 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCDNet: Self-supervised Learning Feature-based Speaker Change Detection
Jun 12, 2024Speaker Change Detection (SCD) is to identify boundaries among speakers in a conversation. Motivated by the success of fine-tuning wav2vec 2.0 models for the SCD task, a further investigation of self-supervised learning (SSL) features for SCD is conducted in this work. Specifically, an SCD model, named SCDNet, is proposed. With this model, various state-of-the-art SSL models, including Hubert, wav2vec 2.0, and WavLm are investigated. To discern the most potent layer of SSL models for SCD, a learnable weighting method is employed to analyze the effectiveness of intermediate representations. Additionally, a fine-tuning-based approach is also implemented to further compare the characteristics of SSL models in the SCD task. Furthermore, a contrastive learning method is proposed to mitigate the overfitting tendencies in the training of both the fine-tuning-based method and SCDNet. Experiments showcase the superiority of WavLm in the SCD task and also demonstrate the good design of SCDNet.
StreamVoice: Streamable Context-Aware Language Modeling for Real-time Zero-Shot Voice Conversion
Feb 07, 2024



Recent language model (LM) advancements have showcased impressive zero-shot voice conversion (VC) performance. However, existing LM-based VC models usually apply offline conversion from source semantics to acoustic features, demanding the complete source speech, and limiting their deployment to real-time applications. In this paper, we introduce StreamVoice, a novel streaming LM-based model for zero-shot VC, facilitating real-time conversion given arbitrary speaker prompts and source speech. Specifically, to enable streaming capability, StreamVoice employs a fully causal context-aware LM with a temporal-independent acoustic predictor, while alternately processing semantic and acoustic features at each time step of autoregression which eliminates the dependence on complete source speech. To address the potential performance degradation from the incomplete context in streaming processing, we enhance the context-awareness of the LM through two strategies: 1) teacher-guided context foresight, using a teacher model to summarize the present and future semantic context during training to guide the model's forecasting for missing context; 2) semantic masking strategy, promoting acoustic prediction from preceding corrupted semantic and acoustic input, enhancing context-learning ability. Notably, StreamVoice is the first LM-based streaming zero-shot VC model without any future look-ahead. Experimental results demonstrate StreamVoice's streaming conversion capability while maintaining zero-shot performance comparable to non-streaming VC systems.
MSM-VC: High-fidelity Source Style Transfer for Non-Parallel Voice Conversion by Multi-scale Style Modeling
Sep 03, 2023



In addition to conveying the linguistic content from source speech to converted speech, maintaining the speaking style of source speech also plays an important role in the voice conversion (VC) task, which is essential in many scenarios with highly expressive source speech, such as dubbing and data augmentation. Previous work generally took explicit prosodic features or fixed-length style embedding extracted from source speech to model the speaking style of source speech, which is insufficient to achieve comprehensive style modeling and target speaker timbre preservation. Inspired by the style's multi-scale nature of human speech, a multi-scale style modeling method for the VC task, referred to as MSM-VC, is proposed in this paper. MSM-VC models the speaking style of source speech from different levels. To effectively convey the speaking style and meanwhile prevent timbre leakage from source speech to converted speech, each level's style is modeled by specific representation. Specifically, prosodic features, pre-trained ASR model's bottleneck features, and features extracted by a model trained with a self-supervised strategy are adopted to model the frame, local, and global-level styles, respectively. Besides, to balance the performance of source style modeling and target speaker timbre preservation, an explicit constraint module consisting of a pre-trained speech emotion recognition model and a speaker classifier is introduced to MSM-VC. This explicit constraint module also makes it possible to simulate the style transfer inference process during the training to improve the disentanglement ability and alleviate the mismatch between training and inference. Experiments performed on the highly expressive speech corpus demonstrate that MSM-VC is superior to the state-of-the-art VC methods for modeling source speech style while maintaining good speech quality and speaker similarity.
UniSyn: An End-to-End Unified Model for Text-to-Speech and Singing Voice Synthesis
Dec 06, 2022



Text-to-speech (TTS) and singing voice synthesis (SVS) aim at generating high-quality speaking and singing voice according to textual input and music scores, respectively. Unifying TTS and SVS into a single system is crucial to the applications requiring both of them. Existing methods usually suffer from some limitations, which rely on either both singing and speaking data from the same person or cascaded models of multiple tasks. To address these problems, a simplified elegant framework for TTS and SVS, named UniSyn, is proposed in this paper. It is an end-to-end unified model that can make a voice speak and sing with only singing or speaking data from this person. To be specific, a multi-conditional variational autoencoder (MC-VAE), which constructs two independent latent sub-spaces with the speaker- and style-related (i.e. speak or sing) conditions for flexible control, is proposed in UniSyn. Moreover, supervised guided-VAE and timbre perturbation with the Wasserstein distance constraint are leveraged to further disentangle the speaker timbre and style. Experiments conducted on two speakers and two singers demonstrate that UniSyn can generate natural speaking and singing voice without corresponding training data. The proposed approach outperforms the state-of-the-art end-to-end voice generation work, which proves the effectiveness and advantages of UniSyn.
Delivering Speaking Style in Low-resource Voice Conversion with Multi-factor Constraints
Nov 16, 2022



Conveying the linguistic content and maintaining the source speech's speaking style, such as intonation and emotion, is essential in voice conversion (VC). However, in a low-resource situation, where only limited utterances from the target speaker are accessible, existing VC methods are hard to meet this requirement and capture the target speaker's timber. In this work, a novel VC model, referred to as MFC-StyleVC, is proposed for the low-resource VC task. Specifically, speaker timbre constraint generated by clustering method is newly proposed to guide target speaker timbre learning in different stages. Meanwhile, to prevent over-fitting to the target speaker's limited data, perceptual regularization constraints explicitly maintain model performance on specific aspects, including speaking style, linguistic content, and speech quality. Besides, a simulation mode is introduced to simulate the inference process to alleviate the mismatch between training and inference. Extensive experiments performed on highly expressive speech demonstrate the superiority of the proposed method in low-resource VC.
Robust MelGAN: A robust universal neural vocoder for high-fidelity TTS
Nov 02, 2022



In current two-stage neural text-to-speech (TTS) paradigm, it is ideal to have a universal neural vocoder, once trained, which is robust to imperfect mel-spectrogram predicted from the acoustic model. To this end, we propose Robust MelGAN vocoder by solving the original multi-band MelGAN's metallic sound problem and increasing its generalization ability. Specifically, we introduce a fine-grained network dropout strategy to the generator. With a specifically designed over-smooth handler which separates speech signal intro periodic and aperiodic components, we only perform network dropout to the aperodic components, which alleviates metallic sounding and maintains good speaker similarity. To further improve generalization ability, we introduce several data augmentation methods to augment fake data in the discriminator, including harmonic shift, harmonic noise and phase noise. Experiments show that Robust MelGAN can be used as a universal vocoder, significantly improving sound quality in TTS systems built on various types of data.
Cross-speaker Emotion Transfer Based On Prosody Compensation for End-to-End Speech Synthesis
Jul 04, 2022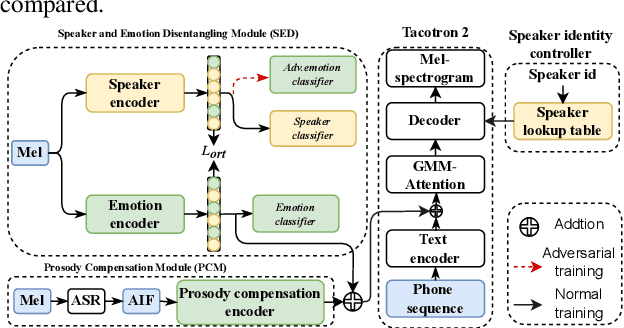
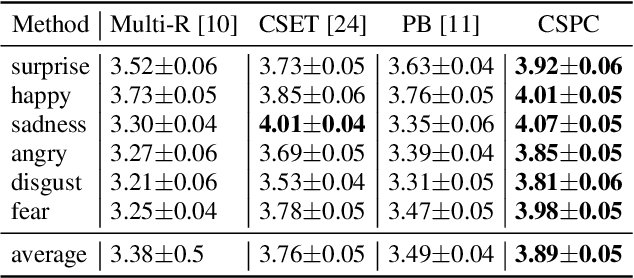
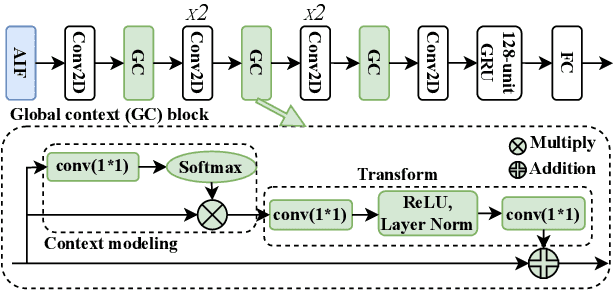
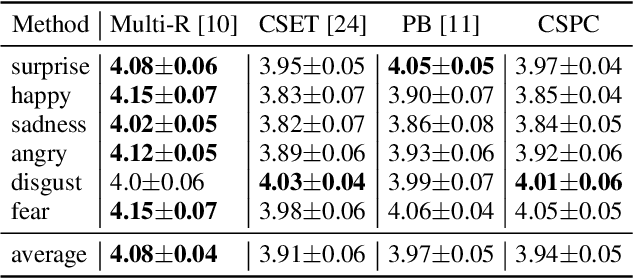
Cross-speaker emotion transfer speech synthesis aims to synthesize emotional speech for a target speaker by transferring the emotion from reference speech recorded by another (source) speaker. In this task, extracting speaker-independent emotion embedding from reference speech plays an important role. However, the emotional information conveyed by such emotion embedding tends to be weakened in the process to squeeze out the source speaker's timbre information. In response to this problem, a prosody compensation module (PCM) is proposed in this paper to compensate for the emotional information loss. Specifically, the PCM tries to obtain speaker-independent emotional information from the intermediate feature of a pre-trained ASR model. To this end, a prosody compensation encoder with global context (GC) blocks is introduced to obtain global emotional information from the ASR model's intermediate feature. Experiments demonstrate that the proposed PCM can effectively compensate the emotion embedding for the emotional information loss, and meanwhile maintain the timbre of the target speaker. Comparisons with state-of-the-art models show that our proposed method presents obvious superiority on the cross-speaker emotion transfer task.
AdaVITS: Tiny VITS for Low Computing Resource Speaker Adaptation
Jun 01, 2022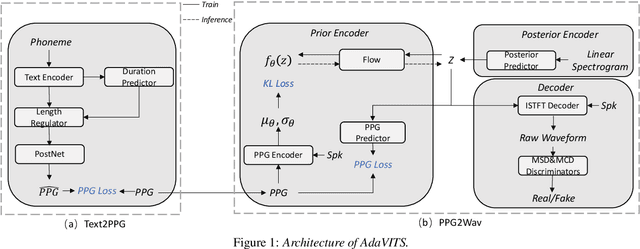

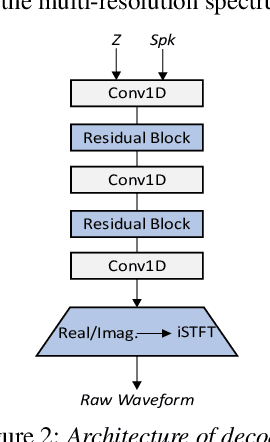
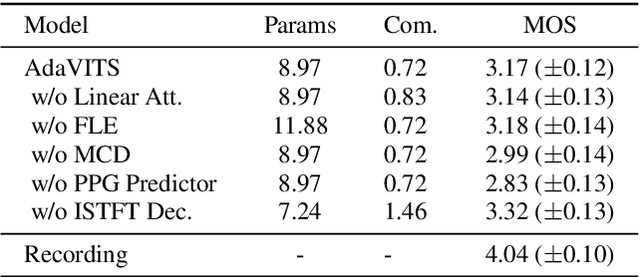
Speaker adaptation in text-to-speech synthesis (TTS) is to finetune a pre-trained TTS model to adapt to new target speakers with limited data. While much effort has been conducted towards this task, seldom work has been performed for low computational resource scenarios due to the challenges raised by the requirement of the lightweight model and less computational complexity. In this paper, a tiny VITS-based TTS model, named AdaVITS, for low computing resource speaker adaptation is proposed. To effectively reduce parameters and computational complexity of VITS, an iSTFT-based wave construction decoder is proposed to replace the upsampling-based decoder which is resource-consuming in the original VITS. Besides, NanoFlow is introduced to share the density estimate across flow blocks to reduce the parameters of the prior encoder. Furthermore, to reduce the computational complexity of the textual encoder, scaled-dot attention is replaced with linear attention. To deal with the instability caused by the simplified model, instead of using the original text encoder, phonetic posteriorgram (PPG) is utilized as linguistic feature via a text-to-PPG module, which is then used as input for the encoder. Experiment shows that AdaVITS can generate stable and natural speech in speaker adaptation with 8.97M model parameters and 0.72GFlops computational complexity.
Learn2Sing 2.0: Diffusion and Mutual Information-Based Target Speaker SVS by Learning from Singing Teacher
Mar 30, 2022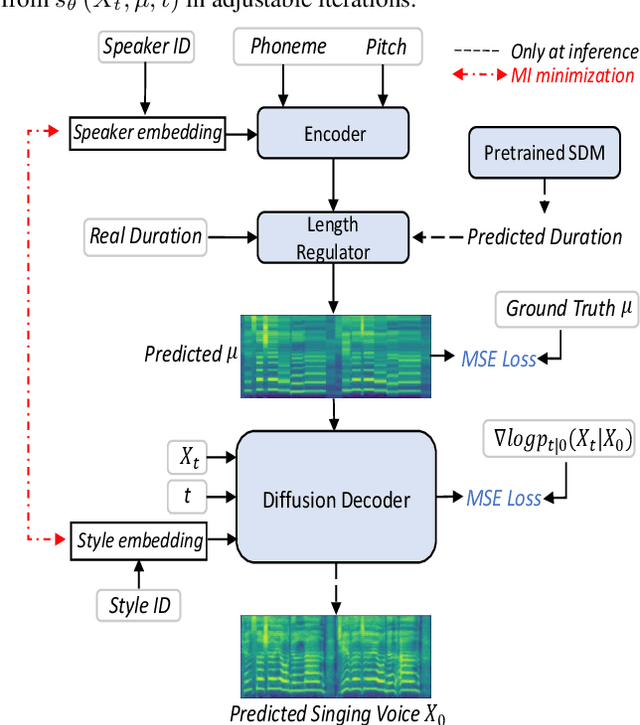
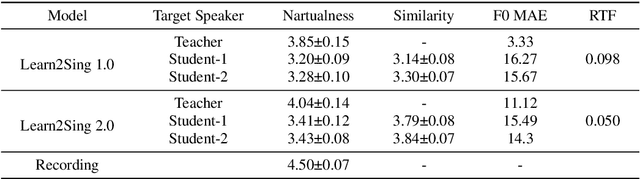
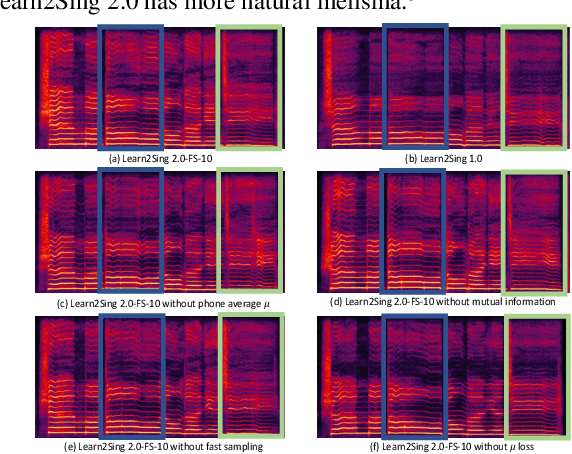
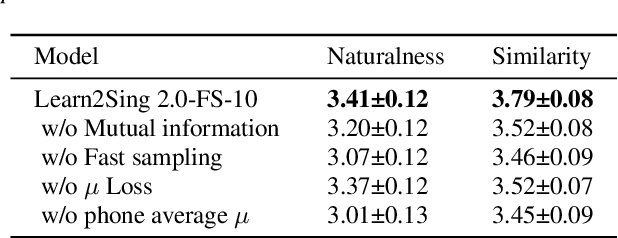
Building a high-quality singing corpus for a person who is not good at singing is non-trivial, thus making it challenging to create a singing voice synthesizer for this person. Learn2Sing is dedicated to synthesizing the singing voice of a speaker without his or her singing data by learning from data recorded by others, i.e., the singing teacher. Inspired by the fact that pitch is the key style factor to distinguish singing from speaking voice, the proposed Learn2Sing 2.0 first generates the preliminary acoustic feature with averaged pitch value in the phone level, which allows the training of this process for different styles, i.e., speaking or singing, share same conditions except for the speaker information. Then, conditioned on the specific style, a diffusion decoder, which is accelerated by a fast sampling algorithm during the inference stage, is adopted to gradually restore the final acoustic feature. During the training, to avoid the information confusion of the speaker embedding and the style embedding, mutual information is employed to restrain the learning of speaker embedding and style embedding. Experiments show that the proposed approach is capable of synthesizing high-quality singing voice for the target speaker without singing data with 10 decoding steps.
Opencpop: A High-Quality Open Source Chinese Popular Song Corpus for Singing Voice Synthesis
Jan 20, 2022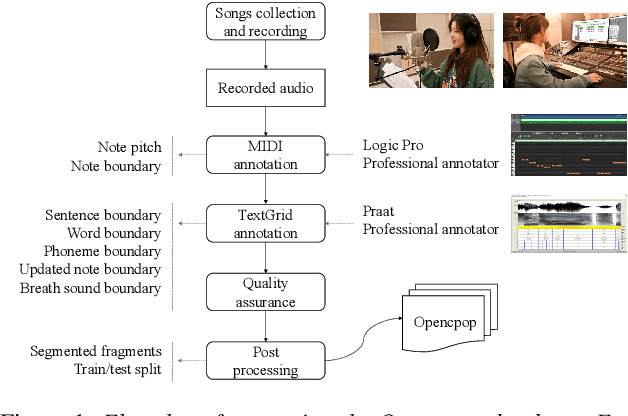
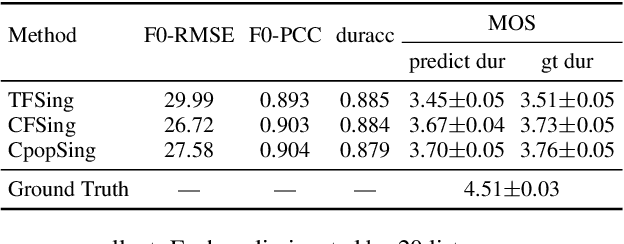


This paper introduces Opencpop, a publicly available high-quality Mandarin singing corpus designed for singing voice synthesis (SVS). The corpus consists of 100 popular Mandarin songs performed by a female professional singer. Audio files are recorded with studio quality at a sampling rate of 44,100 Hz and the corresponding lyrics and musical scores are provided. All singing recordings have been phonetically annotated with phoneme boundaries and syllable (note) boundaries. To demonstrate the reliability of the released data and to provide a baseline for future research, we built baseline deep neural network-based SVS models and evaluated them with both objective metrics and subjective mean opinion score (MOS) measure. Experimental results show that the best SVS model trained on our database achieves 3.70 MOS, indicating the reliability of the provided corpus. Opencpop is released to the open-source community WeNet, and the corpus, as well as synthesized demos, can be found on the project homepage.