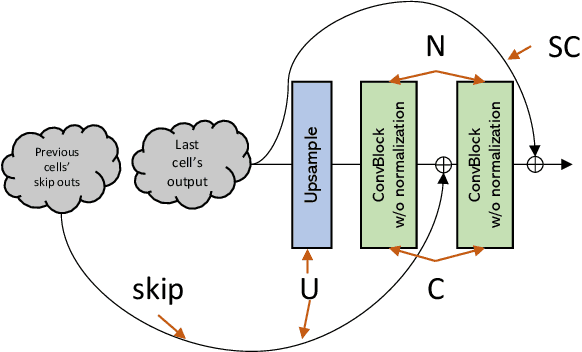
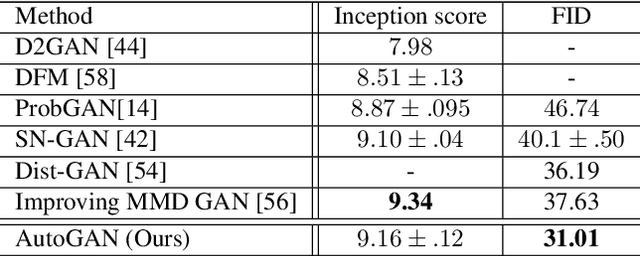
Neural architecture search (NAS) has witnessed prevailing success in image classification and (very recently) segmentation tasks. In this paper, we present the first preliminary study on introducing the NAS algorithm to generative adversarial networks (GANs), dubbed AutoGAN. The marriage of NAS and GANs faces its unique challenges. We define the search space for the generator architectural variations and use an RNN controller to guide the search, with parameter sharing and dynamic-resetting to accelerate the process. Inception score is adopted as the reward, and a multi-level search strategy is introduced to perform NAS in a progressive way. Experiments validate the effectiveness of AutoGAN on the task of unconditional image generation. Specifically, our discovered architectures achieve highly competitive performance compared to current state-of-the-art hand-crafted GANs, e.g., setting new state-of-the-art FID scores of 12.42 on CIFAR-10, and 31.01 on STL-10, respectively. We also conclude with a discussion of the current limitations and future potential of AutoGAN. The code is available at https://github.com/TAMU-VITA/AutoGAN