 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReward Shaping for User Satisfaction in a REINFORCE Recommender
Sep 30, 2022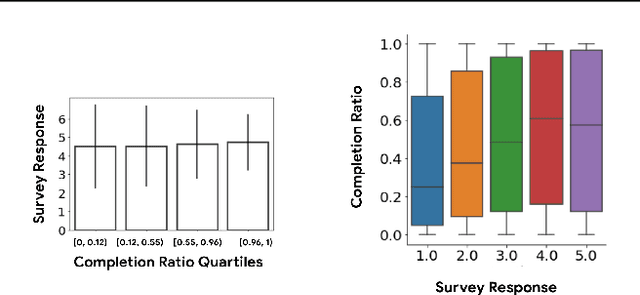
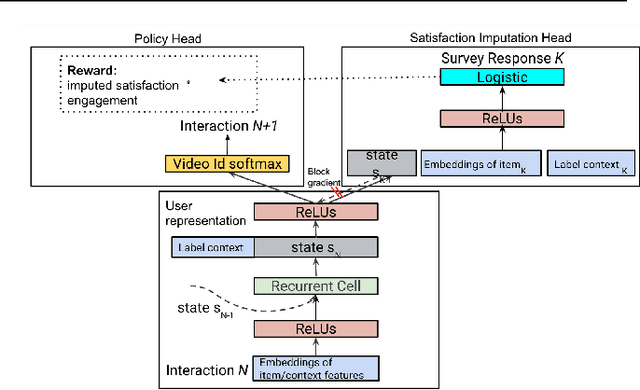
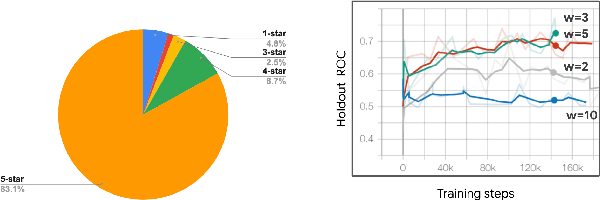
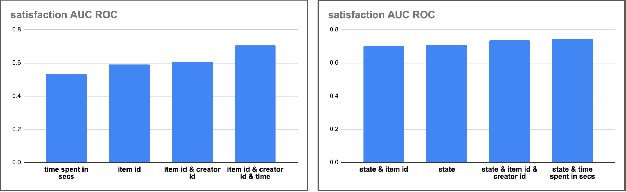
How might we design Reinforcement Learning (RL)-based recommenders that encourage aligning user trajectories with the underlying user satisfaction? Three research questions are key: (1) measuring user satisfaction, (2) combatting sparsity of satisfaction signals, and (3) adapting the training of the recommender agent to maximize satisfaction. For measurement, it has been found that surveys explicitly asking users to rate their experience with consumed items can provide valuable orthogonal information to the engagement/interaction data, acting as a proxy to the underlying user satisfaction. For sparsity, i.e, only being able to observe how satisfied users are with a tiny fraction of user-item interactions, imputation models can be useful in predicting satisfaction level for all items users have consumed. For learning satisfying recommender policies, we postulate that reward shaping in RL recommender agents is powerful for driving satisfying user experiences. Putting everything together, we propose to jointly learn a policy network and a satisfaction imputation network: The role of the imputation network is to learn which actions are satisfying to the user; while the policy network, built on top of REINFORCE, decides which items to recommend, with the reward utilizing the imputed satisfaction. We use both offline analysis and live experiments in an industrial large-scale recommendation platform to demonstrate the promise of our approach for satisfying user experiences.
Improving Multi-Task Generalization via Regularizing Spurious Correlation
May 19, 2022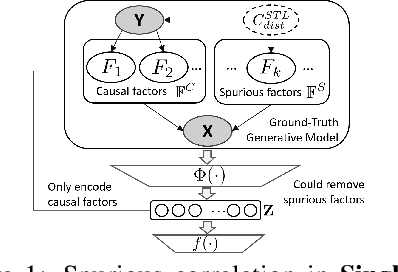
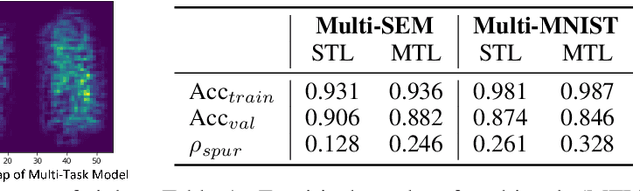
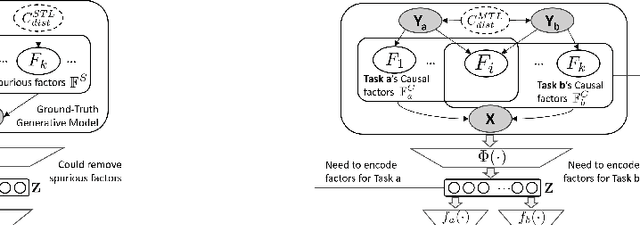
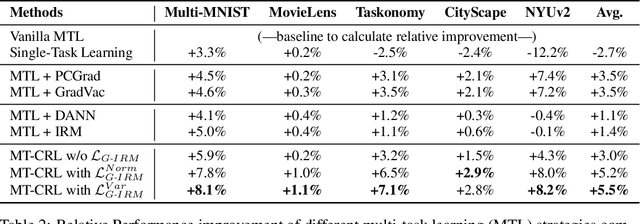
Multi-Task Learning (MTL) is a powerful learning paradigm to improve generalization performance via knowledge sharing. However, existing studies find that MTL could sometimes hurt generalization, especially when two tasks are less correlated. One possible reason that hurts generalization is spurious correlation, i.e., some knowledge is spurious and not causally related to task labels, but the model could mistakenly utilize them and thus fail when such correlation changes. In MTL setup, there exist several unique challenges of spurious correlation. First, the risk of having non-causal knowledge is higher, as the shared MTL model needs to encode all knowledge from different tasks, and causal knowledge for one task could be potentially spurious to the other. Second, the confounder between task labels brings in a different type of spurious correlation to MTL. We theoretically prove that MTL is more prone to taking non-causal knowledge from other tasks than single-task learning, and thus generalize worse. To solve this problem, we propose Multi-Task Causal Representation Learning framework, aiming to represent multi-task knowledge via disentangled neural modules, and learn which module is causally related to each task via MTL-specific invariant regularization. Experiments show that it could enhance MTL model's performance by 5.5% on average over Multi-MNIST, MovieLens, Taskonomy, CityScape, and NYUv2, via alleviating spurious correlation problem.
Deep Hash Embedding for Large-Vocab Categorical Feature Representations
Oct 21, 2020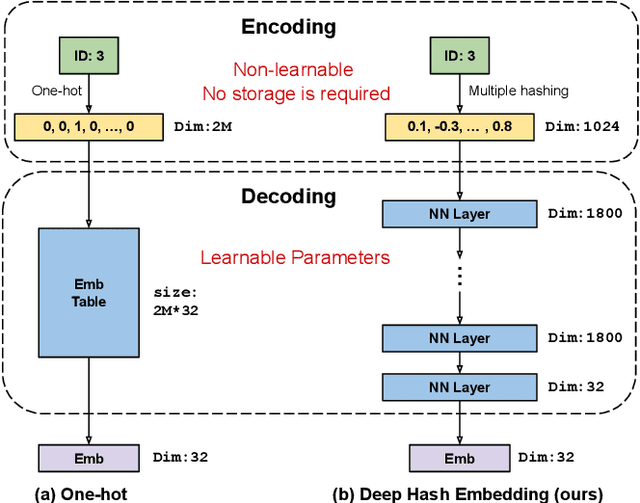

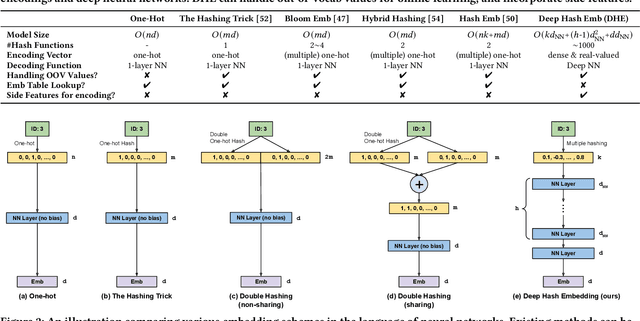
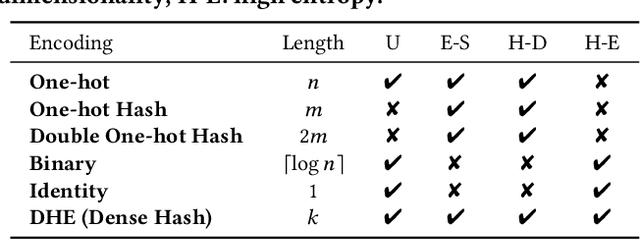
Embedding learning for large-vocabulary categorical features (e.g. user/item IDs, and words) is crucial for deep learning, and especially neural models for recommendation systems and natural language understanding tasks. Typically, the model creates a huge embedding table that each row represents a dedicated embedding vector for every feature value. In practice, to handle new (i.e., out-of-vocab) feature values and reduce the storage cost, the hashing trick is often adopted, that randomly maps feature values to a smaller number of hashing buckets. Essentially, thess embedding methods can be viewed as 1-layer wide neural networks with one-hot encodings. In this paper, we propose an alternative embedding framework Deep Hash Embedding (DHE), with non-one-hot encodings and a deep neural network (embedding network) to compute embeddings on the fly without having to store them. DHE first encodes the feature value to a dense vector with multiple hashing functions and then applies a DNN to generate the embedding. DHE is collision-free as the dense hashing encodings are unique identifiers for both in-vocab and out-of-vocab feature values. The encoding module is deterministic, non-learnable, and free of storage, while the embedding network is updated during the training time to memorize embedding information. Empirical results show that DHE outperforms state-of-the-art hashing-based embedding learning algorithms, and achieves comparable AUC against the standard one-hot encoding, with significantly smaller model sizes. Our work sheds light on design of DNN-based alternative embedding schemes for categorical features without using embedding table lookup.
Self-supervised Learning for Deep Models in Recommendations
Jul 25, 2020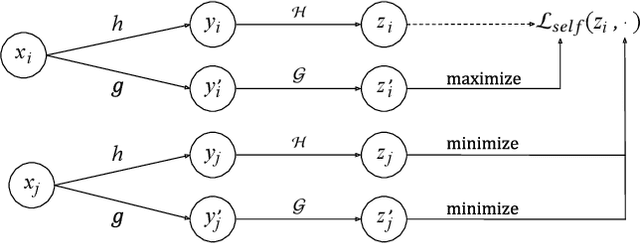
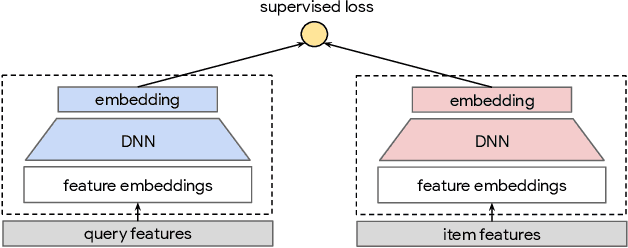
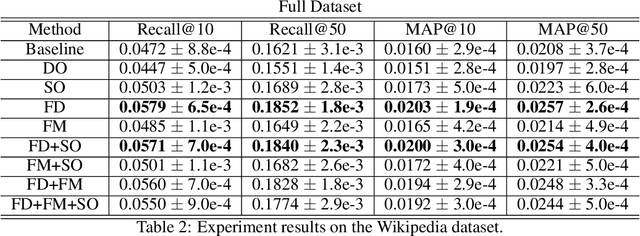
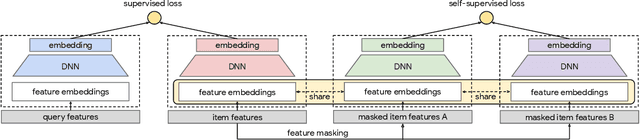
Large scale neural recommender models play a critical role in modern search and recommendation systems. To model large-vocab sparse categorical features, typical recommender models learn a joint embedding space for both queries and items. With millions to billions of items to choose from, the quality of learned embedding representations is crucial to provide high quality recommendations to users with various interests. Inspired by the recent success in self-supervised representation learning research in both computer vision and natural language understanding, we propose a multi-task self-supervised learning (SSL) framework for sparse neural models in recommendations. Furthermore, we propose two highly generalizable self-supervised learning tasks: (i) Feature Masking (FM) and (ii) Feature Dropout (FD) within the proposed SSL framework. We evaluate our framework using two large-scale datasets with ~500M and 1B training examples respectively. Our results demonstrate that the proposed framework outperforms baseline models and state-of-the-art spread-out regularization techniques in the context of retrieval. The SSL framework shows larger improvement with less supervision compared to the counterparts.
Learning-to-Rank with Partitioned Preference: Fast Estimation for the Plackett-Luce Model
Jun 09, 2020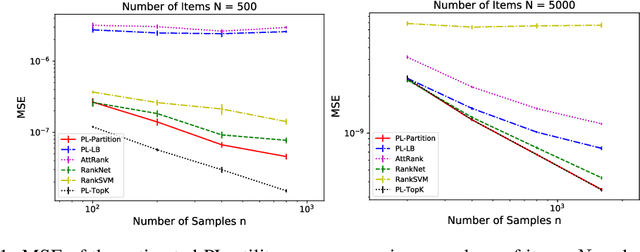
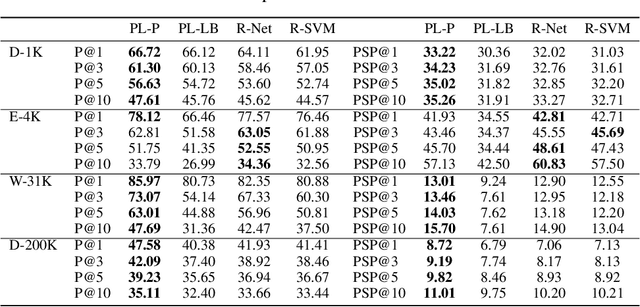
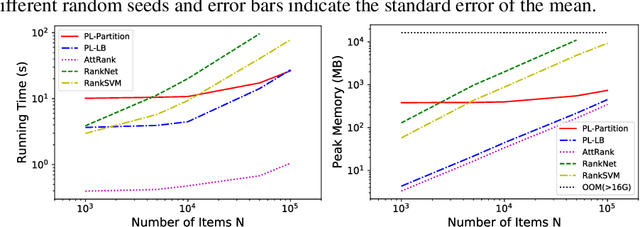
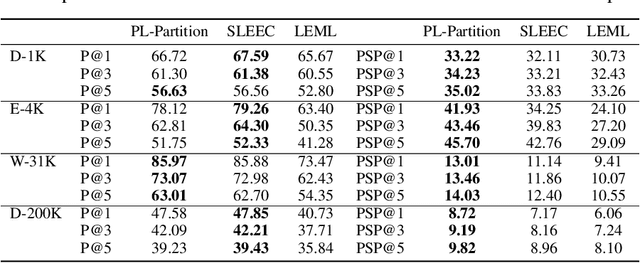
We consider the problem of listwise learning-to-rank (LTR) on data with \textit{partitioned preference}, where a set of items are sliced into ordered and disjoint partitions, but the ranking of items within a partition is unknown. The Plackett-Luce (PL) model has been widely used in listwise LTR methods. However, given $N$ items with $M$ partitions, calculating the likelihood of data with partitioned preference under the PL model has a time complexity of $O(N+S!)$, where $S$ is the maximum size of the top $M-1$ partitions. This computational challenge restrains existing PL-based listwise LTR methods to only a special case of partitioned preference, \textit{top-$K$ ranking}, where the exact order of the top $K$ items is known. In this paper, we exploit a random utility model formulation of the PL model and propose an efficient approach through numerical integration for calculating the likelihood. This numerical approach reduces the aforementioned time complexity to $O(N+MS)$, which allows training deep-neural-network-based ranking models with a large output space. We demonstrate that the proposed method outperforms well-known LTR baselines and remains scalable through both simulation experiments and applications to real-world eXtreme Multi-Label (XML) classification tasks. The proposed method also achieves state-of-the-art performance on XML datasets with relatively large numbers of labels per sample.
More Supervision, Less Computation: Statistical-Computational Tradeoffs in Weakly Supervised Learning
Jul 14, 2019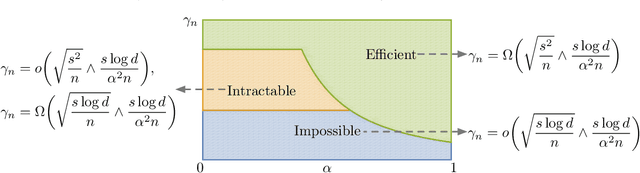
We consider the weakly supervised binary classification problem where the labels are randomly flipped with probability $1- {\alpha}$. Although there exist numerous algorithms for this problem, it remains theoretically unexplored how the statistical accuracies and computational efficiency of these algorithms depend on the degree of supervision, which is quantified by ${\alpha}$. In this paper, we characterize the effect of ${\alpha}$ by establishing the information-theoretic and computational boundaries, namely, the minimax-optimal statistical accuracy that can be achieved by all algorithms, and polynomial-time algorithms under an oracle computational model. For small ${\alpha}$, our result shows a gap between these two boundaries, which represents the computational price of achieving the information-theoretic boundary due to the lack of supervision. Interestingly, we also show that this gap narrows as ${\alpha}$ increases. In other words, having more supervision, i.e., more correct labels, not only improves the optimal statistical accuracy as expected, but also enhances the computational efficiency for achieving such accuracy.
* This work has been published in NeurIPS 2016. The first three authors contribute equally
Efficient Training on Very Large Corpora via Gramian Estimation
Jul 18, 2018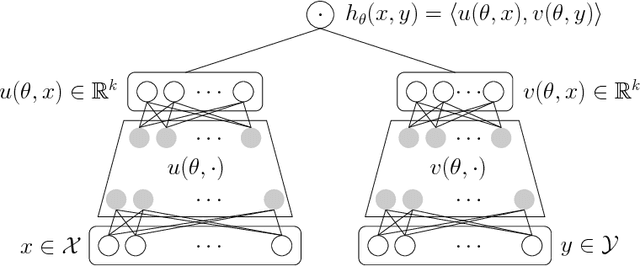

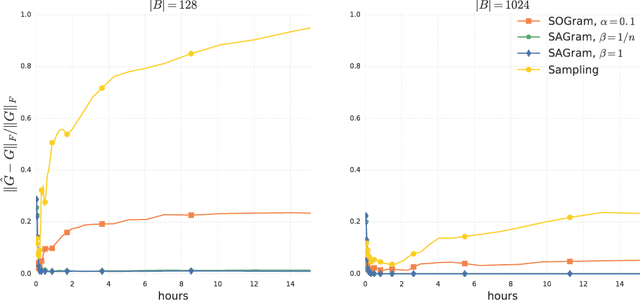

We study the problem of learning similarity functions over very large corpora using neural network embedding models. These models are typically trained using SGD with sampling of random observed and unobserved pairs, with a number of samples that grows quadratically with the corpus size, making it expensive to scale to very large corpora. We propose new efficient methods to train these models without having to sample unobserved pairs. Inspired by matrix factorization, our approach relies on adding a global quadratic penalty to all pairs of examples and expressing this term as the matrix-inner-product of two generalized Gramians. We show that the gradient of this term can be efficiently computed by maintaining estimates of the Gramians, and develop variance reduction schemes to improve the quality of the estimates. We conduct large-scale experiments that show a significant improvement in training time and generalization quality compared to traditional sampling methods.
Fast Algorithms for Robust PCA via Gradient Descent
Sep 19, 2016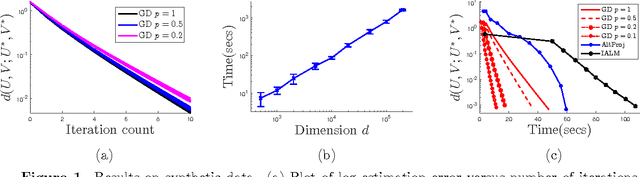


We consider the problem of Robust PCA in the fully and partially observed settings. Without corruptions, this is the well-known matrix completion problem. From a statistical standpoint this problem has been recently well-studied, and conditions on when recovery is possible (how many observations do we need, how many corruptions can we tolerate) via polynomial-time algorithms is by now understood. This paper presents and analyzes a non-convex optimization approach that greatly reduces the computational complexity of the above problems, compared to the best available algorithms. In particular, in the fully observed case, with $r$ denoting rank and $d$ dimension, we reduce the complexity from $\mathcal{O}(r^2d^2\log(1/\varepsilon))$ to $\mathcal{O}(rd^2\log(1/\varepsilon))$ -- a big savings when the rank is big. For the partially observed case, we show the complexity of our algorithm is no more than $\mathcal{O}(r^4d \log d \log(1/\varepsilon))$. Not only is this the best-known run-time for a provable algorithm under partial observation, but in the setting where $r$ is small compared to $d$, it also allows for near-linear-in-$d$ run-time that can be exploited in the fully-observed case as well, by simply running our algorithm on a subset of the observations.
Solving a Mixture of Many Random Linear Equations by Tensor Decomposition and Alternating Minimization
Aug 19, 2016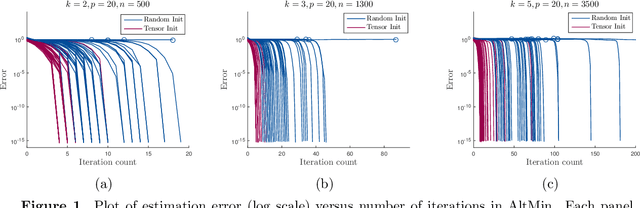
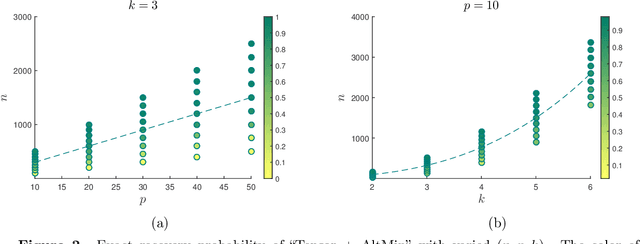
We consider the problem of solving mixed random linear equations with $k$ components. This is the noiseless setting of mixed linear regression. The goal is to estimate multiple linear models from mixed samples in the case where the labels (which sample corresponds to which model) are not observed. We give a tractable algorithm for the mixed linear equation problem, and show that under some technical conditions, our algorithm is guaranteed to solve the problem exactly with sample complexity linear in the dimension, and polynomial in $k$, the number of components. Previous approaches have required either exponential dependence on $k$, or super-linear dependence on the dimension. The proposed algorithm is a combination of tensor decomposition and alternating minimization. Our analysis involves proving that the initialization provided by the tensor method allows alternating minimization, which is equivalent to EM in our setting, to converge to the global optimum at a linear rate.
Regularized EM Algorithms: A Unified Framework and Statistical Guarantees
Dec 05, 2015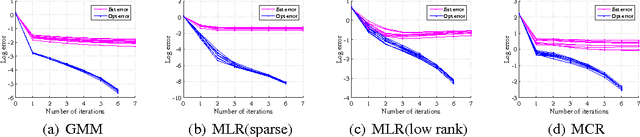
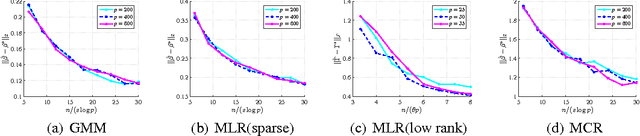
Latent variable models are a fundamental modeling tool in machine learning applications, but they present significant computational and analytical challenges. The popular EM algorithm and its variants, is a much used algorithmic tool; yet our rigorous understanding of its performance is highly incomplete. Recently, work in Balakrishnan et al. (2014) has demonstrated that for an important class of problems, EM exhibits linear local convergence. In the high-dimensional setting, however, the M-step may not be well defined. We address precisely this setting through a unified treatment using regularization. While regularization for high-dimensional problems is by now well understood, the iterative EM algorithm requires a careful balancing of making progress towards the solution while identifying the right structure (e.g., sparsity or low-rank). In particular, regularizing the M-step using the state-of-the-art high-dimensional prescriptions (e.g., Wainwright (2014)) is not guaranteed to provide this balance. Our algorithm and analysis are linked in a way that reveals the balance between optimization and statistical errors. We specialize our general framework to sparse gaussian mixture models, high-dimensional mixed regression, and regression with missing variables, obtaining statistical guarantees for each of these examples.